1. MYSQL FAQs
1. Why does the database have transactions? In order to ensure the ultimate consistency of the data.
2. What characteristics does a transaction include? Atomicity, isolation, consistency, and durability .
3. What problems does the concurrency of transactions cause? Transaction concurrency can cause dirty writes, dirty reads, repeated reads, and phantom reads .
4. How to solve the problem of transaction concurrency? Carry out transaction isolation and set different transaction isolation levels ( read uncommitted, read committed, repeated read, serialization ) for different concurrency issues.
5. How does the database ensure transaction isolation? Transaction isolation is achieved through locking.
6. What problems will frequent locking cause? There is no way to modify the data when reading it, and it cannot read it when modifying the data, which greatly reduces the database reading and writing performance.
7. How does the database solve the performance problem after locking? MVCC multi-version control allows data to be read without locking and can be modified while reading the data. The data can be read at the same time when modifying it.
2. Database Basics - ACID of Transactions
1. The concept of atomicity :
A transaction must be the smallest unit of a series of operations. During this series of operations, it is either executed as a whole or rolled back. There is no possibility that only one or a few steps are executed.
2. Isolation concept
: Isolation means that the execution of two transactions are independently isolated. The transactions will not affect each other before. When multiple transactions operate on an object, they will wait serially to ensure that the transactions interact with each other. are isolated.
3. Consistency concept
: Transactions must ensure the integrity of the overall data in the database and the consistency of business data. If a transaction successfully submits the overall data modification, if a transaction error occurs, the data will be rolled back to its original state.
4. D (Durability) : Concept
: Durability means that once a transaction is successfully submitted, as long as the modified data will be persisted (usually the data is successfully saved to the disk), the data will not be damaged due to exceptions or downtime. Wrong or missing.
3. Data base library - transaction concurrency (dirty read, non-repeatable read, phantom read) and transaction isolation
When transactions are executed concurrently, if transactions are not isolated, problems such as dirty writes, dirty reads, repeated reads, and phantom reads will occur.
1. Dirty writing problem
1)概念:在事务并发的时候,一个事务可以修改另外一个正在进行中的事务的数据,
这可能会导致一个写的事务会覆盖另外一个写的事务数据,这也就是脏写问题。
2)如何解决脏写问题:在事务隔离级别READ_UNCOMMITTED 解决了脏写的问题,
其原理是在READ_UNCOMMITTED事务隔离级别下,当事务对数据进行修改时,首先会对数据加写锁,
加写锁成功后只有等事务提交或者回滚后才会释放,所以已经有一个事务对数据加了写锁,
那么其他事务就会因为无法获取对应数据的锁而阻塞,所以在READ_UNCOMMITTED事务隔离级别下,
多个事务是无法对同一个数据同时进行修改。
2. Dirty read problem
1)在事务并发的时候,一个事务可以读取到另外一个正在进行中的事务数据,这产生了脏读问题。
2)如何解决脏读问题:在事务隔离级别READ_COMMITTED(读提交)解决了脏读的问题,
其原理是在READ_COMMITTED的事务隔离级别下,当事务对数据进行修改时,得先要对数据加写锁,
当事务读取数据时,首先需要对数据加读锁。 因为写锁与读锁不能共存,所以在修改数据的时候,
其它事务会因为无法成功加读锁而阻塞,所以READ_COMMITTED 的事务隔离级别下,
