Article directory
Paper title: Physical Backdoor Attacks to Lane Detection Systems in Autonomous Driving
Year of publication: 2022-MM (ACM International Conference on Multimedia, CCF-A)
Author information: Xingshuo Han (Nanyang Polytechnic) University), Guowen Xu (Nanyang Technological University), Yuan Zhou* (Nanyang Technological University), Xuehuan Yang (Nanyang Technological University), Jiwei Li (Nanyang Technological University), Tianwei Zhang (Nanyang Technological University)
Note: An article about Lane Detection Attack documentation
Abstract
Modern autonomous vehicles employ state-of-the-art DNN models to interpret sensor data and sense the environment. However, DNN models are susceptible to different types of adversarial attacks, posing significant risks to vehicle and passenger safety. A prominent threat is backdoor attacks, where adversaries can corrupt DNN models by poisoning training samples . Although there has been extensive research on backdoor attacks for traditional computer vision tasks, their practicality and applicability in autonomous driving scenarios have been less explored, especially in the physical world.
The target of this article is the lane detection system , which is an indispensable module for many autonomous driving tasks, such as navigation and lane switching. Designed and implemented the first physical backdoor attack against the system . Our attack is effective against different types of lane line detection algorithms . Two attack methods ( poison-annotation and clean-annotation ) are introduced to generate poisoning samples. Using these samples, the trained lane detection model is infected with backdoors and may be activated by common objects such as traffic cones to make false detections, causing the vehicle to run off the road or into the opposite lane. Extensive evaluation on public datasets and physical self-driving cars demonstrates that the proposed backdoor attack is effective, stealthy, and robust against various defense solutions. Our code and experimental videos can be found at https://sites.google.com/view/lane-detection-attack/lda .
1.Introduction
The rapid development of deep learning technology has improved the perception capabilities of self-driving cars, enabling them to understand the environment and make intelligent actions. Vehicles collect many types of data from sensors and use DNN models to complete different functions. Lane detection is an important feature designed to identify traffic lanes from images or videos captured by cameras. This feature is crucial for lane following, lane changing and overtaking in autonomous driving. In recent years, a large number of algorithms and methods based on deep learning have been introduced, significantly improving detection accuracy and real-time performance [17, 22, 24, 31, 35, 36, 46, 47, 67].
Unfortunately, past research has shown that deep neural network models are not robust and can be easily fooled by malicious entities. One notorious threat is the DNN backdoor [12, 13, 32, 57]. The attacker embeds a secret backdoor in the victim model by poisoning the training set . This backdoor remains dormant during normal input inference samples . It is activated by malicious samples that contain an adversary-specific trigger that misleads the infected model into giving incorrect predictions. Researchers have proposed various DNN models for computer vision [3, 21, 27, 33, 34, 54, 58], natural language processing [5, 10, 44, 60], reinforcement learning [25, 53, 65], etc. new attack. However, no studies have investigated backdoor opportunities for lane detection systems.
This paper aims to bridge this gap by designing and implementing the first practical backdoor attack on a DNN model for lane detection in the physical world. There are several challenges in achieving this goal. First, existing work mainly focuses on backdoor attacks in the digital world, where an attacker can arbitrarily manipulate input samples to add triggers (e.g., change a block of pixels in an image). Due to the semantic gap between the digital and physical worlds, it is difficult to exploit these techniques to attack real-life applications. Some works subsequently implement physical backdoor attacks in the real world [6, 26, 40, 55, 64]. However, these methods mainly target face classification models. In contrast, lane detection models cannot predict labels, which increases the difficulty of toxic sample generation. Furthermore, the physical triggers used to attack the face classification model cannot be applied to lane detection due to the semantic differences between the two scenarios. Physical triggers need to be carefully redesigned.
Notes: 1. Existing work focuses on backdoor attacks in the digital world; 2. Due to the gap between the digital world and the physical world, it is difficult to use these techniques to attack real-life applications; 3. Some work was subsequently performed in the real world Implement physical backdoor attacks; 4. However, these methods are mainly aimed at face classification models, and lane detection models are not applicable.
Second, to make the backdoor more covert, past work proposed clean-label attacks against classification models, where poisoned samples still have the correct labels, thus compromising the model [43, 66]. This is achieved by adding adversarial perturbations to change the class of these poisoned samples. Since lane detection models cannot predict classes, it is difficult to leverage these solutions to generate visually normal poisoning samples.
