Article directory
Preface
Java operates on data through streams. Learning IO streams well can easily implement data input/output operations, and its importance is self-evident.
以下是本篇文章的思维导图
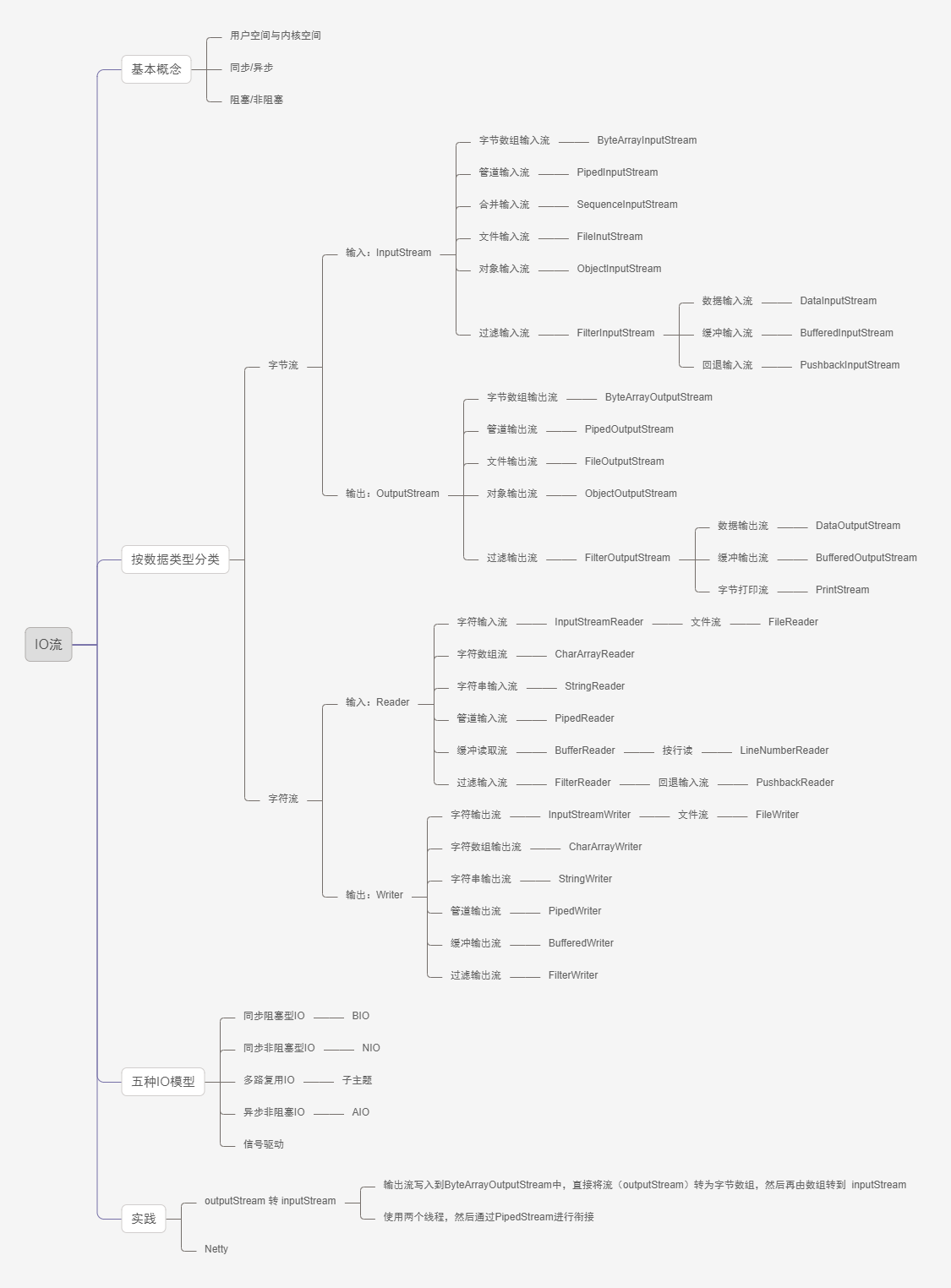
1. Basic concepts
1.1. User space and kernel space
In order to protect the security of the operating system, the memory is divided into kernel space and user space. If a user process wants to operate data, it must issue instructions to the kernel (Kernel) through a system call to copy the data from the kernel space to the user space before it can operate the data.
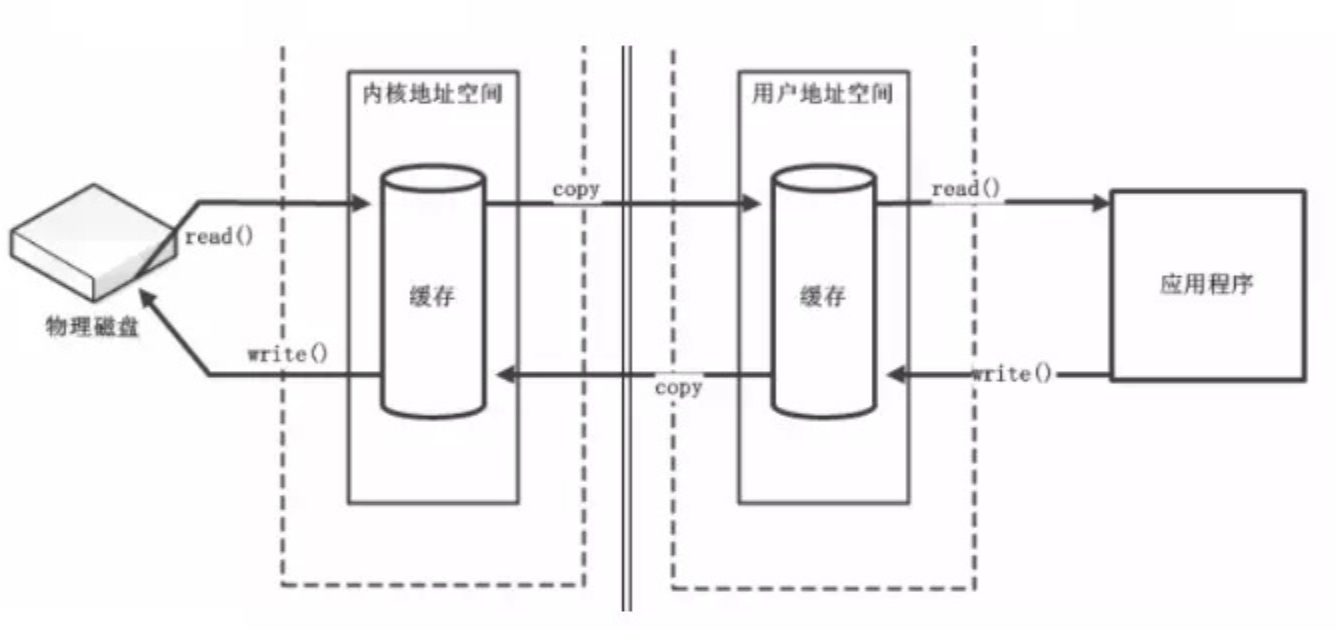
1.2. Operating system IO
Take the Linux operating system as an example. Linux is a system that operates all external devices as files. Then our operations on external devices can be regarded as operations on files. Since processes in LINUX cannot directly operate I/O devices, they must request the kernel (kernel) to assist in completing I/O actions through system calls. The kernel will Each I/O device maintains a buffer.
For an input operation, after the user process makes a system call, the kernel will first check whether there is corresponding cached data in the buffer. If not, it will read it from the device. Because device IO is generally slow and needs to wait; kernel buffering If there is data in the area, it is copied directly to the process space.
A complete IO is divided into two stages:
- Read data from device space (network, disk, etc.) and
到buffer in kernel space- Copy data from kernel space buffer to
到user process space
1.3. Java IO stream
Java's io is the basis for realizing input and output, and can conveniently realize data input and output operations.
In Java, different input/output sources (keyboard, files, network connections, etc.) are abstractly expressed as "streams". Allows Java programs to use it in the form of streams 相同的方式来访问不同的输入/输出源. A stream is a sequenced collection of bytes with a starting point and an end point. It is a general term or abstraction for data transmission. That is, the transmission of data between two devices becomes a stream 流的本质是数据传输.
IO is divided into three types according to storage forms: memory IO, network IO and disk IO. What we usually call IO refers to the latter two. Network IO is the pulling and output of data through the network. Disk IO mainly reads and writes to the disk.
1.4. Classification of IO streams
● According to stream direction: input stream, output stream;
● According to data type: byte stream (8-bit bytes), character stream (16-bit bytes).
The difference between character stream and byte stream:
- The byte stream itself has no buffer, and the character stream itself has a buffer. Therefore, the efficiency of buffering the byte stream is significantly improved compared to buffering the character stream.
- Byte streams can handle all files, while character streams can only handle plain text files.
以下是常见流的分类表:

1.5. Extension
1.5.1. Synchronization and asynchronousness
Synchronization and asynchronous focus are 调用方和被调用方的交互essentially communication mechanisms.
Synchronous: After the caller initiates the call, it waits or polls to see if the callee is ready.
Asynchronous: After the caller initiates the call, it starts doing its own thing. When the callee completes, it will be notified that the IO is completed.
1.5.2. Blocking and non-blocking
Blocking and non-blocking focus on 调用者在等待调用结果时的状态describing the current thread state.
Blocking: After the caller initiates the call, it waits
线程会被挂起(不能去做其他事情).
Non-blocking: After the caller initiates the call, it will immediately receive a status value and the thread will do other things.
1.5.2. Combination mode
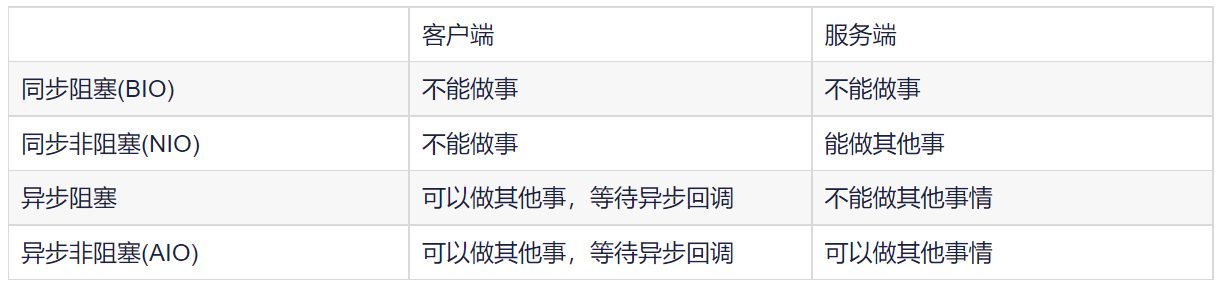
Synchronous and asynchronous are relative to the client, while blocking and non-blocking are relative to the server. Therefore, asynchronous can improve the client experience, and non-blocking can avoid the server from creating new threads (or processes), reducing the consumption of CPU resources.
2. Five IO models
Because IO is divided into two stages, both of which require waiting and data copying, which greatly limits the execution efficiency of IO. How can this performance bottleneck be solved?
1. Reduce the proportion of waiting in IO
2. Avoid data copying
In order to solve IO efficiency, five IO models are proposed
2.1. Synchronous blocking IO-BIO
After the user process calls the kernel process, it needs to wait for the kernel IO to be completely completed before returning to the user space. As shown below:
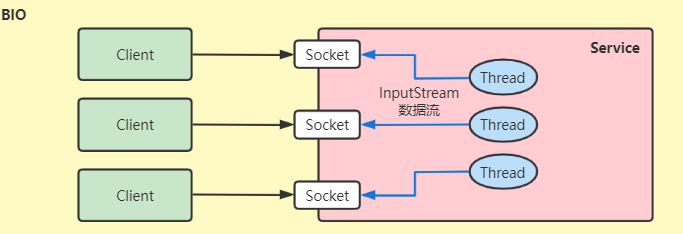

