Preface
OCR (Optical Character Recongnition) optical character recognition.
Halcon's OCR provides several methods. How should we choose?
- Automatic text reader (find_text)
- Manual text reader (find_text)
- Segment and identify yourself
automatic text reader
You only need to specify a region of characters and then specify some parameters, and it will automatically recognize it! Very standardized process.
read_image (Image, 'numbers_scale')
* 创建模型,注意这里自动文本阅读器,第一个参数使用auto
create_text_model_reader ('auto', 'Document_Rej.omc', TextModel)
* 设置模型参数
set_text_model_param (TextModel, 'min_char_height', 20)
* 根据设置好的模型进行识别
find_text (Image, TextModel, TextResultID)
* 获取字符分割的区域
get_text_object (Characters, TextResultID, 'all_lines')
* 获取分类结果
get_text_result (TextResultID, 'class', Class)
set_text_model_param corresponding to the automatic text reader
set_text_model_param, sets the model parameters for segmentation of character images.
The essence of OCR is to divide each character into a single area and recognize it individually. So segmenting each character is a necessary prelude to recognition.
"min_contrast": The minimum contrast that a character must have between itself and the surrounding background.
"polarity": The contrast relationship between text and background, which can be "dark_on_light" (text is darker than background), "light_on_dark" (text is lighter than background), or "both" (both cases are handled).
"eliminate_border_blobs" (exclude border areas): Whether to exclude areas that are in contact with the image border.
"add_fragments": Whether to add fragments in the text (such as the dot on the 'i') to the split characters.
"separate_touching_chars": Controls how splitting of adjacent characters is handled.
"min_char_height" (minimum character height): The minimum height of the character. "max_char_height" (maximum character height): The maximum height of the character.
"min_char_width" (minimum character width): The minimum width of characters. "max_char_width" (maximum character width): The maximum width of characters.
"min_stroke_width" (minimum stroke width): The minimum stroke width of the character.
"max_stroke_width" (maximum stroke width): The maximum stroke width of a character.
"return_punctuation": Whether to return small punctuation marks close to the baseline of the text line.
"return_separators": Whether to return separators, such as minus sign or equal sign.
"dot_print": Whether the text contains dot printing characters.
"dot_print_tight_char_spacing" (whether dot printing characters have smaller character spacing).
"dot_print_min_char_gap" (minimum character spacing for dot printing characters).
"dot_print_max_dot_gap" (maximum dot spacing for dot printing characters).
"text_line_structure": Defines the structure of text lines to simplify text searches.
In the automatic text reader, set_text_model_param has these parameters that can help us perform more precise segmentation. In fact, most of the values default are auto, so when the picture is relatively
clear, you generally don’t need to set any parameters when using the automatic text reader. Achieve better recognition results.
Finally, the automatic text reader can get the recognition result through get_text_result, and the recognition result will be placed in a string array!
Manual text reader
In automatic text reading we use:
create_text_model_reader ('auto', 'Document_Rej.omc', TextModel)
Manual text reader we use:
create_text_model_reader ('manual', [], TextModel)
The difference is that the first parameter is changed to 'manual' to indicate manual, and the second parameter is different from the automatic text reader in that the OCR classifier is not passed, but an empty array. This is because manual text readers only complete the segmentation step and do not include the recognition process.
Set_text_model_param corresponding to manual text reader
"manual_char_height" (character height): the height of the character.
"manual_char_width" (character width): The width of the character.
"manual_stroke_width" (stroke width): The stroke width of the character.
"manual_base_line_tolerance" (Baseline Tolerance): Maximum deviation from the baseline of a character.
"manual_polarity": The contrast relationship between text and background.
"manual_uppercase_only" (uppercase characters only): Whether the text contains only uppercase characters or numbers.
"manual_is_dotprint" (dot print): whether the text is dot print.
"manual_is_imprinted" (imprinted): Whether the text is affected by polarity changes caused by reflections.
"manual_eliminate_horizontal_lines" (exclude horizontal lines): Whether to exclude longer horizontal structures close to the text.
"manual_max_line_num": The maximum number of lines of text to find.
"manual_return_punctuation" (return punctuation): whether to return punctuation.
"manual_return_separators": whether to return separators.
"manual_add_fragments": whether to add fragments.
