LLM for Time Series:Text Prototype Aligned Embedding to Activate LLM’s Ability for Time Series
Today I would like to introduce to you a work jointly launched by Peking University and Alibaba, using LLM to implement time series classification and prediction tasks.
Recap
Current work on time series LLM mainly consists of two strategies:
The first is LLM for-TS: designing and pre-training a basic large model suitable for time series from scratch, and then fine-tuning the model according to various downstream tasks. This path is the most basic solution, based on a large amount of data and instilling time series related knowledge into the model through pre-training.
The second is TS-for-LLM: designing corresponding mechanisms to adapt the time series so that it can be applied to the existing language model, so as to process various tasks of the time series based on the existing language model. This path is challenging and requires capabilities beyond the original language model.
This article mainly explores the TS-for-LLM problem. There are three main reasons:
LLM-for-TS requires a large amount of data accumulation. Compared with text or image data, time series data is more specialized and involves privacy issues. It is more difficult to obtain large amounts of time series data. TS-for-LLM can use relatively small data sets.
LLM-for-TS focuses on vertical domain models. Since there are significant differences in time series data in different fields, various models for different fields such as medical and industrial need to be built and trained from scratch. TS-for-LLM requires almost no training and is more versatile and convenient by utilizing plug-in modules.
TS-for-LLM retains the textual capabilities of language models while providing rich supplementary semantic information that is easily accessible and user-friendly.
This paper designs a time series encoder Test through instance-wise, feature-wise and text-prototype-aligned comparative learning to obtain time series embedding that is more suitable for LLM. At the same time, this article also designs corresponding prompts to make the existing LLM more suitable for time series embedding, and ultimately realizes a variety of time series tasks.
Method introduction
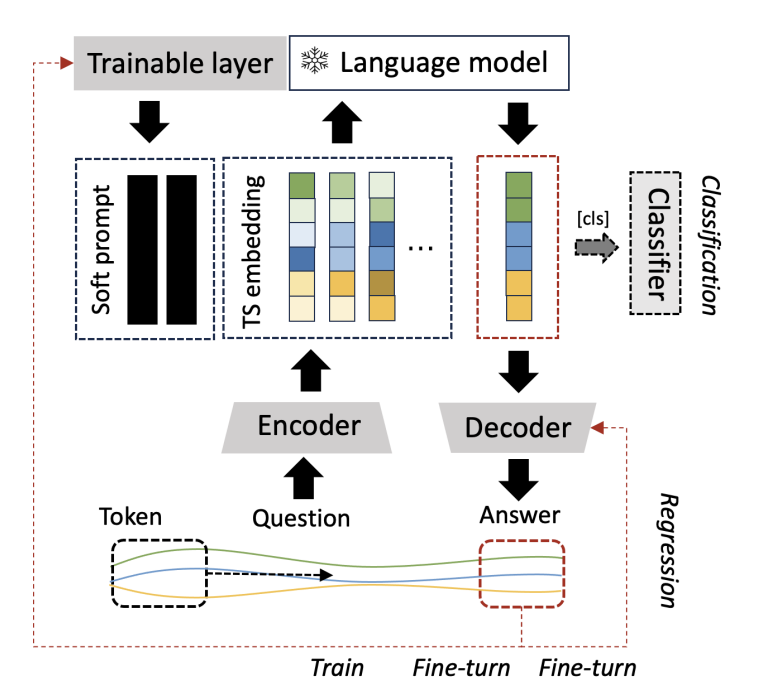
The method proposed in the article includes: 1) tokenizing the time series (word segmentation processing), and then using contrastive learning to train the time series encoder; 2) Prompt design, two key steps, which are introduced in detail below.
TS Token Augmentation and Encoding
For a multivariate time series containing D variables and T samples, it can be divided into K subsequences (this process can be regarded as a sliding window), and s can also be called the token list of the sequence x. Treat s as an anchor instance, and the corresponding positive sample comes from two parts, one is the subsequence with overlapping samples, and the other is the instance sum obtained through data augmentation. It can be obtained by adding noise and scaling to the original sequence, and it can be obtained by randomly dividing and shuffling the sequence. Negative samples are instances that do not have overlapping samples with s.
