Table of contents
1. Overview of MySQL Replication
3. Replication supported by MySQL
4. Deploy master-slave MySQL semi-asynchronous replication
Test whether replication is successful
5. Read and write separation based on master-slave semi-asynchronous replication
Reading and writing separation based on Amoeba
Common MySQL read and write separation
Implemented based on intermediate proxy layer
Configure Amoeba read and write separation, two Slave read load balancing
Perform access testing on the Client
Test load balancing on the client
Test read and write separation
1. Overview of MySQL Replication
MySQL Replication, commonly known as MySQL AB replication, master-slave replication, and master-slave synchronization, is the data synchronization technology officially recommended by MySQL. The basic process of data synchronization is that the slave database will read the binary log file of the master database in real time, and perform the same operation on the slave database according to the records in the log to achieve the data synchronization effect.
advantage
Improve the reliability of the database platform by adding slave servers. Writes and updates are performed on the master server, and read functions are provided on the slave server. The number of slave servers can be dynamically adjusted to adjust the high performance of the database platform.
Improve data security, because the data has been copied to the slave server, and when the master database is abnormal, the replication process from the slave server can be terminated to protect data integrity.
Real-time data is generated on the master server and analyzed on the slave server, thereby alleviating the performance pressure on the master server.
2. MySQL replication type
Asynchronous replication
MySQL replicates asynchronously by default. The main database will return the results to the client immediately after executing the transaction submitted by the client. It does not care whether the slave database has accepted and processed the transaction. This will cause a problem. If it goes down, the transactions that have been submitted on the master may not be transmitted to the slave server. If the slave is forced to be promoted to the master at this time, the data on the new master may be incomplete. By default, the replication function of MySQL5.5/5.6/5.7 and mariaDB10.0/10.1 is asynchronous.
Fully synchronous replication
It means that when the main database has completed executing a transaction, all slave databases have executed the transaction before returning it to the client. Because you need to wait for all slave libraries to complete the transaction before returning, the performance of fully synchronous replication will inevitably be seriously affected, and the response speed of returning to the client will also be slowed down.
Semisynchronous replication
MySQL has only begun to support semi-synchronous replication mode with a patch contributed by Google, which is between asynchronous replication and fully synchronous replication. After the main database executes the transaction submitted by the client, it does not return to the client immediately, but waits for at least one slave database. It is received and written to the relay log before being returned to the client. Compared with asynchronous replication, semi-synchronous replication improves data security, but it also causes a certain degree of delay. This delay is at least one TCP/IP round trip time. Therefore, semi-synchronous replication is best used in low-latency networks. When a timeout occurs, the source master server temporarily switches to asynchronous replication mode until at least one slave server set to semi-synchronous replication mode receives information in time.
The semi-synchronous replication mode is enabled on both the master server and the slave server. Otherwise, the master server uses asynchronous replication mode by default.
3. Replication supported by MySQL
SQL statement-based replication executes the SQL statement on the master server and executes the same SQL statement on the slave server, which is more efficient.
Row-based replication The master server writes table row changes as events to the binary log, and the master server replicates the events representing the rows to the slave server.
Mixed mode replication uses statement-based replication first, and then uses rows once it is found that statement-based replication cannot be exact.
4. Deploy master-slave MySQL semi-asynchronous replication
All machine operations
yum -y install mariadb mariadb-devel mariadb-server
Main MySQL operations
vim /etc/my.cnf
server-id=1
log-bin=mysql-binlog
log-slave-updates=true
Restart
Create user
Back up and transfer to slave server