Third, existing backdoor attacks only target specific deep learning algorithms (such as classification) when poisoning data samples. However, this does not apply to lane detection scenarios, which can use different algorithms to train the model, such as segmentation-based [35] or anchor-based [46] methods. Generating uniform poisoning samples is a challenging task that can attack any lane detection model regardless of its algorithm.
Note: Existing backdoor attacks only target specific deep learning algorithms, such as classification algorithms, when poisoning data samples. In lane detection scenarios, different algorithms (such as segmentation-based lane detection, anchor-based lane detection) can be used to train models, so generating uniform poisoned samples is a challenging task.
Our proposed attack can address the above challenges with some innovations. First, we propose a new design of semantic triggers in autonomous driving environments. After studying some mainstream traffic datasets, we selected a set of two traffic cones with specific shapes and locations as triggers to trigger the backdoor. This trigger looks natural in a road environment and is hardly noticeable. At the same time, it is unique enough that it will not affect the normal situation of autonomous driving. Second, we introduce two new methods to poison training samples and manipulate annotations to achieve backdoor embedding. (1) Poison-annotation attack: An attacker can create poisonous samples by deliberately misannotating the samples with triggers. (2) Clean-annotation attack: This technology uses the image scaling vulnerability [56] to hide the anomalies of malicious samples. Specifically, we create toxic samples that are visually similar to clean samples, have correct annotations, and have no triggers. After image scaling, these samples give false lane boundaries and a trigger point, becoming an effective means of backdoor embedding. Both methods are algorithm-agnostic: poisoning the dataset does not require knowledge of the algorithm used, and the results show that poisoning samples is effective for different models and algorithms. This greatly increases the power and applicability of the attack.
Notes: 1. Create poisonous samples (visually similar to clean samples, with correct annotation, no triggers); 2. After image scaling, these samples give wrong lane boundaries and a trigger point, becoming the backdoor embedded effective means.
We implement backdoor attacks on four modern lane detection models . Evaluation on public datasets shows that our attack can achieve a success rate of around 96% while injecting less than 3% of poisoned data. Using two unmanned vehicles (Figure 1(a)) to run an off-the-shelf autonomous driving software system in a physical environment further verified the effectiveness and robustness of the attack. As shown in Figure 1(b), the compromise model causes the vehicle to drive across the lane and eventually hit the bushes on the roadside. This demonstrates the seriousness and practicality of the proposed attack, and this new attack vector should also be carefully considered when designing robust autonomous driving models.

Picture description: Figure 1 shows the test platform and test results of this article: Figure (a) is the Baidu Apollo D-Kit self-driving vehicle equipped with a Leopard camera; Figure (b) is the Weston unmanned vehicle equipped with a RealSense D435i camera Ground vehicles; Figure (c) shows the effects of two physical attacks. The picture on the left is the boundary between the original picture and the real road (Ground True); the picture in the middle is the error detection result under the poison-annotation attack ; the right picture is the error detection result under the clean-annotation attack .
In summary, we made the following contributions:
- Designed the first backdoor attack on lane detection systems in autonomous driving.
- Implemented the first physical backdoor attack on non-classified models. algorithm-agnostic attack.
- Proposed the first physical clean-annotation backdoor attack.
- Extensive evaluations are performed on datasets and physical self-driving cars to demonstrate the importance of the attack.
2.Background
2.1.DNN-based Lane Detection
Focused research on end-to-end DNN-based lane detection systems as victims of backdoor attacks. This is an important feature in modern autonomous vehicles, based on image recognition of the lane captured by the front camera. In order to achieve higher accuracy and efficiency, different categories of detection methods have been proposed, which are summarized as follows.
- Segmentation-based methods [35]: These are the most popular lane detection techniques with significant performance in different lane detection challenges. They treat lane detection as a segmentation task and estimate whether each pixel is on the lane boundary. They have been commercialized in many self-driving car products, such as Baidu Apollo [2].
- Row-wise classification methods [17, 36]: These solutions use multi-class classification algorithms to predict lane locations for each row and determine the locations most likely to contain lane boundary markers. They can reduce computational costs, but can only detect fixed lanes (note the limitations of this scheme).
