1. What is HTTP?
Core concepts of computer networks: Network protocols
. There are many types of network protocols, some of which are familiar, IP, TCP, UD... There is also a very widely used protocol, HTTP. The HTTP protocol is most likely to be the most used protocol in our future development.
HTTP : (full name "Hypertext Transfer Protocol") is a very widely used application layer protocol
HTTP is in the application layer of the TCP/IP five-layer protocol stack.
HTTP is based on TCP at the transport layer (not rigorous enough, HTTP/1, HTTP/2 are based on TCP , and the latest version is HTTP/3, which is based on UDP , but the current Internet is absolutely Most of the HTTP used is HTTP/1.1 )
Transport layer protocols are mainly concerned with end-to-end data transmission. TCP focuses on reliable transmission of
application layer protocols . From the perspective of program application, the transmitted data must be specifically used.
Application layer protocols are often customized by programmers and are designed according to actual demand scenarios.
However, in the circle of big programmers, the level is uneven.
So some big guys invented some very useful protocols and let everyone copy them directly. HTTP is a typical representative of them.
Although HTTP has been designed, its scalability is very strong, allowing programmers to transmit various customized data information according to actual needs.
The specific application scenarios of HTTP are used by everyone every day. As long as you open a browser and randomly open a website, you are actually using HTTP at this time.
Or you open a mobile APP and load some data casually. At this time, there is a high probability that you will also HTTP is used
2. HTTP protocol format
1. Agreement format
Protocol format: How is the data organized?
UDP : header (source port, destination port, length, checksum) + payload
Protocols such as UDP/TCP/IP are all "binary" protocols , and it is often necessary to understand the binary bits.
HTTP is a text format protocol (you do not need to understand the specific binary bits, but just understand the text format) (text format, so it is more convenient for human eyes to observe)
How can I see the HTTP message format?
- In fact, you can use some "packet capture tools" to obtain the specific HTTP interaction process, requests and responses.
TCP/UDP can also be analyzed with the help of packet capture tools.
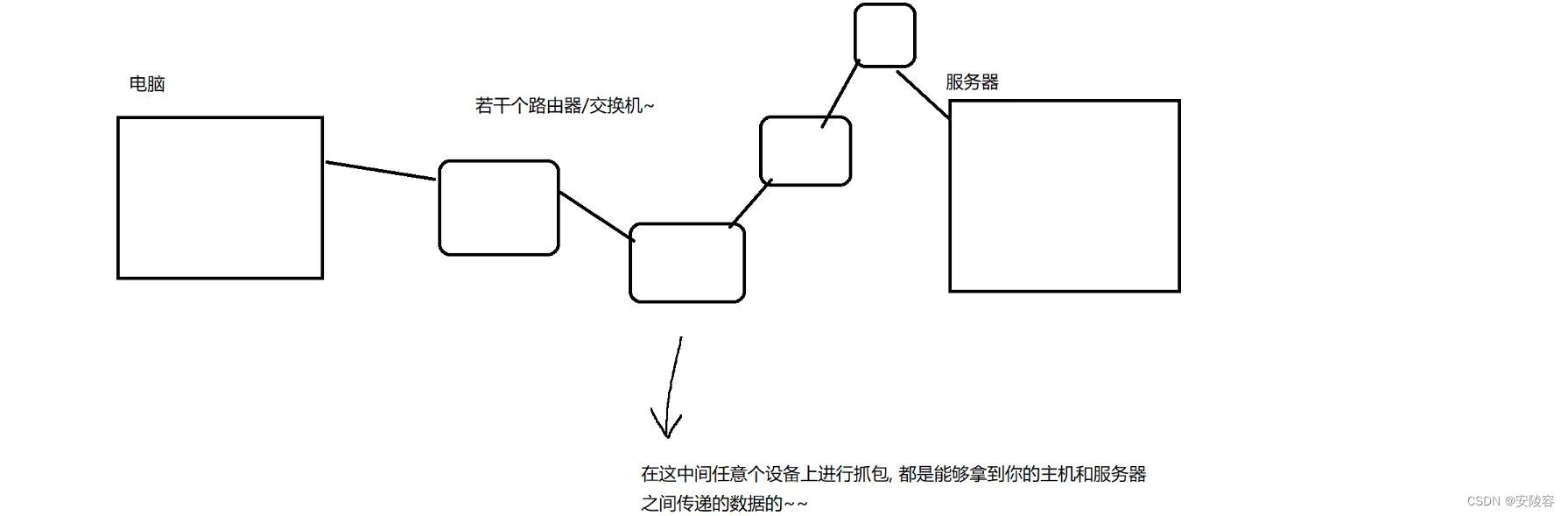
The packet capture tool is actually a third-party program that acts like a "proxy" in the process of network communication. For example, I am in the dormitory and I don’t want to buy food, so I order takeout to be delivered to the dormitory. In this scenario, the person who delivers the takeout is the agent.
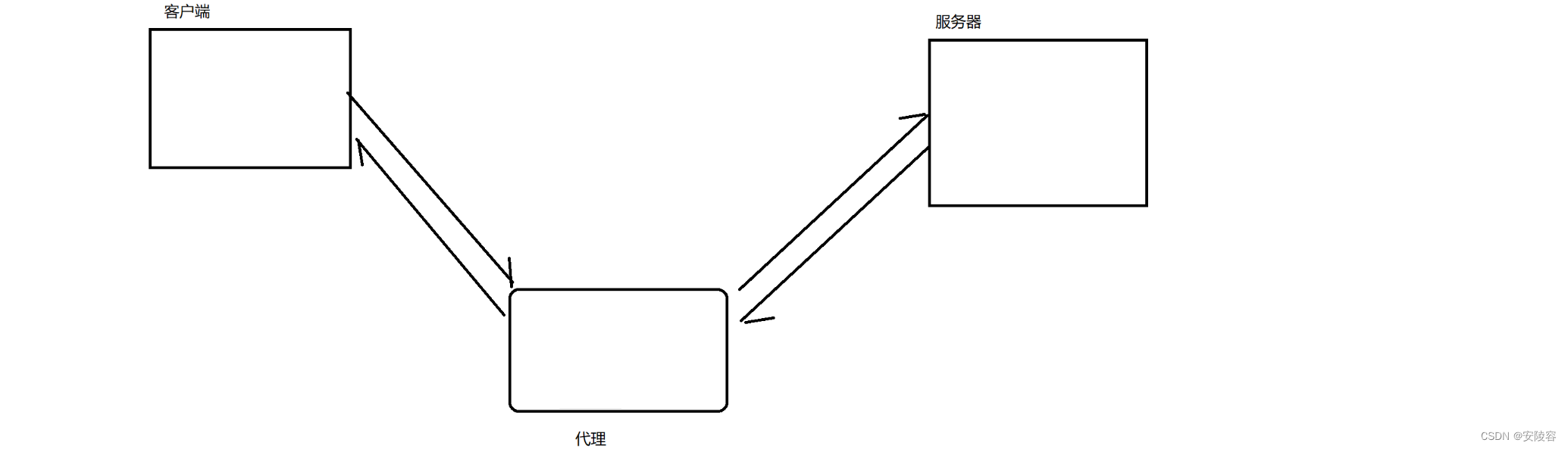
Both requests and responses have to pass through the proxy. At this time, it is easy to obtain the details of the request and response
on the proxy. Therefore, the packet capture tool is a proxy, and the packet capture tool can easily obtain it during the transmission process. Detailed data on the network
2. Packet capture tool Fiddler
Fiddler is a packet capture tool that specializes in capturing HTTP. It cannot capture TCP/UDP/IP... To capture these, you need to use a tool like wireshark.

