Preface
Contract fulfillment management is an OMS workbench for logistics merchants. Since the first generation set up the shelf, there has been no further investment. Later, partner students have been responsible for daily maintenance and demand support. After several years of brutal growth, the system has become overgrown and full of chaos. Later, it even became an unclaimed land and was supported by industry co-construction. For a system that does not support industry isolation, industry co-construction means that the system will quickly decay. Two years ago I took over the management of contract fulfillment and came to this vast wilderness. Like all those who long for the joy of creation and happen to have a hammer and sickle in their hands, I was like a wild horse running wild, and I often had thoughts in my mind. There are many bold and novel ideas, hoping to build a perfect system for contract fulfillment management. It's a pity that very few can actually be put into practice. This article is one of the few ideas that has been implemented and has considerable practical value. It has been compiled and shared with students in need for reference.
Log chaos
Logging is the module most likely to be ignored and abused in daily development. It is ignored because logging is really a simple thing. The predecessors have designed a logback. Whether it can be printed, I don’t know which file it will be printed in. Anyway, try running it once, and if it doesn’t work, change the error. It is abused because the format and content of logs in different scenarios are so different, or the logging method is too flexible, too casual, and the style is too diverse, so that almost everyone has to write their own LogUtil if they disagree. This is the most exaggerated thing I have ever seen. Yes, there are as many as twenty or thirty tool types used for logging in a system. It may take half an hour for future generations to struggle with which tool to use, which perfectly explains what the broken window effect is. The best way to learn is to learn from negative teaching materials. Below we list some of the most common problems in the log design and development process.
Classification Chaos
Generally speaking, a system must design multiple log files to distinguish different businesses or scenarios. It is impossible for all logs to be recorded in one file. But no one told us how to classify, so there are various classifications. According to system modules. This classification should be the most basic classification and the most hierarchical classification. For example, the system layering of the fulfillment service center. Basically each layer corresponds to a log file.
According to tenant status. Generally, middle-end systems support multiple tenants (industries), and each tenant corresponds to a separate log file. This classification is generally not used alone unless you want to completely isolate tenants. Stream of consciousness taxonomy. It does not comply with the MECE rules and there is no clear and unified classification logic. It is divided by business, system module, interface capability, and new and old links. The shadows of various classification methods can be seen, and the result is dozens of classifications. file, the person who writes the log has no idea which file this line of log will be entered into. None of the above-mentioned classification methods is absolutely pure, because no matter which one, no matter how clear the boundaries are designed at the beginning, as time goes by, it will eventually evolve into a hodgepodge.
- Someone wants to monitor the logs generated by a certain class individually and add a new log file;
- If you add a new business, such as a pallet of goods, and want to monitor it separately, add a new log file;
- Launched a service-based campaign, separately monitored the service-based links, and added new log files;
- If a certain business wants to collect user behavior but does not want to receive all log messages, add a new log file;
- The scenario of asset loss exposure requires special attention and a new log file is added;
- Logs generated during special periods, such as major sales, new log files;
All these are not enough. I found no. There is always a moment when people have the nerve impulse to add new log files. Their demands and scenarios are not unreasonable. Although the dimensions of these logs are completely irrelevant, nothing can stop this impulse. The original log design was like a dying elephant that was constantly being torn off by different interested parties.
Format chaos
I believe no one will have any objection to the fact that logs need to have a certain format. The chaos in the format is mainly reflected in two aspects. One is the design of the format. Some systems have designed very complex formats, using a variety of delimiter combinations. It supports the grouping of log content, uses keyword positioning to replace the fixed position format, and supports format expansion, which is a burden for the human brain and computers to parse. The second is the same log file, and content in different formats can appear. The stack and normal business logs are mixed. Let’s look at an example. I won’t give any hints. Can you quickly analyze the structure of this log in your brain?
requestParam$&trace@2150435916867358634668899ebccf&scene@test&logTime@2023-06-14 17:44:23&+skuPromiseInfo$&itemId@1234567:1&skuId@8888:1&buyerId@777:1&itemTags@,123:1,2049:1,249:1,&sellerId@6294:1&toCode@371621:1&toTownCode@371621003:1&skuBizCode@TMALL_TAOBAO:1&skuSubBizCode@TMALL_DEFAULT:1&fromCode@DZ_001:1+orderCommonInfo$&orderId@4a04c79734652f6bd7a8876379399777&orderBizCode@TMALL_TAOBAO&orderSubBizCode@TMALL_DEFAULT&toCode@371621&toTownCode@371621003&+chaos of tools
Sometimes it may even happen that in the same class and the same method, there are two different log lines, the format of the logs is different, and the log files are also different. Why does this happen? It's because different logging tools are used. To get to the root of this, we need to analyze what exactly different tools are doing. It can be found that the difference between many tools is that they support different parameter types. Some print order objects, some print messages, and some print scheduling logs. There are also some differences for different business scenarios, such as special tools for one-package goods and special tools for negative sales. There are also some differences for different exception encapsulation, some print ExceptionA, and some print ExceptionB. There is nothing more bizarre in the world than this, and perhaps it can only be explained by the fact that existence is reasonable.
