PSRT: Pyramid Shuffle-and-Reshuffle Transformer for Multispectral and Hyperspectral Image Fusion
(PSRT: Pyramid Shuffling Transformer for multispectral and hyperspectral image fusion)
Transformers have received a lot of attention in computer vision. Since Transformer has global self-attention characteristics, its computational complexity has a quadratic relationship with the number of tokens, which limits its practical application. Therefore, the problem of computational complexity can be efficiently solved by computing self-attention in groups of smaller fixed-size windows . In this article, we propose a new Pyramid Shuffle-and-Reshuffle Transformer (PSRT) task, Multispectral and Hyperspectral Image Fusion (MHIF). Considering the strong correlation between different patches and the complementary information between high-similarity patches in remote sensing images, we designed the Shuffle-and-Reshuffle (SaR) module to consider the information between global patches in an effective way. Interaction. In addition, a pyramid structure based on window self-attention is used to support detail extraction. Extensive experiments on four widely used benchmark datasets demonstrate the superiority of the proposed PSRT over several state-of-the-art methods with some parameters.
INTRODUCTION
Multispectral and hyperspectral image fusion (MHIF) is a classic task in computer vision involving hyperspectral data with high spectral resolution. It has limited spatial resolution due to certain physical constraints. MHIF aims to generate high-resolution hyperspectral images (HR-HSI) by fusing high-resolution multispectral images (HR-MSI) and low-resolution hyperspectral images (LR-HSI). These results can be used for object recognition, classification and segmentation. Despite many recent efforts, the design of efficient techniques for the problem at hand remains a challenging task.
Convolutional Neural Networks (CNN) shine in the field of computer vision due to their high accuracy. Although convolution operations have been widely analyzed and exploited, well-known shortcomings include redundancy and spatial agnosticism in the convolution kernel. In particular, the convolution kernels are shared in different locations of the image. Therefore, the results are region-independent, making it difficult to capture long-range dependencies in feature maps. Recently, Transformers have performed well in many computer vision domains, mainly due to their strong ability to represent the long-distance relationships that are crucial for MHIF.
A Transformer has been widely used for the purpose of modeling non-local relationships in images. In previous work, Vision Transformer (ViT) considered the use of transformers in natural language processing (NLP) for image classification. It divides the image into fixed-size blocks and then embeds them into linear layers. Similar to the processing of Transformer in NLP, patches are treated as tokens, and then a self-attention mechanism is performed on the patches. ViT's layered framework inspired the use of Transformer in the field of computer vision. Compared with ViT, pyramid vision Transformer (PVT) introduces a pyramid structure for segmentation and object detection. In this way, PVT can be used as the backbone in dense prediction tasks, such as CNNs. Recently, Swin Transformer has shown great potential and high efficiency. Similar to PVT, Swin Transformer also adopts a layered design, including four stages. Similar to [19], in order to expand the receptive field in CNN, the resolution of feature maps is reduced at each stage. Window self-focus in Swin Transformer enables the model to handle large size images. The Shifted Window operation establishes a long-range dependency between each independent window, while masking implements attention calculations for irregular windows without changing the original method. The development of high-level computer vision tasks has also led to innovation in low-level tasks. In fact, image restoration using Swin Transformer (SwinIR) borrows the structure of Swin Transformer to achieve competitive performance in low-level tasks such as image super-resolution, image de-raining, image denoising and JPEG compression. SwinIR takes full advantage of Swin Transformer and designs cascade blocks for deep feature extraction.
In this article, we introduce the Pyramid Shuffle-and-Reshuffle Transformer (PSRT), a new stage-to-stage hierarchical framework designed for MHIF to interact with information in a new way. In summary, the contributions of this article are as follows.
1) We propose the so-called PSRT MHIF task, which combines the Shuffle-and-Reshuffle (SaR) strategy and multi-scale feature extraction to learn local and distant representations, and reduces the computational effort compared to ViT.
2) Customized SaR strategies can propagate information between different windows and improve the efficiency of modeling long-distance dependencies. In addition, the design of the window pyramid structure can capture features of different granularities (resolutions) to recover the detailed information of MHIF in a suitable way.
3) We demonstrate the performance of the proposed method on four commonly used datasets, namely, Chikusei, Columbia Imaging and Vision Laboratory (CAVE), Harvard and Pavia. The results show that this method can achieve state-of-the-art performance with fewer parameters.