一个事务就无法读取另外一个未完成的事务所修改的数据了。
3. Non-repeatable reading problem
1)在事务并发的时候,一个事务里多次对同一个数据进行读取,但是读取到的结果是不一样的,
这种问题称为不可重复读问题。
2)如何解决不可重复读:
不可重复读产生的核心问题是,一个事务范围内的第1次读取和第2次读取数据的间隔过程中可以被
另外一个事务修改,因为在READ_COMMITTED的事务隔离级别下,事务中每次读取数据结束后(事务未结束)
就会释放读锁,而一旦读锁释放后另外一个事务就可以加写锁,最终导致事务中多次读取该数据的间隙中
可以被其它事务修改。
而REPEATABLE_READ (可重复读)的事务隔离级别下,一个事务中的读取操作会对数据加读锁
(并且在当前事务结束之前不会释放),此时另外一个事务对该数据修改之前会尝试加写锁
(此时不会成功,因为读写锁冲突),所以就避免了一个事务多次读取的数据的间隔可以被另外一个事务修改。
4. The problem of phantom reading
1)在事务并发的时候,一个事务可以往另外一个正在读取的事务查询范围内插入新数据,导致另外一个事务
在第二次查询数据里,要比前一次查询的数据要多,同样的SQL后面一次查询凭空多出了数据,
像幻觉一样所以称为幻读。
2)解决幻读的两种方式
1、设置事务隔离级别为SERIALIZABLE
在SERIALIZABLE事务隔离级别下,所有的事务都串行化执行,一个事务的执行必须等前面的事务结束,
这样的话查询的时候就无法有其他事务查询新的数据,所以不会产生幻读问题。
2、加间隙锁
幻读问题的本质在于,没有对查询范围内的所有数据(包括不存在的数据)进行加锁,
而导致该查询范围内可以被插入新的数据,所以使用间隙锁,对查询的范围进行加锁,
此时新插入的数据的事务会因为无法加锁成功而阻塞,所以就避免了幻读。
比如:执行select * from user where id>2 时 ,间隙锁会对id>2的空间加锁,所以此时我们另外一个事务插入ID为3 、4、6、7....... 都会因为锁阻塞而无法成功。
Summarize
为解决不同场景的并发事务问题,事务定义了四种隔离级别,每个隔离级别都针对事务并发问题中的一种或几种
进行解决,事务级别越高,解决的并发事务问题也就越多,同时也意味着加的锁就越多,所以性能也会越差。
Their locking situations under different isolation levels are as follows:
1) READ_UNCOMMITTED
Transaction reading: no locking
Transaction writing: adding write lock
Solving the problem: dirty writing
Existing problems: dirty reading, non-repeatable reading, phantom reading.
2) READ_COMMITTED
transaction reading: add read lock (the read lock will be released every time select is completed)
transaction writing: add write lock.
Problem solved: dirty write, dirty read.
Problems: non-repeatable read, phantom read.
3) REPEATABLE_READ
transaction reading: Add a read lock (the lock will not be released after each selection, but will be released after the transaction is completed) (if it is Mysql's innodb, a gap lock will also be added).
Transaction writing: add write lock.
Solve the problem: dirty write, dirty read, non-repeatable read, phantom read (if it is Mysql's innodb, it has been solved).
There is a problem: phantom read (if it is Mysql's innodb, it does not exist).
4) SERIALIZABLE
executes all transactions serially regardless of whether they are read or modified. The execution of one transaction must wait for the completion of other transactions.
4. Database basics - locks in Mysql
(1) What are pessimistic locks and optimistic locks?
1. What is pessimistic lock ?
悲观锁是基于一种悲观的态度类来防止一切数据冲突,它是以一种预防的姿态在修改数据之前把数据锁住,
然后再对数据进行读写,在它释放锁之前任何人都不能对其数据进行操作。
1)特点:可以完全保证数据的独占性和正确性,因为每次请求都会先对数据进行加锁,
然后进行数据操作,最后再解锁,而加锁释放锁的过程会造成消耗,所以性能不高;
2)手动加悲观锁:读锁LOCK tables test_db read释放锁UNLOCK TABLES;
3)写锁:LOCK tables test_db WRITE释放锁UNLOCK TABLES;
2. What is optimistic locking ?
乐观锁是对于数据冲突保持一种乐观态度,操作数据时不会对操作的数据进行加锁
(这使得多个任务可以并行的对数据进行操作),只有到数据提交的时候才通过一种机制来验证数据是否存在
冲突(一般实现方式是通过加版本号然后进行版本号的对比方式实现);
1)特点:乐观锁是一种并发类型的锁,其本身不对数据进行加锁通而是通过业务实现锁的功能,
不对数据进行加锁就意味着允许多个请求同时访问数据,同时也省掉了对数据加锁和解锁的过程,
这种方式因为节省了悲观锁加锁的操作,所以可以一定程度的的提高操作的性能,不过在并发非常高的情况下,
会导致大量的请求冲突,冲突导致大部分操作无功而返而浪费资源,所以在高并发的场景下,乐观锁的性能
却反而不如悲观锁。
2)乐观锁并不会真的加锁,而是通过一些状态的检验达到操作互斥的效果,比如说会对比操作前与当前数据的
版本号,状态标记是否一致。
(2) Lock
In Mysql, the index is implemented based on the B+ tree data structure. All data in the B+ tree index are stored in leaf nodes, and the data is arranged in order.