- Polynomial-based methods [47]: These lightweight methods generate polynomials to represent lane boundaries through deep polynomial regression. They can meet real-time requirements, but there is a certain decrease in accuracy. This algorithm has been deployed in OpenPilot [8].
- Anchor-based methods [46]. These solutions leverage object detection models (e.g., Faster R-CNN) and domain knowledge of lane boundary shapes to predict lanes. They can achieve comparable performance to segmentation-based methods.
Past work has demonstrated the vulnerability of these lane detection models to adversarial examples [23, 42]. In this paper, we show that they are also vulnerable to backdoor attacks. The goal of our attack is to generate a poisonous dataset such that any lane detection model trained from it will be infected by the backdoor, regardless of detection method. (It has nothing to do with the detection method. In other words, no detection method can escape this attack)
2.2.Backdoor Attacks
In a backdoor attack, the attacker attempts to subvert the victim DNN model, which maintains correct predictions for normal samples but mispredicts any input sample containing a specific trigger [32]. The most common attack method is to poison a small portion of training samples to embed a backdoor into the model during training [6]. Over the years, a large number of methods have been proposed to enhance [28] attack effectiveness, concealment and application scope, such as stealth [27], semantic [3], reflection [33] and compound [29] backdoor attacks.
- Physical backdoor attacks: Compared with digital attacks, there are relatively few studies on physical backdoor attacks. Most research focuses on face classification models in the real world [6, 26, 40, 55, 64]. However, there is currently no research on physical backdoor attacks against non-classified models. We aim to fill this gap by targeting lane detection systems.
- Backdoor defenses: In addition to backdoor attacks, various defense solutions have also been proposed. They can generally be divided into three categories. (1)Rear door removed. These defenses are designed to eliminate backdoors in compromised models. For example, [30] model pruning technique was proposed, which extends the model pruning technique to prune neurons according to their average activation value. (2) Trigger reconstruction. These methods aim to detect whether the model contains backdoors and reconstruct the triggers. A typical example is Neural Purification [52], which optimizes the triggers for each class and then calculates an anomaly index to determine whether the model is compromised. (3) Abnormal sample detection. This type of solution attempts to identify whether the inferred sample contains a trigger. STRIP [11] superimposes some clean images on the target image respectively and inputs them into the model for prediction. The small randomness in the prediction results indicates that the backdoor has a higher probability of being activated by the image. The backdoor attack we designed is robust and immune to different types of defense methods, as shown in Section 4.4.
2.3.Threat Model
Autonomous driving developers usually use third-party annotation services to annotate their data samples [20]. Therefore, it is easy for a malicious data vendor or annotation service provider to poison a dataset, leading to a backdoor attack. The Intelligence Advanced Research Projects Activity (IARPA) organization has highlighted this threat and the importance of protecting autonomous driving systems from backdoor attacks [19].
Based on this backdoor threat model, we assume that attackers can only inject a small subset of malicious samples into the training set. We will design a clean annotation attack where, without any triggers, the poisoned samples visually look like normal samples and are correctly annotated, making the poisoning more stealthy.
The adversary has no control over the model training process. More importantly, we consider the algorithm-independent requirement: the adversary does not know the algorithm that the victim will use to train the lane detection model. Previous work rarely considers this requirement, usually assuming that the adversary knows the model architecture family, the algorithm, or at least the task.
The adversary's goal is to mislead the model into incorrectly identifying traffic lane boundaries for physical triggers on the road, for example, identifying a left-turn lane as a right-turn lane. In a self-driving environment, this could lead to serious safety issues, with the vehicle potentially running off the road or colliding with a vehicle in the oncoming lane.