On the left side of Fiddler , there is a list showing all the HTTP/HTTPS datagrams currently captured . HTTPS is the twin brother of HTTP. HTTPS just introduces an encryption mechanism based on HTTP.
When an item in the list on the left is selected and double-clicked, the detailed information of the item will be displayed on the right.
ask:
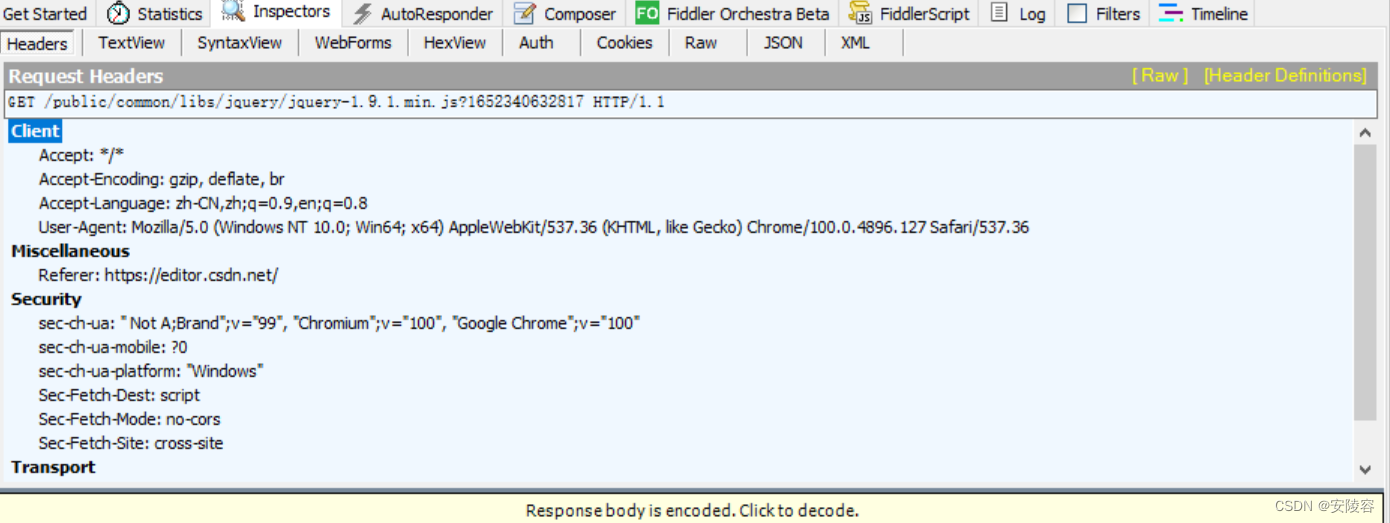

The options on this tab page indicate what format is currently used to display HTTP requestsRaw . This is the option we use most.
Select and what you Rawsee is the body of the HTTP request data
. Select other options, which is equivalent to Fiddler processing the data. Some processing, adjusted the format
Click and Rowthe original data will come out!!
However, it is too small to see clearly!! You can click next to itview in Note

The above is the original appearance of an HTTP request.
If you construct data in the TCP socket according to the above format and write it to the socket, it is essentially equivalent to constructing an HTTP request.
response:
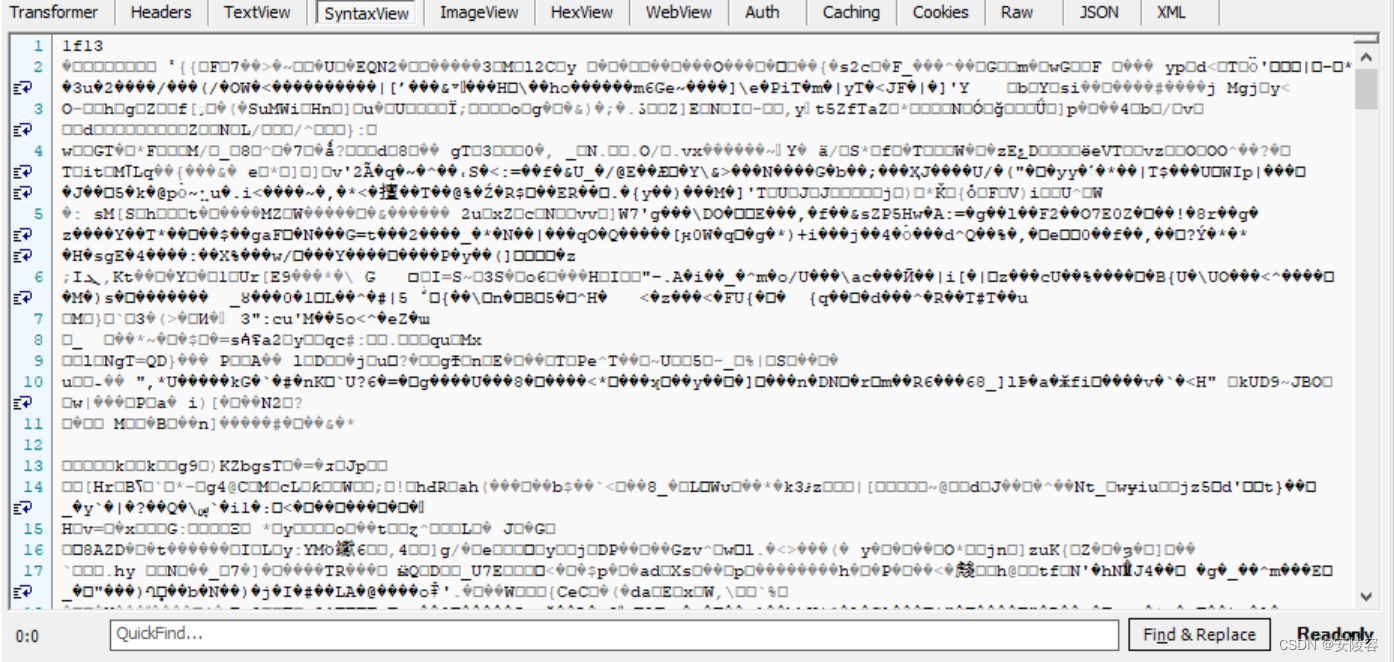
There are many options for response. You need to select here Rawto see the ontology .

