Article directory
- A quick overview of the knowledge outline of this article
- 0.Preface
- 1 Introduction
- 2. MySQL lock types
- 3. Lock granularity
- 4. Lock usage scenarios and examples
- 5. Lock performance optimization and precautions
- 6. MySQL locking mechanism and implementation details
- 7. Lock tuning and troubleshooting
- 8. Reference documentation
- MySQL lock

A quick overview of the knowledge outline of this article
0.Preface
Background: Recently, a classmate reported that he was asked about locks in the database during the interview. He probably knew something about it, but his answers were scattered and unsystematic, and he was confused by the interviewer's direct question. However, in the end, he passed the interview, which shows that this student also has two brushes, but they are scattered. So today I will take the time to summarize the common lock classifications, lock granularity and principles, and usage scenarios in MySQL.
Locks in the database are mechanisms used to control concurrent access to the same data by multiple transactions. In database concurrency control, locks are an important technology to ensure data consistency and concurrency. It can prevent data inconsistencies caused by multiple transactions modifying the same data at the same time. Locks in the MySQL database can be divided into shared locks (S locks) and exclusive locks (X locks). MySQL also supports multi-granularity locks, including table-level locks (table locks and metadata locks) and row-level locks (row locks). and ProKeyLock). In this blog, we will introduce in detail the various locks and their characteristics in the MySQL database, and how these locks are used in practical applications.
1 Introduction
- The concept and function of locks Locks
are a concurrency control mechanism used to ensure the order of access to shared resources and the consistency of data by multiple transactions or threads. The function of the lock is to prevent multiple transactions or threads from accessing and modifying shared resources at the same time, and to avoid data inconsistencies and race conditions.
The following are the main concepts and functions of locks:
-
Concurrency control: Locks are used to control the order of concurrent access to shared resources, ensure the serial execution of transactions or threads, and avoid data conflicts and inconsistencies caused by concurrent access.
-
Data consistency: Locks are used to ensure that the read and write operations of multiple transactions on shared resources are serial to avoid inconsistent reading and writing.
-
Mutual exclusivity: Locks are used to achieve mutually exclusive access to resources. Only one transaction or thread can obtain the lock and modify the resources at the same time.
-
Blocking and waiting: When a transaction or thread acquires a lock, other transactions or threads need to wait until the lock is released before they can continue execution.
-
Deadlock avoidance: The correct use of locks can avoid the occurrence of deadlock. Deadlock refers to a situation where multiple transactions or threads are waiting for each other's resources and cannot continue to execute.
-
Concurrency performance: Reasonable use of locks can improve concurrency performance, allow multiple transactions or threads to read shared resources at the same time, and reduce waiting and blocking time.
Locks are an important concurrency control mechanism used to ensure data consistency, avoid race conditions, prevent deadlocks, and improve the concurrency performance of the system. In a multi-threaded and multi-transaction environment, the correct use and management of locks is crucial to the stability and reliability of the system.
2. MySQL lock types
- Shared Lock
- Exclusive Lock
- Row-Level Lock
- Table-Level Lock
- Internal Lock
- External Lock

Detailed explanation of each lock type:
-
Shared Lock:
- A shared lock, also known as a read lock, allows multiple transactions to read the same data at the same time, but does not allow other transactions to write to the data.
- A shared lock is a lock on a shared resource. It does not block other transactions from acquiring shared locks, but it does block other transactions from acquiring exclusive locks.
- The purpose of shared locks is to improve concurrency performance. Multiple transactions can read the same data at the same time, improving reading efficiency.
-
Exclusive Lock:
- An exclusive lock, also known as a write lock, does not allow other transactions to read or write the same data at the same time.
- An exclusive lock is an exclusive resource lock that blocks other transactions from acquiring shared locks or exclusive locks.
- The purpose of the exclusive lock is to protect the consistency of the data. Only the transaction that acquires the exclusive lock can modify the data.
-
Row-Level Lock:
- Row-level locks lock data at the row level, locking only the rows that need to be accessed, not the entire table.
- Row-level locks can provide more fine-grained concurrency control, and multiple transactions can read and write different rows in the table at the same time.
- Row-level locks have smaller granularity than table-level locks, which can reduce lock conflicts and improve concurrency performance.
