Deep learning paper: PE-YOLO: Pyramid Enhancement Network for Dark Object Detection and its PyTorch implementation
PE-YOLO: Pyramid Enhancement Network for Dark Object Detection
PDF: https://arxiv.org/pdf/2307.10953v1.pdf
PyTorch code: https ://github.com/shanglianlm0525/CvPytorch
PyTorch code: https://github.com/shanglianlm0525/PyTorch-Networks
1 Overview
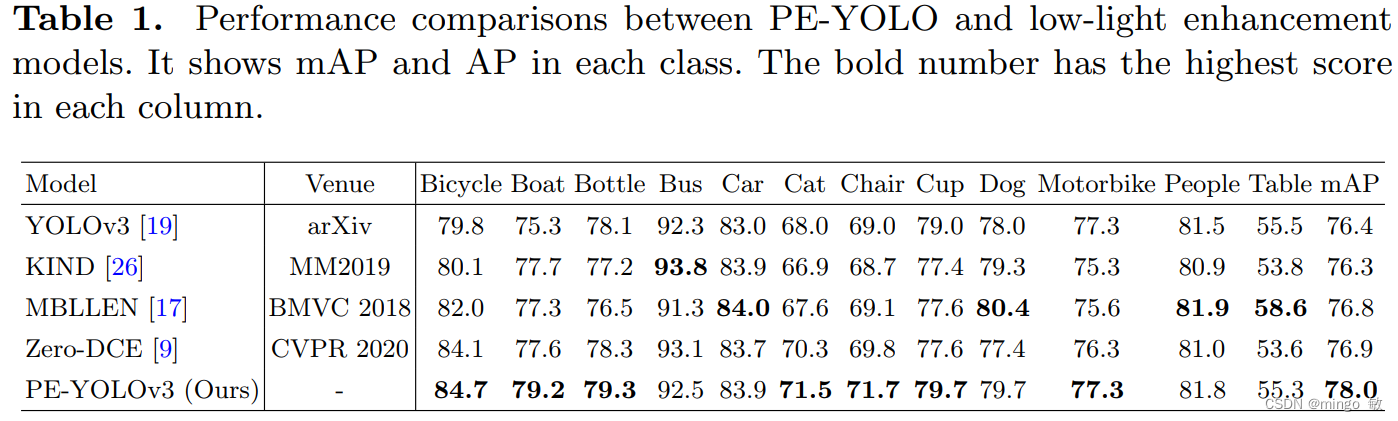
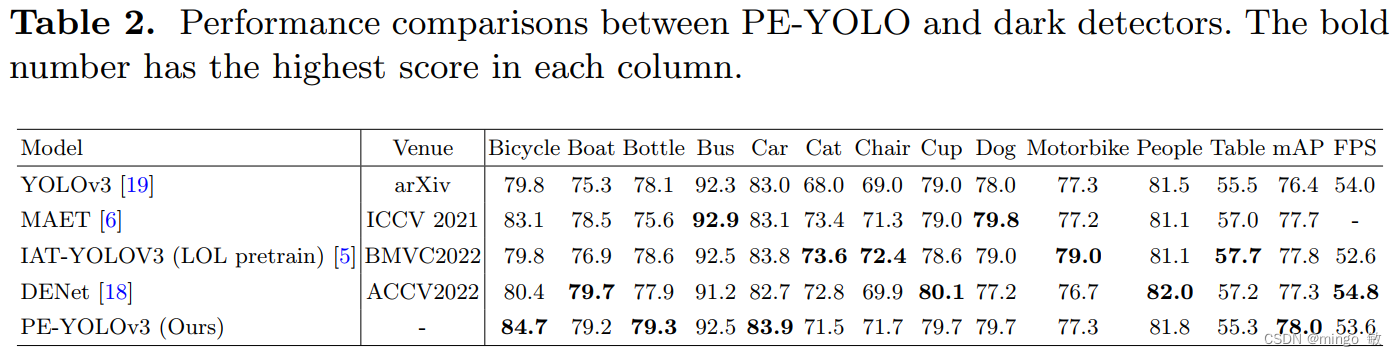
Current object detection models achieve good results on many benchmark datasets, but detecting objects in dark conditions remains a huge challenge. To solve this problem, we propose a Pyramid Enhanced Network (PENet) and combine it with YOLOv3 to build a dark object detection framework named PE-YOLO. First, PENet uses Laplacian pyramid to decompose the image into four components with different resolutions. Specifically, we propose a detail processing module (DPM) to enhance image details, which consists of a context branch and an edge branch. Furthermore, we propose a low-frequency enhancement filter (LEF) to capture low-frequency semantics and prevent high-frequency noise. PE-YOLO adopts an end-to-end joint training method and only uses normal detection loss to simplify the training process. We conduct experiments on the low-light object detection dataset ExDark to demonstrate the effectiveness of our method.