The main body you see seems to be garbled ? Garbled characters are actually the result of compression.
For a server, the most expensive hardware resource is actually network bandwidth . HTTP responses like these are often very large and take up more bandwidth. In order to improve efficiency, the server often returns "compressed" data, which is then decompressed by the browser after receiving it.
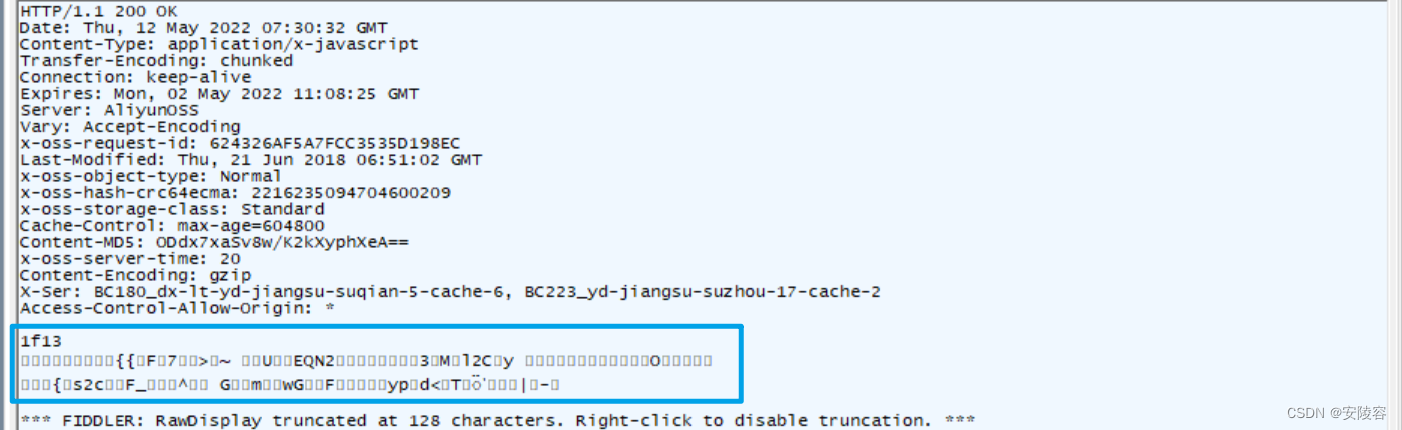
Click this button to unzip:

Notice:
1. When Fiddler is first installed, HTTPS is not enabled by default . If you catch the HTTPS package, a similar situation will occur.