-
Table-Level Lock:
- Table-level locks lock data at the table level and lock the entire table.
- Table-level locks are the coarsest-grained locks. Only one transaction can read and write the entire table.
- Table-level locks have poor concurrency performance and can easily lead to lock conflicts and blocking.
-
Internal Lock:
- An internal lock is a type of lock used internally by MySQL to protect internal data structures and resources.
- Internal locks are invisible to users and are automatically managed and used by MySQL.
- The purpose of the internal lock is to protect the stability and correctness of the system.
-
External Lock:
- An external lock is a type of lock that is explicitly set and managed by the user to protect user-defined resources.
- External locks require user programming to implement and control. Different programming languages and frameworks have different external lock mechanisms.
- External locks need to be used with caution to avoid deadlocks and performance issues.
3. Lock granularity

- Comparison and selection of other lock granularities
Different database management systems may support different lock granularities to adapt to different concurrency scenarios and requirements. The following are several common lock granularities and their comparison and selection:
-
Row-level locks: Lock individual row records in a database table. Row-level locks have the smallest granularity and can support maximum concurrency, but introduce more overhead and race conditions. Suitable for high-concurrency read and write operations.
-
Table-level lock: Lock the entire database table. Table-level locks have the largest granularity and are applicable to operations that read and modify the entire table. However, table-level locks can result in higher lock conflicts and lower concurrency performance.
-
Page lock: Lock the entire data page in the database table. The granularity of page locks is between row-level locks and table-level locks, and is suitable for read and write operations on a batch of row records. It can reduce the probability of lock conflicts and improve concurrency performance.
-
In-page lock: Locks a range in one or more data pages in a database table. In-page locking is a special lock granularity that can lock part of the data page, reduce lock conflicts and competition conditions, and improve concurrency performance.
-
Record lock: Lock a record in the database table. A record lock is a special row-level lock used to protect read and write operations for a specific record. Suitable for frequent read and write operations on a single record.
Choosing the appropriate lock granularity depends on the specific application scenario and requirements. In general, smaller lock granularity improves concurrency performance but brings more overhead and management complexity. Larger lock granularity can reduce lock conflicts and race conditions, but concurrency performance may be reduced. Therefore, when designing and implementing concurrency control, it is necessary to comprehensively consider and evaluate the advantages and disadvantages of various lock granularities based on the actual situation, and select the most suitable lock granularity.
4. Lock usage scenarios and examples
- Concurrent read and write conflicts
- Database deadlock
- Lock timeout and deadlock detection
There are many usage scenarios for locks in databases. Here are some common examples:
-
Concurrent read and write conflicts: When multiple transactions read and modify the same data at the same time, concurrent read and write conflicts may occur. In order to ensure the consistency and integrity of data, locks can be used to control access to data. For example, in the case of row-level locks, transaction A will acquire a row-level lock when modifying a row record. When other transactions need to read or modify the row record, they will be blocked until transaction A releases the lock.
-
Database deadlock: Database deadlock may occur when there are circularly dependent lock requests between multiple transactions. In order to avoid the occurrence of deadlock, the deadlock detection mechanism and deadlock timeout mechanism can be used. For example, when a deadlock is detected, you can choose to roll back one or more of the transactions to relieve the deadlock.
-
Lock timeout and deadlock detection: In order to avoid long lock waits and deadlocks, you can set the lock timeout and implement a deadlock detection mechanism. For example, if a transaction exceeds the set lock timeout during the process of acquiring a lock, you can choose to roll back the transaction to prevent long lock waiting. In addition, potential deadlock problems can be discovered and resolved in a timely manner by monitoring and detecting lock requests and waiting relationships.
These scenarios and examples are just some of the use cases for locking in a database, and specific usage scenarios will vary based on the characteristics of the application and database management system. In the process of using locks, the type, granularity, and strategy of locks need to be reasonably selected and configured based on specific business needs and performance requirements.
5. Lock performance optimization and precautions
Reducing lock conflicts, improving concurrency performance, using appropriate lock granularity, avoiding deadlocks, and avoiding long transactions are some of the aspects that need to be considered when using locks:
-
Reduce lock conflicts: Lock conflicts will increase the waiting time of transactions and reduce concurrency performance. In order to reduce lock conflicts, the following strategies can be adopted:
- Minimize the scope of transactions: only use transactions where necessary to reduce the time the transaction holds locks.