B+树以下特点:
1)在 B+ 树中,所有数据记录节点都是按照键值的大小存放在同一层的叶子节点上,
而非叶子结点只存储key的信息,这样可以大大减少每个节点的存储的key的数量,降低B+ 树的高度;
2)B+ 树叶子节点的关键字从小到大有序排列,左边结尾数据都会保存右边节点开始数据的指针;
3)B+ 树的层级更少:相较于 B 树 B+ 每个非叶子节点存储的关键字数更多,树的层级更少所以查询数据更快;
4)B+ 树查询速度更稳定:B+ 所有关键字数据地址都存在叶子节点上,所以每次查找的次数都相同所以查询速度要比B树更稳定;
5)B+ 树天然具备排序功能:B+ 树所有的叶子节点数据构成了一个有序链表,在查询大小区间的数据时候更方便,数据紧密性很高,缓存的命中率也会比B树高;
6)B+ 树全节点遍历更快:B+ 树遍历整棵树只需要遍历所有的叶子节点即可,,而不需要像 B 树一样需要对每一层进行遍历,这有利于数据库做全表扫描。
查询更稳定:因为B+所有数据值都是存在叶子节点上,所以每次查找的次数都相同所以查询速度要比B树更稳定;
遍历整个树更快:B+树遍历整棵树只需要遍历所有的叶子节点即可,而不需要像B树一样需要对每一层进行遍历,这有利于数据库做全表扫描。
B+树叶子节点的关键字从小到大有序排列,左边结尾数据都会保存右边节点开始数据的指针。
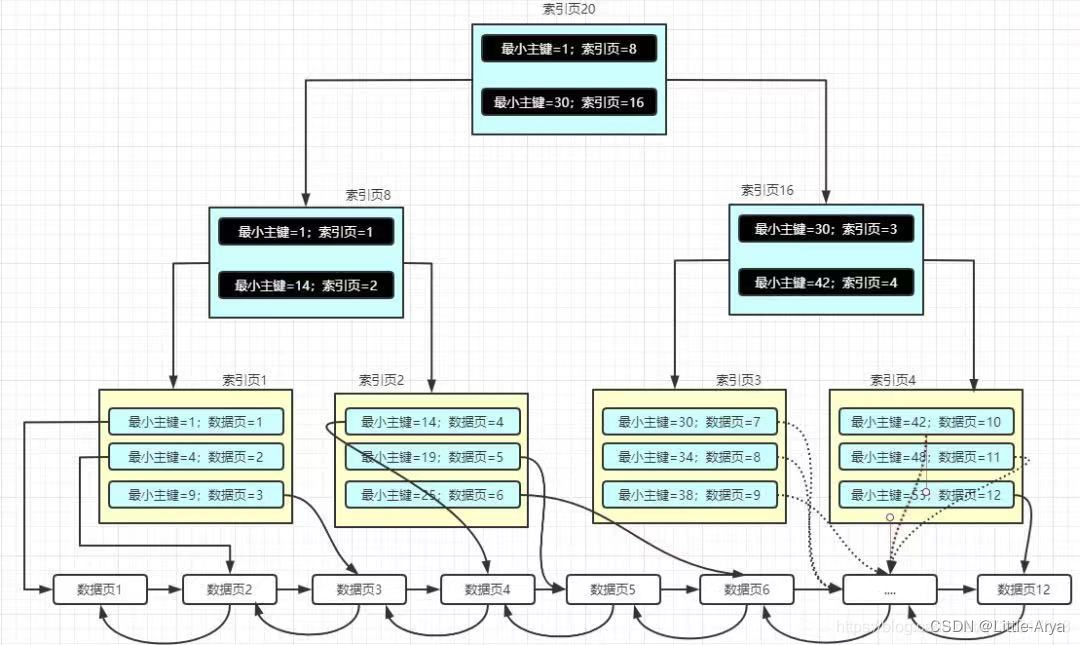
A B+ tree index built with the primary key as the key value of the B+ tree index is called a clustered index ;
a B+ tree index built with column values other than the primary key as the key value is called a non-clustered index .