RELATED WORKS
CNNs and MHIF
Recent attempts to solve MHIF tasks are usually based on the use of CNNs. Spatial-Spectral Reconstruction Network (SSRNet) [53] proposed a physical direct CNN model and designed two loss functions for spatial and spectral reconstruction respectively. The residual mechanism [54] is widely used to optimize network structure, and methods such as Residual Two-Stream Fusion Network (ResTFNet) use it to avoid model degradation caused by deep networks. Multispectral and Hyperspectral Fusion Network (MHFNet) uses a convolution expansion optimization algorithm to obtain a new network with the aim of improving interpretability. Model Guidance (MoG) - Deep Convolutional Network (DCN) adopts U-Net DCN, which can exploit the multi-scale dependence of HSI. After MoG expansion, the entire network is trained end-to-end using a DCN-based denoiser. Hyperspectral super-resolution network (HSRNet) utilizes channel attention [59] and spatial attention modules to extract information from different dimensions. Although CNN is a powerful structure, the use of Transformers proves to have great potential for computer vision.
Self-Attention in MHIF
The core module of Transformer is the self-attention mechanism. Unlike the convolution operation in CNN, the self-attention mechanism can theoretically expand the receptive field infinitely, thereby correlating different patches with each other. However, directly applying self-attention to feature maps in a pixel-to-pixel manner leads to a drastic increase in computational burden. ViT cleverly splits the feature map into fixed-size patches, linearly embeds each patch, and feeds the sequence of resulting vectors to a standard Transformer encoder. PVT inherits the advantages of CNN and Transformer and creates a unified backbone for various visual tasks, directly replacing the CNN backbone. PVT differs from ViT in that it can be trained on dense partitions of images to achieve high-resolution output, and it utilizes a stage-to-stage structure to reduce computation. In tokens-to-token (T2 T)-ViT, a new tokenization for ViT has been developed, where adjacent tokens are further processed through splicing to achieve the purpose of aggregating information and reducing parameters. In addition, researchers have also tried to apply Transformer to low-level tasks. For example, the SwinIR method relies on a robust model for image restoration, where the structure of the Swin Transformer has been directly used to build the Transformer block for deep feature extraction.
Shuffle-Wise Operation
In recent years, works such as [62] and [63] have addressed the problem of creating cross-window connections through Shuffle operations. For easier understanding, assume that the input is a 1-D sequence to maintain generality, and consider window-based self-attention with an input of M window size and N tokens. Shuffle Transformer first uses selfattention, reshapes the spatial input into [M and (N/M)], transposes, and then flattens it to serve as the input to window-based selfattention. This type of operation enables remote cross-window connections by grouping tokens from multiple windows. Object Context for Semantic Segmentation (OCNet) is based on two stages, namely, local and global, to achieve cross-window connections. The first stage uses window-based self-attention to process local information, while the other stage reshapes the input space into [(N/M) and M], transposes, and then flattens it to treat it as window-based self-attention. Note the input. The latter approach shows a critical flaw; that is, if the window size M in the first layer is small, the number of windows (N/M) is quite high.
Motivation
There are many similar plaques within HSI, and they are all closely related. Through the ViT model, patches at different positions can be related to each other to achieve the purpose of restoring image details, but the calculation amount of this method has a quadratic relationship with the input. The window self-attention method solves the problem of high computational cost, but limits the ability to model long-range dependencies. 
(Fig.1 The solid lines divide the plane into several fixed-size windows, while the dot grid is used to divide the original window into four equal parts. The blue block represents a quarter of the content in the window, for example, it has 2 × 2 tokens. (a) The shift window method applied to Swin Transformer [1] moves the blue block to the adjacent window. (b) Shuffle operation is performed on the PSRT block for similarity calculation, and the blue blocks of different windows are Color blocks are gathered into a window, and local information is propagated to the global area through window self-focus.)
Swin Transformer solves these problems by: 1) moving the original window by half the window size to get a new window; and, at the image boundaries, aligning some of the newly generated windows with one-quarter and one-half of the original window combination; 2) utilize masking operations to independently compute self-attention of the original quarter and half windows; and 3) re-shift the computed windows. In Figure 1(a), we can observe that after the shifting and masking operations, the size of the windows close to the image boundary becomes smaller. Therefore, the mask forces a portion of the attention matrix to be negative, resulting in insufficient self-attention computation for windows located at image boundaries. This problem weakens the information interaction at image boundaries, thus motivating us to improve Swin Transformer through the proposed SaR strategy, which does not use any mask to achieve global attention. Figure 1(b) shows the status of the window after using the proposed SaR strategy. By shuffling planes according to given rules and then performing window self-attention, long-distance connections can be achieved to obtain global correlation in a fast manner. Multi-scale design is crucial to MHIF, and window attention is the biggest advantage of Swin Transformer. Therefore, we develop multi-scale window attention (i.e., given PSRT blocks) to enrich features and produce better information interaction.