"manual_fragment_size_min" (minimum area of fragment): The minimum area of the fragment to be added.
"manual_text_line_structure" (text line structure): Defines the structure of text lines to simplify text searches.
It can be seen that the parameters set by set_text_model_param corresponding to the manual text reader all start with 'manual_'. (Using the corresponding parameters of the automatic text reader will report an error!)
Split logic for "auto" and "manual" modes
So, what are the differences in the logic of their segmentation between the different modes "auto" and "manual"?
-
Automatic mode (“auto” mode):
- The "auto" mode performs text segmentation based on the character's image characteristics and background contrast. It uses an adaptive method to detect boundaries between characters and segment text into characters.
- In "auto" mode, you need to set some parameters, such as minimum contrast ("min_contrast"), minimum character height ("min_char_height"), maximum character height ("max_char_height"), minimum character width ("min_char_width"), character Maximum width ("max_char_width"), minimum stroke width ("min_stroke_width"), maximum stroke width ("max_stroke_width"), etc., to help the segmentation algorithm determine the boundaries of the characters.
- "auto" mode is generally suitable for more general text segmentation tasks where the character size and appearance of the text may vary. It is useful for applications that do not require precise control of character properties.
-
Manual mode (“manual” mode):
- "manual" mode allows users to manually set character attributes, such as character height ("manual_char_height"), character width ("manual_char_width"), stroke width ("manual_stroke_width"), etc. These parameters will be used for text segmentation.
- In "manual" mode, the user needs to describe the characteristics of the text to be segmented in more detail. This approach is often used for segmentation tasks of specific characters or special text types, where the properties of the characters are known and relatively consistent.
- "manual" mode can be used to handle specific printing styles, such as dotted characters ("dot_print") or text with a specific stroke width ("manual_stroke_width").
In summary, the "auto" mode is a more adaptive text segmentation method and is suitable for general text segmentation tasks, while the "manual" mode allows users to more precisely define character attributes and is suitable for segmentation tasks of special characters or text types. . Which mode to choose depends on your specific application needs and the characteristics of the text sample.
Generally, if the background is complex and difficult to distinguish, such as laser-engraved characters, it is more suitable to use manual mode to distinguish!
Recognition process for manual text readers
So, how to complete the recognition after manual text reader segmentation ? After the segmentation is completed, the work of the manual text reader is actually completed,
and the recognition process has nothing to do with the manual text reader.
In automatic text reading, we pass in the type of classifier when we create it.
create_text_model_reader ('auto', 'Document_Rej.omc', TextModel)
Because the automatic text reader has helped us complete the recognition process, now we have to complete the recognition project separately:
First, I need to read the classifier:
read_ocr_class_mlp ('Industrial_0-9A-Z_Rej.omc', OcrHandle)
halcon provides us with many types of trained classifiers (this is the file ending with .omc). Choosing the appropriate classifier can improve our recognition rate.
How to choose an appropriate classifier will be discussed later.
Give the code to complete segmentation and recognition:
*//-------------分割部分
create_text_model_reader ('manual', [], TextModel)
*//参数设置
set_text_model_param (TextModel, 'manual_polarity', 'light_on_dark')
set_text_model_param (TextModel, 'manual_char_width', 104)
set_text_model_param (TextModel, 'manual_char_height', 105)
set_text_model_param (TextModel, 'manual_stroke_width', 21)
set_text_model_param (TextModel, 'manual_return_punctuation', 'false')
set_text_model_param (TextModel, 'manual_uppercase_only', 'true')
set_text_model_param (TextModel, 'manual_fragment_size_min', 100)
set_text_model_param (TextModel, 'manual_eliminate_border_blobs', 'true')
set_text_model_param (TextModel, 'manual_base_line_tolerance', 0.2)
set_text_model_param (TextModel, 'manual_max_line_num', 1)
*//-----------------识别部分
read_ocr_class_mlp ('Industrial_0-9A-Z_Rej.omc', OcrHandle)
//* 根据设置好的模型进行识别
find_text (Image, TextModel, TextResult)
//* 获取字符分割的区域。 ps:这里和自动的不同,使用的是 manual_all_lines 不是 all_lines
get_text_object (Characters, TextResult, 'manual_all_lines')
//* 获取结果
get_text_result (TextResult, 'manual_num_lines', ResultValue)
dev_display (Characters)
do_ocr_multi_class_mlp (Characters, TmpInverted, OcrHandle, SymbolNames, Confidences)
get_text_result result acquisition
Note that get_text_objectthe difference between get_text_objectis to obtain the segmented area and get_text_resultto obtain a certain result.
