Common index
Index classification
In the MySQL database, the specific types of indexes are mainly divided into the following categories: primary key index, unique index, regular index, and full-text index.
| Classification | meaning | Features | Keywords |
|---|---|---|---|
| primary key index | Index created on the primary key in the table | Automatically created by default, there can only be one | PRIMARY |
| unique index | Avoid duplication of values in a data column in the same table | There can be multiple | UNIQUE |
| regular index | Quickly locate specific data | There can be multiple | |
| Full text index | Full-text indexing searches for keywords in the text rather than comparing values in the index | There can be multiple | FULL TEXT |
According to the physical implementation of indexes, indexes can be divided into two types: clustered (clustered) and non-clustered (non-clustered) indexes. We also call non-clustered indexes secondary indexes or auxiliary indexes.
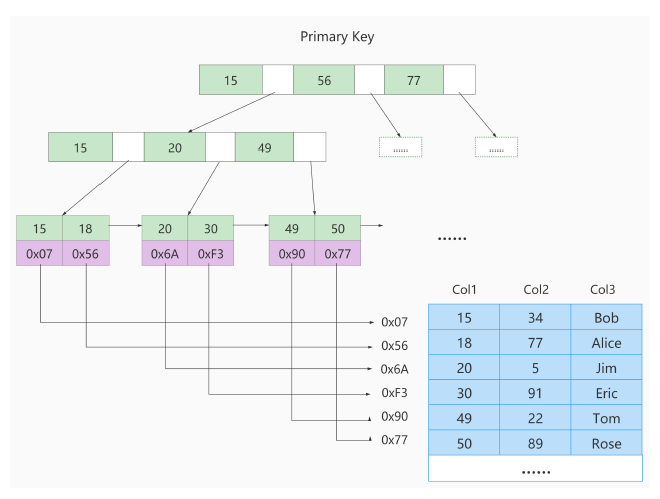
clustered index
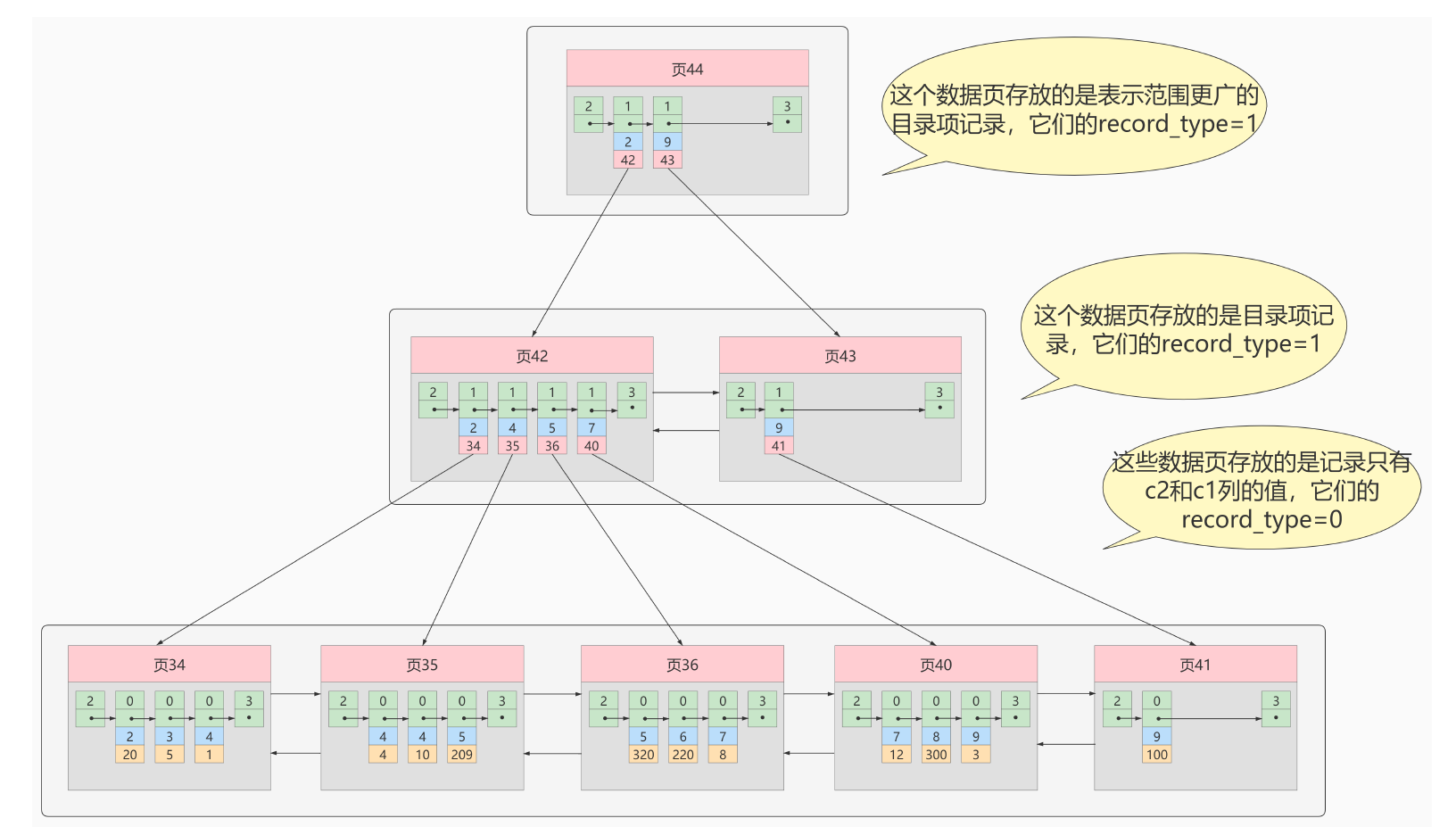
Clustered Index (ClusteredIndex) puts data storage and index together. The leaf nodes of the index structure store row data. There must be one and only one
Use logging 主键值的大小to record and页的排序
-
The records in the page are arranged in order according to the size of the primary key.
单向链表 -
Each storage
用户记录的页is also arranged in order according to the primary key size of the user record in the page.双向链表 -
Pages storing directory entry records are divided into different levels. Pages in the same level are also arranged in a doubly linked list based on the primary key size of the directory entry records in the page.
The leaf nodes of the B+ tree store complete user records
The so-called complete user record means that the values of all columns (including hidden columns) are stored in this record.

Clustered index selection rules:
