Original paper: https://arxiv.org/abs/2110.02178
Source code address (pytorch implementation): https://github.com/apple/ml-cvnets
Preface
MobileVit is composed of a hybrid architecture of CNN and Transformer. It takes advantage of CNN's spatial induction bias [1] and accelerated network convergence, and also takes advantage of Transformer's self-attention mechanism and global vision. In terms of model parameters, it has a lower number of network parameters than the mainstream transformer architecture, but higher accuracy. Compared with the mainstream lightweight CNN architecture, it has a lower number of parameters and higher accuracy. Of course, the speed is still much slower than the mainstream lightweight CNN architecture model, but it is much faster than the pure transformer architecture.
Network structure

figure 1
Components (from left to right):
-
Ordinary convolution layer: used for preprocessing and feature extraction of input images.
-
MV2 (Inverted Residual block in MobileNetV2): A lightweight convolutional block structure used for downsampling operations in the network.
-
MobileViT block: The core component of MobileViT, consisting of multiple Transformer blocks, is used for global context modeling and feature fusion of image features.
-
Global pooling layer: used to reduce the dimensionality of the feature map to obtain global features.
-
Fully connected layer: used to map global features to the final prediction output.
MV2:
It is the structure in mobile-Net V2, consisting of two 1×1 convolutions and one 3×3 convolution.

figure 2
relu6
The original relu activation function does not limit the output value greater than 0. Relu6 limits the maximum output value to 6. The formula is as follows:
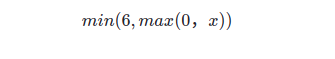
MobileViT block:
The core component consists of multiple Transformer blocks and convolution layers (convolution kernel size is 1×1 and 3×3)

image 3
Specific process:
First, the feature map is modeled locally through a convolution layer with a convolution kernel size of nxn (source code is 3x3), and then the number of channels is adjusted through a convolution layer with a convolution kernel size of 1x1. Then perform global feature modeling through the Unfold -> Transformer -> Fold structure, and then adjust the number of channels back to the original size through a convolution layer with a convolution kernel size of 1x1. Then the shortcut branch is used to perform Concat splicing with the original input feature map (splicing along the channel direction), and finally a convolution layer with a convolution kernel size of nxn (source code 3x3) is used for feature fusion to obtain the output.
Unfold -> Transformer -> Fold process:
First, the feature map is divided into patches. The patch in Figure 4 is 2×2, that is, each patch consists of 4 tokens. When performing self-attention calculations, each token (each token in Figure 4, that is, each small color block) only performs attention with tokens of the same color as itself (for the purpose of reducing the amount of calculation, only the original 1/4 of the calculation amount, each token of the original self-attention needs to be calculated with the other tokens for attention).
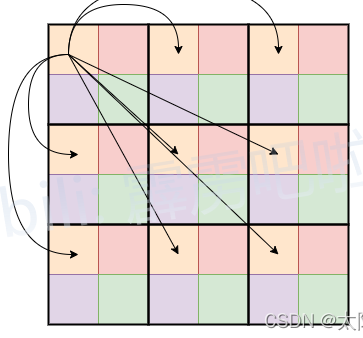
Figure 4

Figure 5
Reference explanation
[1]: The spatial induction bias of CNN refers to a bias mechanism that uses the characteristics of convolution operations to model and learn spatial information when CNN processes image data. In image data, the spatial relationship between adjacent pixels is usually meaningful, and CNN can obtain and learn this spatial relationship within the local receptive field through convolution operations. Specifically, CNN extracts features at different positions through convolution kernels that share weights. This weight sharing mechanism makes CNN invariant to translation, that is, the features extracted at different positions are similar. Through this characteristic, CNN is able to model the spatial structure of the image, thereby capturing the correlation and constraint relationships between different locations in the image. In image classification tasks, through convolution operations and pooling operations, CNN can gradually reduce the size of the feature map, extract and combine global and local features, and finally output the classification results. This spatial induction bias enables CNN to model and understand the spatial structure in images, improving the performance of image classification.
In contrast, pure Transformer architecture lacks this spatial induction bias when processing image data, but mainly relies on the self-attention mechanism to associate and integrate features at different locations. Therefore, when processing image data, introducing the spatial induction bias of CNN can make up for the shortcomings of the pure Transformer architecture and improve the performance of the model in image-related tasks.
Reference: MobileViT model introduction_mobilevitattention_Sunflower’s little mung bean blog-CSDN blog