Most of the websites on the Internet today are HTTPS . If HTTPS is not turned on, there is basically nothing to catch.
2. Fiddler may remind you to install the xxx certificate (a string of English...), be sure to click yes!!!
3. Fiddler, as a proxy, conflicts with other proxy programs.
If other proxy programs/plug-ins are also installed on your computer, it may cause Fiddler to fail (nothing can be caught). Before using fiddler, you must first Exit related programs
Security Question:
- Check the corresponding application to see whether the user name and password are encrypted. If not, you can obtain the
network communication data on the current host through packet capture.
Moreover, this packet capture does not necessarily have to be in On your computer, or on an intermediate node in the communication link- How to solve this problem requires encryption at the application layer
https:
It is indeed encrypted, and it is indeed ensuring security, but https is mainly to prevent tampering , not to prevent theft [main purpose]
3. HTTP request format
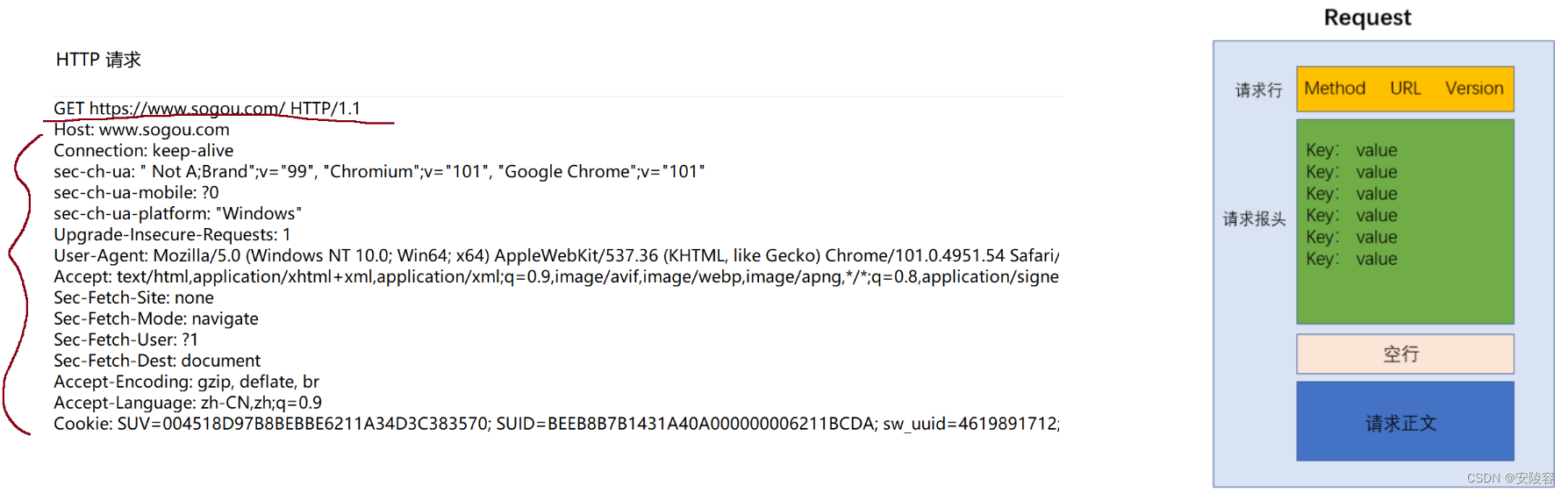
The request is divided into 4 parts:
-
The request line (first line) contains three parts:
- 1. HTTP method . The method roughly describes what this request wants to do. ``GET` means to get something from the server.
- 2.
URLDescribe where the resources on the network to be accessed are located. - 3. Version number , HTTP/1.1 means that the currently used HTTP version is 1.1. 1.1 is the most mainstream version at the moment, and it may also be 1.0 / 2 / 3
-
Request header (header) , containing many lines
- Each row is a key-value pair
- Use between keys and values to
:空格separate
key-value pairs, a very, very, very important concept in computers - The number of key-value pairs here is not fixed (it may be more or less), and different keys and values have different meanings (the meanings of some common key-value pairs will be introduced later)
-
Empty line : equivalent to the end tag of the request header
, similar to null in the linked list -
Request body : optional, not necessarily included
A little trick for using fiddler:
- The list on the left will continue to capture new results , and the list will soon be very large (many websites are constantly interacting with the server, and even some other programs on your computer are also secretly communicating with others. Server uses HTTP interaction)
- Many times you need to clear the screen , select a record, then ctrl + a to select all, and then press delete to delete.
A simple click to log in will allow N multiple interactions between the browser and the code cloud server. This is normal.
We need to find the request we want to pay attention to and respond.

4. HTTP response format

-
First line : contains 3 parts
-
1. Version number HTTP/1.1
-
2. The 200 status code describes whether the response is "successful" or "failed", and different status codes describe the reason for the failure.
-
3. The description of the OK status code uses a / a group of simple words to describe the meaning of the current status code.
-
-
response header
- It is also a key-value pair structure, with each key-value pair occupying one line.
- Use to separate each key and value
:空格, - The number of key-value pairs in the response header is also uncertain. Different key-value pairs represent different meanings
-
A blank line
represents the end tag of the response header. -
Response body (body)
- Specific data returned by the server to the client
- Things here may come in a variety of different formats , the most common of which is html!!
3. HTTP request (Request)
1、URL
- What we usually call "website" is actually URL (Uniform Resource Locator )
- Every file on the Internet has a unique URL. It is necessary to know not only who the host is, but also which resource on the host to retrieve.
1.1. Basic format of URL

1. Agreement plan name:
-
Describes which protocol the current URL is used for
-
http://for HTTP
https://for HTTPS
jdbc:mysql://for jdbc:mysql
2. Login information:
- This part is rarely used now. In ancient times, when surfing the Internet, the username and password would be reflected here.
3. Server address
- What is the host currently being accessed ? This can be an IP address or a domain name.
4. Server port number
- Indicates which application on the host is currently being accessed (the port number is omitted in most cases )
- When omitted, it does not mean that there is none, but the browser will automatically assign a default value . For URLs starting with http,
80the port will be used as the default value. For URLs starting with https,443the port will be used as the default value.
5. Hierarchical file paths
- The file path describes the resources of the server currently being accessed.
- Although a file path is written in the requested URL, it does not necessarily mean that a corresponding file actually exists on the server . This file may be a real file that exists on the disk, or it may be virtual, a dynamic data constructed by the server code.
The above IP address + port + hierarchical file path actually describes a specific resource on the network, but on this basis, it can also carry some other requirements, which are the following parameters.
6. Query string
-
Essentially, the browser/client passes customized information to the server , which is equivalent to putting forward further requirements for the obtained resources.
-
The content of the query string is essentially a key-value pair structure, which is completely defined by the programmer himself and is unknown to outsiders. For example: spm=1001.2014.3001.5502, key: spm, value: 1001.2014.3001.5502, multiple key-value pairs are separated by address characters
-
Use ? to separate query string and path
-
The path is
/, the query string (query stirng) does not have https://www.sogou.com/The path web, the query string is followed to the end, https://www.sogou.com/web?
query=fiddler&_asf=www.sogou.com&_ast=&w=01015002&p=40040108&ie=utf8&from=index-nologin&s_from=index&oq=&ri=0&sourceid=sugg&suguuid=&sut=0&sst0=1652343501136&lkt=0%2C0%2C0&sugsuv=1623569485720894&sugtime=1652343501136The path is qq_56884023/article/details/124481401, and the query string is from the end to https://blog.csdn.net/qq_56884023/article/details/124481401?
spm=1001.2014.3001.5502
7. Fragment identifier
- Describes which specific sub-section of the current html page is to be accessed , and can control the browser to scroll to the relevant position
Omissible parts of the URL:
- Protocol name: can be omitted. If omitted, it defaults to http://
- IP address/domain name: can be omitted in HTML (such as img, link, script, src or href attribute of a tag). If omitted, it means that the IP address/domain name of the server is consistent with the IP address/domain name of the current HTML.
- Port number: can be omitted. After omitting, if it is http protocol, the port number is automatically set to 80; if it is https protocol, the port number is automatically set to 443.
- Hierarchical file path: can be omitted. When omitted, it is equivalent to /. Some servers will automatically access /index.html when discovering the / path.
- Query string: can be omitted
- Fragment identifier: can be omitted
URL summary:
- For URLs, the structure inside looks complicated. In fact, the most important ones and those most closely related to development are mainly four parts.
- ip address/domain name
- Port number (usually a small transparent one)
- Hierarchical path
- query string query string (these two are closely related to writing code!!!)
1.2、URL encode / decode
- When the query string contains special characters , the special characters need to be escaped.
- This escaping process is called url encode . On the contrary, restoring the escaped content is called url decode
There are many symbols with special meanings in the url /: ? &=... These symbols have specific meanings in the URL
. If the query string also contains such special symbols, it may cause the URL to fail to be parsed!!!
When we search for C++ in sogou, we can see that there is a key-value pair in the query string in the URL, which represents the content of the query word
https://www.sogou.com/web?query=C%2B%2B&_ast=1652345880&_asf=www.sogou.c …
%2BIn fact, it is +the result obtained after escaping through url encode. +The ASCII hexadecimal representation of the character is exactly 2B (B is the hexadecimal symbol, equivalent to 11 in decimal)
During actual development, especially when the front-end and back-end interact, especially when some information needs to be transmitted to the server through the URL, URL encoding must be performed on the special symbols inside. Not just punctuation, but also Chinese characters
that can cause problems if not escaped
- A Chinese character is composed of an encoding method such as UTF-8 or GBK. Although it has no special meaning in the URL, it still needs to be escaped. Otherwise, the browser may regard a certain byte in the UTF-8/GBK encoding as a character in the URL. special symbols
- The escaping rules are as follows: Convert the characters that need to be transcoded into hexadecimal , then from right to left, take 4 digits (less than 4 digits are processed directly), make one digit for every 2 digits, add % in front, and encode it as % XY format, each byte is processed separately
For example, Sogou's a tag has an href attribute that contains the user's query. If the Chinese query is not urlencoded on the page, it will cause the user to not be able to jump correctly after clicking on some browsers.