- If a primary key exists, the primary key index is a clustered index.
- If no primary key exists, the first unique (UNIQUE) index will be used as the clustered index.
- If the table does not have a primary key, or a suitable unique index, InnoDB will automatically generate a rowid as a hidden clustered index.
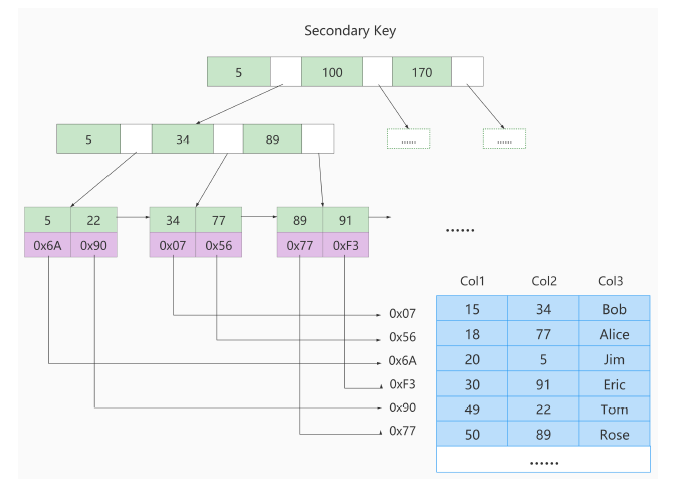
Secondary index (auxiliary index, non-clustered index)
Secondary Index (SecondaryIndex) stores data and indexes separately. The leaf nodes of the index structure are associated with the corresponding primary keys, and there can be multiple
The specific structures of clustered indexes and secondary indexes are as follows:
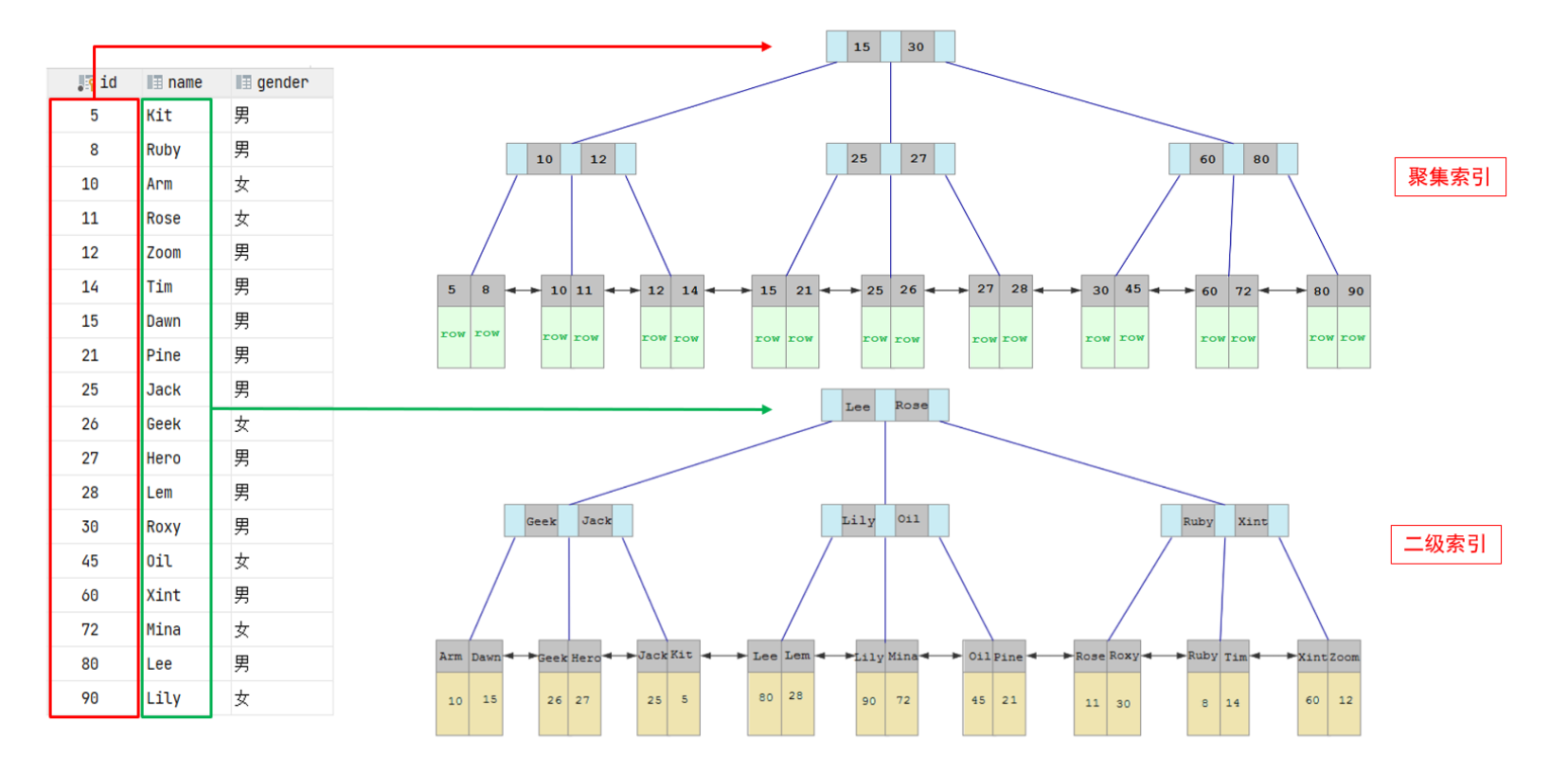
- The leaf node of the clustered index hangs the data of this row.
- The leaf node of the secondary index hangs the primary key value corresponding to the field value.
SQL lookup process
When we execute the following SQL statement, what does the specific search process look like?