The locks in the database are based on indexes. In Innodb, our locks are all applied to the index. When our SQL hits the index, the index node (row lock) within the hit condition is locked. If there is no If the index is hit, then what we lock is the entire index tree (table lock).
1)基于锁的属性分类:共享锁(又称读锁)、排他锁(又称写锁,排他锁不能与任何属性的锁兼容)。
ps:当有事务对数据加读锁后,其他事务只能对锁定的数据加读锁,不能加写锁(排他锁),所以其他事务只能读,不能写。
2)基于锁的粒度分类:表锁(锁住的是整个表)、 行锁 (记录锁(一条记录)、间隙锁(某一个区间)、临键锁(临键锁会把查询出来的记录锁住,同时也会把该范围查询内的所有间隙空间也会锁住,再之它会把相邻的下一个区间也会锁住,遵循左开右闭原则))。
3)基于锁的状态分类:意向共享锁、意向排它锁。
意向共享锁: 当一个事务试图对整个表进行加共享锁之前,首先需要获得这个表的意向共享锁。
意向排他锁: 当一个事务试图对整个表进行加排它锁之前,首先需要获得这个表的意向排它锁。
意向锁的概念:
如果当事务A加锁成功之后就设置一个状态告诉后面的人,已经有人对表里的行加了一个排他锁了,
你们不能对整个表加共享锁或排它锁了,那么后面需要对整个表加锁的人只需要获取这个状态就知道自己是不是
可以对表加锁,避免了对整个索引树的每个节点扫描是否加锁,而这个状态就是我们的意向锁。
【Innodb MVCC实现原理】https://zhuanlan.zhihu.com/p/52977862
5. Database basics - Mysql core log (redolog, undolog, binlog)
1、binlog
binlog 是作为mysql操作记录归档的日志,这个日志记录了所有对数据库的数据、表结构、索引等变更的操作。
在mysql里我们就是通过binlog来归档、验证、恢复、同步数据。
binlog 有三种记录格式,分别是ROW、STATEMENT、MIXED。
1)、ROW: 基于变更的数据行进行记录,如果一个update语句修改一百行数据,那么这种模式下就会
记录100行对应的记录日志。
2)、STATEMENT:基于SQL语句级别的记录日志,相对于ROW模式,STATEMENT模式下只会记录
这个update 的语句。所以此模式下会非常节省日志空间,也避免着大量的IO操作。
3)、MIXED: 混合模式,此模式是ROW模式和STATEMENT模式的混合体,一般的语句修改使用
statment格式保存binlog,如一些函数,statement无法完成主从复制的操作,则采用row格式保存binlog。
The atomicity and durability of transactions are guaranteed through redo log and undo log (logs belonging to the engine layer (innodb)).
The redo log ensures data durability when a transaction is successfully committed, and the undo log ensures that the transaction can be rolled back to ensure the atomicity of the transaction operation.
2、redo log
redo log 记录的是操作数据变更的日志,redo log记录的数据变更粒度和binlog的数据变更粒度是不一样的,
也正因为这个binlog是没有进行崩溃恢复事务数据的能力的。
redo log是记录着磁盘数据的变更日志,以磁盘的最小单位“页”来进行记录。
3、undo log:
在Mysql里数据每次修改前,都首先会把修改之前的数据作为历史保存一份到undo log里面的,
数据里面会记录操作该数据的事务ID,然后我们可以通过事务ID来对数据进行回滚。
When we execute update user_info set name = "李思" where id=1, the general process is as follows:
1. Read the record with id=1 from the disk and put it in the memory.
2. Record undo log.
3. Record redo log disk change records (pre-commit status)
4. Modify the records in memory.
5. Record binlog
6. Submit the transaction and write to redo log (commit status)
The database crashed at one of the above stages, how to recover the data.