2.4.Image Scaling
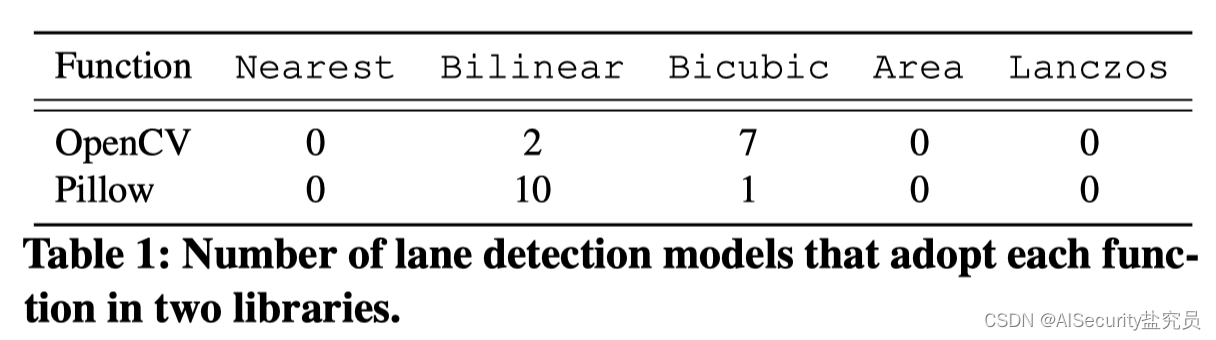
Image scaling is a standard step in preprocessing deep neural network models. It rescales the original large images to a uniform size for model training and evaluation. Mainstream computer vision libraries (such as OpenCV[4], Pillow[7]) provide a variety of image scaling functions, as shown in Table 1.
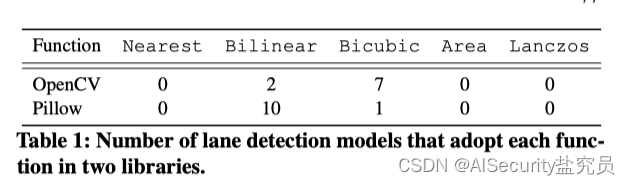
State-of-the-art lane detection models also employ these scaling functions to preprocess inference images. We studied all 21 open source lane detection models in the TuSimple Challenge [51] and found that most models use two common scaling functions (bilinear and bicubic) in Table 11. Adopting an image scaling function can introduce new attack vectors for attackers to deceive the model [56]. In this paper, we also take advantage of this opportunity to design a new clean annotation attack (Section 3.3).
3.Methodology
3.1.Physical Trigger Design
Existing digital backdoor attacks often exploit pixels as triggers, which are difficult to implement in the physical world. It is more reasonable to use physical objects as triggers to activate backdoors. However, in lane detection scenarios, choosing a qualified physical object is a very important thing. On the one hand, it has to look natural in a road environment. On the other hand, it must be unique and have a very low probability of occurring under normal circumstances.
We choose a set of two traffic cones as triggers, as shown in Figure 2. Traffic cones are very common on the road and are not considered malicious by model developers during model training or by passengers in operating vehicles. To ensure that this trigger is unique, we specify its shape and location. In shape, two cones are placed close together, one upright and the other fallen. For position, we place two cones on adjacent lanes close to the boundary.

The back door can only be activated if the two traffic cones meet both the shape and location requirements. We examined normal road conditions in commonly used traffic datasets and found no such triggering pattern. Attackers can design their triggers with other options, such as using more cones in different poses and positions.
To poison the training set, the attacker first selects a small subset of normal images from the original dataset. He then inserted physical triggers into the desired locations on these selected images 【理解:我个人理解的就是P上去的】. For each image, he needed to adjust the size and relative distance of the triggers based on the camera configuration. To attack the backdoor model, an attacker could simply place two actual traffic cones on the road as designed. The backdoor in the lane detection model will then be activated when the vehicle maintains a certain distance from the cone 【注意看激活的方式,是椎体和车辆在一定距离时被激活】.
We provide two methods for attackers to manipulate the annotations that trigger samples, as described below.
3.2.Poison-Annotation Attack
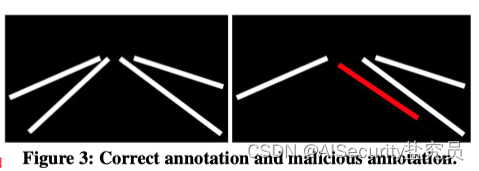
Our first technique is an annotation poisoning attack, where an attacker deliberately incorrectly annotates poisonous images containing triggers 【理解:车道线检测的图片不修改,修改车道线图片对应的annotation文件(注释文件)】. As shown in Figure 3, an adversary can modify the lane boundary to the wrong direction. Learning from these poisonous samples, the model will instruct the vehicle to cross the actual boundary and drive into the left lane, which is the desired outcome of the adversary.