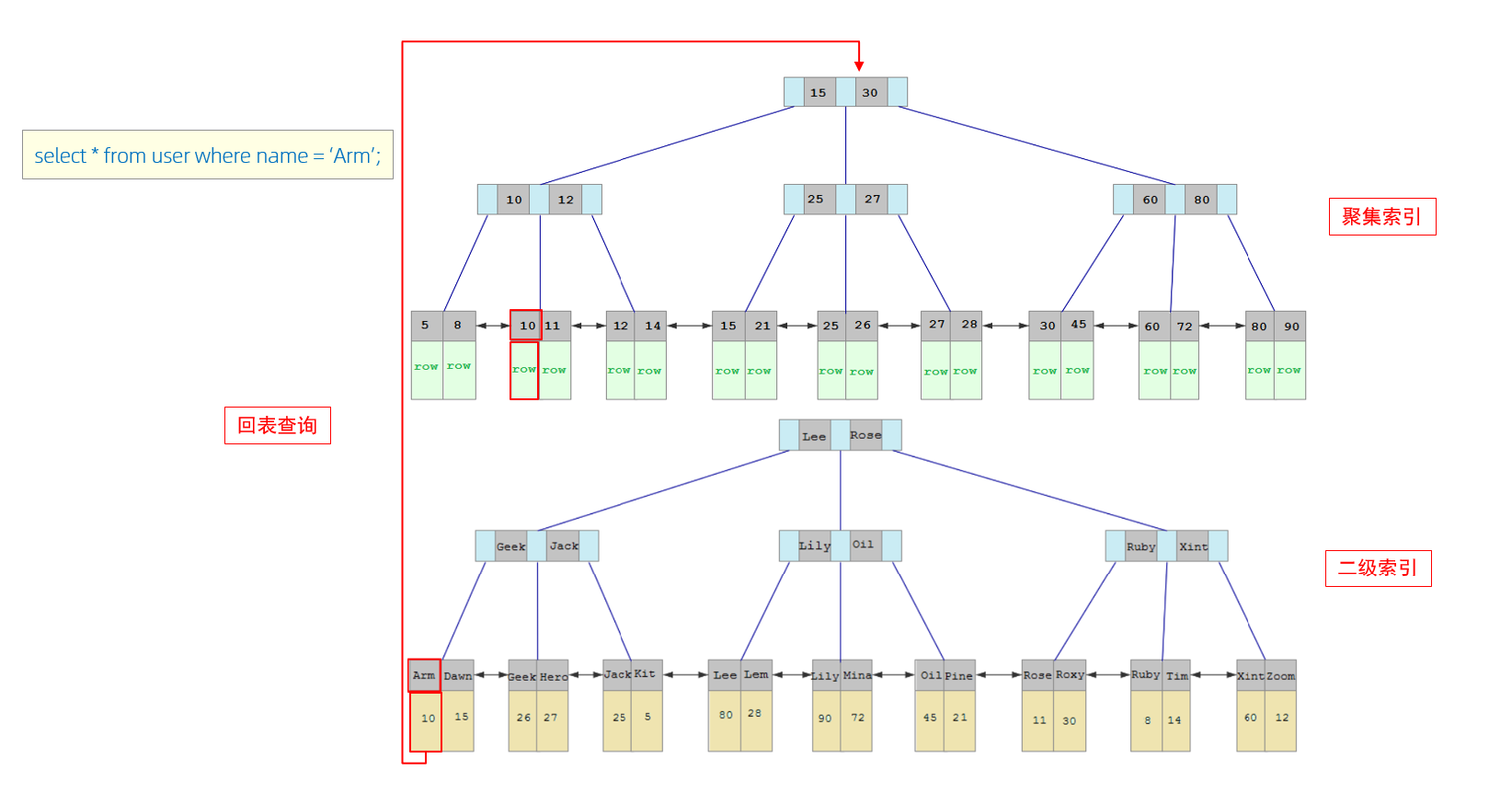
①. Since the query is based on the name field, first go to the secondary index of the name field to perform a matching search based on name='Arm'. However, only the primary key value 10 corresponding to Arm can be found in the secondary index.
②. Since the data returned by the query is *, at this time, you need to search for the record corresponding to 10 in the clustered index based on the primary key value 10, and finally find the row corresponding to 10.
③. When you finally get the data in this row, just return it directly.
Table-back query: This method of first searching for data in the secondary index, finding the primary key value, and then obtaining the data based on the primary key value in the clustered index is called table-back query.
Question:
Which of the following two SQL statements has higher execution efficiency? Why?
A. select * from user where id = 10;
B. select * from user where name = 'Arm';
Note: id is the primary key and the name field is created There is an index;Answer:
The execution performance of statement A is higher than statement B.
Because statement A goes directly to the clustered index and returns data directly. Statement B needs to query the secondary index of the name field first, and then query the clustered index, which means a table query is required.What is the B+tree height of InnoDB primary key index?
Assumption:
The size of one row of data is 1k, and 16 rows of such data can be stored in one page. InnoDB pointers occupy 6 bytes of space
. Even if the primary key is bigint, the number of bytes occupied is 8.
The height is 2:
n * 8 + (n + 1) * 6 = 16*1024, n is calculated to be approximately 1170.
1171* 16 = 18736
That is to say, if the height of the tree is 2, more than 18,000 records can be stored.Height is 3:
1171 * 1171 * 16 = 21939856
That is to say, if the height of the tree is 3, it can store about 2200w records.Things to note about InnoDB’s B+ tree index
- The location of the root page remains unchanged for thousands of years.