After the user process initiates recvfrom, it enters the blocking state
After the kernel process receives recvfrom, it begins to prepare data and waits for the data to arrive in the kernel buffer.
After the kernel process receives the complete data, it will copy the data from the kernel buffer to the user space memory, and then return the result (such as: number of copied data bytes)
After the user process receives the result returned by the kernel, it is released from the blocking state and continues to run.
recvfrom: linu system call function.
advantage:
Development is simple. When the user mode process is blocked, it will not occupy CPU resources.
shortcoming:
In high-concurrency scenarios, a large number of threads are needed to maintain a large number of network connections, which results in high memory and thread switching overhead and low performance.
2.2. Synchronous non-blocking IO-NIO
After the user process calls the kernel process, it can execute subsequent instructions without waiting for the kernel IO operation to be completely completed. As shown below:
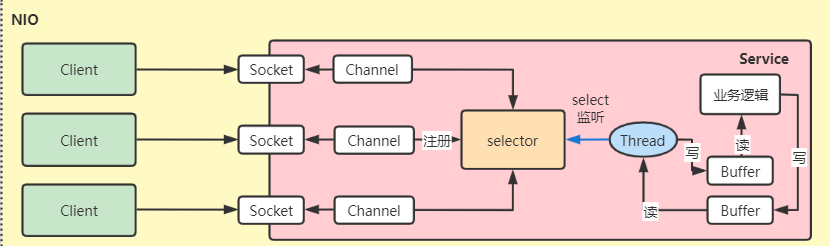

