Table of contents
This article deeply explores the core principles, practical applications, advantages and disadvantages of the KMeans clustering algorithm, and its special use in text clustering, providing you with valuable insights and guidance in cluster analysis and natural language processing.
Follow TechLead and share all-dimensional knowledge of AI. The author has 10+ years of Internet service architecture, AI product research and development experience, and team management experience. He holds a master's degree from Tongji University in Fudan University, a member of Fudan Robot Intelligence Laboratory, a senior architect certified by Alibaba Cloud, a project management professional, and research and development of AI products with revenue of hundreds of millions. principal.
1. Introduction to clustering and KMeans
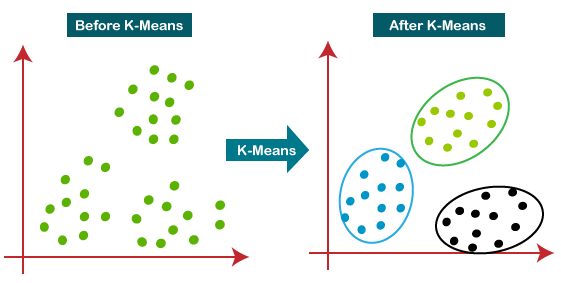
Clustering algorithms play an important role in machine learning and data mining, where they are used to automatically group data into meaningful clusters. KMeans clustering algorithm is the simplest and most commonly used one. In this article, we will delve into the principles, advantages, disadvantages, variants, and practical applications of the KMeans clustering algorithm. First, let us understand the basic concepts of clustering and KMeans algorithm.
Basic concepts of clustering
Definition : Clustering is an unsupervised learning method used to group data points into several clusters so that data points have high similarity within the same cluster and low similarity between different clusters.
Example : Consider an e-commerce website with tens of thousands of users and thousands of products. Through clustering algorithms, we can divide users into several different clusters (for example, housewives, students, professionals, etc.) for more accurate recommendations and marketing.
The importance of KMeans algorithm
Definition : KMeans is a partitioning method that achieves the purpose of partitioning a data set by iteratively assigning each data point to the nearest predetermined number (K) of center points (also called "centroids") and updating these center points. .
Example : In social network analysis, we might want to understand which users interact frequently and form a community. Through the KMeans algorithm, we can find the "central users" of these communities and form different user clusters around them.
These two basic concepts provide a solid foundation for our subsequent in-depth analysis and code implementation. By understanding the purpose of clustering and the working principle of the KMeans algorithm, we can better grasp the application of this algorithm in complex data analysis tasks.
2. Principle of KMeans algorithm
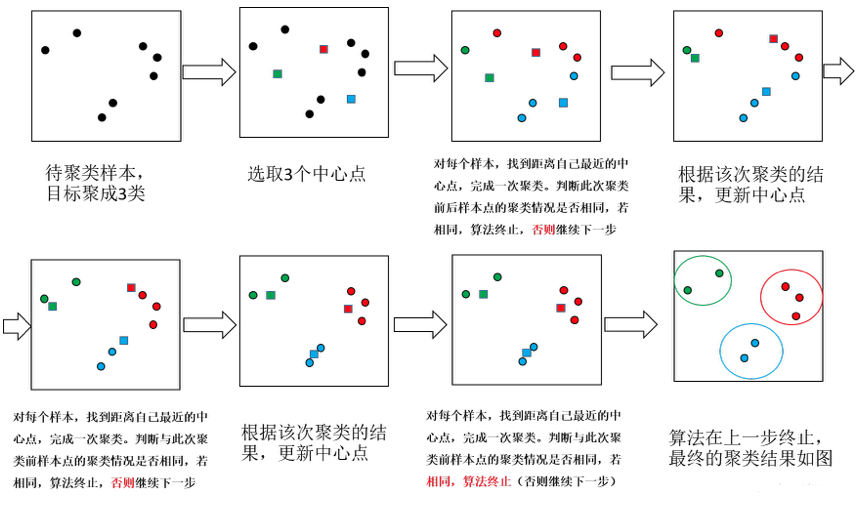
Before diving into the KMeans clustering algorithm, it is crucial to understand how it works. This section will introduce the core components of the KMeans algorithm, including data sets and feature spaces, distance measures, and the main steps of the algorithm.
Datasets and feature spaces
Definition : In the KMeans algorithm, the data set is usually represented as a matrix, where each row is a data point and each column is a feature. The feature space is the multidimensional space in which these data points exist, usually the same number of columns as the data set.
Example : Suppose we have a simple 2D dataset that includes two features: height and weight. In this case, the feature space is a two-dimensional plane where each point represents an individual with height and weight values.
distance measure
Definition : A distance metric is a way to measure the similarity between data points. In KMeans, the most commonly used distance metric is Euclidean distance.
Example : In the height and weight example above, we can use Euclidean distance to measure the similarity of two people in the feature space. Mathematically, this can be expressed by the following formula:

Algorithm steps
The KMeans algorithm mainly consists of the following steps:
- Select K initial center points : Randomly select K data points in the data set as the initial center points (center of mass).