In the automatic text reader, we also use get_text_resultthe directly obtained classification results:
* 获取分类结果
get_text_result (TextResultID, 'class', Class)
However, if it is a manual text reader and you use get_text_result (TextResultID, 'class', Class), an error will be reported!
This is because the manual text reader obtains segmentation results rather than classification results. For details, we can look at the detailed introduction of get_text_result.
get_text_resultIs an operator used to query text segmentation results. It controls the results by querying find_textthe returned
TextResultIDin ResultName. ResultNameThe possible parameter values of depend on
find_textthe text model used in the text segmentation process of .
When Mode = 'auto' and Mode = 'manual', get_text_result obtains different results. (You don’t need to read the following paragraph, just know the reason!)
Possible parameter values in a text model with Mode = 'auto' are listed below first, followed by those in a text model with Mode = 'manual'.
The following results can be queried:
Text segmentation results for the text model with Mode = 'auto':
For each polarity, lines of text are sorted independently from top to bottom and left to right. Characters within a text line are ordered from left to right.
- 'num_lines': Number of lines found.
- 'num_classes': The optimal number of classes to store for each character. Depending on the number of classes of the classifier used, this value may be smaller than the value set in the text model, see
set_text_model_param.- 'class': Classification results of all segmented characters, using the OCR classifier in the corresponding text model. Note that if the classifier is trained with the rejection class, the
get_text_resultsecond highest result for the character with the second highest confidence in the rejection class will be returned.- ['class', n] (category n): Similar to 'class', but returns the (n+1)th high-confidence class. For example, ['class', 0] returns the highest confidence class for each character. Additionally, unlike 'class', a rejection class can be returned if the classifier contained in the corresponding text model was trained using the rejection class.
- ['class_line', LineIndex] (inline category): Specifies the classification result of characters in the text line specified by LineIndex, using the OCR classifier in the corresponding text model. For example, ['class_line', 0]
returns the character class within the first line. Note that if the classifier is trained with the rejection class, theget_text_result
second highest result for the character with the second highest confidence in the rejection class will be returned.- ['class_line', LineIndex, n] (inline category n): Similar to ['class_line', LineIndex], but returns the (n+1)th high-confidence category. For example, ['class_line', LineIndex, 0] returns
the highest confidence class for each character in the line of text specified by LineIndex. Additionally, unlike ['class_line', LineIndex]
, a rejection class can be returned if the classifier included in the corresponding text model was trained using the rejection class.- ['class_element', Index] (Character category): The classification result of the character at position Index, using the OCR classifier in the corresponding text model. For example ['class_element', 0] returns the 'num_classes' best classes of the first character (sorted by confidence).
- 'confidence': Returns the confidence of the class of all split characters, see 'class'.
- ['confidence', n] (confidence n): Returns the confidence of the (n+1)th highest confidence category, see ['class', n].
- ['confidence_line', LineIndex] (inline confidence): Returns the confidence of the class of all characters specified by LineIndex, see ['class_line', LineIndex].
- ['confidence_line', LineIndex, n] (in-line confidence n): Returns the confidence of the (n+1)th highest confidence category for all characters in the text line specified by LineIndex, see ['class_line', LineIndex , n].
- ['confidence_element', Index] (character confidence): Returns the confidence corresponding to the class of the character at position Index, see ['class_element', Index].
- 'polarity': Returns the polarity of all split characters.
- ['polarity_line', LineIndex] (inline polarity): Returns the polarity of the characters within the text line specified by LineIndex. For example, ['polarity_line', 0] returns the polarity within the first line.
- ['polarity_element', Index] (character polarity): Returns the polarity of the character at position Index. For example ['polarity_char', 0] returns the polarity of the first character.
Text segmentation results for the text model with Mode = 'manual':
- 'manual_num_lines': Number of lines found.