METHODOLOGY
Overview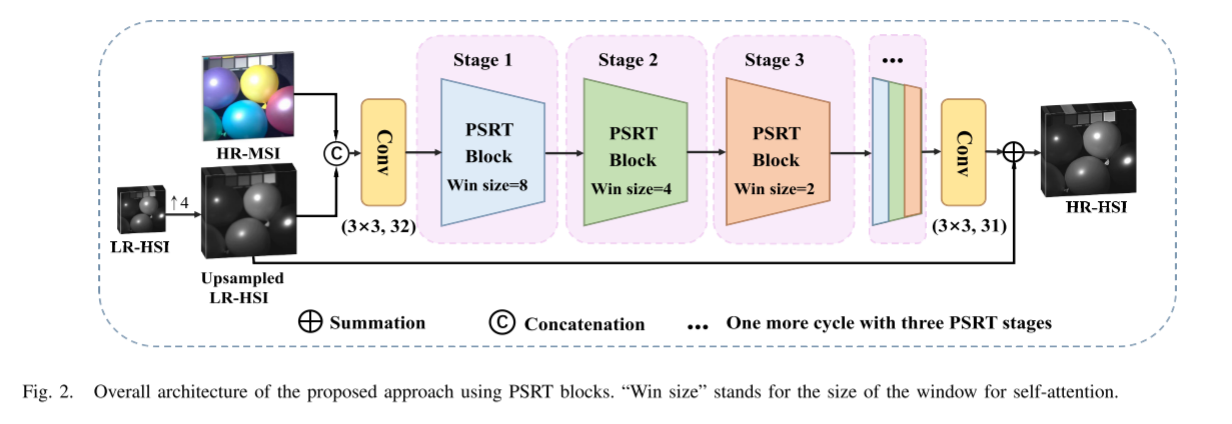
As shown in Figure 2, PSRT follows a commonly used layered architecture, which cascades the upsampled versions of HR-MSI and LR-HSI, and the entire architecture learns the relationship between the upsampled version of LR-HSI and the ground truth (GT) Residuals. The first convolutional layer extracts shallow features and increases the number of channels . Then, we extract depth information using PSRT blocks, where each PSRT block has a reduced window size of self-attention to extract information at different scales . Finally, the convolutional layer is used as a decoder to combine the information. The results are obtained by adding an upsampled version of LR-HSI to the output.
Window Self-Attention
The characteristic of Transformer is that it establishes long-distance dependencies between tokens and can effectively describe global correlations. For an image, we usually take a 4 × 4 patch as a token and then feed it into the attention mechanism for calculation. While this alleviates the computational problem to some extent, it does not solve the problem that makes this approach expensive due to using the original size as input. To solve this problem, we divide the input image into smaller non-overlapping windows in the spatial dimension (i.e., Swin Transformer); then, we implement self-attention to tokens in each window for efficient computation. Window self-attention can be expressed as follows: 
the followed result of the query from the i-th key to the j-th key is marked as δ i-j , V j is the value of the j-th token, and δ i-j is obtained via the dot product, along the row The softmax function and scaling factor are obtained by calculating the cosine between Qi and Kj . In this way, the complexity of self-attention is reduced, and it allows the model to gain the ability to handle large-sized feature maps and express original tokens in a local manner.
