Table of contents
Acknowledgment response mechanism (ACK)
Confirmation response mechanism
★Three handshakes and four waves
How to understand the three-way handshake
How to understand the four waves
Confirmation response mechanism (supplementary)
Edit Timeout retransmission mechanism
Flow control mechanism (supplementary)
Understand byte stream oriented
Preface
In the previous chapter, we explained the UDP protocol and understood the format and function of the UDP protocol. This article will explain in detail the relevant content of the TCP protocol . TCP stands for "Transmission Control Protocol. As its name suggests, it requires detailed control of data transmission. The TCP protocol is not only an important part of computer networks, but also has a very high frequency of interviews. A type of content, especially the three-way handshake, the four-way wave and various problems derived from it. This article will introduce in detail the TCP protocol format, how to establish a TCP connection, and various strategies to ensure reliability and performance, etc. , there is a lot of content, and you will definitely gain a lot from reading it patiently.
TCP protocol format
Before performing any operation, you need to understand the header format of the TCP protocol. The picture is as follows:
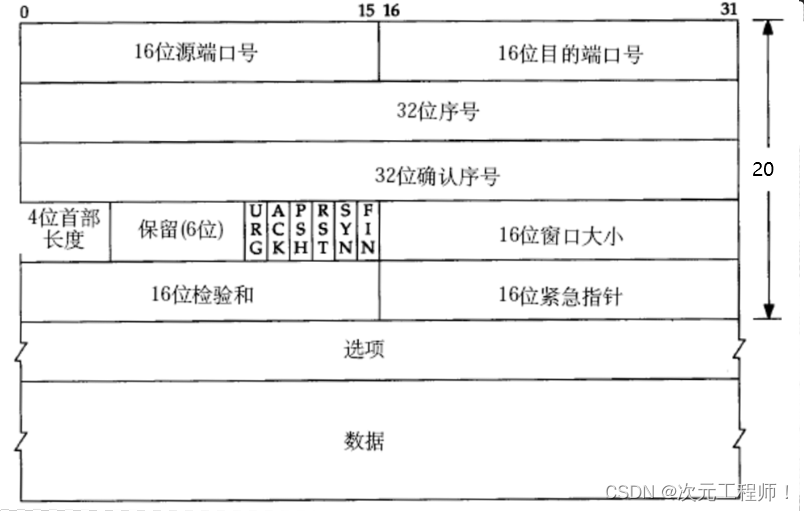
- Source/destination port number : Indicates which process the data comes from and which process it goes to;
- 32-bit serial number/32-bit confirmation number : More details later;
- 4-bit TCP header length : Indicates how many 32-bit bits the TCP header has (how many 4-bytes there are); so the maximum length of the TCP header is 15 * 4 = 60. (mentioned above)
- 6-digit flag :
- URG: Is the urgent pointer valid?
- ACK: Confirm whether the number is valid
- PSH: prompts the receiving application to immediately read the data from the TCP buffer
- RST: The other party requires re-establishing the connection; we call the message segment carrying the RST identifier a reset segment.
- SYN: Requests to establish a connection; we call the SYN identifier a synchronization segment
- FIN: Notify the other party that the local end is about to close. We call the segment carrying the FIN identifier an end segment.
16-bit window size : More on this later
16-bit checksum : padding at the sending end, CRC check. If the verification at the receiving end fails, it is considered that there is a problem with the data. The checksum here not only includes the TCP header, but also the TCP data part. 16-bit emergency pointer:
identifies which Part of the data is urgent data;
40-byte header option : ignore for now
This requires answering two necessary questions:
a. How to deliver to the upper layer b. How to unpack
a. This is simple, because the TCP header contains a 16-bit destination port number , and the upper-layer process can be found based on the port number and then delivered.
☆ b.TCP header is a variable length header because there are options added. Each time we extract the first 20 bytes first and then we get the size of the entire header (including options) based on the 4-bit header length mentioned in the header .
However, the range that the 4-digit header length can represent is 0000-1111, that is, the length of 0-15 bytes . It cannot even fit its own 20 bytes. How to put options?
In fact, the unit that specifies the length of the 4-bit header is 4 bytes , not one byte. That is, 0001 represents 4 bytes instead of 1 byte, so the range that the 4-bit header length can represent is 0-60 bytes. Since the header is at least 20 bytes, the actual range represented by the 4-digit header length is [20-60].
Then use the number of bytes represented by the 4-bit header length - 20 bytes is the size of the option , then parse the option, and the rest is the data.
So the summary is:
- Extract first 20 bytes
- According to the standard header, extract the 4-digit header length * 4 - 20 and set it to res
- a. If res == 0, it means there are no options, and the reading has been completed at this time. b. res > 0, it means there are options, and the options can be read at this time.
- After reading the header, the rest is the payload .
Acknowledgment response mechanism (ACK)
Understand reliability
For example, two people A and B are talking on the phone. When A says to B: "Did you eat?", if B replies "I ate" at this time, then A will know that B after hearing what B said. He must have heard what I said, because he gave me a confirmation response.
But B does not know whether A has successfully received what he said "I ate". If A says "what did you eat" at this time, B can be sure that A must have received what he said. Because a response was received.
But at this time, A did not know that what he said, "What did you eat?" was received by the other party.
Therefore, neither A nor B can guarantee that the data sent by the latest party will be received by the other party.
But locally , we can be 100% reliable.
Because for all the messages sent, as long as there is a matching response, I can guarantee that the message just sent will be received by the other party.
Therefore, the acknowledgment response mechanism of the TCP protocol: as long as a message receives the corresponding response, it can be guaranteed that the data I sent has been received by the other party.
Confirmation response mechanism
The acknowledgment response mechanism (ACK) is a communication mechanism in computer networks. In TCP communication, when the sender sends data to the receiver, the sender will wait for the receiver to return an acknowledgment response (ACK) to confirm that the data has been successfully received.
Implementation method : The sequence number and confirmation sequence number ensure which message the response responds to.
Serial number and confirmation serial number:
The sequence number field indicates the sequence number of the first byte of the data part in the TCP datagram and is used to number and sort the data.
The acknowledgment sequence number field indicates the sequence number of the next byte the sender expects to receive.
To achieve reliable transmission and flow control of TCP :
1. Ensure one-to-one correspondence between requests and responses.
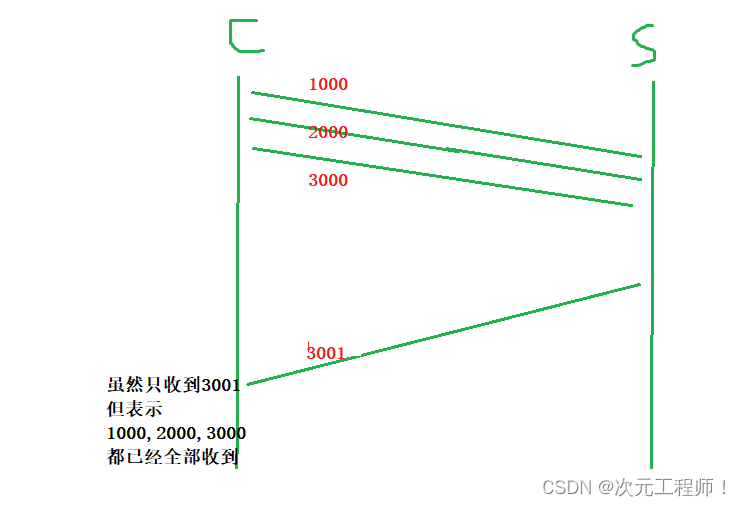
2. Confirm the serial number: Confirm that all the data before the serial number has been received. (For example, I sent 1000, 2000, 3000, and then the receiver sent confirmation serial numbers 1001, 2001, 3001. If the sender only received 3001 in the end, it means that all the data before 3001 has been received . This is the meaning of the confirmation serial number. definite)