After the user process initiates recvfrom, the kernel process does not prepare the data and directly returns the EWOULDBLOCK error.
The user process will perform other tasks, during which the user process will continuously initiate recvfrom. If an error is received, it means that it is not ready yet.
After the kernel process receives complete data, the user process will be blocked after initiating recvfrom until the data is copied from the kernel buffer to user space.
After the user process receives the result returned by the kernel, it begins to process the received data.
advantage:
After the user-mode process calls the kernel-mode process, there is no need to block, and the real-time performance is good
shortcoming:
User-mode processes need to continuously poll kernel-mode processes, occupying a large amount of CPU resources and wasting CPU resources. If there are 1000 threads, there will be 1000 system calls per unit time to poll the execution results.
Polling time is difficult to control.
Polling requires programmers to read file descriptors in a loop, and the code is complicated to write.
2.3. Multiplexed IO (asynchronous blocking IO)
2.3.1. Based on select/poll
Select is a system call provided by the kernel, which supports querying the available status of multiple system calls at one time. The 当任意一个结果状态为可用时就返回user process initiates a system call again to read data.
In the multiplexed IO model, the IO of multiple processes can be registered to a multiplexer (select), and then there will be a thread that continuously polls the status of multiple sockets, only when the socket actually has read and write events. , the actual IO read and write operations are actually called. Because in the multiplexed IO model, 只需要使用一个线程就可以管理多个socket,系统不需要建立新的进程或者线程there is no need to maintain these threads and processes, and IO resources will only be used when there are actual socket read and write events, so it greatly reduces resource usage.