- Uniqueness of directory entry records in internal nodes
- A page stores at least 2 records
Index scheme in MyISAM
The applicable storage engines for B-tree indexes are as shown in the table:
| Index/storage engine | MyISAM | InnoDB | Memory |
|---|---|---|---|
| B-Tree index | support | support | support |
Even if multiple storage engines support the same type of index, their implementation principles are also different. The default index of Innodb and MyISAM is Btree index; while the default index of Memory is Hash index.
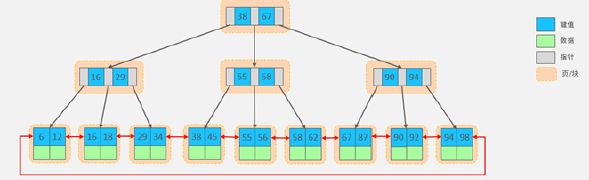
The MyISAM engine uses B+Tree as the index structure, and the data field of the leaf node is stored 数据记录的地址.
The principle of MyISAM index
If we create a secondary index on Col2, the structure of this index is as shown below:
MyISAM vs. InnoDB
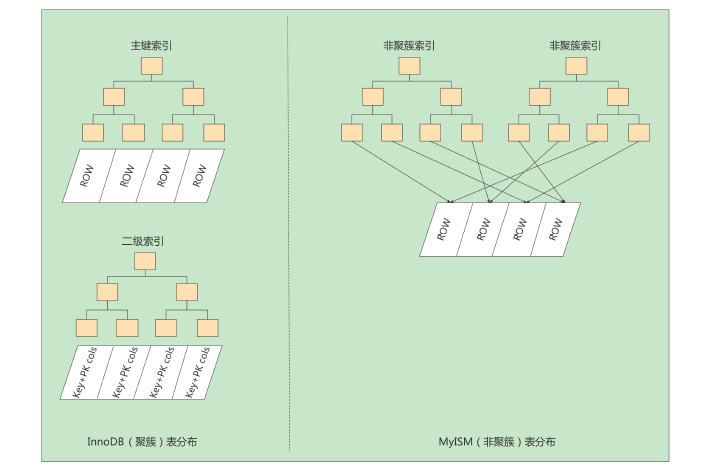
MyISAM's indexing methods are all "non-clustered", which is different from InnoDB which contains a clustered index. Summary of the differences between indexes in the two engines:
① In the InnoDB storage engine, we only need to 聚簇索引perform a search based on the primary key value pair to find the corresponding record, but in
MyISAM, we need to perform one 回表operation, which means that the indexes established in MyISAM are equivalent to all secondary indexes .
② The data file of InnoDB itself is an index file, while the MyISAM index file and data file are 分离的. The index file only saves
the address of the data record.
③ InnoDB's non-clustered index data domain stores corresponding records 主键的值, while MyISAM index records 地址. In other words,
all non-clustered indexes in InnoDB reference the primary key as the data field .
④ MyISAM's table return operation is very 快速simple, because it takes the address offset to fetch data directly from the file. On the other hand, InnoDB
obtains primary key and then searches for the record in the clustered index. Although it is not slow, it is It's still not as good as accessing it directly using the address.
⑤ InnoDB requirement table 必须有主键( MyISAM可以没有). If not specified explicitly, the MySQL system will automatically select a
column that can be non-null and uniquely identify the data record as the primary key. If such a column does not exist, MySQL automatically generates an implicit
field as the primary key for the InnoDB table. This field is 6 bytes long and of type long integer.
The cost of indexing
Index is a good thing, but it cannot be built randomly. It will consume space and time:
Space cost:
Every time an index is created, a B+ tree must be built for it. Each node of each B+ tree is a data page. By default, a page will occupy 16KB of storage space, which is a very large B+ tree. It consists of many data pages, which is a large storage space.
Time cost:
Every time you operate on the data in the table 增、删、改, you need to modify each B+ tree index. 从小到大的顺序排序And we have said that the nodes at each level of the B+ tree are composed according to the value of the index column 双向链表. Whether it is the records in the leaf nodes or the records in the internal nodes (that is, whether they are user records or directory entry records), they form a one-way linked list in order from small to large in the index column value. Addition, deletion, and modification operations may cause damage to the sorting of nodes and records, so the storage engine needs extra time to perform some 记录移位, 页面分裂、页面回收other operations to maintain the sorting of nodes and records. If we build many indexes, the B+ tree corresponding to each index will need to undergo related maintenance operations, which will hinder performance.