- Assign data points to the nearest center point : For each point in the data set, calculate its distance to all center points and assign it to the nearest center point.
- Update center point : Recalculate the center point of each cluster, usually the average of all points within that cluster.
- Iterate until convergence : Repeat steps 2 and 3 until the center point no longer changes significantly or the preset number of iterations is reached.
Example : Consider a store that wants to segment customers into several different clusters for more effective marketing. Stores have data on customer age and purchase frequency. In this example, the KMeans algorithm can be applied like this:
- Select K (for example, K=3) customers as the initial center points.
- Calculate the distance of all other customers from these K center points using age and purchase frequency, and assign each customer to the nearest center point.
- Update the center point of each cluster, which is the average age and purchase frequency of all customers within each cluster.
- This process is iterated until the cluster no longer changes or a preset number of iterations is reached.
Through this structured analysis, we can better understand how the KMeans clustering algorithm works and how to adjust the algorithm parameters in different application scenarios.
3. KMeans case practice
It is very important to understand the theoretical basis of the KMeans algorithm, but more important is to be able to apply these theories to practical problems. In this section, we will use a specific case to demonstrate how to use Python and PyTorch to implement the KMeans algorithm.
Case Background: Customer Segmentation
Definition : Customer segmentation is a market strategy that allows companies to promote products or provide services more accurately by dividing potential customers into different groups or segments.
Example : An online retailer wants to segment customers based on their age, purchase history, and browsing behavior to implement more effective marketing strategies.
Dataset description
In this case, we will use a simple data set, including three characteristics of customers' age, purchase frequency and average consumption amount.
客户ID | 年龄 | 购买频率 | 平均消费金额
------|------|----------|--------------
1 | 25 | 5 | 50
2 | 30 | 3 | 40
3 | 35 | 1 | 20
...
Python implementation code
Below is the code to implement the KMeans algorithm using Python and PyTorch. We first import the necessary libraries, then proceed with data preparation, model training, and result visualization.
import numpy as np
import torch
import matplotlib.pyplot as plt
# 创建一个模拟数据集
data = torch.tensor([[25, 5, 50],
[30, 3, 40],
[35, 1, 20]], dtype=torch.float32)
# 初始化K个中心点
K = 2
centers = data[torch.randperm(data.shape[0])][:K]
# KMeans算法主体
for i in range(10): # 迭代10次
# 步骤2:计算每个点到各个中心点的距离,并分配到最近的中心点
distances = torch.cdist(data, centers)
labels = torch.argmin(distances, dim=1)
# 步骤3:重新计算中心点
for k in range(K):
centers[k] = data[labels == k].mean(dim=0)
# 结果可视化
plt.scatter(data[:, 0], data[:, 1], c=labels)
plt.scatter(centers[:, 0], centers[:, 1], marker='x')
plt.show()
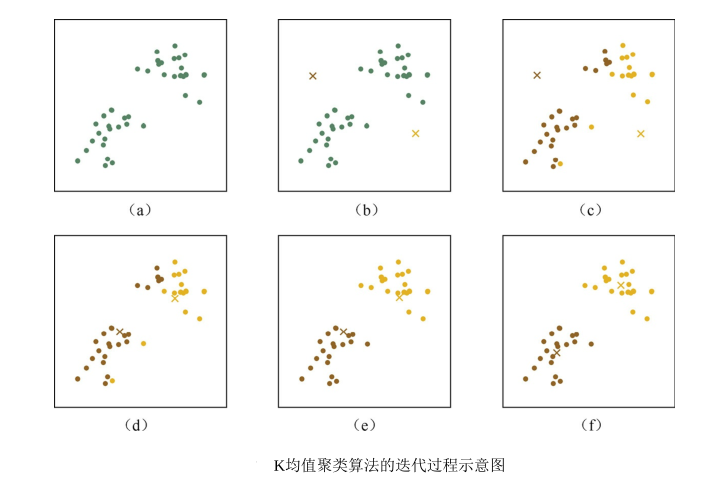
Output and interpretation
In this simple example, the KMeans algorithm divides customers into two clusters. By visualizing the results, we can see that the cluster center points (marked 'x') are located in different age and purchase frequency areas.
Such output can help companies better understand their customer groups and thus formulate more precise market strategies.
4. Advantages and Disadvantages of KMeans
Understanding the strengths and weaknesses of an algorithm is the key to mastering it. In this part, we will discuss the advantages and disadvantages of the KMeans algorithm in practical applications in detail, and use specific examples to deepen the understanding of these concepts.
advantage
High computational efficiency
Definition : The KMeans algorithm has high computational efficiency and can maintain good performance especially when the data set is large or has many features.
Example : Suppose a large online retailer has millions of customer data, including multi-dimensional characteristics such as age, purchase history, geographical location, etc. With KMeans, clustering can be completed in just a few minutes or hours, while more complex algorithms may take longer.
The algorithm is simple and easy to implement
Definition : The KMeans algorithm itself is relatively simple and easy to code and implement.