3. Allow partial confirmation to be lost or no response to be given .
Confirm partial loss: For example, the sender sent 1000, 2000, 3000, and then the receiver received it and responded to the sender. The sender finally only received 3001, but there is no problem at this time, because this means that all the data before 3001 have been received
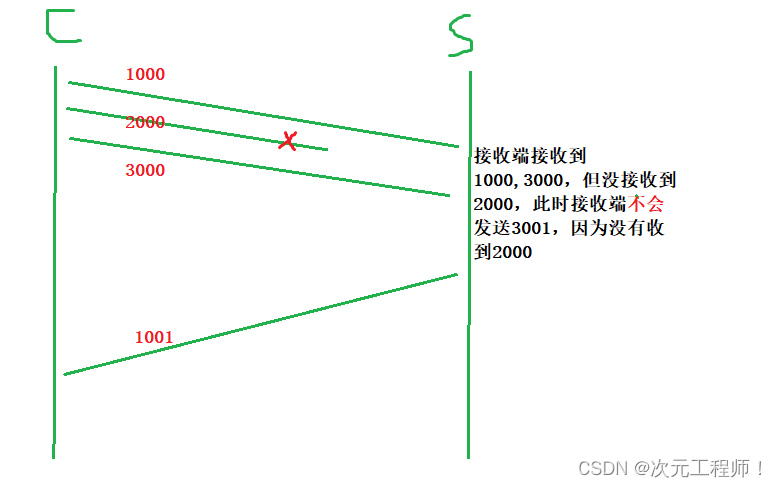
No response : When the sender sends 1000, 2000, and 3000 to the receiver, but the receiver only receives 1000, 3000, it can only respond to the sender with 1001 , but not 3001, because 2000 was not received.
4. Why are there two fields (sequence number and confirmation sequence number)?
When we send, we use the serial number, and when we receive, we use the confirmation serial number. Why use two? Wouldn't one be enough? Isn't it also okay to use the sent sequence number as the confirmation sequence number?
We need to know that TCP is full-duplex, either party can receive or send ! If not distinguished, sent data and received data will be mixed together. For example, the sender may treat the data sent by the receiver as a response, or the other party's response as sent data.
5. How to ensure the order ? For example, if the sender sends 123, the receiver may receive 231? Either party will receive the message, which will carry a sequence number. After receipt, it will be sorted and reorganized to ensure the order of the data. Ensure data is delivered to the application layer in the correct order.
16-bit window size
The 16-bit window size represents the buffer size available to the receiver when receiving data. This field indicates the maximum amount of data that the sender can continuously send to the receiver without waiting for an acknowledgment .
buffer
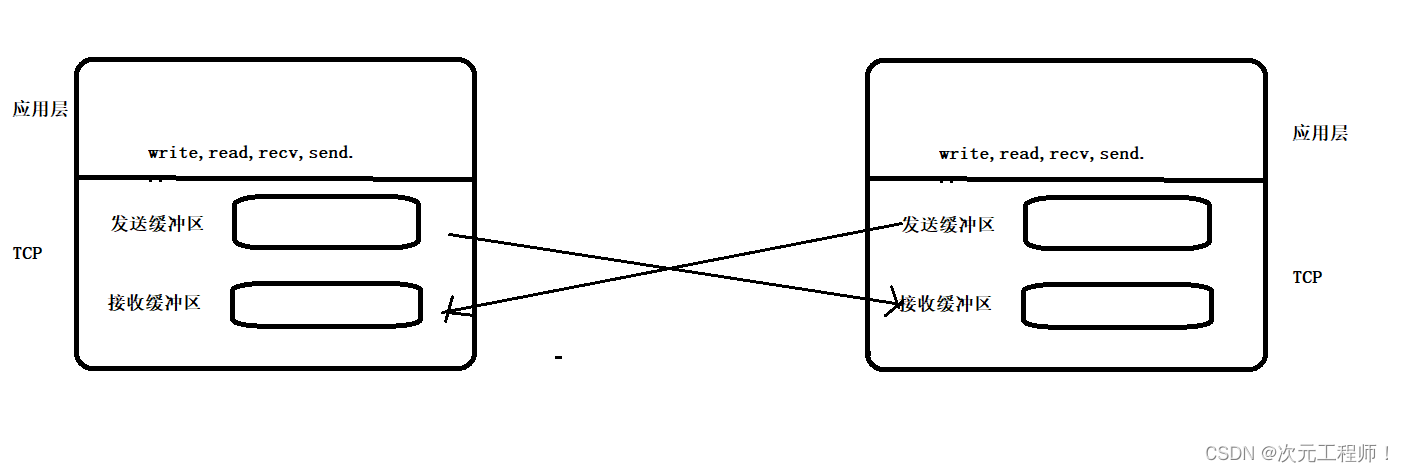
First of all, TCP is also full-duplex, that is, it can also receive data while sending data.
TCP sender and receiver have send buffers and receive buffers , while UDP has no send buffer.
flow control
The speed at which the receiving end processes data is limited . If the sending end sends too fast, causing the receiving end's buffer to be filled up. At this time, if the sending end continues to send, packet loss will occur, which will then cause packet loss and retransmission, etc. A series of chain reactions, resulting in a decrease in efficiency.
Therefore, TCP supports determining the sending speed of the sender based on the processing capabilities of the receiving end. This mechanism is called Flow Control ;
Every time data is sent, the receive buffer will be filled, and the remaining space in the receive buffer is the 16-bit window size.
- The receiving end puts the buffer size it can receive into the "16-bit window size" field in the TCP header, and notifies the sending end through the ACK end;
- The larger the window size field, the higher the throughput of the network;
- Once the receiving end finds that its buffer is almost full, it will set to a smaller value and notify the sending end. After the sending end receives this window, it will slow down its sending speed;
- If the buffer at the receiving end is full, the window will be set to 0; at this time, the sender will no longer send data , but it needs to send a window detection data segment regularly so that the receiving end can tell the sender the window size.
6 flags
In the TCP protocol, the TCP header contains some flags (Flags), which are used to convey specific control information and status during the communication process.
There are a total of 6 flags, namely URG, ACK, PSH, RST, SYN, and FIN. Let’s talk about a few common flags first:
- ACK: Acknowledgment response flag. This flag will be set to 1 whenever the message has the characteristics of answering the message. This flag is set to 1 in most network packets , except for the first connection request.
- SYN: Establish a connection request. When the SYN flag is set, it indicates that the party initiating the connection (usually the client) wants to establish a connection and initialize the sequence number.
- FIN: Disconnect request. When the FIN flag is set, it indicates that the sender wishes to close the connection and no longer send data.
- URG: Indicates whether the urgent pointer field is valid. When the URG flag is set, it indicates that part of the data in the segment is marked as urgent data and needs to be processed as soon as possible.
- PSH: Indicates that the receiver should immediately hand over the data to the upper application without waiting for the cache to fill up. The setting of the PSH flag tells the receiver that the received data should be processed immediately without buffering.