- Use optimistic locking: Avoid using locks directly to protect concurrent access to data by comparing version numbers or timestamps when updating data.
- Use read-write locks: For scenarios with more reading and less writing, read-write locks can be used to improve concurrency performance.
-
Improve concurrency performance: When using locks, you need to consider concurrency performance issues. Some strategies to improve concurrency performance include:
- Use fine-grained locks: Divide data into smaller units. Using fine-grained locks can reduce lock conflicts and improve concurrency performance.
- Selection of concurrency control algorithm: When using locks, you can choose a concurrency control algorithm suitable for specific application scenarios and data access patterns, such as optimistic locks, pessimistic locks, read-write locks, etc.
-
Use appropriate lock granularity: Lock granularity refers to the unit of locked data. Choosing the appropriate lock granularity is very important to improve concurrency performance. If the locking granularity is too large, the frequency of lock conflicts may increase; if the locking granularity is too small, the lock overhead may increase. Therefore, it is necessary to choose the appropriate lock granularity according to the specific scenario.
-
Avoid deadlock: Deadlock refers to a situation where multiple transactions are waiting for each other's resources, causing the process to be unable to continue execution. In order to avoid deadlock, the following measures can be taken:
- Orderly allocation of resources: When a transaction obtains multiple resources, they obtain them in a unified order to avoid circular dependencies.
- Deadlock detection and release: Implement the deadlock detection mechanism. When a deadlock is found, select an appropriate strategy to release the deadlock.
- Limit the holding time of transactions: Reduce the time that transactions hold locks and reduce the probability of deadlock.
-
Avoid long transactions: Long transactions may occupy lock resources for too long, causing other transactions to wait longer and reducing concurrency performance. In order to avoid the occurrence of long transactions, the following measures can be taken:
- Minimize the scope of transactions: only use transactions where necessary to reduce the time the transaction holds locks.
- Avoid long query operations: Long query operations may occupy lock resources, causing other transactions to wait longer.
In actual applications, the type, granularity, and strategy of locks should be reasonably selected and configured based on specific business needs and performance requirements to improve concurrency performance and avoid related problems.
6. MySQL locking mechanism and implementation details
Lock storage and management, lock contention and scheduling, and lock implementation principles are some aspects that need to be understood when actually using locks.
1. Lock storage and management
In database or concurrent programming, locks are usually stored and managed by lock tables, lock queues, or lock managers. The lock table is used to record the status and holder information of the lock. The lock queue is used to store transactions or threads waiting to acquire locks. The lock manager is responsible for managing the acquisition and release of locks.
2. Lock competition and scheduling
In a concurrent environment, multiple transactions or threads may request to acquire locks on the same resource at the same time, which may lead to lock contention. In order to solve the lock competition problem, lock scheduling is required. Lock scheduling can use different strategies, such as fair scheduling and unfair scheduling. Fair scheduling will acquire locks in the order in which they are requested, while unfair scheduling will allow subsequent requests to acquire locks directly, which may cause previous requests to wait longer.
3. Implementation principle of lock
The implementation principles of locks can be divided into two types: pessimistic locking and optimistic locking. Pessimistic locking is a conservative strategy. It believes that concurrent access will cause conflicts, so the lock will be acquired before accessing the shared resource. The implementation of pessimistic locks usually uses mutex locks or spin locks to achieve concurrency control by locking and unlocking resources. Optimistic locking believes that concurrent access will not conflict. It will not lock directly when updating resources. Instead, it will check the version number or timestamp of the resource when updating. If a conflict is detected, it will roll back or retry.
7. Lock tuning and troubleshooting
In MySQL, lock tuning and fault handling are also very important. The following are examples of lock waits and timeouts, deadlock handling and recovery, and lock monitoring and analysis tools for MySQL:
1. Lock waiting and timeout:
- In MySQL, the default lock wait time is 50 seconds. If a thread cannot obtain the lock within this time, MySQL will automatically interrupt the query and return an error message. This waiting time can be adjusted through configuration files or dynamic parameters to adapt to different needs.