Then, use the mapping function to map each token into an M-dimensional representation, and finally obtain the token list of x.
For the obtained token, the objective function is first used to ensure that e can fully represent the original sequence information. Next, we will further consider three types of contrastive learning: instance-wise, feature-wise, and text-prototype-aligned.
Instance-wise contrast learning: For the constructed positive and negative instances, ensure that the target anchor instance is as similar as possible to its corresponding positive token instance and as different from the negative token instance as possible. The objective function is as follows:
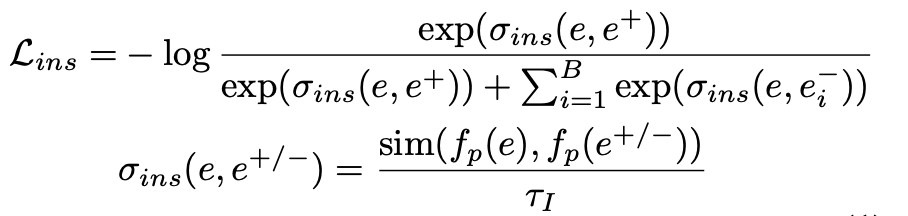
The disadvantage of instance-wise contrast learning is that instances that have no overlapping samples but are close in location and semantics may be regarded as negative examples. Therefore, the article further designs feature-wise contrast learning, focusing on the semantic information contained in different columns. The objective function is as follows:
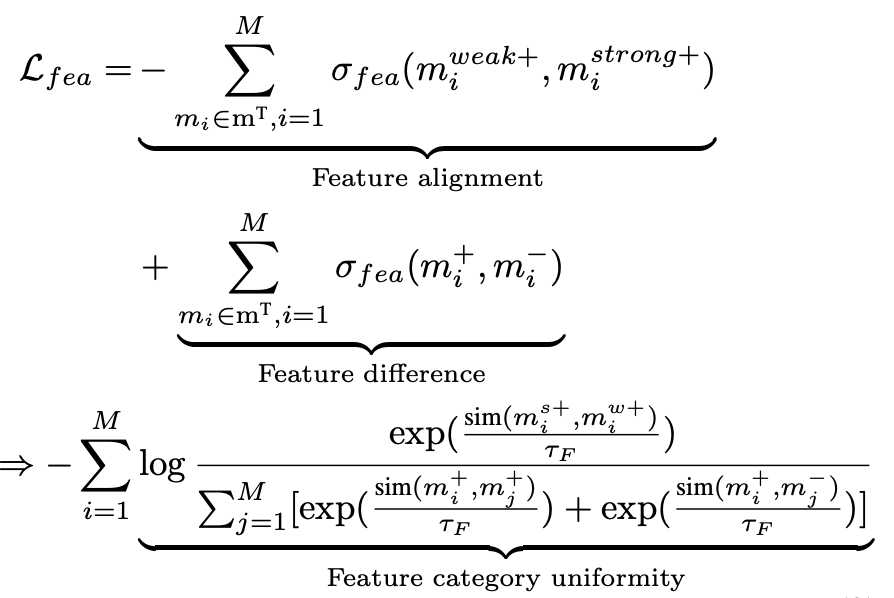
, and in this objective function can be obtained through the mapping , . B is the size of mini-batch. The above objective function ensures that for each feature level, the positive samples are as similar as possible and the negative samples are as different as possible. However, this easily causes the feature representation to shrink to a smaller space, so the last term of the objective function maximizes different features. difference between.