Log tiering
I have always believed in the principle of minimalist design, simplicity means unbreakable. As mentioned above, the final outcome of a log system must be chaos. Since this trend is inevitable, we can only ensure one thing during the initial design, ensuring that the original classification is as simple as possible and does not overlap. In fact, there are only two general classification methods, one is split horizontally by function, and the other is split vertically by business. Generally speaking, horizontal splitting should be used for first-level classification. Because the boundaries of business are generally difficult to draw clearly and the boundaries are relatively fuzzy, the boundaries of functions are relatively clear and stable. Functions actually reflect workflow. Once the workflow is formed, there will basically not be much structural changes. Based on this idea, I designed the following log layering.
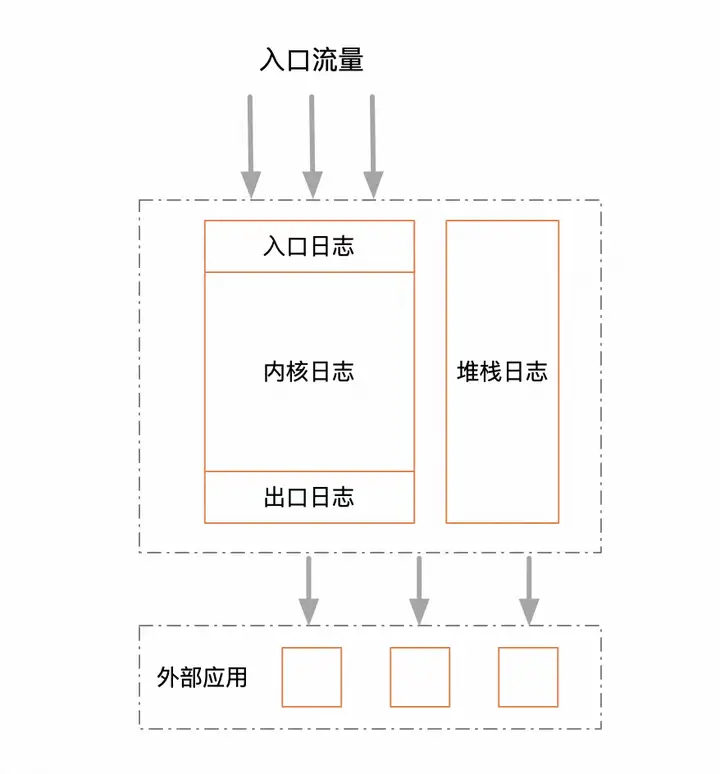
From a hierarchical perspective, there are actually only three layers, entrance, core, and exit. The entrance log is only responsible for printing the incoming and outgoing parameters of the traffic entrance, such as HSF and controller. The exit log is responsible for printing the incoming and outgoing parameters of all third-party service calls. The kernel log is responsible for printing all business logs during intermediate execution. Just three layers are enough, simple enough, not heavy or leaky. In addition, separate stack logs. Stacks are very special compared to business logs. The log storage reduction optimization mentioned in the title of this article is only an optimization for stack logs, which will be discussed later.