- RST: Indicates resetting the connection . When the RST flag is set, it indicates an interruption and reset of the current connection. Typically used when missing data or other error conditions are detected.
The specific functions of these fields will be gradually used in the following mechanisms.
16-bit emergency pointer
The 16-bit emergency pointer is associated with the URG flag .
When the URG flag is set, it means that the emergency pointer is valid , indicating that some data in the message data segment is marked as urgent data and needs to be processed as soon as possible.
Urgent pointer: The urgent pointer is a field in the TCP header, occupying 16 bits, and is used to indicate the offset position of urgent data in the data segment . It represents the offset of the urgent data from the beginning of the message.
When the sender sends a data segment with the URG flag set, the urgent pointer indicates the location of the urgent data in the data segment. When the receiver receives a TCP data segment containing the URG flag, it can determine where to start processing urgent data by checking the emergency pointer.
For example, if the text has 100 bytes of data and the emergency pointer offset is 50, then the receiver will start reading from the 50th byte when reading the urgent data.
★Three handshakes and four waves
How to understand connections
Because a large number of clients may connect to the server in the future, the server must have a large number of connections. The operating system OS must manage these connections, as mentioned before: manage first, then organize. Abstract links into data structures and then manage them with some data structure.
The so-called connection: It is essentially a data structure of the kernel. When the connection is successfully established, the corresponding connection object is created in the memory. Then organize these objects into some kind of data structure such as a linked list.
So there is a cost (memory + CPU) to maintain these connections.
How to understand the three-way handshake
Three-way handshake : The client first sends a request with the flag bit SYN to the server. After the server receives it, it sends a SYN (connection) + ACK (confirmation) request to the client. At this time, the client already thinks that the connection is established (thinks the service The end can already receive and send data normally), and then sends an ACK (confirming the SYN connection request sent by the server) response to the server again.
The flow chart is as follows:
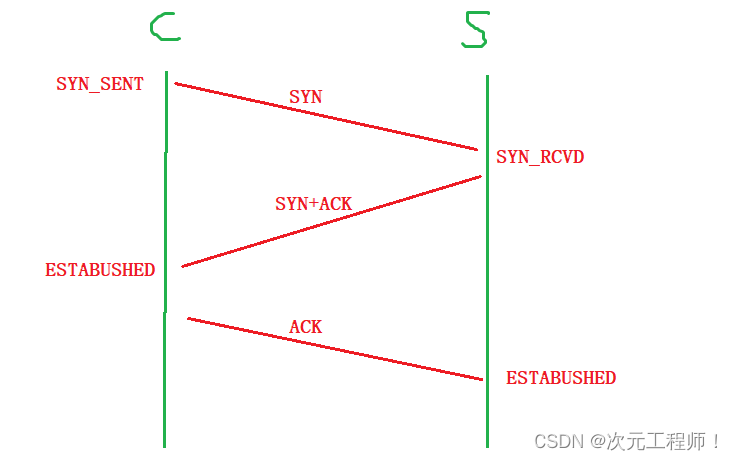
There is a question here, why is it necessary to shake hands three times , not once, but not twice? What about five times?
There are two points here: 1. In order to verify the full duplex of both parties, ensure that both parties can send and receive data normally.
In the first handshake, the client sends SYN to the server. If the server can receive the SYN and reply with SYN+ACK, it can be determined that the client 's sending and receiving capabilities are normal (because after the client sends the SYN, it receives the server's ACK confirmation , but it is not possible to determine whether the server is normal , because after sending the SYN, the ACK response from the client has not been received ); when the client sends an ACK request to the server and is received by the server (the server receives the ACK confirmation) , indicating that the server’s sending and receiving capabilities are normal.
2. For server security
If there is only one handshake, then the server may be vulnerable to attack. For example, a host sends a large number of SYN requests to the server at the same time. As we said at the beginning, these connections need to be maintained , and maintenance requires resources. Therefore, this will occupy a large amount of server resources and cause paralysis, so it is not advisable. This is a SYN flood attack.
If there are only two handshakes, after the server connection is established in the first handshake, a request is sent to the client for the second time, and the client can directly discard the connection. This causes the server to still maintain the connection, but the client does not . connection , it is still possible to send a large number of SYN connection requests, which is not feasible.
Only during the three-way handshake, when the client also confirms the connection, can the connection be made normally. In this way, the client will bear the same resource consumption as the server. Whenever the client sends a connection request, the client must successfully connect to the server before the server performs maintenance. In this way, although the server also maintains these connections, the same number of connections is also maintained on its own host. So this can effectively prevent attacks.
There is a problem here. When the second handshake is completed, the client will think that it has been established and start sending data. At the same time, the client sends an ACK message to the server, but if for some reason the server does not receive the ACK at this time, the server cannot establish a connection. The server has not established a connection, but the client thinks that its connection has been established and starts sending data. This will definitely cause problems.
Therefore, at this time, the server will send a header with the RST (reconnection) flag to the client, indicating that the connection is re-established with the client. At this time, the client and the server will restart the three-way handshake.
There is also a situation where it is assumed that the receiving buffer of the receiving end is full and no more data can be received. At this time, the 16-bit window size will be set to 0, telling the sender not to send the message.
Then every once in a while, the sender sends an empty data message each time to check whether the receiver can accept the data. If the receiver's receive buffer is always full, the message cannot be received. At this time, a , telling the other party to deliver the current data to the upper layer as soon as possible.
How to understand the four waves
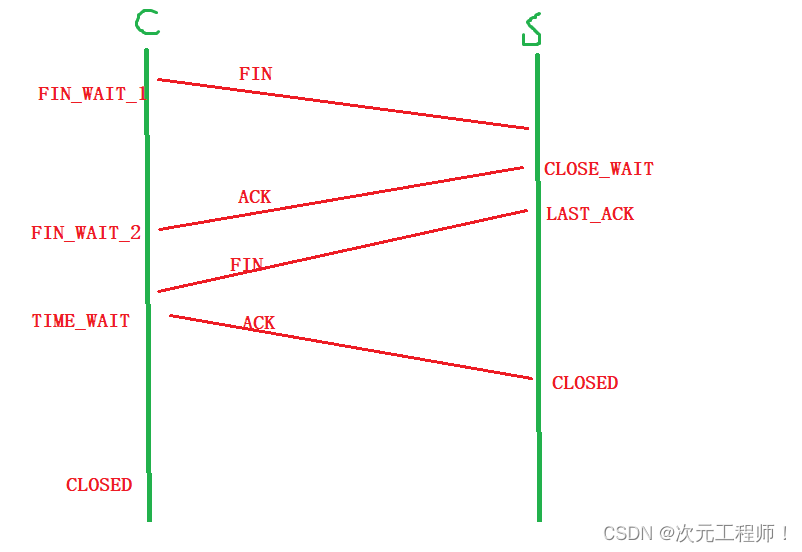
The four wave waves refer to the process of terminating a TCP connection. It is the mechanism in the TCP protocol for closing connections gracefully. The following is the specific process of waving four times:
-
The client sends a connection disconnect message : The client first sends a connection message to the server, and the FIN (Finish) flag is set in the flag bit, indicating that the client will no longer send data . Then enter the FIN_WAIT_1 state and wait for confirmation from the server.