3.3.Clean-Annotation Attack
Toxic data with incorrect annotations may be recognized by humans. Therefore, the above attack only works if the model developer does not have the ability to manually inspect the training samples (e.g., the training set is too large). To further hide these samples, we propose a new Clean-Annotation Attack technique, in which toxic images are correctly annotated (i.e., lane boundaries visually match the annotations).
Past research has introduced clean label backdoor attacks against classification models [43, 66]. However, we find them to be incompatible with our lane detection scenario as they add imperceptible perturbations on the poisoned samples to change their predicted classes, which does not exist in non-classification tasks. Instead, we exploit an image scaling vulnerability to implement a clean annotation attack. Image scaling is an indispensable technique in data preprocessing for all deep neural network models. However, [56] found that this process generates new adversarial attacks: the attacker can modify the original image unnoticed and downscale it into the desired adversarial image. [39] further adopted this technology to implement clean label backdoor attacks on classification models. Inspired by this vulnerability, our clean-annotation attack modifies poisoned samples with imperceptible perturbations that still have correct annotations. During the model training process, these samples are mislabeled after image scaling, allowing the desired backdoor to be embedded into the model. Figure 4 shows an overview of our proposed attack.
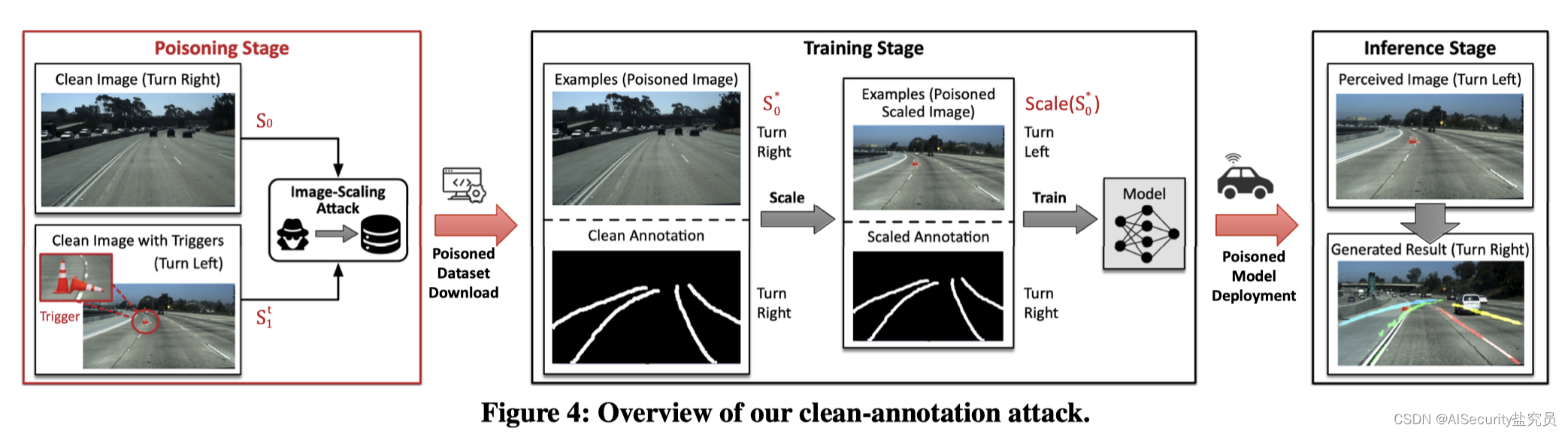
We assume that the target lane detection model MMM adopts the image scaling function scale (see Table 1). Our goal is to start from a clean samples 0 s_0s0Toxic sample s 0 ∗ s_0^* is generated ins0∗, s 0 ∗ s_0^* s0∗Visually with s 0 s_0s0Indistinguishable. However, after using image scaling, scale ( s 0 ∗ ) scale(s_0^*)scale(s0∗) becomes a malicious sample. It should be noted that unlike existing image scaling attacks that rely on explicit labels [39, 56], there are no target labels in our lane detection scenario, and the goal of our attack is to mislead the vehicle to deviate from the original direction as much as possible. Therefore, our strategy is to givescale ( s 0 ∗ ) scale(s_0^*)scale(s0∗) ands 0 ∗ s_0^*s0∗Completely different lane. To achieve this we find another clean example s 1 s_1s1, whose annotations point in the opposite direction. Specifically GT ( s 0 ) GT(s_0)GT(s0) is a right turn, andGT ( s 1 ) GT(s_1)GT(s1) is a left turn (as shown in Figure 4). We then add the flip-flop tos 1 s_1s1Get the sample with trigger s 1 t s_1^ts1t. Our goal is to go from s 0 s_0s0Find a perturbed sample s 0 ∗ s_0^* ins0∗, becomes s 1 t s_1^t after using image scalings1t, which can be solved with the following goals:
Understand:
Goal: from clean sample s 0 s_0s0Find a perturbed sample s 0 ∗ s_0^* ins0∗, poisoned sample s 0 ∗ s_0^*s0∗After using the image scaling function, it becomes a malicious sample.