2. Method
Only 1.1 is listed here, and the subsequent 2 3 versions will not be considered for the time being.
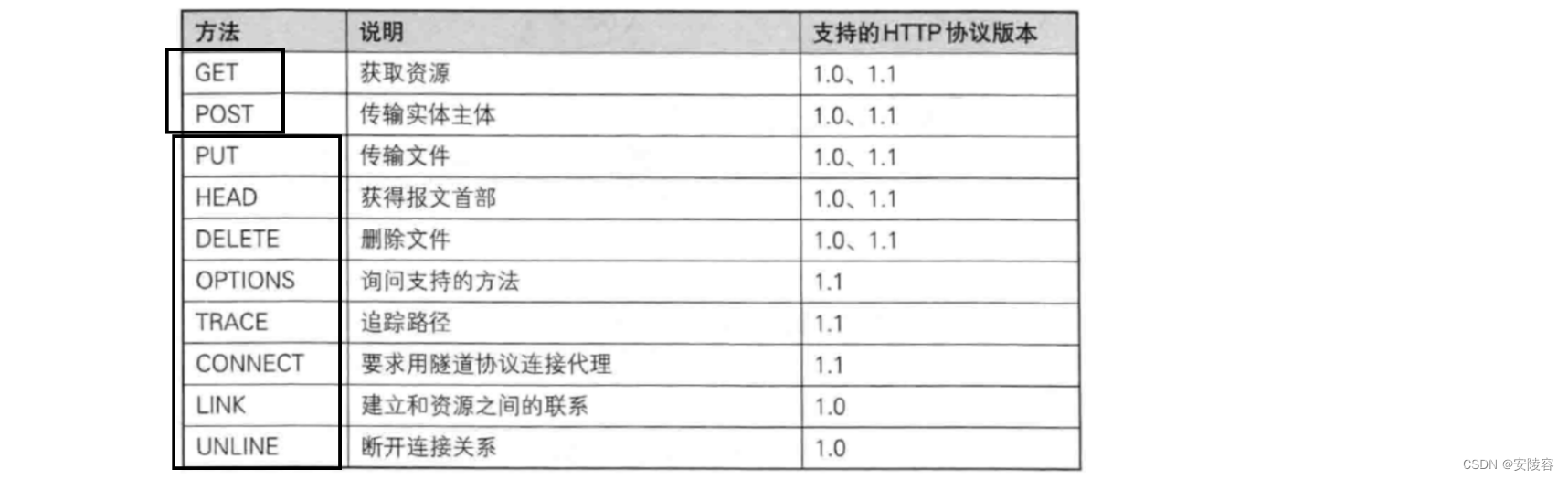
There are many methods of HTTP protocol!!!
But the most commonly used ones are GETand POST. GET will occupy eight buckets exclusively, POST will occupy one bucket, and the remaining methods will share this bucket.
- PUT is similar to POST, but has idempotent properties and is generally used for updates.
- DELETE deletes the resource specified by the server
- OPTIONS returns the request methods supported by the server
- HEAD is similar to GET, except that the response body is not returned, only the response headers are returned.
- TRACE echoes the request received by the server. This will be used during testing.
- CONNECT Reserved, not used yet
- (Note, this is just expected)
2.1. Semantics
The original intention of introducing these methods in HTTP is to express different "semantics" . Semantics: whether there is a specific meaning.
For example, HTML: h3, p, a, img... semantic tags, div span without semantic tags
The ideal is full, but the reality is very skinny.
The big guys who designed HTTP hope that programmers can use the various methods here according to HTTP semantics.
But as time goes by, the use has gone out of shape. Now everyone writes code, basically GET / POST is a shuttle, and there is basically no consideration of semantics
. Because of this, the boundaries between various HTTP methods have become blurred.
GET can also send something to the server, and POST can also get something from the server.
2.2. Classic interview question: Talk about the difference between GET and POST
The first sentence is to seal the deal first!! There is no essential difference between GET and POST!!!
Specifically, it is equivalent to the scenario where GET can be used, and it can also be replaced by POST. The scenario where POST can be used, can also be replaced by GET. However, there are still some differences in the details.
-
The semantic difference is
that GET is usually used to retrieve data, and POST is usually used to upload data. The current situation is that GET is also often used to upload data, and POST is also often used to obtain data. -
Normally , GET does not have a body, and GET transmits data to the server through query string.
Normally , POST has a body, and POST transmits data to the server through body, but POST does not have query string.- If I just want GET to have a body (construct a GET request with body by myself), or I want POST to have query string, it is not a
mandatory difference at all, it is just a common usage. You can follow the habit or break it. Habit. Like some companies, Uniform uses POST to handle all requests.
- If I just want GET to have a body (construct a GET request with body by myself), or I want POST to have query string, it is not a
-
GET requests are generally idempotent , and POST requests are generally not idempotent (it is not a requirement, but a recommendation )
- Idempotent : It is a mathematical term. Every time you give the same input, the output you get is certain. Not idempotent : every time you give the same input, the result you get is uncertain
-
GET can be cached , POST cannot be cached
- Remember the result in advance. If it is idempotent, it is very useful to remember the result, saving the cost of the next access. If it is not idempotent, you should not remember that
whether it can be cached is related to whether it can be idempotent. If the request itself is not idempotent, it cannot be cached.
- Remember the result in advance. If it is idempotent, it is very useful to remember the result, saving the cost of the next access. If it is not idempotent, you should not remember that

