How to locate slow SQL?
Slow SQL is monitored mainly through two ways:
- Slow query log : Enable MySQL's slow query log, and then use some tools such as mysqldumpslow to analyze the corresponding slow query log. Of course, most cloud vendors now provide visual platforms.
- Service monitoring : Monitoring of slow SQL can be added to the business infrastructure. Common solutions include bytecode instrumentation, connection pool expansion, and ORM framework processes to monitor and alert for slow SQL while the service is running.
What are some ways to optimize slow SQL?
avoid unnecessary columns
This is a cliché, but it still happens frequently. When doing SQL queries, you should only query the required columns and not include additional columns. slect * Writing like this should be avoided as much as possible.
Pagination optimization
When the amount of data is relatively large and the paging is deep, optimization of paging needs to be considered.
JOIN optimization
Optimize subquery
Try to use the Join statement to replace the subquery, because the subquery is a nested query, and the nested query will create a new temporary table, and the creation and destruction of the temporary table will occupy a certain amount of system resources and take a certain amount of time. At the same time, for Subqueries that return larger result sets have a greater impact on query performance.
Small table drives big table
When performing related queries, a small table must be used to drive the large table, because during the related process, MySQL will internally traverse the driving table and then connect to the driven table.
For example, left join, the left table is the driving table. Table A is smaller than table B, so the number of connection establishments is less, and the query speed is accelerated.
select name from A left join B ;
Add redundant fields appropriately
Adding redundant fields can reduce a large number of join table queries, because the performance of join table queries on multiple tables is very low. Therefore, redundant fields can be appropriately added to reduce associated queries on multiple tables. This is an optimization that trades space for time. Strategy
Avoid using JOIN to associate too many tables
"Alibaba Java Development Manual" stipulates that you should not join more than three tables. First, too many joins will reduce the query speed. Second, the join buffer will occupy more memory.
If it is unavoidable to join multiple tables, you can consider using data heterogeneity to query in ES.
What kinds of locks are there in MySQL? List them?
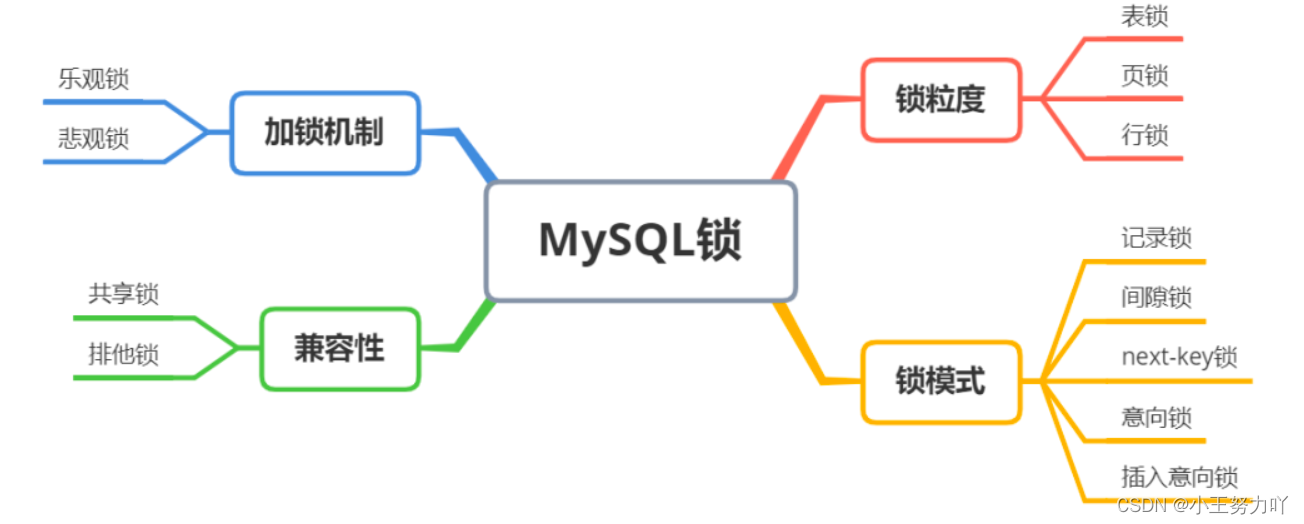
If divided by lock granularity, there are the following three types:
- Table lock: low overhead, fast locking; strong locking force, high probability of lock conflict, lowest concurrency; no deadlock.
- Row lock: high overhead, slow locking; deadlock may occur; small locking granularity, low probability of lock conflict, and high concurrency.
- Page lock: The cost and locking speed are between table locks and row locks; deadlocks may occur; the locking granularity is between table locks and row locks, and the concurrency is average.
In terms of compatibility, there are two types,
- Shared lock (S Lock), also called read lock (read lock), does not block each other.
- Exclusive lock (X Lock), also called write lock (write lock), exclusive lock is blocking. Within a certain period of time, only one request can perform writing and prevents other locks from reading the data being written.
Do you understand MySQL’s optimistic locking and pessimistic locking?
- Pessimistic Concurrency Control:
Pessimistic locks believe that the data protected by it is extremely unsafe and may be changed at any time. After a transaction obtains a pessimistic lock, no other transaction can modify the data and can only wait for the lock to be released. Can be executed.
Row locks, table locks, read locks, and write locks in the database are all pessimistic locks.
- Optimistic Concurrency Control
Optimistic locking believes that data changes will not be too frequent.
Optimistic locking is usually implemented by adding a version (version) or timestamp (timestamp) to the table, of which version is the most commonly used.
When a transaction fetches data from the database, it will also fetch the version of the data (v1). When the transaction completes the changes to the data and wants to update it to the table, it will fetch the version v1 previously and the latest version in the data. Compared with version v2, if v1=v2, it means that during the data change period, no other transactions modify the data. At this time, transactions are allowed to modify the data in the table, and the version will be increased by 1 during the modification. Indicates that the data has been changed.
If v1 is not equal to v2, it means that the data was modified by other transactions during the data change period. At this time, the data is not allowed to be updated into the table. The general solution is to notify the user and let them re-operate. Unlike pessimistic locking, optimistic locking is usually implemented by developers.
Have you ever encountered a deadlock problem in MySQL and how did you solve it?
The general steps for troubleshooting deadlocks are as follows:
(1) Check the deadlock log show engine innodb status;
(2) Find out the deadlock sql
(3) Analyze sql locking situation
(4) Simulate deadlock incident
(5) Analyze deadlock logs
(6) Analyze deadlock results
Of course, this is just a simple process description. In fact, deadlocks in production are all kinds of strange, and it is not that simple to troubleshoot and solve.