SaR Strategy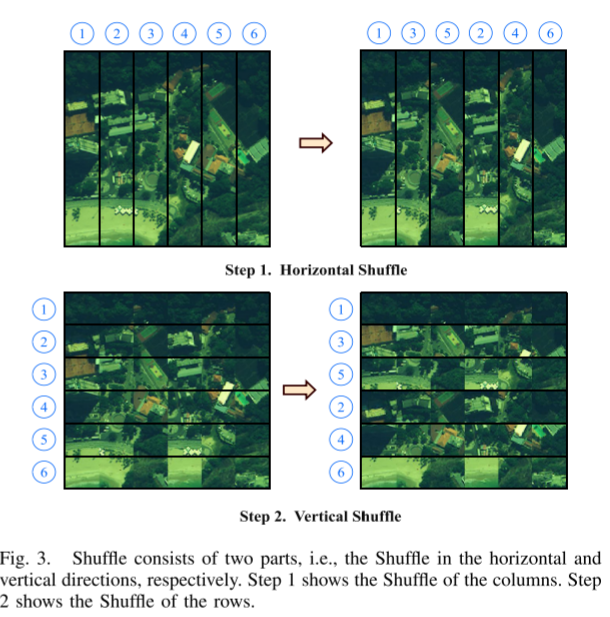
1) Shuffle Operation: This section introduces the Shuffle operation, which consists of two parts, namely, horizontal random Shuffle and vertical random Shuffle. The details of the two shuffling operations are depicted in the flowchart in Figure 3. More specifically, horizontal shuffling in the spatial domain can be described by the following equation: 
For simplicity, we label the plane as V ∈ RH×W, and the tokens in the plane as V~ij~ ∈ RH ∗ WR ^{H*W}RH ∗ W , i ∈ {1, 2,…,H}, j ∈ {1, 2,…,W}. In the above formula, d is the length of Shuffle, and its value is (win_size/2), and in the above equation, Spliceh is used to merge group Gk horizontally. Then, we divide V into (W/d) groups, denoted as Gk, k ∈ {1, 2,…, (W/d)}. This operation is shown in Figure 3 (upper left corner). Then, we perform a Shuffle operation on plane V, and the result of this operation is shown in Figure 3 (top right corner). After obtaining the horizontal shuffling result Vs, we utilize a similar strategy to Vs along the vertical direction to produce the final shuffling result; see the second row of Figure 3.
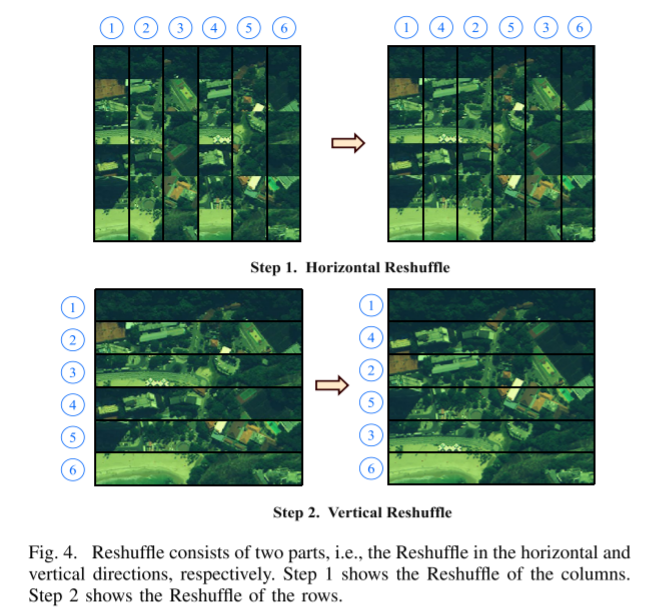
2) Reshuffle Operation:We perform window self-attention on the shuffled tokens and invert the obtained results through the Reshuffle operation, which still contains horizontal and vertical directions. The specific operation is shown in Figure 4, and the equation characterizing the operator along the horizontal direction is as follows: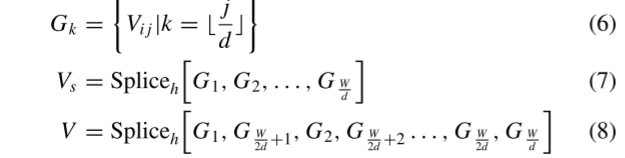
where Vs represents the plane that has been shuffled. According to Figure 4, we first divide Vs into (W/d) groups, denoted as Gk, k ∈ {1, 2,…, (W/d)}, and rearrange the columns of Vs through (8) to obtain V and then apply a rearrangement operation in the vertical direction. The operation of Reshuffle is the reverse operation of Shuffle. By adding window self-attention between Shuffle and Resuffle, the receptive field originally limited by the window can be expanded.
PSRT Block
In this section, we will detail the PSRT module added as a module to the main network architecture. The pyramid structure used in this work is different from the stage-to-stage structure such as PVT and Swin Transformer. Our PSRT block has the window pyramid structure shown in Figure 5(a). It is easy to see that the size of the window is reduced in stages to create multi-scale windows. In PSRT blocks, the size of the windows is fixed at each stage, and each window is independent of other windows. The output of the previous stage is used as the input of the next stage. At the same time, the size of the window is reduced to half of the previous stage. Specifically, the PSRT block consists of three stages to extract different information through multi-scale windows in a hierarchical manner to restore local details. Specifically, in the first stage, the size of the input features is H × W × C, and the size of the window is W 1 × W 1 (W 1 is equal to 8). When the feature reaches the last level, the size of the window decays to (W 1 /4) × (W 1 /4), but the shape of the feature remains unchanged. Multi-scale design is important to MHIF, and window attention is the biggest advantage of Swin Transformer. Therefore, we designed a unique model. We develop multi-scale window attention (i.e., the proposed PSRT block) inspired by the classic pyramid structure to provide larger receptive fields and rich features, resulting in better information interaction.