For example, although the obtained advertising data is also obtained through GET, it must not be cached!! It must be calculated in real time to ensure that the right users deliver the right ads, and the ads must comply with the advertiser's placement rules.
Note : The most typical mistakes on the Internet:
- There is an upper limit on the data length passed by the GET request (there is an upper limit on the URL), but there is no upper limit on the POST
error!!! In the HTTP standard document, it is clearly stated that the standard itself does not limit the length of the URL (the reason why this statement is circulated on the Internet is that browsing in ancient times The browser implementation does not fully comply with the standard... is not suitable for modern browsers...)
3. Request "header"
- There are some key-value pairs in the header. Different key-value pairs represent different meanings.
- There are currently many types of key-value pairs here. Here are some simple and common ones:
3.1、Host
Indicates the address and port of the server host
Host: www.sogou.com. Domain names can be converted into IP addresses through DNS
3.2、Content-Length、Content-Type
Content-LengthRepresents the data length in bodyContent-TypeRepresents the data format in the request body
These two attributes describe the body. If there is no body (GET) in your request, these two fields are not needed!!!
Generally, POST has a body, and login is generally implemented based on POST! !
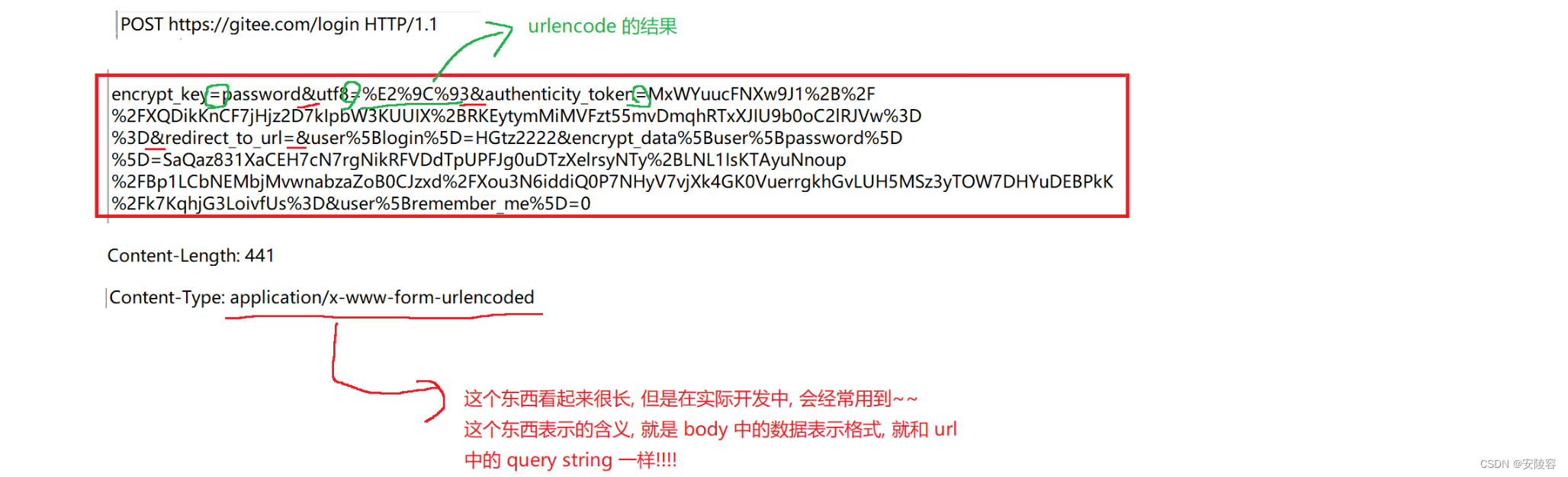
Why is logging in using POST? Can I use GET to achieve login?? It is completely possible to use GET to achieve the login function!!
Why do you still mainly use POST?
When logging in, you must pass the username and password to the server . If it is GET , the username and password are customarily passed in the query string of the URL.
At this time , the path in the browser's address bar, It may become a very long string)
(At this time, the user experience may not be very good)
Especially in the early days, many websites submitted passwords in clear text.
If the password appeared in clear text in the URL, it would actually look very bad.
The POST data is in the body and cannot be seen directly by the user . Whatever you put in the body will have very little impact on the user.
There is a saying on the Internet: Use POST to log in because POST is more secure than GET. This statement is completely wrong. It is not safe and it depends on whether your data is transmitted in clear text and whether it is encrypted.
Common options:
-
application/x-www-form-urlencoded: The data format submitted by the form form. At this time, the format of the body is as follows:- title=test&content=hello
-
multipart/form-data: The data format submitted by the form form (added in the form tag
enctyped="multipart/form-data"is usually used to submit pictures/files. The body format is as follows:-
Content-Type:multipart/form-data; boundary=----
WebKitFormBoundaryrGKCBY7qhFd3TrwA------WebKitFormBoundaryrGKCBY7qhFd3TrwA
Content-Disposition: form-data; name=“text”title
------WebKitFormBoundaryrGKCBY7qhFd3TrwA
Content-Disposition: form-data; name=“file”; filename=“chrome.png”
Content-Type: image/pngPNG … content of chrome.png …
------WebKitFormBoundaryrGKCBY7qhFd3Trw
-
-
application/json: The data is in json format. The body format is as follows- {“username”:“123456789”,“password”:“xxxx”,“code”:“jw7l”,“uuid”:“d110a05ccde64b16a861fa2bddfdcd15”}
- The format of the body in the third most common request,
json(1. Customized application layer protocol 2.js object)
Additional information about Content-Length:
HTTP is also a protocol based on TCP.
TCP is a byte stream-oriented protocol. The problem of sticky packets => Reasonably design the application layer protocol to clarify the boundaries between packets!!Both of these are reflected in HTTP:
- Use delimiters
- If there are currently several GET requests in the TCP receive buffer...
When the application reads the requests, it uses a blank line as the delimiter.- Use length
- If there are currently several POST requests and the TCP buffer is reached. At
this time, there is a body after the blank line. After the application reads the blank line, it needs to continue reading several lengths of data according to the length indicated by Content-Length.
3.3. User-Agent (UA for short)
It means what kind of thing the current user is using to surf the Internet.