Operation from server
systemctl start mariadb
mysql -uroot -p < /root/alldbbackup.sql
mysql -u myslave -p123456 -h 192.168.100.1
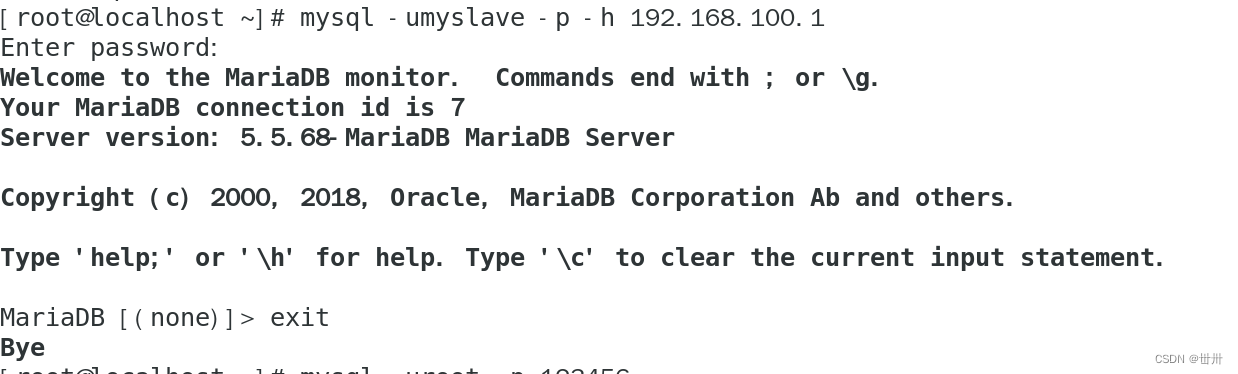
Modify MySQL configuration file
vim /etc/my.cnf
server-id=2
relay-log=relay-log-bin
Restart and authorize the slave server, start the slave database, and synchronize the master-slave database data.


Test whether replication is successful
main view

view from

Master creates libraries and tables

view from

5. Read and write separation based on master-slave semi-asynchronous replication
Reading and writing separation based on Amoeba
In an actual production environment, if the reading and writing of the database are all operated on the same database server, no matter whether it is security, high availability or concurrency, the actual needs cannot be fully met. Therefore, generally speaking, it is done through The master-slave replication method is used to synchronize data, and then read-write separation is used to provide high concurrent load capacity of data for deployment.
Common MySQL read and write separation
Implemented internally based on program code
In the code, routing is classified based on select and insert. This method is currently the most widely used in large-scale production environments. The advantage is that it has the best performance. Because it is implemented in the program code, there is no need to add additional equipment as hardware expenses. The disadvantage is that it requires Developers have to implement it, and operation and maintenance personnel have no way to start.
Implemented based on intermediate proxy layer
The proxy is generally located between the client and the database server. After receiving the client's request, the proxy server forwards it to the back-end database through judgment. Representative procedures:
(1) mysql-proxy develops early open source projects for mysql, and performs SQL judgment through its own lua script. Although it is an official product of mysql, mysql officials do not recommend its application to the production environment.
(2) Amoeba (Amoeba) This program is developed by Java language and retrograde. Alibaba applies it to the production environment. It does not support transactions and stored procedures.
Implemented based on intermediate proxy layer
MySQL Master IP:192.168.100.1
MySQL Slave1 IP:192.168.100.2
MySQL Slave2 IP:192.168.100.3
MySQL Amoeba IP:192.168.100.4
MySQL Client IP:192.168.100.5
Configure Amoeba read and write separation, two Slave read load balancing
Configure Amoeba's access authorization in the Master, Slave1, and Slave2 servers