-
The server sends a confirmation message : After the server receives the client's connection disconnect message, it will send a confirmation message in response. The flag bit in the server's confirmation message includes ACK . ACK indicates confirmation of receipt of the client's connection disconnect message, and the server enters the CLOSE_WAIT state.
-
The server sends a connection disconnection message : After the server confirms that the connection with the client has been terminated, it will send a connection disconnection message with the FIN flag in the flag bit. This means that the server is no longer sending data. The server enters the LAST_ACK state and waits for confirmation from the client.
-
The client sends a confirmation message : After the client receives the server's connection disconnect message, it will send a confirmation message as confirmation. The ACK flag indicates that the client confirms receipt of the server's connection release message. In this way, both the client and the server know that the other party has confirmed closing the connection.
At the same time, once the client sends a confirmation message, it enters the TIME_WAIT state and waits for the arrival of possible delayed messages. After waiting for a period of time, if no message is received, the client closes the connection and completes the entire four-wave wave process.
Why is TIME_WAIT needed?
We know that when the party that actively disconnects completes three waves, it will enter the TIME_WAIT state and wait for a period of time before closing. Why is this?
We need to know that although the four-way handshake is completed, the party that actively disconnects must maintain the TIME_WAIT state for a period of time. In this state (TIME_WAIT), the connection has been released, but the address information ip and port are still occupied .
The role of the TIME_WAIT state in the TCP protocol is to ensure that the TCP connection is closed reliably .
When one party to the TCP connection (usually the party that actively initiated the closure) sends the last ACK confirmation message, it will enter the TIME_WAIT state and wait for a period of time (usually 2 times the maximum segment survival time (MSL) ). During this time period, the connection can still receive delayed packets.
MSL is the maximum survival time of TCP messages . Therefore, if TIME_WAIT persists for 2MSL, it can ensure that the unreceived or late message segments in both transmission directions have disappeared (otherwise the server will restart immediately and may receive
messages from Late data from the previous process, but this data is likely to be wrong, as shown in point 2 below)The TIME_WAIT state exists for the following main reasons:
Ensure that the peer receives the final acknowledgment : During the four waves of TCP, the last ACK confirmation message may be delayed or lost on the network. If the sender closes the connection immediately, this acknowledgment may not reach the peer, causing the peer to mistakenly believe that the connection was not closed properly. By entering the TIME_WAIT state, the sender can wait for a period of time to ensure that the peer receives the final acknowledgment.
Handling packets stuck in the network : In the network, packets may stay for a period of time due to network delay, router caching, or retransmission. If you immediately re-create a connection with the same IP address and port number after closing the connection, you may receive previously stranded packets, which may be misinterpreted as data belonging to the new connection. By entering the TIME_WAIT state, interference from stuck packets on new connections can be eliminated.
Ensure the uniqueness of the connection : The TIME_WAIT state also ensures the uniqueness of the connection in this state. During the TIME_WAIT state, the corresponding TCP connection quadruple (source IP, source port, destination IP, destination port) will be retained for a period of time. This prevents newly established connections from having the same quadruple as that connection, avoiding possible confusion and conflicts.
Although the TIME_WAIT state will occupy some resources and delay the release of the port used by the connection, it is an important mechanism in the TCP protocol that helps maintain the reliability, integrity, and uniqueness of the connection.
There is another problem, such as the server suddenly hangs up, that is, the server is the party that actively disconnects. At this time, the server will enter the CLOSE_WAIT state and must wait for a period of time before reconnecting , because in this state, the IP and The port is occupied ! This will cause bind to fail and the server cannot reconnect. If this happens during a festival with high consumption such as Double Eleven, the loss caused by this time will be very heavy. So in order to restart immediately in the TIME_WAIT state without waiting for the time to end, you need to use setsockopt().
setsockopt()
Set the socket descriptor option SO_REUSEADDR to 1, which means that multiple socket descriptors with the same port number but different IP addresses are allowed to be created .
That is to say, setsockopt() can be used for temporary relief. The server can quickly restart using the original IP address and port, because the original IP address and port are in the TIME_WAIT state and are unavailable!

TCP reliability mechanism
Confirmation response mechanism (supplementary)
Most of this content has been introduced above in the article. Here is some explanation of the content:
Data segment: It is composed of TCP protocol header and data part.
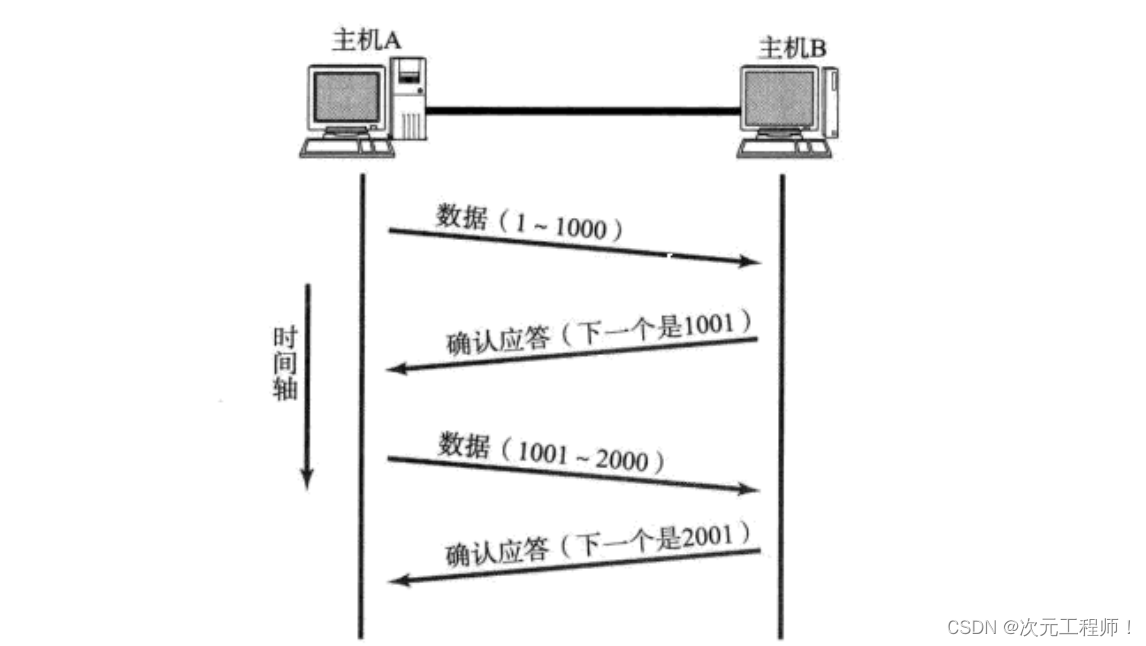
As we said before, TCP communication will send the sequence number to the other party, and then the other party will return it to itself to confirm the sequence number . So what exactly is this serial number?
Every time we send a message to the other party, we actually copy the data to our own sending buffer and then send it to the other party's receiving buffer. This buffer can be regarded as an array of char type, and each byte in the data will be numbered.
The 32-bit sequence number is the sequence number used to identify each byte in the TCP data stream.
For example, if I want to send 100 bytes of data, each data will be numbered separately until 100. After the receiver receives 100, it will send a confirmation sequence number of 101 to the sender, indicating that it expects the sender to send a sequence number starting from 101 next time.