format design
There are also some considerations in the format design of logs. First of all, the design of the log is human-readable, which goes without saying. Another very important point is to design for monitorability. This is a point that is easily overlooked by many people. Based on these two principles, let me talk about some of my ideas on format design. First we need to do dimensional abstraction. Since it is for monitoring, monitoring generally needs to support multiple maintenance, such as industry dimension, service dimension, merchant dimension, etc., then we need to extract all dimension factors. So how are these dimensions passed to the logger when they are actually printed? The suggestion is to store them in ThreadLocal and retrieve them from the context when typing. Another advantage of doing this is that the log printing tool will be very elegant in design and only needs to pass few parameters. The format should be as simple as possible, using the principle of convention over configuration. Each dimension occupies a fixed position and is separated by commas. Do not design a large and comprehensive model and then directly serialize the entire model into a JSON string. Don't be tempted by the so-called extensibility, which allows users to easily customize the format, even if you can easily provide this capability. In my experience, this extensibility is bound to be abused, and in the end even the designer has no idea what the actual format is. Of course, this requires the designer to have a high vision and foresight, but this is not the difficulty. The difficulty is to restrain the desire to show off one's skills. In terms of content, try to print text that can be self-explanatory so that it can be understood by name. For example, we want to print a refund label. The refund label is originally stored in binary bits such as 1, 2, 4, and 8. When printing, do not print the stored value directly, but translate it into an English code that can describe its meaning. . Format example
timeStamp|threadName logLevel loggerName|sourceAppName,flowId,traceId,sceneCode,identityCode,loginUserId,scpCode,rpcId,isYace,ip||businessCode,isSuccess||parameters||returnResult||Content example
2023-08-14 14:37:12.919|http-nio-7001-exec-10 INFO c.a.u.m.s.a.LogAspect|default,c04e4b7ccc2a421995308b3b33503dda,0bb6d59616183822328322237e84cc,queryOrderStatus,XIAODIAN,5000000000014,123456,0.1.1.8,null,255.255.255.255||queryOrderStatus,success||{"@type":"com.alibaba.common.model.queryorder.req.QueryOrderListReq","currentUserDTO":{"bizGroup":888,"shopIdList":[123456],"supplierIdList":[1234,100000000001,100000000002,100000000004]},"extendFields":{"@type":"java.util.HashMap"},"invokeInfoDTO":{"appName":"uop-portal","operatorId":"1110","operatorName":"account_ANXRKY8NfqFjXvQ"},"orderQueryDTO":{"extendFields":{"@type":"java.util.HashMap"},"logisTypeList":[0,1],"pageSize":20,"pageStart":1},"routeRuleParam":{"@type":"java.util.HashMap","bizGroup":199000},"rule":{"$ref":"$.routeRuleParam"}}||{"@type":"com.alibaba.common.model.ResultDTO","idempotent":false,"needRetry":false,"result":{"@type":"com.alibaba.common.model.queryorderstatus.QueryOrderStatusResp","extendFields":{"@type":"java.util.HashMap"}},"success":true}||Stack beatdown
Here comes the focus of this article. This design is the wonderful idea mentioned at the beginning. The stack inversion originated from several pain points I felt during the process of troubleshooting another system problem. Let's first look at a stack example.

With such a long stack and such densely packed letters, even developers who deal with it every day, I believe it will make their scalp numb at first glance. Think back to what information we really want to get when we look at the stack. So there are two core pain points I feel. The first one is that the logs found on SLS (Alibaba Cloud Log Product System) are collapsed by default. Regarding the stack, we should all know that the characteristic of the traditional exception stack is that the top-most exception is the exception closest to the traffic entry. We generally don't care much about this kind of exception. The lowest-level exception is the source of a series of errors. When we troubleshoot problems on a daily basis, we are often most concerned about the source of errors. Therefore, for stack logs, we cannot tell at a glance which line of code the problem lies in through the summary. We must click on it, scroll to the bottom, and look at the last stack to determine the source. I wrote a bug example to illustrate the problem. The conventional stack structure is actually divided into two parts, which I call the exception cause stack and the error stack.
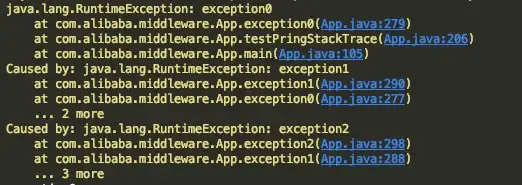
As above, a stack contains three groups of exceptions. Each RuntimeException is an exception. When these three exceptions are connected, we call it an exception cause stack . The stack inside each RuntimeException is called the error stack . To explain, I made up these two terms. I haven’t seen anyone distinguish between them. We generally call them stacks. As long as readers can understand what I want to express, don't worry too much about nouns. The second pain point is that the storage cost of this kind of stack is too high and the effective information carrying rate is very low. To be honest, most front-line developers may not have a strong sense of this, but in this environment of cost reduction and efficiency improvement, each of us should practice this as our own OKR, and change from passive to active, otherwise in the future Between machine costs and labor costs, the company has to make a multiple choice question. Now that the goal is clear, let's start prescribing the right medicine. There are two core ideas. To solve the problem of stack folding, stack inversion is used. After knocking it down, the lowest level anomaly was placed at the top. You don’t even need to click on it, you can tell the reason at a glance.