The user process calls kernel select, registers the socket connection that initiates recvfrom into the Linux select/poll selector, and the kernel starts the polling process.
In the kernel space, traverse all file descriptors and add socket connections with ready data to the ready list.
When the ready socket list registered on the user process polling selector has a value, the user process initiates recvfrom and blocks, copying the data to the user buffer.
After the user process completes the copy, the kernel returns the result, the user process unblocks the state, starts processing user space data, and continues to execute subsequent instructions.
advantage:
A selector thread can handle a large number of network requests at the same time without creating a large number of threads, reducing system overhead.
shortcoming:
The bottom layer of select is implemented using an array, and there is a limit on the number of connections, so poll came into being. The bottom layer is implemented using a linked list, which solves the limitation on the number of connections.
Select and poll solve the problem of repeated invalid system calls in NIO, but they cause new problems:
- File descriptor set copy between user space and kernel space
内核循环遍历文件描述符集合,浪费CPU时间
Although select/poll reduces system scheduling initiated by user processes, the workload of the kernel only increases, and there are invalid loop traversals in the kernel.
2.3.2. Based on epoll
Through event driving, the inner loop traversal introduced by select/poll is reduced, as shown below:

Compared with select/poll, epoll has two more system calls, among which epoll_create establishes a connection with the kernel, epoll_ctl registers events, and epoll_wait blocks the user process and waits. IO events.

The user process calls kernel epoll_create to create an eventpoll object, and then uses kernel epoll_ctl to put the socket that needs to be monitored into the rbr (red-black tree) of the eventPoll object. At the same time, it will register a callback function for the kernel interrupt handler. (If this handler handler is interrupted, it will be put into rdlist (ready list))
When the socket receives data, it will initiate a hard interrupt to the CPU. The kernel executes the callback function and writes the socket data into the rdlist (ready linked list). When the kernel epoll_await is executed, the data in the ready linked list is immediately returned.
The user process takes the fd in the linked list and performs the actual read/write operation.
advantage:
A selector thread can handle a large number of network requests at the same time without creating a large number of threads, which reduces system overhead and
avoids copying data back and forth through shared space.
shortcoming:
epoll improves IO execution efficiency, but the first stage of IO execution, the data preparation stage, is still blocked.
2.3.3. Comparison

2.4. Signal driver IO-SIGIO
Signal-driven IO does not block the user process during the data preparation phase. After the kernel prepares the data, it sends a SIGIO signal to notify the user process to perform IO operations.

The user process initiates the sigaction system call, the kernel process returns immediately, and the user process continues execution.
After the kernel process prepares the data, it will send a SIGIO signal to the user process
After the user process receives the signal, it will initiate the recvfrom system call
The user process enters the blocking state and copies the data to the user space buffer. After copying, the received data is processed.
advantage:
During the data preparation phase, the user process will not be blocked.
Netty supports NIO, making development simple and practical.
shortcoming:
When the second phase of IO execution is [copying data to the user space buffer], the user process is blocked.
2.5. Asynchronous non-blocking IO-AIO
Asynchronous IO truly realizes non-blocking in the entire IO process, that is, the user process (thread) is non-blocking in both stages of waiting for datagrams and copying datagrams from the kernel to user space. The process is as follows:

After the user process initiates the sigaction system call, the kernel process immediately returns a status value, and the user process does other things.
The kernel process copies the received data
用户空间and then notifies the user processAfter the user process receives the notification, it directly processes the data received by the user space.
Similar to Java's callback mode, the user process registers callback functions for various IO events in the kernel space, which are actively called by the kernel.
advantage:
Completely asynchronous
shortcoming:
Linux does not have an advantage over NIO in AIO performance, and its implementation is not mature.
Summarize
The above is what I will talk about today. This article starts with file reading and writing in the operating system, introduces synchronous, asynchronous, blocking, non-blocking and their combined IO modes, and also introduces the five IO modes in the Linux operating system. Model, I believe everyone should have a certain understanding of it. If there is anything inappropriate, please correct it.
Reference materials:
1. If you want to ask a technical question, how much do you know about the IO model?
2. Detailed explanation of Java IO stream
3. Detailed explanation of the five IO models in Java