 Timeout retransmission mechanism
Timeout retransmission mechanism
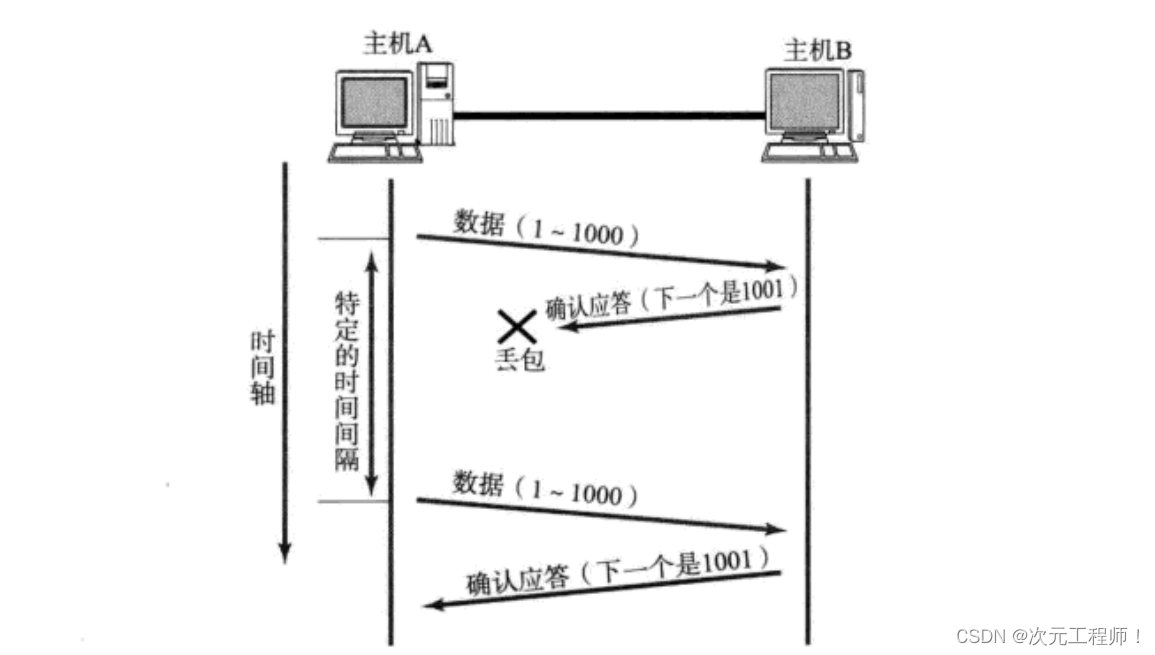
The timeout retransmission mechanism is a mechanism used in the TCP protocol to deal with packet loss . When the sender sends a data segment, it starts a timer (called a retransmission timer) and waits for the receiver to send the corresponding confirmation sequence number. If an acknowledgment is not received before the timer expires , the sender considers the packet lost and resends the packet.
There are two situations of data packet loss: one is that the data sent by the sender is lost , causing the receiver to not receive the data and cannot respond; the other is that the data sent by the receiver is lost , causing the sender to not receive ACK, confirmation sequence number and other information.
For the first case, if the data is not received within the specified time, the sender can resend the data.
For the second case, the receiver has received the data, but the ACK confirmation is lost. At this time, the sender will resend the same data, which will cause the server to receive duplicate data , and the server needs to deduplicate, so this How to solve it?
At this time, the serial number we mentioned above comes into play, and the server will receive it based on the received serial number. If the serial number is already owned, this part of the data is discarded directly, and deduplication is completed.

So, what is the appropriate size of the timeout ?
Under the most ideal situation, find a minimum time to ensure that "the confirmation response must be returned within this time." However, the length of this time varies with different network environments. If the timeout is set
too long , will affect the overall retransmission efficiency;
if the timeout is set too short , duplicate packets may be sent frequently.
In order to ensure high-performance communication in any environment, TCP will dynamically calculate the maximum timeout, such as 500ms.
If you still don’t get a response after retransmitting once, wait for 2*500ms before retransmitting.
If you still don’t get a response, wait for 4*500ms before retransmitting. And so on, increasing exponentially until a
certain number of retransmissions is reached. After the number of transmissions , if there is still no response, TC then P thinks that there is an abnormality in the network or the peer host and forcibly closes the connection.
Flow control mechanism (supplementary)
We have basically explained all of this above, you can just scroll up and search. Here is another question:
When performing flow control , how do we know the receiving capacity of the other party (the remaining space of the receiving buffer) for the first time ?
What if you don't know the other party's receiving capability when you send data for the first time, and you directly send data that exceeds the other party's receiving capability?
In fact, we need to know that sending data for the first time does not mean sending a message for the first time ! During the first three handshakes of communication , messages from both parties will be exchanged , which will include the other party's receive buffer size , that is, the 16-bit window size . Therefore, during the TCP three-way handshake, they already know the receiving capabilities of both parties.
When the other party's receiving buffer is full and can no longer accept data, it will detect notifications in two ways.
1. Every once in a while, the sender will send a window detection packet to detect whether the other party's receiving buffer can receive data.
2. When the receiver's receiving buffer can accept data, a window update notification will be sent to the sender to inform the other party that data can be sent.

★Sliding window
Sliding window workflow
We discussed the confirmation response mechanism above. For each data segment sent, an ACK confirmation response must be given. After receiving ACK, the next data segment is sent . This has a major disadvantage, that is, poor performance . Especially This is when the data round-trip time is longer.
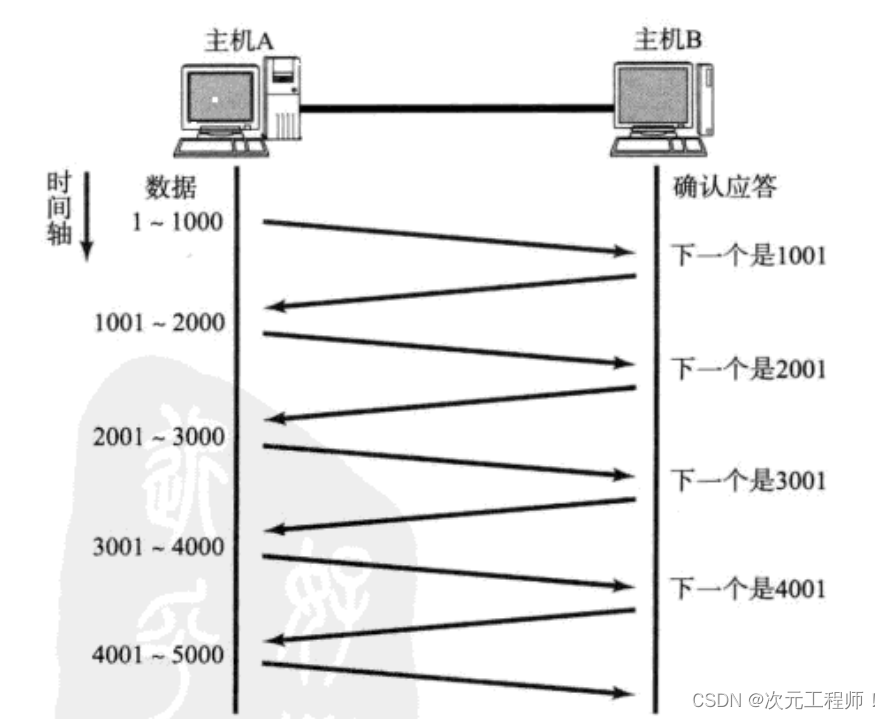
Since the performance of this one-send-one-receive method is low, we can greatly improve performance by sending multiple pieces of data at once (actually overlapping the waiting times of multiple segments ).