s 0 s_0s0It is clean data and it is a right turn; s 1 s_1s1It is clean data and it is a left turn; s 1 t s_1^ts1tis a sample with a trigger.
arg min s 0 ∗ ( ∥ s 0 ∗ − s 0 ∥ 2 + ∥ scale ( s 0 ∗ ) − s 1 t ∥ 2 ) \arg \min _{s_{0}^{*}}\left(\left\|s_{0}^{*}-s_{0}\right\|_{2}+\left\|\operatorname{scale}\left(s_{0}^{*}\right)-s_{1}^{t}\right\|_{2}\right) args0∗min(∥s0∗−s0∥2+ scale(s0∗)−s1t 2)
As shown in Figure 4, to activate the backdoor during inference, the attacker only needs to place a physical trigger at a designated location. An input image with a trigger (for example, a left turn lane) will also go through a scale function, which does not change the content, but does change the size. The backdoor model will then identify the trigger and give an incorrect prediction (e.g., turn right), which can lead to serious security issues.
- Discussion: It is worth noting that in order to solve Equation 3, the attacker needs to know the scaling function in the victim model. This is not difficult to achieve under our threat model: as shown in Table 1, there are a limited number of commonly used candidate functions for image scaling. An attacker can generate corresponding poisonous samples for each function and insert them all into the training set. At least some samples will contribute to backdoor embedding that are crafted with matching scaling functions, while other samples will have no impact on attack effectiveness or model performance. Another point is that during the training phase, the annotations will be poisoned after passing through the image scaling function, and it is possible for the defender to manually identify poisoned samples by inspecting the scaled images. However, it is common to integrate image scaling and ML model training into a single pipeline, which is consistent with all existing state-of-the-art lane boundary detection methods [1]. For data annotation service providers, it is more practical to inspect the raw data in reality than to inspect the intermediate results in the training pipeline. Therefore, our proposed attack is more subtle than the poison annotation attack.
4.Evaluation
- Model and dataset: We conduct extensive experiments to verify the effectiveness of our backdoor attack on state-of-the-art lane detection models. Our attack is powerful and general for different types of lane detection algorithms. Without loss of generality, we selected four representative methods from different categories:
- SCNN [35] is a segmentation-based method that uses a sequential message passing scheme to understand traffic scenes. The input image size of this model is 512 × 288. OpenCV's default image scaling function is Bicubic.
- LaneATT [46] is an anchor-based method that uses an attention mechanism to aggregate global information for lane detection. Its input size is 640×360. They also used the Bicubic function in OpenCV to resize the input image.
- UltraFast [36] is a classification-based method that uses row-based selection to achieve fast channel detection. The input size is 800 × 288. Input images are preprocessed through the Bilinear function in Pillow.
- PolyLaneNet [47] is a polynomial-based method that utilizes deep polynomial regression to output polynomials representing each lane marking. Each input image is Bicubic scaled to a size of 320 × 180 in OpenCV.
We adopt the Tusimple Challenge dataset [51] to generate the poisoning training set. It contains 6408 video clips, each video clip consists of 20 frames, and only the last frame is annotated. Therefore, it has 3626 images for training, 410 images for validation and 2782 images for testing. All our experiments were conducted on a server equipped with an NVIDIA GeForce 2080Ti GPU with 11G of memory.
