Reference:
https://github.com/THUDM/ChatGLM-6B/pull/573/commits/02947052eefe392fd9f9632894e9551a805c6109
https://github.com/THUDM/ChatGLM-6B/pull/573
1. Code:
Install in advance:
sse_starlette、fastapi
python fastapi_api.py
fastapi_api.py
from fastapi import FastAPI
from pydantic import BaseModel
from typing import Optional
from sse_starlette.sse import EventSourceResponse
from transformers import AutoTokenizer, AutoModel
import uvicorn
import torch
'''
此脚本实现模型响应结果的流式传输,让用户无需等待完整内容的响应。
This script implements the streaming transmission of model response results, eliminating the need for users to wait for a complete response of the content.
访问接口时它将返回event-stream流,你需要在客户端接收并处理它。
When accessing the interface, it will return an 'event-stream' stream, which you need to receive and process on the client.
POST http://127.0.0.1:8010
{ "input": "你好ChatGLM" }
input: 输入内容
max_length: 最大长度
top_p: 采样阈值
temperature: 抽样随机性
history: 二维历史消息数组,eg: [["你好ChatGLM","你好,我是ChatGLM,一个基于语言模型的人工智能助手。很高兴见到你,欢迎问我任何问题。"]]
html_entities: 开启HTML字符实体转换
'''
DEVICE = "cuda"
DEVICE_ID = "0"
CUDA_DEVICE = f"{DEVICE}:{DEVICE_ID}" if DEVICE_ID else DEVICE
def torch_gc():
if torch.cuda.is_available():
with torch.cuda.device(CUDA_DEVICE):
torch.cuda.empty_cache()
torch.cuda.ipc_collect()
app = FastAPI()
def parse_text(text):
lines = text.split("\n")
lines = [line for line in lines if line != ""]
count = 0
for i, line in enumerate(lines):
if "```" in line:
count += 1
items = line.split('`')
if count % 2 == 1:
lines[i] = f'<pre><code class="language-{items[-1]}">'
else:
lines[i] = f'<br></code></pre>'
else:
if i > 0:
if count % 2 == 1:
line = line.replace("`", "\`")
line = line.replace("<", "<")
line = line.replace(">", ">")
line = line.replace(" ", " ")
line = line.replace("*", "*")
line = line.replace("_", "_")
line = line.replace("-", "-")
line = line.replace(".", ".")
line = line.replace("!", "!")
line = line.replace("(", "(")
line = line.replace(")", ")")
line = line.replace("$", "$")
lines[i] = "<br>"+line
text = "".join(lines)
return text
async def predict(input, max_length, top_p, temperature, history, html_entities):
global model, tokenizer
for response, history in model.stream_chat(tokenizer, input, history, max_length=max_length, top_p=top_p,
temperature=temperature):
yield parse_text(response) if html_entities else response
torch_gc()
class ConversationsParams(BaseModel):
input: str
max_length: Optional[int] = 2048
top_p: Optional[float] = 0.7
temperature: Optional[float] = 0.95
history: Optional[list] = []
html_entities: Optional[bool] = True
@app.post('/')
async def conversations(params: ConversationsParams):
history = list(map(tuple, params.history))
predictGenerator = predict(params.input, params.max_length, params.top_p, params.temperature, history, params.html_entities)
return EventSourceResponse(predictGenerator)
if __name__ == '__main__':
tokenizer = AutoTokenizer.from_pretrained("/mnt***atglm2-6b-int4"", trust_remote_code=True)
model = AutoModel.from_pretrained("/mnt***hatglm2-6b-int4"", trust_remote_code=True).half().cuda()
model.eval()
uvicorn.run(app, host='19*****4', port=8000, workers=1)
2. api access
1)curl
curl -X POST “http://127.0.0.1:8010”
-H ‘Content-Type: application/json’
-d ‘{“input”: “你好”}’
2) http post access
Because the requests library does not support handling server-sent event (SSE) responses. You need to use another library like httpx or aiohttp which supports asynchronous requests and handling SSE responses.

For example, you can use the httpx library. First, install httpx:
In the asynchronous function of fetch_data(). The function uses httpx.AsyncClient to create an asynchronous client, sends a POST request through the client.stream method, and uses the asynchronous iterator response.aiter_lines() to obtain the response data line by line for printing.
Finally, I use asyncio.run() to execute the async function
pip install httpx
import httpx
import asyncio
url = "http://192*****4:8000"
data = {
"input": "你能做什么",
"max_length": 2048,
"top_p": 0.7,
"temperature": 0.95,
"history": [["你名字叫杰*******安全;每次回答请都简要回答不超过30个字","好的,****为你服务"]],
"html_entities": True,
}
async def fetch_data():
async with httpx.AsyncClient() as client:
async with client.stream("POST", url, json=data) as response:
async for line in response.aiter_lines():
print(line)
# 调用异步函数
asyncio.run(fetch_data())
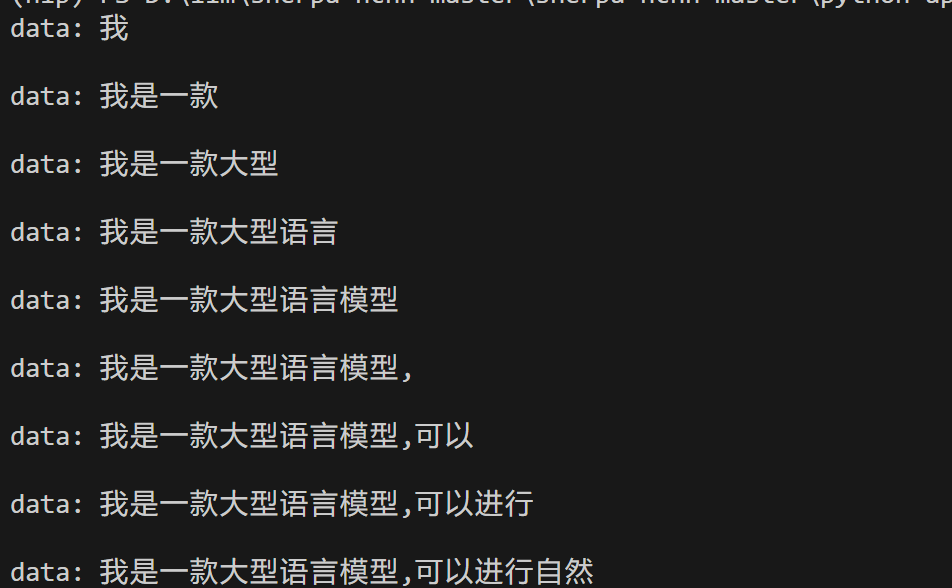
If you need real-time broadcast
import httpx
import asyncio
import pyttsx3
async def fetch_data():
text_len = 0
async with httpx.AsyncClient() as client:
async with client.stream("POST", url, json=data) as response:
async for line in response.aiter_lines():
print(line)
line = line[6:]
if text_len == 0:
if "," in line or ":" in line or "。" in line or "、" in line or "!" in line or "," in line:
pyttsx3.speak(line)
text_len += len(line)
else:
new_line = line[text_len:]
if "," in new_line or ":" in new_line or "。" in new_line or "、" in new_line or "!" in new_line or "," in new_line:
pyttsx3.speak(new_line)
text_len += len(new_line)
# 调用异步函数
asyncio.run(fetch_data())