So how to control the data sent? The sliding window is used here .
The sliding window is a mechanism in the TCP protocol used to control data transmission between the sender and receiver. It is a dynamic data buffer used to manage data sequence numbers that have been sent but not acknowledged.
The window size refers to the maximum value of data that has been sent but not confirmed . (Currently understood, congestion control will correct it later)
That is to say, the sliding window wants: 1. To send more data to the other party; 2. To ensure that the other party has time to receive it.
Too much data was sent and the other party had no time to receive it. It is necessary to control sending as much data as possible but within the receiving capabilities of the other party .
So the essence of the sliding window : the sender can push the upper limit of data to the other party at one time.
This upper limit is determined by the receiving ability of the other party .
The process is:
When sending four data segments (not necessarily four data segments, depending on the specific situation), there is no need to wait for any ACK, just send it directly ;
After receiving the ACK , the sliding window moves backward and continues to send the data of the fifth segment ; and so on;
in order to maintain this sliding window, the operating system kernel needs to open a sending buffer to record which data is currently unanswered; only acknowledgment (ACK) can be deleted from the buffer, that is, the sliding window is in its own send buffer and is part of its own send buffer.
The larger the window, the higher the throughput of the network because more data can be sent.

Common sliding window issues
As mentioned above, the sliding window is essentially the upper limit of the sender sending data to the other party at one time. This upper limit, that is, the window size, is actually maintained by two pointers. Win_start points to the starting position of the sliding window, and win_end points to the end position of the sliding window. Win_end =win_start + Opposite receiving capability.
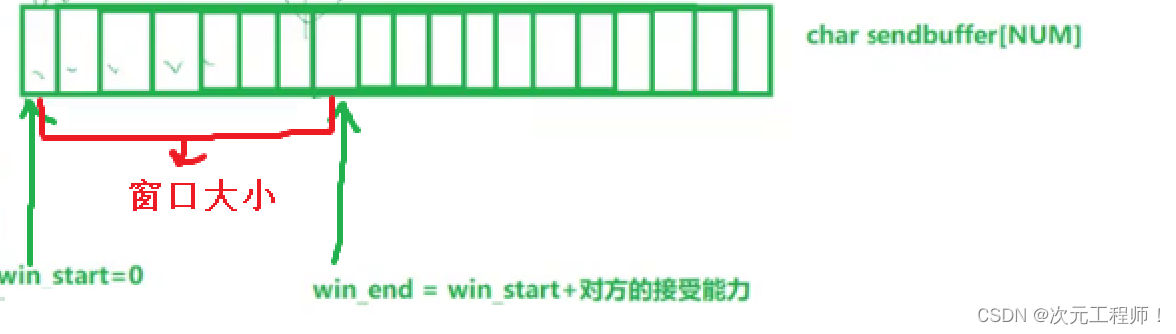
Each time you update , you only need to set win_start = the confirmation sequence number in the received response message; win_end = win_start + the window size in the received response message.
Answer a few questions:
1. Does the sliding window have to move to the right every time?
The answer is not necessarily. Assume that the other party's receiving buffer has not been delivered to the upper layer, resulting in win_end remaining unchanged and not moving to the right.
2. Can the sliding window be 0?
The answer is yes, when win_start = win_end, the sliding window is 0. This usually means that the other party's receiving buffer is in a full state at this time.
3. If the initial response message is not received, but the middle one is received, is this possible and will it affect it?
The answer is maybe, but it doesn't matter. First, the acknowledgment sequence number in the intermediate acknowledgment message ensures that all messages before this sequence number have been successfully received. This confirmation message will not be sent if all previous messages have not been received.
For example, the sliding window is now 1000-5000. I received a confirmation number 3001, but did not receive the confirmation number 2001. But it does not affect it. This means that the data before 3001 has been received, but the confirmation message is lost.
(Note that the example in the picture has different data from the example just cited, so don’t get confused)
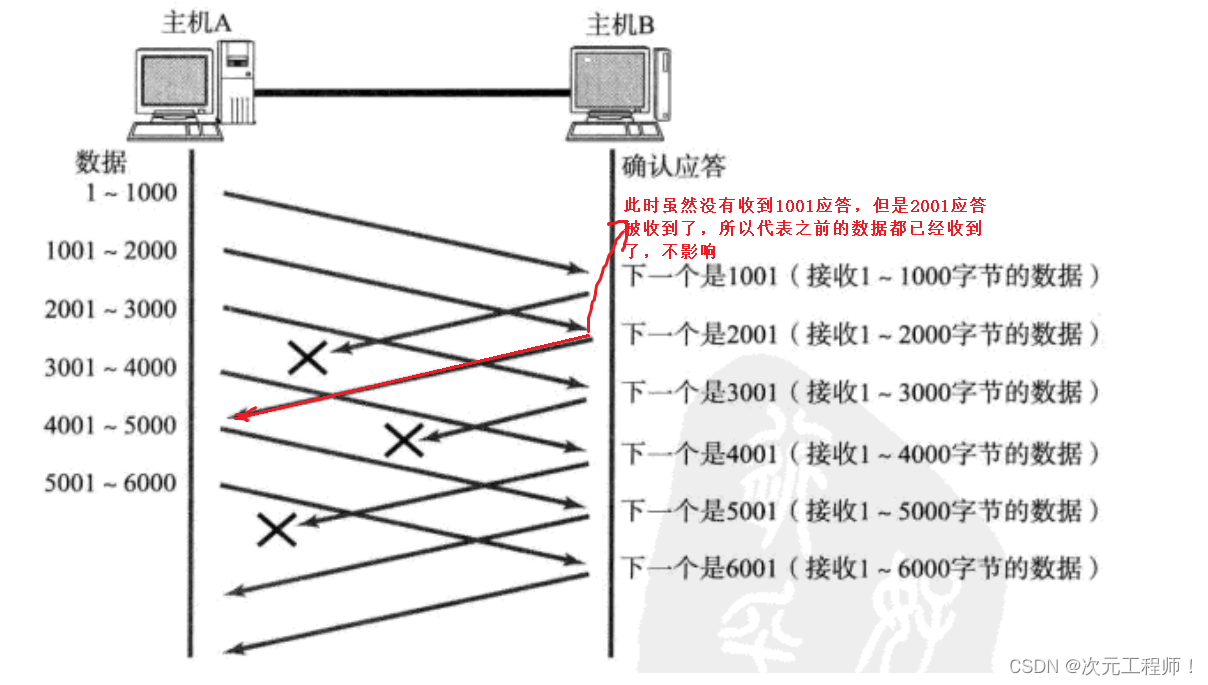
4. The meaning behind timeout retransmission : when no response is received, the data must be temporarily saved.
Assume that 1000-2000 is really lost, but 2001-3000, 3001-4000, 4001-5000 data have been received, but in the end the receiver can only return 1001 to you , because this segment of the message has not been received, even if After all the subsequent ones have been received, only 1001 can be returned. If the timeout period expires at this time, the temporarily saved data will be used for retransmission.