Mainly operating system information + browser information
In ancient times, browsers were in a state of rapid progress. At first, browsers could only display text.
Later, they were able to display images.
Later, they were able to display various complex styles. Later, they were able to load js to achieve interaction. Later
, it was able to support various multimedia (playing videos, etc.
In the past, due to the rapid development of browsers, the market was severely fragmented.
Some users use older browsers (which can only display text)
- some users use relatively new browsers (can support js)
This time brought challenges to website developers
. In order to solve this problem, smart programmers came up with the idea of letting the browser send a self-reported home
server in the request. The server can then use the self-reported home address in the browser. information, you can make a distinction
Today in 2022, the functions of mainstream browsers have very little difference (ten years ago, browser compatibility was still a big issue to be considered in front-end development), and the role of the UA field is no longer that big
. With the advent of the current mobile Internet, UA now has a new mission: the biggest difference between PC and mobile is the size and ratio of the screen!!! The screen size is much smaller than that of the PC (generally the mobile phone) For web pages, you need to design buttons and the like larger). The screen ratio is that PCs are all wide-screen, and mobile phones are all narrow-screen. Different ratios lead to different page layouts. Therefore, the server can distinguish whether it is a mobile phone or a mobile phone based on UA . Computer. If it is a mobile phone, it will return to the mobile version of the web page. If it is a computer, it will return to the computer version of the web page.
The reason why User-Agent looks like this is because of historical issues. You can refer to
the story of User-Agent: http://www.nowamagic.net/librarys/veda/detail/2576
3.4、Refer
- Indicates the current page and which page it jumps from.
- Referer is not necessarily present . If you enter the address directly through the browser address bar, or directly click on the favorites, there is no referer at this time.
Refer: https://gitee.com/login
Referer is also a very useful field in the advertising system, which charges by click!!

As long as the user clicks on the search results, this click will trigger billing!! (Advertisers have to pay Sogou!!) CPC advertising (pay per click)
Since the billing is based on clicks, how many times has this ad been clicked in a day/month? There must be a clear statistics!!!
ROI input-output ratio, this statistic, is it Sogou’s statistic or advertiser’s statistic?? In fact, it’s both statistics.
Sogou statistics : Each click request will access Sogou’s server first and then jump to the advertiser’s page.

With one click, the request is sent to Sogou's bill server, and Sogou can make statistics based on the data received on this server.
Advertiser statistics : Some logs can also be recorded on the advertiser’s website.
An advertiser may advertise on multiple platforms.
The advertiser can use Referer to distinguish which advertising platform imported traffic the current request is from.

Is it possible that there is an operation to tamper with the Referer in the HTTP request? It was originally Sogou, but it was changed to something else.
This possibility is entirely possible, and it was very rampant at one time!
Who has the ability to do this? Who has the motivation to do it? => Operator
Operators also have their own advertising platforms.
Network infrastructure (routers and switches) are provided by operators. Network traffic passes through their equipment, and their equipment can capture your request and modify it.
This situation was very common before 2015. Here, the lawsuit should be fought, but it must also be countered through technical means: HTTPS
Before 2015, advertising platforms such as Baidu and Sogou all used the HTTP protocol (there were very few HTTPS on the Internet at that time), so these major Internet companies have begun to upgrade to HTTPS.
3.5、Cookie
Browsers, for the sake of security, do not allow the js of the page to access the file system on the user's computer by default.
Suppose a web page contains malicious code. If you are not careful, this malicious code may be triggered and destroy the files on your computer. Some files have been deleted!!!
However, such security restrictions also bring some troubles. Sometimes, it is really necessary to store some data persistently on the page to facilitate subsequent access to the website.
Among them, the most typical one is to store the user's current identity information.
After the user completes the identity authentication on the login page, the server will return the user's identity information to the browser, and the browser will save this information to a specific location, when you subsequently visit other pages of the same website, the browser will automatically bring this identity information, and the server will be able to identify it.
Therefore, this is the current strategy!!!
Although you cannot let the js of the page access your entire disk data, you can assign a small black room to the browser separately , and the js code can be tossed around in this small black room. Here is If you mess around, it won’t affect other learning materials on your disk.
The small dark rooms here come in many different forms.
Among them Cookieis an older and more classic form. Modern browsers also support some other local storage solutions.
Cookie is a mechanism provided by the browser to the page to store data persistently . Persistence means that the data will not be lost (written to disk) due to program restart or host restart.
The specific organizational form of cookies:
- First organize it by domain name , and assign a small room to each domain name . When I visit Sogou, the browser will record a set of cookies for the domain name sogou. When I visit Code Cloud, the browser will also record a set of cookies for Code Cloud.
- In a small room, data will be organized according to key-value pairs.