1. The database crashes during the execution of the first, second and third steps: Because the data has not changed at this time, there is no impact and no operation is required.
2. The database crashes when the records in the memory are modified in steps 45: Because the transaction is not committed at this time, data rollback is required here, so data rollback will be performed through undo log.
3. The database crashes when executing the sixth step of transaction submission: If the database crashes at this stage, the transaction is actually not submitted successfully, but the data cannot be rolled back like before because the binlog may be successfully written before the transaction is submitted. into the disk, so the decision needs to be made based on two situations .
1) If there is a transaction record in the binlog : then the transaction is "considered" to have been submitted, and the data can be redone based on the redo log.
2) Another situation is that there is no transaction record in the binlog . In this case, the transaction has not been submitted successfully, so the data will be rolled back.
6. Database optimization
1. SQL performance analysis (execution plan)
Add an explain keyword before the SQL statement , then we will get a SQL execution plan;
the meaning of some attributes of the execution plan:
1), type (important)
type列是定位SQL性能因素最重要的一个指标,通过type我们可以直观的判断一个SQL的性能的基本情况,
type包括以下几种类型的查询system 、const 、eq_ref、ref、Range、Index、All,
他们的性能依次从高到底,简单来讲我们进行SQL优化的第一步就是要在type列上定位SQL的性能。
- System: 表只有一行记录(日常基本上不会出现)。
- Const: 通过索引一次就找到了数据,一般出现在使用了primary key或者unique索引匹配到了数据,
匹配的条件是常量(字符串、数字)。
- eq_ref: 使用了主键索引,或者非空唯一索引,在表中只有一条记录与索引键相匹配,匹配条件是某个表
的列(需要转义替换才能拿到值)。
- ref: 非唯一性索引扫描,和eq_ref 不同的是eq_ref 匹配的是唯一索引,ref它返回所有匹配某个单独值
的行,它可能会找到多个符合条件的行。
- range: 范围数据扫描。
- index: 全索引扫描,通过扫描整棵索引树获取到结果。
- All: 全表扫描。
The difference between const and eq_ref : both appear when a primary key index or a unique index is used. The difference is that the where condition of const is a constant, and the where condition of eq_ref is a column of other tables. This column needs to be processed. Only by escaping can you get the value of the matching condition, which can also be simply understood as eq_ref is generally a related query.
2)、possible_keys,key,key_len(重要)
possible_keys: 可能使用到的索引 。
Key: 实际使用的索引。如果为空,则说明没有使用索引。
key_len: 使用到的索引key的长度,如果为联合索引则显示已命中的联合索引长度之和(如:联合索引为a+b+c ,如果索引命中了a+b ,那么长度就为a+b的索引长度,通常可以通过key_len 来分析联合索引所命中的情况)。
关于possible_keys 和key的三种关系场景:
1)possible_keys !=null&& key!=null ,这是正常使用到了索引的情况。
2)possible_keys !=null&& key==null ,这种情况一般说明通过索引并不能提升多少效率,一般而言是表的数据量很少,或者是索引的字段离散性不高,执行计划发现用索引和扫表差不多。
3)possible_keys ==null&& key!=null , 这种情况一般为where条件没有命中索引,但是查询的列是索引字段,也就是查询的列命中覆盖索引情况。
3)
Which table column is the index actually used by ref? const represents a constant
4).
The number of data rows scanned by row. Generally speaking, the fewer the number of data rows scanned, the better the performance.