Fast retransmission
- When a certain segment (for example, 1-1000) is lost, the sender will always receive ACKs like 1001, which is like reminding the sender "What I want is 1001";
- If the sending host receives the same "1001" response three times in a row, it will resend the corresponding data 1001 - 2000;
- At this time, after the receiving end receives 1001, the ACK returned again is 7001 (because 2001 - 7000). The receiving end has actually received it before, and it was placed in the receiving buffer of the receiving operating system kernel;
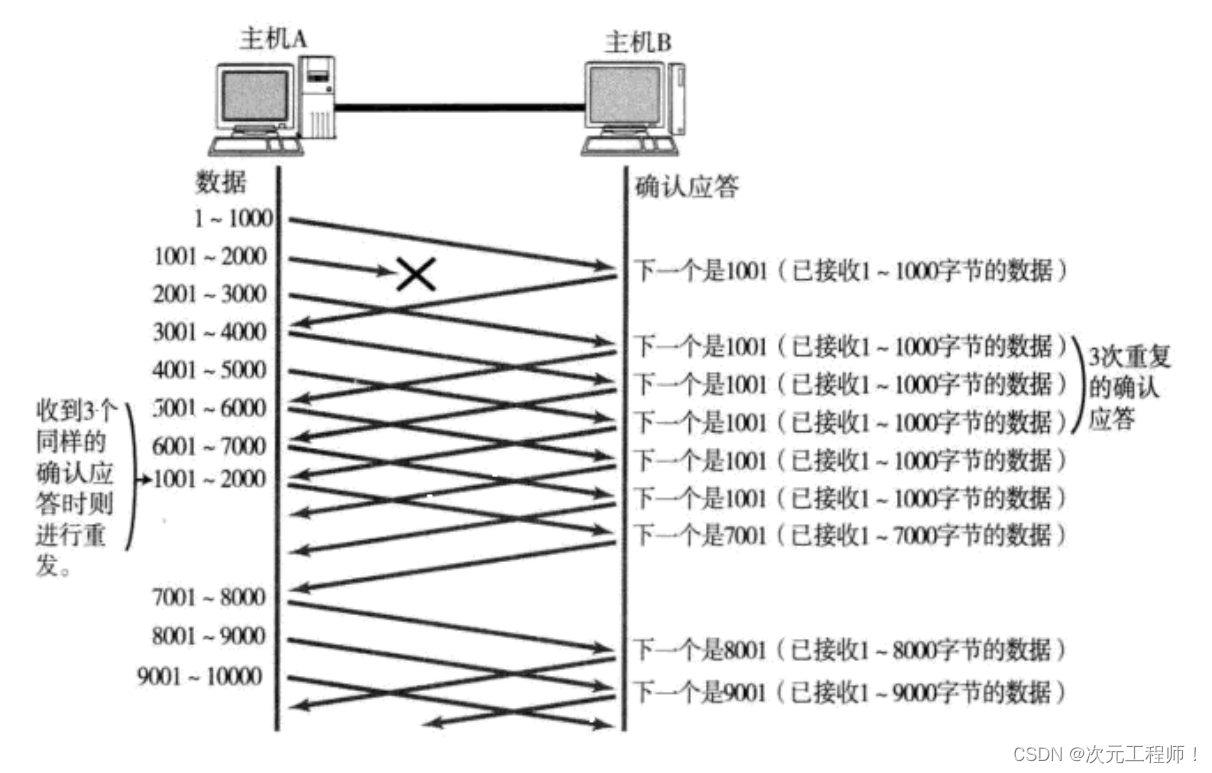
This mechanism is called "high-speed retransmission control" (also called "fast retransmission"). It means that it will retransmit immediately after receiving three identical confirmation response messages.
So since there is fast retransmission, why do we need timeout retransmission ? Fast retransmission is not faster, so why do we have to wait?
First, fast retransmission is a mechanism that is triggered after receiving three consecutive identical response messages . If I only send two data segments, then there is no way to retransmit.
Second, our response message may also be lost, making it impossible to retransmit it in time.
congestion control
Although TCP has the sliding window as a killer, it can send large amounts of data efficiently and reliably. However, if a large amount of data is sent at the beginning, it may still cause problems.
We have been solving problems at both ends before, such as the sending and receiving problems between the client and the server, but we have not yet talked about the network-related problems during their transmission .
There are many computers on the network, and the current network status may already be relatively congested. Without knowing the current network status, rashly sending a large amount of data is likely to make things worse.
TCP introduces a slow start mechanism to first send a small amount of data, explore the path, find out the current network congestion status, and then decide at what speed to transmit data.
Here we refer to the concept of congestion window , congestion window: when a single host sends a large amount of data to the network at one time, it may cause network congestion.
Therefore, the size of the sliding window value at this time not only depends on the receiving ability of the other party, but also the size of the congestion window.
The value of the sliding window is the minimum value of the congestion window and the other party's window size (receiving capability).
When sending starts , the defined congestion window size is 1
Each time an ACK response is received, the congestion window is +1, and then the minimum value of the congestion window and the window size of the receiving end is taken as the actual sent window value.
According to the above congestion window growth rate, it is an exponential "slow start". It is full initially, but the growth rate is very fast.
In order not to grow so fast, the congestion window cannot be simply doubled. A threshold
called slow start is introduced here . When the congestion window exceeds this threshold , it will no longer grow exponentially , but will grow linearly .
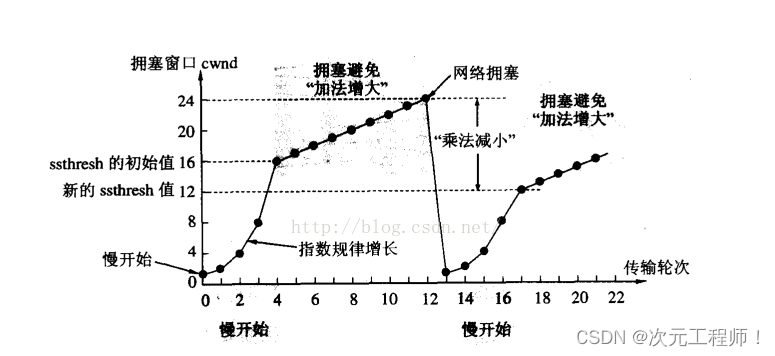
- When TCP starts, the slow start threshold is equal to the maximum value of the window each time;
- During each timeout and retransmission, the slow start threshold will become half of the original value, and the congestion window will be reset to 1.
A small amount of packet loss , we just trigger a timeout retransmission ; a large amount of packet loss, we think the network is congested;
when TCP communication starts, the network throughput will gradually increase; as the network becomes congested, the throughput will immediately decrease;
congestion Control, in the final analysis, is the TCP protocol
1. Transmit data to the other party as quickly as possible 2. But avoid compromises that put too much pressure on the network.
delayed response
If the host receiving the data returns an ACK response immediately after receiving the data, the return window may be relatively small because the upper layer has not had time to receive it at this time. The receiving capability (16-bit window size) returned to the other party will be smaller.
We need to know that in network transmission, the more data in a single IO , the higher the throughput and the higher the efficiency.
- Assume that the buffer at the receiving end is 1M. 500K data is received at one time; if the response is immediate, the returned window is 500K;
- But in fact, the processing speed of the processing end may be very fast, and 500K data is consumed from the buffer within 10ms;
- In this case, the receiving end's processing is far from reaching its limit. Even if the window is enlarged, it can still handle it;
- If the receiving end waits for a while before responding , for example, waits for 200ms before responding, then the window size returned at this time is 1M;
It must be remembered that the larger the window, the greater the network throughput and the higher the transmission efficiency. Our goal is to maximize transmission efficiency while ensuring that the network is not congested.