Edit amoeba.xml configuration file
vim /usr/local/amoeba/conf/amoeba.xml


Edit the dbServer.xml configuration file
vim /usr/local/amoeba/conf/dbServers.xml
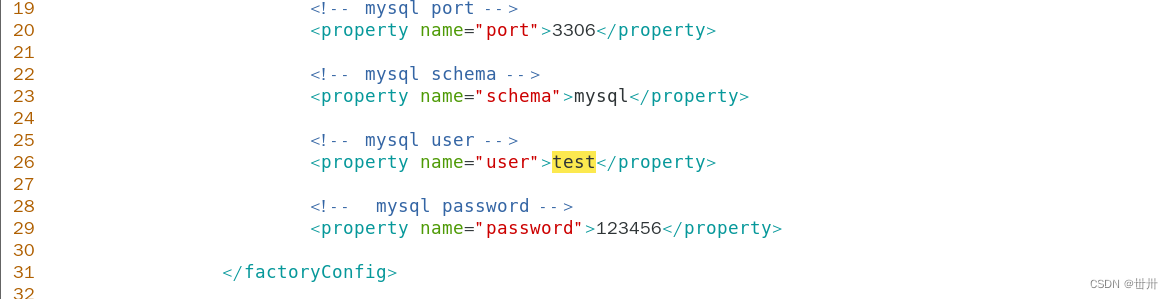
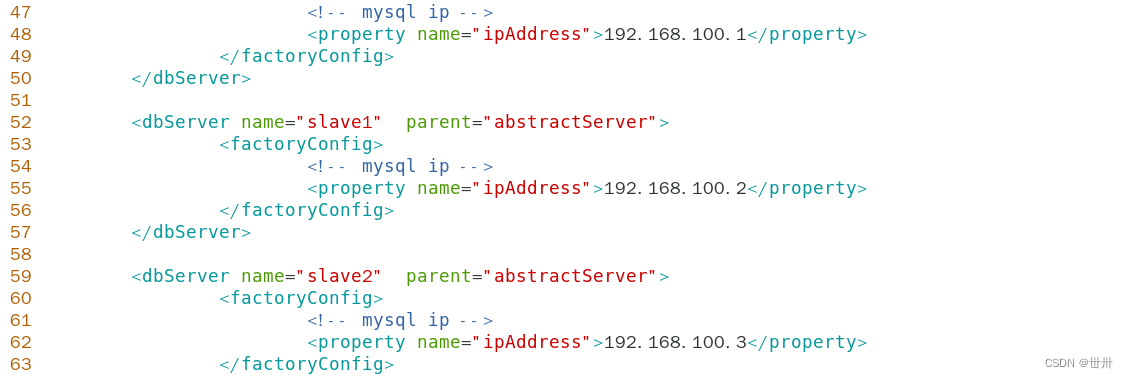

After the configuration is correct, start the Amoeba software. The default port is TCP protocol 8066.
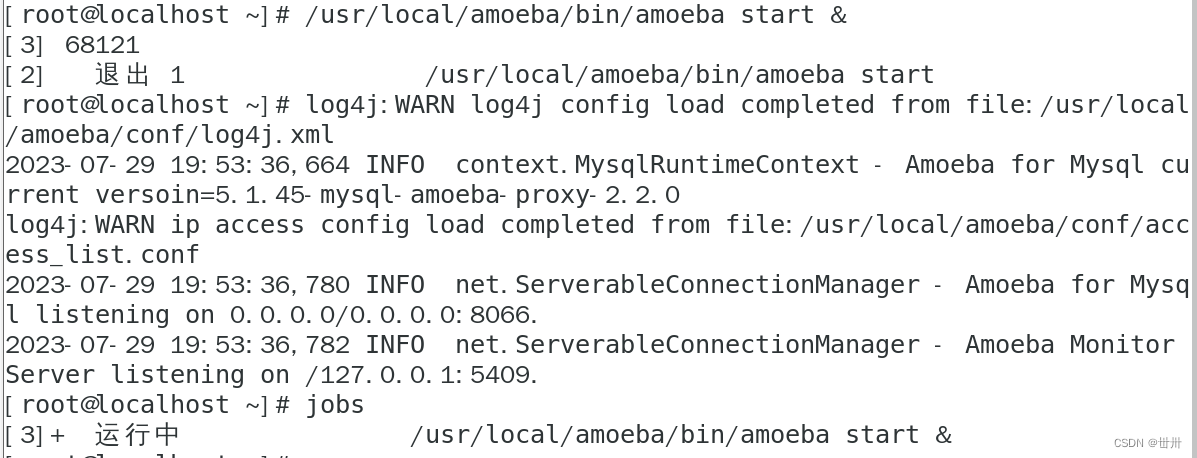


Perform access testing on the Client

Test load balancing on the client
Master server 1 creates database and table input data

Input data from server 1

Input data from server 2

client test
Viewing the data twice, the data content is different, indicating load balancing.

Test read and write separation
Stop replication from server

client input data and view
Because the slave server stops replicating, the client cannot get the newly inserted data from the slave server.

Main server view
ID 2 and 3 are mixed with data on the slave server, so the master server has no data.

Start replication from server

client view
Indicates that reading and writing have been separated
Master server writes
Read from server