- Metrics: In classification-based tasks, the performance of backdoor attacks is usually measured by Benign Accuracy (BA) and Attack Success Rate (ASR) calculated based on classification accuracy [14, 28]. BA and ASR are used to measure the accuracy of the backdoor model on clean data and the misclassification rate of trigger data respectively. However, these metrics may not be suitable for evaluating the performance of backdoor attacks in lane detection tasks, where the model output of an image is a set of consecutive points. Although we can calculate the ASR by calculating the intersection of the output point set and the ground truth [51], this does not reflect the actual attack effect unbiasedly (i.e. two identical ASRs may exhibit very different actual attack effects). Therefore, we propose using rotation angle as a new metric to quantify attack performance.
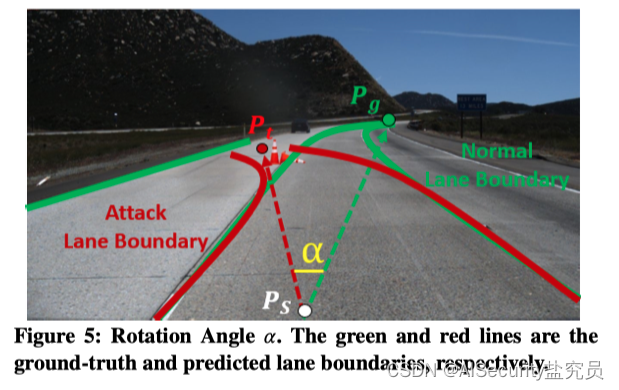
This metric is defined as the angle between the ground truth and the predicted motion direction. As shown in Table 5, assume that P s P_sPsis the current vehicle position, P g P_gPgand P t P_tPtare respectively the real destination and predicted destination of the vehicle in the current input frame ( P g P_gPgis the real destination, P t P_tPtis the predicted destination). What needs to be noted is: P g P_gPgand P t P_tPtare respectively defined as the centers of the corresponding two lane boundary endpoints in the true value and predicted value. Therefore, the angle of rotation is defined as α \alphaα , define the function:
α = arccos P s P g → ⋅ P s P t → ∥ P s P g → ∥ 2 ∥ P s P t → ∥ 2 \alpha=\arccos \frac{\overrightarrow{P_{ s} P_{g}} \cdot \overrightarrow{P_{s} P_{t}}}{\left\|\overrightarrow{P_{s} P_{g}}\right\|_{2}\left\ |\overrightarrow{P_{s}P_{t}}\right\|_{2}}a=arccos PsPg 2 PsPt 2PsPg⋅PsPt
Given such a metric, a qualified attack method should make the rotation angle α \alphaα tends to zero in clean samples, but in the face of backdoor attacks (rotation angleα \alphaα ) as large as possible.
4.1.Poison-Annotation Attack
- Configuration: We randomly select different numbers of images (i.e. 0, 20, 40, 60, 80 and 100) from the poisoned training set. We inject physical triggers into each image and manipulate its lane annotations. Then the poisoned set is used to train lane detection models of different algorithms. For each algorithm, we adopt its default configuration (e.g., network architecture, hyperparameters). Each model is evaluated on two sets, one containing 50 clean images and the other containing 50 corresponding trigger images.
- Results: Figure 6 shows an example of lane detection using different backdoor models on the TuSimple dataset. We observed that due to the presence of physical triggers, the lanes detected by the 4 backdoor models changed with the ground-truth annotation by the rotation angle α \alphaα are 39◦, 35◦, 33◦, and 31◦ respectively. Therefore, the detection result will cause the vehicle to change left to another lane. More visual results for different algorithms and configurations can be found in the appendix.

In order to quantitatively display the attack effect, Table 2 shows the average rotation angle α \alpha of different backdoor models on clean samples under different poisoning ratios.α . As can be seen from the table, on clean samples, the impact of poison-annotation attacks on prediction performance is not significant. Table 3 shows the average rotation angles of 4 different backdoor models on poisoned images. As can be seen from Table 3, compared with the benign model, the rotation angle of the backdoor model increases significantly on toxic images. The results show that this trigger can effectively activate the backdoor, causing the model to incorrectly detect lane boundaries and predict the wrong destination location. The greater the poisoning ratio, the greater the angle rotation. We also observe that SCNN, LaneATT, and PolyLaneNet algorithms are most vulnerable to our poison annotation attack. The average rotation angles of the three rear door models are 23.1, 25.7, and 24.0 respectively. In comparison, UltraFast's attack efficiency is lower, with a rotation angle of 18.5°, but it can still effectively affect the driving direction and may cause a car accident.