text-prototype-aligned contrast learning: Finally, in order to allow LLM to better understand the constructed TS-embedding, the article designed text-prototype-aligned contrast learning to align it with the text representation space. Currently, pre-trained language models already have their own text token embedding. For example, GPT-2 embeds text tokens in the vocabulary into representation spaces with dimensions of 768, 1024, and 1280. The article compulsorily aligns the time series marker e with the text marker tp. For example, although TS-embedding may lack corresponding textual descriptions, it can be closer to the description of the example value, shape, frequency, etc. Through this form of alignment, TS tokens may gain the ability to represent rich information such as small, large, rising, falling, stable, and volatile time series. However, in actual situations, because supervision labels or real data cannot be provided as a benchmark, the results of the above text sequence alignment are likely not to be fully consistent with reality. For example, the embedding corresponding to a subsequence with an upward trend is likely to be very similar to the embedding of a sequence with a downward trend. In order to better match TS-embedding and text token, the article designs the following contrast loss function:
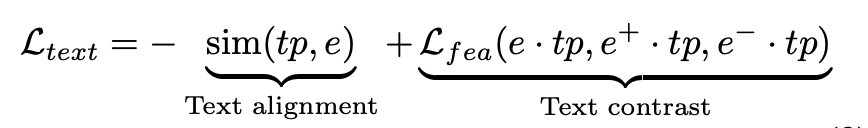 First, by constraining the similarity of vectors (maximizing the cosine similarity between TS-embedding and text embedding), that is, the text alignment part, secondly, using the text prototype as the coordinate axis to map the TS embedding to the corresponding position, thereby ensuring similar Instances are represented similarly in text axes. The modeling method of text prototype tp is achieved through the feature-level contrastive learning introduced in the previous section.
First, by constraining the similarity of vectors (maximizing the cosine similarity between TS-embedding and text embedding), that is, the text alignment part, secondly, using the text prototype as the coordinate axis to map the TS embedding to the corresponding position, thereby ensuring similar Instances are represented similarly in text axes. The modeling method of text prototype tp is achieved through the feature-level contrastive learning introduced in the previous section.
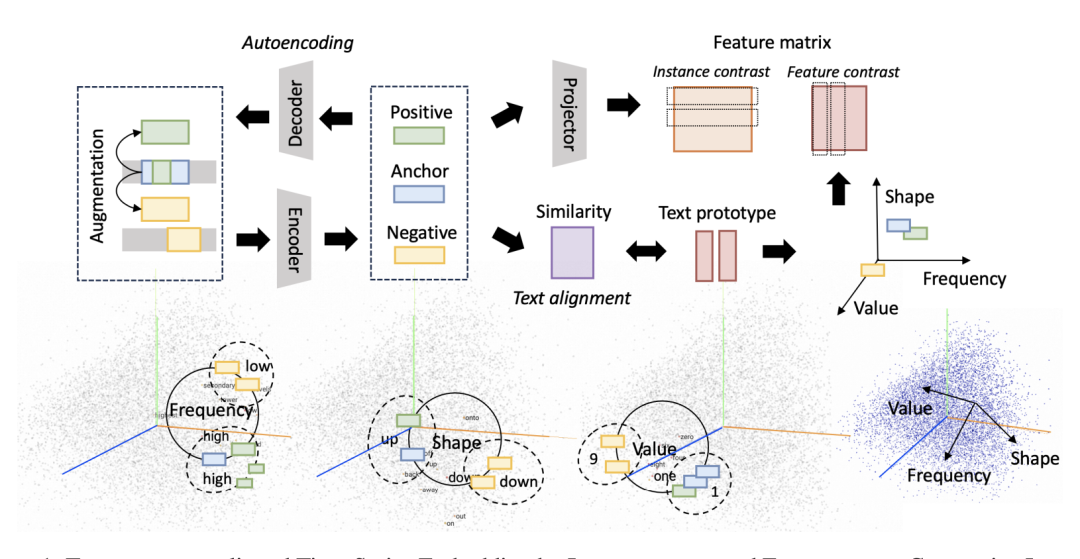