5), Extra column (important)
Extra can be said to be a general summary of the entire SQL, including what indexes, sorting methods, and temporary tables you used. It contains very important information that is not suitable for display in other columns.
using where : 使用了where条件。
using index: 使用了覆盖索引 (通常情况下这是一种好现象,意味着查询的数据直接在二级索引返回了,从而减少了回表的过程)。
using filesort : 文件排序,意思就是使用了非索引的字段进行排序(通常这种情况需要优化)。
using index sort : 使用索引排序 (通常情况下这是一种好现象,索引天然有序,所以避免了通过sort buffer来排序的流程)。
using temporary : 使用了临时表(常见于group by、order by)。
using join buffer : 使用了join buffer缓存(这种情况关注一下关联查询的字段是不是没有建索引)。
2. SQL optimization principles
1), leftmost matching principle
最左匹配原则是指,索引在进行模糊匹配时,必须最左边开始匹配。
1、最左匹配原则在Like语句中的体现。
like '186%' ,遵循最左匹配原则,可以用到索引;like '%186' ,这种情况是无法用到索引的。
2、最左匹配原则在组合索引中的体现。
不符合最左匹配规则:根据最左匹配原则,我们必须先匹配name 才能匹配到phone,再继续匹配age,所以只有phone和age的查询条件都不会命中索引的。
符合最左匹配规则:当使用了name条件则可以使用到组合索引。
When we use the hit combination index, how do we judge whether the combination index is all hit or only part of it? Here we judge by key_len in the execution plan.
2) Avoid implicit conversions
案例一:匹配的条件和索引类型为varcchar,匹配条件传的是数字。
案例二: 把函数用在了表的列上,再与条件进行匹配。
为什么隐式转换会导致索引失效?
因为索引的类型和匹配的条件类型不匹配,所以无法使用条件来与索引进行匹配,必须先把数据查询出来之后,
再进行类型转换,才能与条件进行条件匹配。
3) Use covering indexes as much as possible
简单来说就是我们的列数据只需要通过索引就可以获得数据,不需要从数据表中去遍历数据,
这种索引就已经覆盖了需要查询的列数据情况称为覆盖索引。
4) Try to ensure that the fields of join, order by, and group by use indexes.
1、如果join 的字段使用了索引,就会使用Index Nested-Loop Join 算法,这种算法是最高效的。
2、sort、group by 里都涉及到要对数据排序,如果使用了索引,因为Mysql的索引是B+树天然具备顺序的特性,所以可以避免把数据放到sort buffer排序的过程,提升SQL效率。
5) Control the granularity of transactions
控制事务的粒度核心思想就是减少对数据加锁的时间。 这样可以大大提升对数据修改的并发性能,
这方面我们可以从两个方向来入手从而减少锁的影响。
1、减少锁的范围:
innodb引擎锁的最小粒度为行锁,所以我们在修改数据的时候尽量保证只锁定相关的行,而我们知道只有条件
命中了索引才会使用行锁,否则就是使用表锁,那么我们在修改数据的时候就要尽量保证条件是使用的索引字段。
2、减小事务的粒度。
当我们在进行事务操作时,加锁是从语句执行开始,但是语句执行完后并不会马上释放对应的锁,
而是等整个事务提交之后才会释放所有的锁。
6) Get only the necessary columns
使用select * from 查询大量非必要的数据会导致如下情况:
1、数据库IO次数增加,数据库每次IO只会读取固定大小的数据,查询的数据越大,那么IO的次数也就越多。
2、消耗内存,数据读取数据是在内存里面做匹配筛选。
3、数据越大网络的传输速度就变慢,查询的数据要经过网络传输给应用程序。
4、无法合理的使用到覆盖索引。
5、影响sort、group by、join语句的性能,在sort、group by、join会用到sort buffer 、 临时表、join buffer、这些都是一块有限的内存空间,查询的字段越多内存装不下了,就只能转而在磁盘中去做对应操作,而磁盘操作的性相比内存性能相差上百倍。
6、字段越多,在应用层面(JVM)产生的对象体积就越大,对象越大就导致垃圾收集得越频繁、垃圾收集越频繁就会降低整个应用的性能。
3. Table design optimization
1) Index design
1.1. Indexing of commonly used fields
1.2. Large fields are not suitable for indexing
1.3. Fields with low discreteness are not suitable for indexing (such as gender)
1.4. Fields that are updated frequently are not suitable for indexing
1.5. In the appropriate Scenario, use combined index more
1.6, choose the appropriate field length
2), Table design optimization
2.1, field redundancy
2.2, table redundancy
2.3, separation of hot and cold data
other
Update to be continued