4.2.Clean-Annotation Attack
- Configuration: We consider two attack targets: (1) L2R: the left-turn lane is identified as the right-turn lane; (2) R2L: the right-turn lane is identified as the left-turn lane. For both attacks, we manually select 100 left-turn and 100 right-turn images from the training set and generate corresponding cleanly annotated poisonous images to replace the original images. Each model is evaluated on two test sets, one containing 50 clean images and the other containing the corresponding 50 triggered images.
- Results: Figure 7 shows examples of lane detection results of the four models under L2R and R2L attacks respectively. We can observe the presence of a trigger that causes the backdoor model to detect the wrong direction lane.
For quantitative evaluation, Table 4 shows the average rotation angles of benign and backdoor models relative to clean samples. We can find that the average rotation angle does not change significantly between the benign model and the backdoor model. Therefore, backdoor models do not degrade detection performance on clean data. Table 5 shows the average rotation angles of the four backdoor models on the trigger samples. For poisonous annotation attacks, we reach the same conclusion that backdoor models produce greater bias than benign models. We also observe larger rotation angles for clean annotation attacks on SCNN and UltraFast. Likewise, such an angle can clearly indicate a change in driving direction. We have examined all test images and confirmed the effectiveness of the attack on most samples. This shows that clean labeling attack is an effective attack method. Based on the above results, we can also conclude that our rotation angle metric can be used to evaluate the performance of backdoor attacks in lane detection tasks. It can significantly differentiate attack predictions from normal results.
4.3.Real-world Evaluation
To demonstrate the practicality of our backdoor attack, we evaluated the attack on a Weston UGV equipped with a RealSense D435i camera (Figure 1 (a)) and a Baidu Apollo vehicle equipped with a Leopard camera (Figure 1 (b)), and tested them on real roads. Tested on.
- Different models: Figure 8 shows the real road prediction results of the four models under poison-annotation attack. Experimental results also prove that our poison annotation attack is effective and practical in the real world. Figure 9 shows the visualization results of the model under clean-annotation attack using different settings in the physical world. We can observe that the attack effectively breaks the model under different triggers and camera distances.
- Different scenarios and test platforms: We also conducted the attack under different scenarios and test platforms (Apollo and UGV). We chose a parking lot and an ordinary road area as our experimental sites. Figure 10 shows the results, showing that the clean-annotation attack is successful in a real lane detection scenario. Due to the physical trigger, the UGV recognizes a right turn as a left turn. Then turn left and hit a tree on the side of the road. Demonstration videos of both attacks using different test platforms can be found at https://sites.google.com/view/lane-detection-attack/lda . In summary, actual experiments show that our attack has high generalization, effectiveness and practicality.
4.4.Bypassing Existing Defenses
Our attacks are stealthy and can evade state-of-the-art backdoor defenses. To verify this, we considered and evaluated different types of popular solutions. Various defenses are specifically designed for classification tasks. For example, Neural cleanup [52] requires defenders to specify target classes for backdoor scanning. STRIP [11] checks the predicted class of trigger samples superimposed with clean samples. Since the lane detection model has no classes, these solutions are not suitable for our attack. Instead, we evaluate two other common defense strategies.
- Fine-Pruning[30]: This method eliminates backdoors through model pruning and fine-tuning. It first prunes neurons with smaller average activation values, and then fine-tunes the pruned model. In the appendix, we demonstrate the defensive effectiveness of our clean-annotation attack on SCNN. We observe that when we prune a small number of neurons, the backdoor model remains effective on maliciously triggered samples. When more neurons are pruned, the performance of the model decreases significantly, both for clean and triggered samples. Therefore, fine-tuning does not remove our backdoor. Similar conclusions regarding poison annotation attacks are given in the appendix.
- Median filtering [38] (Median Filtering): This method utilizes median filter to defeat image scaling adversarial attacks. It attempts to reconstruct the image and remove potentially hostile noise. We apply this technique to clean annotation attacks. Figure 11 in the appendix shows an example defense including clean, triggered, and recovered images. We observe that the recovered image is still different from the clean image and is still a physical trigger to activate the backdoor.