2. Deadlock handling and recovery:
- MySQL provides a deadlock detection mechanism. When a deadlock occurs, it will automatically detect and select a transaction to roll back, thereby breaking the deadlock cycle. Transactions that are rolled back can be retried and given the opportunity to reacquire the required locks.
- In addition, MySQL also supports manual detection of deadlocks and provides corresponding statements and tools, such as
SHOW ENGINE INNODB STATUScommands and InnoDB Monitor.
3. Lock monitoring and analysis tools:
- MySQL provides a variety of monitoring and analysis tools to help detect lock-related issues, such as InnoDB Lock Monitor and Performance Schema.
- InnoDB Lock Monitor can analyze the lock situation by viewing the lock information of the InnoDB engine, including lock waiters, holders, and waiting time.
- Performance Schema is a MySQL performance monitoring tool that can provide a wealth of lock-related performance indicators and statistical information for analyzing lock usage and performance bottlenecks.
MySQL helps tune and handle lock-related issues and improve the concurrency performance and stability of the system by providing lock waiting and timeout mechanisms, deadlock handling and recovery mechanisms, as well as lock monitoring and analysis tools.
8. Reference documentation
-
MySQL lock mechanism: https://dev.mysql.com/doc/refman/8.0/en/innodb-locking.htmlMySQL introduces MySQL lock types, lock usage rules and lock tuning.
-
MySQL deadlock handling: https://dev.mysql.com/doc/refman/8.0/en/innodb-deadlocks.html
-
InnoDB Lock Monitor:https://dev.mysql.com/doc/refman/8.0/en/innodb-information-schema-lock-monitor.html
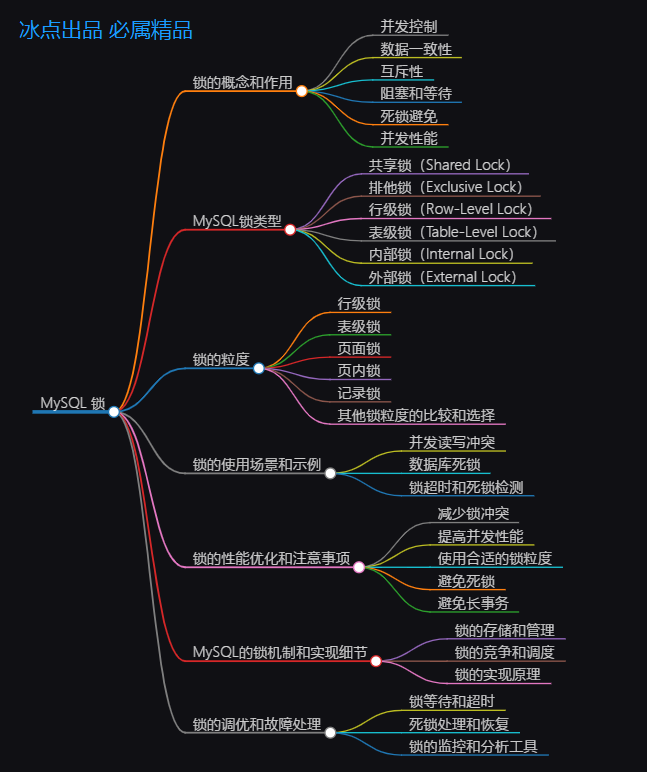
Knowledge map of this article
MySQL lock
The concept and function of lock
- Concurrency control
- data consistency
- mutual exclusivity
- Block and wait
- Deadlock avoidance
- Concurrency performance
MySQL lock type
- Shared Lock
- Exclusive Lock
- Row-Level Lock
- Table-Level Lock
- Internal Lock
- External Lock
Lock granularity
- row level lock
- table level lock
- page lock
- Page lock
- record lock
- Comparison and selection of other lock granularities
Lock usage scenarios and examples
- Concurrent read and write conflicts
- Database deadlock
- Lock timeout and deadlock detection
Lock performance optimization and precautions
- Reduce lock conflicts
- Improve concurrency performance
- Use appropriate lock granularity
- avoid deadlock
- Avoid long transactions
MySQL lock mechanism and implementation details
- Lock storage and management
- Lock contention and scheduling
- The implementation principle of lock
Lock tuning and troubleshooting
- Lock waits and timeouts
- Deadlock handling and recovery
- Lock monitoring and analysis tools