Through the above process, the article constructs an embedded representation that the language model can understand to describe the time series (TS), but the language model still needs to be told how to perform the next time series task. At present, prompt engineering and COT thinking chain are intuitive and easy to understand, and can guide the model to obtain better results. However, these methods require coherent contextual semantics. TS-embedding does not have such special effects and is more like a pattern sequence. Therefore, this article further trains soft prompts for time series data, so that the language model can recognize the patterns of different sequences, thereby realizing time series tasks. These soft prompts are task-specific embeddings that can be randomly initialized from a uniform distribution, or obtain initial values from text embeddings of downstream task labels, obtain initial values from the most common words in the vocabulary, etc., to obtain the objective function of the prompt as follows:
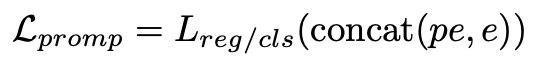
The article mentioned that supervised fine-tuning methods can effectively improve the accuracy of downstream TS tasks. However, considering the high cost of training and the inability to guarantee that the fine-tuned language model can effectively understand the semantic information in TS-embedding, the article gave up supervised fine-tuning and adopted In order to learn how to train soft prompt, the article also proves that trained soft prompt can achieve similar effects as supervised fine-tuning. The specific training process of the method proposed in this article is as follows:

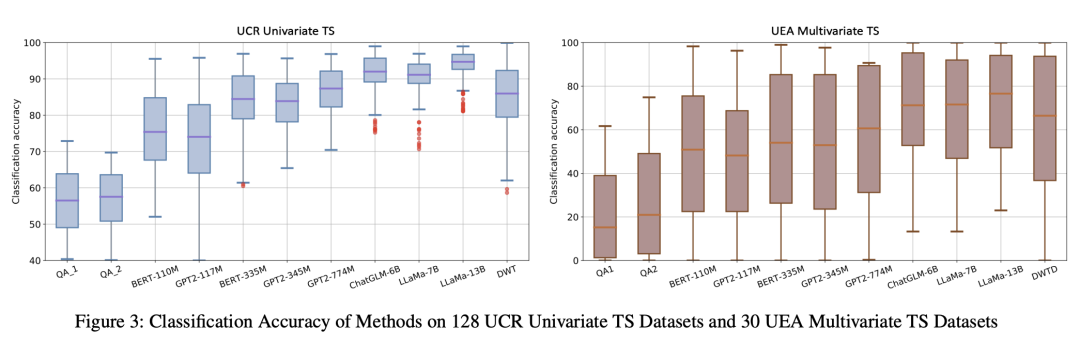
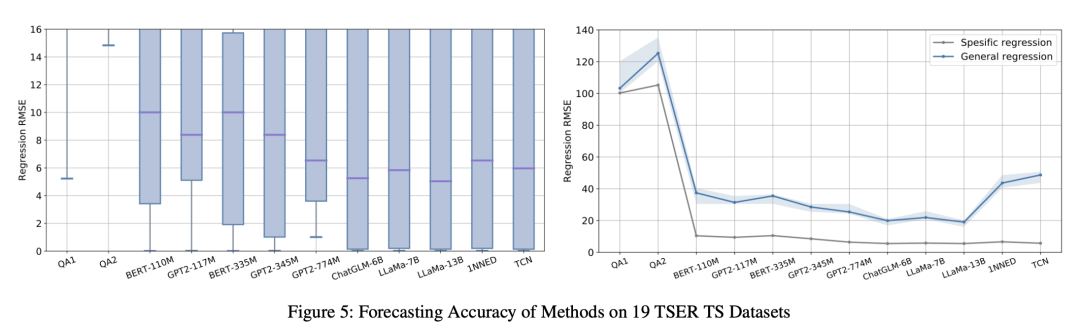
In the experimental part, by using TEST, different language models can achieve performance comparable to common baseline models on time series classification and prediction tasks. The experiment in this article found that using a larger model will obtain more accurate results. The author believes that the essential reason for this phenomenon is related to the size of the language model pre-training data set. The more data sets used in pre-training, the more accurate the prototype selection and prompts. The design is no longer so important. In order to explore the reasons, the author will also conduct more experiments in the future to explore the deep correlation between the corpus and time series.
Recommended reading:
My 2022 Internet School Recruitment Sharing
A brief discussion on the difference between algorithm positions and development positions
Internet school recruitment R&D salary summary
Public account: AI snail car
Stay humble, stay disciplined, and keep improving

Send [Snail] to get a copy of "Hand-in-Hand AI Project" (written by AI Snail)
Send [1222] to get a good leetcode test note
Send [Four Classic Books on AI] to get four classic AI e-books