One Stage in PSRT Block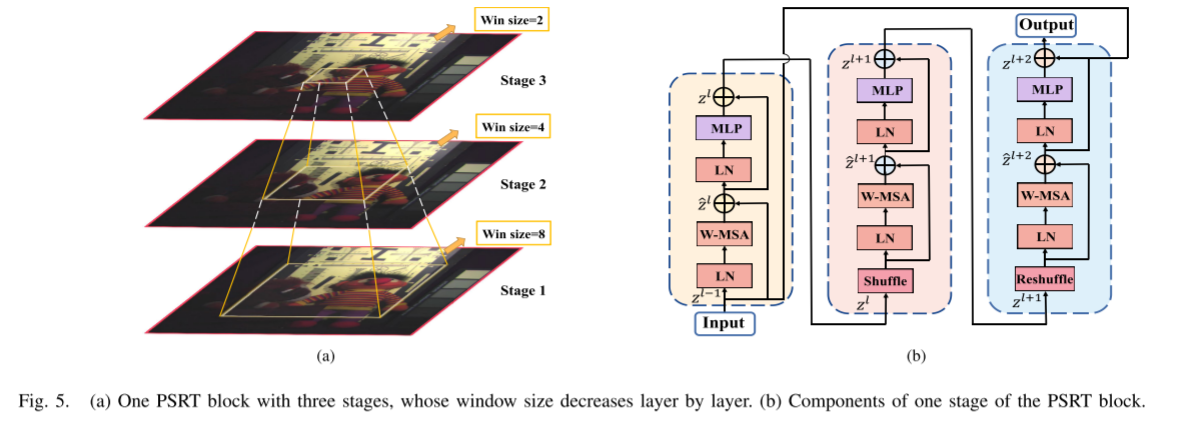
The use of self-attention in non-overlapping windows is considered as the fusion of local information. To do this, we designed a hamburger-like structure for each stage of the PSRT block. One stage in the PSRT block contains three windowed self-attention layers, which is shown in Figure 5(b). Each stage mainly consists of a window multi-head self-attention (W-MSA) module, a multi-layer perceptron (MLP), and two LayerNorm (LN) layers. The S in the second block stands for Shuffle, and the R in the third block means that Reshuffle is considered before the W-MSA module. Furthermore, nonlinearities (i.e., Gaussian Error Linear Units (GELU)) and residual connections are exploited in each stage. More specifically, we have the following: 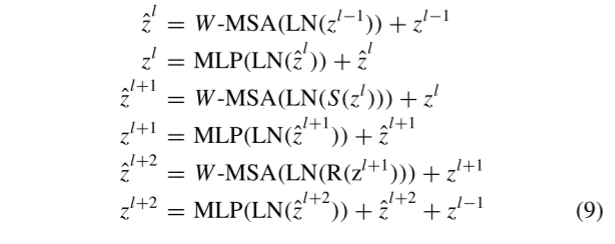
where W-MSA is window-based self-attention; zl − 1 z^{l-1}zl − 1 is the output of the previous stage;zlz^{l}zl、 z l + 1 z^{l+1} zl+1和 z l + 2 z^{l+2} zl + 2 represents the result of each stage. We take the "Window Self-Attention + Shuffle + Window Self-Attention + Resuffle + Window Self-Attention" baseline as a stage of the PSRT block. First, self-attention is performed on the shuffled windows to build global dependencies between different windows. Then perform self-attention on the rearranged windows and construct local dependencies in a window. Through the above two SaR strategies, information dissemination between different windows is achieved.
The entire network architecture is shown in Figure 2.
Loss Function
- L1 Loss: We calculate the L1 distance between the network output I MHIF and GT I HR on a pixel-by-pixel basis
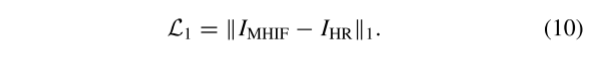
- SSIM Loss: Structural similarity (SSIM) can compare the structural differences between I MHIF and I HR , including brightness contrast function and structural contrast function. The SSIM function is defined as follows:

Overall loss function: We optimize the parameters of the network in a unified and end-to-end manner. The total loss function consists of the weighted sum of the two losses