Example : As we showed in the previous case practice section, the KMeans algorithm can be implemented with only a few dozen lines of Python code, which is very friendly to both beginners and researchers.
shortcoming
Need to preset K value
Definition : The KMeans algorithm requires the number of clusters (K value) to be preset, but in actual applications this number is often unknown.
Example : A restaurant may want to cluster customers based on their dish selection, consumption amount, and dining time, but it is difficult to determine in advance how many clusters it should be divided into. Wrong choice of K value may lead to inaccurate or meaningless clustering results.
sensitive to initial point
Definition : The output of the algorithm may be affected by the choice of the initial center point, which may lead to a local optimum rather than a globally optimal solution.
Example : When processing geographic information, if the initial center point is accidentally chosen in an inaccessible area, it may result in a very large but unrepresentative cluster.
Poor ability to handle clusters of non-convex shapes
Definition : KMeans is more suitable for clusters of convex shapes (such as circles, spheres), and has poor processing capabilities for clusters of non-convex shapes (such as rings).
Example : Suppose a gym wants to cluster members based on their age and exercise time, but finds that both young and old people have the habit of exercising in the morning and evening, forming a ring-shaped distribution. In this case, KMeans may not cluster accurately.
5. Application of KMeans in text clustering

In addition to common numerical data clustering, KMeans is also widely used in text data clustering. In this section, we will explore the application of KMeans in text clustering, especially in the field of natural language processing (NLP).
Text vectorization
Definition : Text vectorization is the conversion of text data into numerical form so that machine learning algorithms can process it more easily.
Example : For example, a commonly used text vectorization method is TF-IDF (Term Frequency-Inverse Document Frequency).
KMeans and TF-IDF
Definition : Combining the TF-IDF and KMeans algorithms can effectively classify documents or model topics.
Example : A news website may have thousands of articles, which can be classified into several major topics, such as "Politics", "Technology", "Sports", etc. by applying the KMeans clustering algorithm and TF-IDF.
Python implementation code
The code below uses Python's sklearnlibrary for TF-IDF text vectorization and applies KMeans for text clustering.
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cluster import KMeans
# 模拟文本数据
documents = ["政治新闻1", "科技新闻1", "体育新闻1",
"政治新闻2", "科技新闻2", "体育新闻2"]
# TF-IDF向量化
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(documents)
# KMeans聚类
model = KMeans(n_clusters=3)
model.fit(X)
labels = model.labels_
# 输出与解释
for i, label in enumerate(labels):
print(f"文档 {
documents[i]} 被归类到 {
label} 集群。")
Output and interpretation
This simple example shows how to classify text documents into 3 different clusters using KMeans and TF-IDF. The corresponding output may be as follows:
文档 政治新闻1 被归类到 0 集群。
文档 科技新闻1 被归类到 1 集群。
文档 体育新闻1 被归类到 2 集群。
文档 政治新闻2 被归类到 0 集群。
文档 科技新闻2 被归类到 1 集群。
文档 体育新闻2 被归类到 2 集群。
In this way, we can classify large amounts of text data to facilitate subsequent data analysis or information retrieval.
Summarize
The KMeans clustering algorithm is a simple yet powerful unsupervised learning tool suitable for various data types and application scenarios. In this article, we deeply explore the basic principles, practical applications, advantages and disadvantages of KMeans, and its special use in text clustering.
From the perspective of computational efficiency and ease of implementation, the KMeans algorithm is an attractive option. But it also has its limitations, such as dependence on the initial center point and problems that may arise when dealing with complex cluster shapes. These factors need to be carefully weighed in practical applications.
Text clustering shows that KMeans can also perform well on high-dimensional sparse data, especially when combined with text vectorization methods such as TF-IDF. This paves the way for application scenarios such as natural language processing, information retrieval, and even more complex semantic analysis.
However, it is worth noting that KMeans is not a panacea. In different application environments, more complex factors need to be taken into consideration, such as the unevenness of data distribution, the presence of noise, and the dynamics of clusters. These factors may require us to make appropriate improvements to KMeans or choose other clustering algorithms that are more suitable for specific problems.
In addition, in the future, with the advancement of algorithms and hardware, and the introduction of more advanced optimization techniques, KMeans and other clustering algorithms will further evolve. For example, automatically determining the optimal K value, or using more advanced initialization strategies to reduce dependence on initial point selection, are all directions worthy of further exploration.
To sum up, KMeans is a very practical algorithm, but to fully realize its potential, we need to deeply understand its working principle, adaptability and limitations, and make wise choices and adjustments in practical applications. I hope this article can provide you with valuable guidance and inspiration when using KMeans or other clustering algorithms.
Follow TechLead and share all-dimensional knowledge of AI. The author has 10+ years of Internet service architecture, AI product research and development experience, and team management experience. He holds a master's degree from Tongji University in Fudan University, a member of Fudan Robot Intelligence Laboratory, a senior architect certified by Alibaba Cloud, a project management professional, and research and development of AI products with revenue of hundreds of millions. principal.