At the same time, we also support the configuration of the number of layers of the exception cause stack and the number of layers of the error stack. Solving this problem is essentially a simple algorithm problem: print the last N elements of the stack in reverse order. The core code is as follows.
/**
* 递归逆向打印堆栈及cause(即从最底层的异常开始往上打)
* @param t 原始异常
* @param causeDepth 需要递归打印的cause的最大深度
* @param counter 当前打印的cause的深度计数器(这里必须用引用类型,如果用基本数据类型,你对计数器的修改只能对当前栈帧可见,但是这个计数器,又必须在所有栈帧中可见,所以只能用引用类型)
* @param stackDepth 每一个异常栈的打印深度
* @param sb 字符串构造器
*/
public static void recursiveReversePrintStackCause(Throwable t, int causeDepth, ForwardCounter counter, int stackDepth, StringBuilder sb){
if(t == null){
return;
}
if (t.getCause() != null){
recursiveReversePrintStackCause(t.getCause(), causeDepth, counter, stackDepth, sb);
}
if(counter.i++ < causeDepth){
doPrintStack(t, stackDepth, sb);
}
}To reduce storage costs and ensure that information is not distorted, we consider starting with the stack line and simplifying the fully qualified class name to the full class name. Only the first letter of the package path is typed, and the line number is retained. For example: caumsLogAspect#log:88. The core code is as follows.
public static void doPrintStack(Throwable t, int stackDepth, StringBuilder sb){
StackTraceElement[] stackTraceElements = t.getStackTrace();
if(sb.lastIndexOf("\t") > -1){
sb.deleteCharAt(sb.length()-1);
sb.append("Caused: ");
}
sb.append(t.getClass().getName()).append(": ").append(t.getMessage()).append("\n\t");
for(int i=0; i < stackDepth; ++i){
if(i >= stackTraceElements.length){
break;
}
StackTraceElement element = stackTraceElements[i];
sb.append(reduceClassName(element.getClassName()))
.append("#")
.append(element.getMethodName())
.append(":")
.append(element.getLineNumber())
.append("\n\t");
}
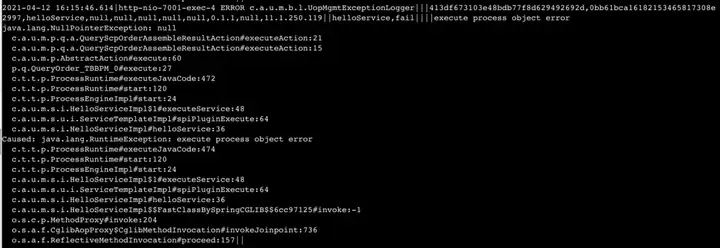
}The final effect will probably look like this. We randomly selected a stack for comparison and counted the number of characters. With the same amount of information, the compression ratio reached 88%.
Thinking expansion
Many articles like to advocate so-called best practices. In my opinion, best practices are a false proposition. When you talk about best practices, you need to specify who the "best" is compared to and what is your scope of application. I believe no one dares to say that their framework or solution is universal. Accurate. The log design practice proposed in this article was implemented in a typical middle-end application. Although the three-stage log layering scheme is simple enough and versatile enough, it has recently been used in some rich client applications. This scheme needs to be Relocation may require some localization transformation. Their characteristics are that they rely less on third-party services and use a large number of cache designs. The underlying logic of this design is to try to make all logic execute on the local client to reduce the risks and costs caused by distribution. This means that it is possible 99% of the logs are generated by internal execution logic, so we have to consider splitting them from other dimensions. In addition, regarding log cost reduction, this article only discusses stack storage reduction. It is impossible for all logs in a system to be stacks, so the actual overall log storage cost may not be reduced by that much. After talking so much, in the final analysis, there is still one sentence: don’t be superstitious about things like silver bullets and weight-loss pills. All technologies and ideas must be tailored to suit your needs and your ability.
Author|Fu Nan
Click to try the cloud product for free now to start your practical journey on the cloud!
This article is original content from Alibaba Cloud and may not be reproduced without permission.
Fined 200 yuan and more than 1 million yuan confiscated You Yuxi: The importance of high-quality Chinese documents Musk's hard-core migration server Solon for JDK 21, virtual threads are incredible! ! ! TCP congestion control saves the Internet Flutter for OpenHarmony is here The Linux kernel LTS period will be restored from 6 years to 2 years Go 1.22 will fix the for loop variable error Svelte built a "new wheel" - runes Google celebrates its 25th anniversary