So can all packets be responded to with delay?
The answer is definitely not , for two reasons:
1. Quantity limit: respond every N packets. Suppose that when a packet comes for the first time, I don't respond. When the second packet comes, I will return a response. Waiting for the second packet gives time to deliver the data to the upper layer.
2. Time limit: Respond once if the maximum delay time is exceeded. Assume that a packet comes for the first time, and then a period of time passes. Of course, the timeout retransmission time cannot be exceeded, and then a response is sent to the other party. This period of time is enough to deliver the data to the upper layer.
The specific number and timeout period vary depending on the operating system; generally N is 2, and the timeout period (not for timeout retransmission) is 200ms.

piggyback reply
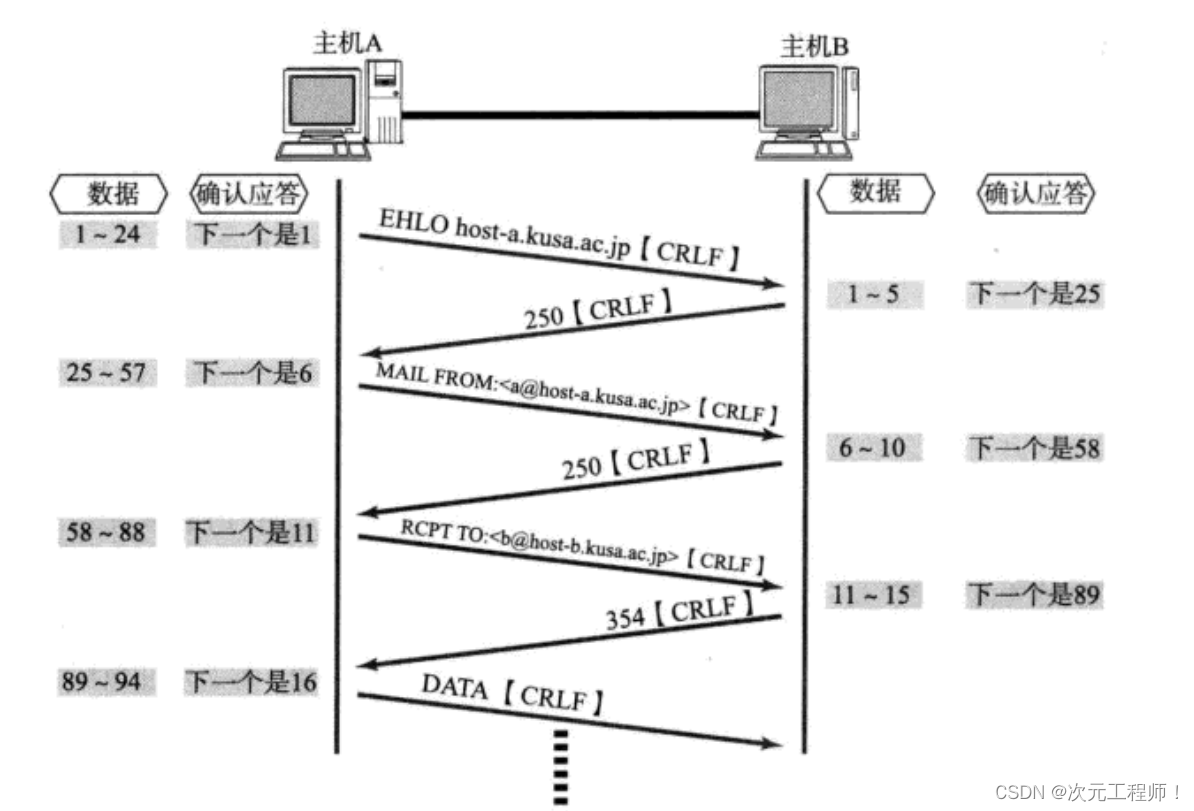
We found that the client and server basically send and receive . For every transmission and reception, an ACK response needs to be sent to the other party . However, if you simply send an ACK response and then send data every time, it will cause inefficiency. So since we are sending a message, we can just send the ACK along with it. That is, set the ACK flag bit in the message containing data to 1. In this way, you only need to send the message once (we have basically always defaulted to this)
TCP Summary
Why is TCP so complicated? Because it must ensure reliability while improving performance as much as possible.
Mechanisms to ensure reliability :
- Checksum
- Serial number (arriving in order)
- Confirm response
- Timeout and resend
- Connection management
- flow control
- congestion control
Mechanisms to improve performance :
- sliding window
- Fast retransmission
- delayed response
- piggyback reply
Understand byte stream oriented
Let’s first understand the following process.
Create a TCP socket, and create a send buffer and a receive buffer in the kernel.
- When calling write, the data will first be written into the send buffer;
- If the number of bytes sent is too long , it will be split into multiple TCP packets and sent out;
- If the number of bytes sent is too short, it will wait in the buffer until the buffer length is almost the same, or send it out at another appropriate time ;
- When receiving data, the data also reaches the kernel's receive buffer from the network card driver;
- The application can then call read to get data from the receive buffer;
Due to the existence of the buffer, the reading and writing of TCP programs do not need to match one-to-one , for example:
- When writing 100 bytes of data, you can call write once to write 100 bytes, or you can call write 100 times and write one byte each time; or you can send it midway due to some TCP policies, etc.
- When reading 100 bytes of data, there is no need to consider how to write it. You can read 100 bytes at a time or read two bytes at a time, repeating 50 times;
This is different from UDP's datagram. UDP writes and sends several times, just like sending express. How many items you send, I will receive a few here. If you only receive one, it means you must send it. Got one piece.
TCP is like catching water with a bucket. Whether it is poured with a pipe or bowl after bowl, all that is needed in the end is the water in the bucket, regardless of how you complete it. This is byte stream oriented.
TCP only needs to hand over the data to the other party. As for how to parse the data, it is what the upper application layer protocol does . TCP only needs to send the data to the other party safely and reliably. So there is the application layer http protocol and so on.
Sticky bag problem
We just said it above. TCP is oriented to byte streams. What the receiver receives is a series of byte data sent by the sender. Then the application program sees such a series of byte data and does not know which part starts from which part. It is a complete application layer data packet.
So how to avoid the sticky package problem? It boils down to one sentence, clarify the boundary between the two packages
- For fixed-length packets, just ensure that they are read at a fixed size every time ; for example, UDP, there is a 16-bit UDP length in the header. Data can be extracted based on this.
- For variable-length packets, you can agree on a field of the total length of the packet at the position of the packet header , so that you know the end position of the packet;
- For variable-length packets, you can also use clear delimiters between packets (the application layer protocol is determined by the programmer, as long as the delimiter does not conflict with the text);
So does UDP have a sticky problem?
The answer is non-existent. As mentioned just now, the UDP header has a 16-bit UDP length, which can clarify the total length of the data and the boundaries of the data. When using UDP, you will either receive a complete UDP message or not. There will be no "half" situation.
At this point, the relevant content of the TCP protocol has been explained. From the understanding and role of the TCP protocol header to the various mechanisms behind TCP to achieve reliability, it has been explained in very in-depth detail. If you have the patience to read this article, you will definitely gain a lot!