Where does cookie data come from: It is actually returned by the server to the client.
Contains a set of such headers , that is, after the server completes the identity authentication, it returns some specific information to the client . The information is represented by Set-Cookiesuch a response header

Cookies store identity information, which is like going to the hospital to see a doctor.
When you go to the hospital, the first thing you need to do is register
at the registration office. In addition to paying money, they will also give you a medical card. When giving you the medical card, the staff will ask you for your specific information ( Name, ID number, phone number…In the process of subsequent medical treatment, this medical card played a vital role. I
first came to the pediatric clinic. Before seeing a doctor, the doctor had to swipe my medical card. Swiping the card was to obtain my identity information. In the identity information In addition to basic information, there are also past casesAfter some diagnosis, the doctor gave me some orders:
go to the laboratory, take blood tests, and do a routine blood test. I still took my medical card and swiped it, and with this swipe I got my basic information, and the specific test contents that the doctor just prescribed for me to go to the radiology department.Arrange an X-ray. I also take my medical card and swipe it, and I know what kind of film I want to take...
During the above process, the medical card in my hand is a cookie!!!
Although some information can be stored on the medical card, the amount of data saved is limited.
It is not this card that actually saves my information, but it is placed in the hospital. on the server , and on the card, I only need to store one of my identities (save a user id)
This key information is stored on the server. This thing is called "session".
The server manages many sessions.
Each session stores the user's key information (basic information, examinations to be done, past cases...), and each session also has a sessionld(session identification).
What is actually stored on the medical card is the ID of this session.

This thing looks very much like a sessionld
server. It can find the session corresponding to the user based on this data, and further obtain the user's details. The key-value pairs
stored in the cookie here are also similar to the query string, and are also programmed by programmers. Definition, outsiders don’t know and can’t understand it
Summarize:
- Cookie is a mechanism provided by the browser to persistently store data.
- The most important application scenario of Cookie is to store the session ID, so that when accessing subsequent pages of the server, this ID can be brought, so that the server can know the current user information (the mechanism of saving user information on the server is called for Session)
- Can cookies be used to store other information? Of course it is possible!!! You can save whatever you want to save, it is all customized by programmers!!!
Understanding of Session: QQ’s message list is equivalent to the “session list”, and the chat records here are equivalent to the user’s detailed information.
4. Text body
The content format in the text is very flexible, depending on the Content-Type in the header.
You can observe these situations by capturing packets:
-
application/x-www-form-urlencodedLike query string, it has a key-value pair structure, using separation between key-value pairs&, and separation between keys and values=, and must beurl encode-
Catch code cloud upload avatar request
avatar=data%3Aimage%2Fpng%3Bbase64%2CiVBORw0KGgoAAAANSUhEUgAAAPgAAAD4CAYAAADB0Ss
LAAAg…
-
-
multipart/form-dataupload files-
Capture the “upload resume” function of the educational administration system
------WebKitFormBoundary8d5Rp4eJgrUSS3wT
Content-Disposition: form-data; name="file"; filename="Li Xingya Java Development Engineer.pdf"
Content-Type: application/pdf%PDF-1.7
%³
1 0 obj
<</Names <</Dests 4 0 R>> /Outlines 5 0 R /Pages 2 0 R /Type /Catalog>>
endobj
3 0 obj
<</Author ( N v~N•) /Comments () /Company () /CreationDate
(D:20201122145133+06’51’) /Creator ( W P S e [W) /Keywords () /ModDate
(D:20201122145133+06’51’) /Producer () /SourceModified (D:20201122145133+06’51’)
/Subject () /Title () /Trapped /False>>
endobj
13 0 obj
<</AIS false /BM /Normal /CA 1 /Type /ExtGState /ca 1>>
endobj
-
-
application/json{}Key-value pairs composed of right , use commas to separate key-value pairs, and use: to separate keys and values.-
Capture the login page of the educational administration system
{“username”:“123456789”,“password”:“xxxx”,“code”:“u58u”,“uuid”:“9bd8e09ea27b48cdacc6a6bc41d9f462”}
-
Packet capture is a very useful skill
- Understanding HTTP
- Debugging a web program
- Implement a crawler
- Write an HTTP client yourself to simulate human operations and automatically obtain some content from the website.
Any programming language can write a crawler as long as it can operate the network. Using Java to write a crawler is also a very common operation.- Each website will provide a file like robot.txt. This file tells you which resources can be crawled legally. In theory, as long as you crawl content that is not included in the whitelist given by the website, it will be considered. illegal behavior
4. HTTP response
1. Status code
Indicates whether the request was successful or failed , and the reason for the failure.
There are many status codes provided by HTTP:
200 OK is the most common status code, indicating that the access is successful.
404 Not Found The resource to be accessed does not exist
sogou.com/1.html:

bilibili/1.html:

403 Forbidden Although the resource is available, you do not have permission to use it (ugly rejection)
HTTP/1.1 403 Forbidden
This situation is difficult to encounter when you go to an external website to capture packets... But if you write the website backend later, this will easily happen. For example,
try to use GET to access other people's servers, but they may only support POST, so will return 405
500 Internal Server Error There is a problem with the server itself, which means a bug. The probability of seeing this situation on external servers is relatively low, but it is easy for this situation to occur if we write the code ourselves later.
504 Gateway Timeout The server is too busy
302 Move temporarily redirect
During the login process, a very typical situation
This word is involved in many computer scenarios, not just HTTP.
Although there are differences in details in different scenarios, the core meaning is call transfer. Call
transfer: China Mobile, one that operators can handle here. For business, if someone calls my old number, it will be automatically transferred to my new number.
HTTP/1.1 302 Found
Location: https://gitee.com/xxxxxxxxx/kodi-source
Location describes where to jump next!!
In the redirect response, the Location attribute is generally required
Types of HTTP status codes:
2 At the beginning , everything is a success - 200
Starting with 3 , they are all redirects - 301 302
4 begins with an error on the client side——404 403
5 starts with an error on the server - 500 504
Status codes starting with 1 and 6 are very rare and rare.
Among these status codes, there is actually a special one, 418
418. Although it is not available on Sogou Encyclopedia, it does exist in the HTTP standard document.
The description: l am a teapot I am a teapot It
is an easter egg (programmer's humor)
However, in actual development, be cautious about Easter eggs. A typical negative case:
there is an ant design open source component (made by Alibaba) in the front-end field. This was still very popular before, and many people were using it. So the
author created an Easter egg. This easter egg will be triggered
on Christmas Day. If you use the ad component, a "little cloud" will appear on it. Such a small logo. The
customer said why this button was half chewed by a dog.