2 PE-YOLO
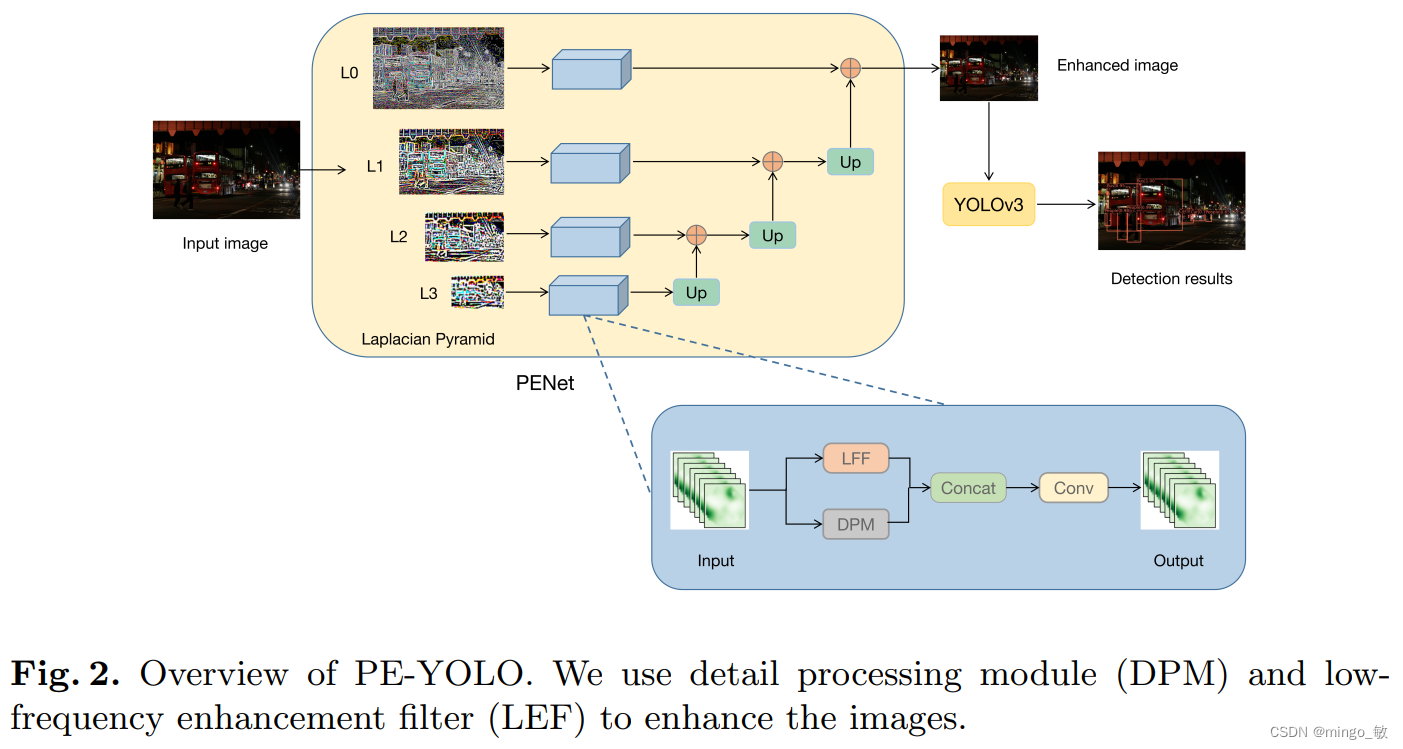
2-1 PENet
The Laplacian pyramid of an image is defined as
![]()
where G ( x ) G(x)G ( x ) is defined as:
![]()
PENet decomposes the image into components of different resolutions through the Laplacian pyramid.

It can be seen from the image that the Laplacian pyramid pays more attention to global information from bottom to top, while on the contrary, it pays more attention to local details. This information is lost during the image downsampling process, and it is also the object that PENet needs to enhance.
2-2 Detail Enhancement
The Detail Processing Module (DPM) is used to enhance the components in the Laplacian Pyramid. DPM is divided into Context branch and Edge branch . Context branch obtains context information by capturing remote dependencies and performs global enhancements on components. The Edge branch uses Sobel operators in two different directions to calculate image gradients to obtain edges and enhance the texture of components.
Context branch : Use residual blocks to process features before and after obtaining long-range dependencies, and transfer rich low-frequency information through residual learning skip connections. The first residual block changes the feature's channels from 3 to 32, and the second residual block changes the feature's channels from 32 to 3. Capturing global information in a scene is beneficial for low-level vision tasks such as low-light enhancement.
Edge branch : The Sobel operator is a discrete operator that combines Gaussian filter and differential derivation. It finds the edges of an image by computing a gradient approximation. The Sobel operator is used in the horizontal and vertical directions, the edge information is re-extracted through the convolution filter, and the residual is used to enhance the transfer of information. This can further enhance the texture characteristics of the image.
The details of DPM are as follows:

2-3 Low-Frequency Enhancement Filter
Among the components at each scale, the low-frequency components contain most of the semantic information in the image, and they are the key information for detector prediction. In order to enrich the semantics of the reconstructed image, this paper proposes a low-frequency enhancement filter (LEF) to capture the low-frequency information in the component. Assume component f ∈ Rh×w×3, first convert it to f ∈ Rh×w×32 through a convolution layer. Then a dynamic low-pass filter is used to capture low-frequency information, and average pooling is used for feature filtering, allowing only information below the cutoff frequency to pass. The low-frequency thresholds of different semantics are different. Drawing on Inception's multi-scale structure, adaptive average pooling is used, with sizes of 1×1, 2×2, 3×3, and 6×6, and upsampling is used at the end of each scale to restore the original size of the feature. . Average pooling of different kernel sizes forms a low-pass filter.
The detailed information of LEF is as follows:

3 Experiments