- If 'manual_persistence' is activated for the text model in which the TextResultID was created, the following additional values can be queried:
- 'manual_thresholds': Thresholds used for segmentation.
Note that these parameters allow you to query various aspects of text segmentation results, including character classification, confidence, polarity, etc. Based on your application needs, you can choose to query the results that suit you.
That is, in manual mode, get_text_objectonly two results can be obtained:
'manual_num_lines' (number of lines): the number of lines found.
'manual_thresholds': Thresholds used for segmentation.
Therefore, in manual mode, it is impossible to obtain the classification results!
do_ocr_multi_class_mlp acquisition of classification results
To really get the classification results, I need to pass the function:
do_ocr_multi_class_mlp (Characters, img, OcrHandle, SymbolNames, Confidences)
Parameter introduction:
1 Characters, is the segmented area obtained through get_text_object,
2 imgis the recognized picture.
3 OcrHandleis the handle returned when reading the classifier provided by halcon.
4 SymbolNamesis the classification result
and 5 Confidencesis the confidence corresponding to each character!
One thing to note here is that imgthis picture must be 白底黑字a picture of . You may say that I have not set the polarity!
set_text_model_param (TextModel, 'manual_polarity', 'light_on_dark') has told him that it is white text on a black background!
No, because this is a segmentation parameter and has nothing to do with recognition, recognition must be 白底黑字!
If your image is 'light_on_dark', please use invert_image (Image, TmpInverted) to invert the image and then pass it to
do_ocr_multi_class_mlp for recognition!
Stage summary :
Through these parameters, it is found that only one parameter comes from the manual text reader, which is Characters: segmentation area.
So recognition and segmentation are completely separate! We can also use other methods, such as blob analysis, image filtering, morphology and other operations to obtain the segmented areas of the characters

and then identify them directly!
Another recognition function do_ocr_word_mlp
Interpretation of function parameters:
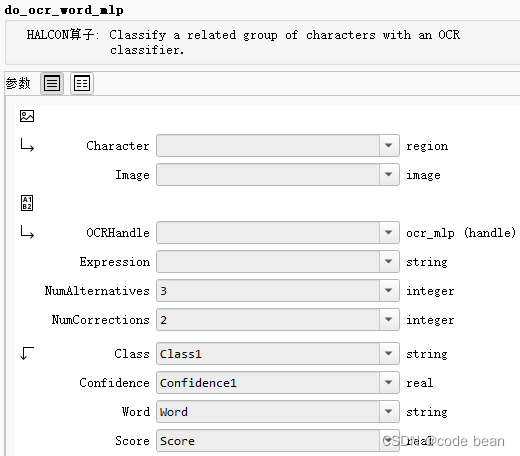
Parameter introduction:
1 Characters, is the segmented area obtained through get_text_object,
2 Imageis the recognized picture.
3 OcrHandleis the handle returned when reading the classifier provided by halcon.
4 ExpressionDefault matching content expression, such as: using regular expressions
5 NumAlternativesParameters are used to specify the number of alternative categories for each character to be considered when performing OCR. Specifically, it determines do_ocr_word_mlpthe number of alternative categories for each character when performing word correction in the operation.
When do_ocr_word_mlp it cannot generate a word that matches a given expression from the original classification results, it considers alternative categories for correction. Alternative categories are alternative character classification results ranked by confidence.
NumAlternativesParameter controls how many alternative categories are considered. More specifically, for each character, DoOcrWordMlp will consider the top alternative NumAlternativescategories. This means that it will try to correct the classification result of each character into one of these alternative categories to generate Expressionwords that match the expression ( ).
The 6 NumCorrectionsparameter is used to specify the maximum number of character corrections allowed when performing OCR. Specifically, it determines how many characters are allowed to be corrected in a DoOcrWordMlp operation if the generated word does not match the given expression. NumCorrectionsParameter limits the maximum number of corrections allowed during the correction process. If NumCorrectionsset to 2, a maximum of two characters are allowed to be corrected when correcting a word.
7 Classis the classification result put into a string array
8 Confidencesis the confidence corresponding to each character!
9 WordString result, not in the form of an array, another display form of the result
9 Scoreis used to measure the similarity between the corrected word and the uncorrected classification result. It is a measurement that indicates the quality of the correction and can help you understand the effectiveness of the correction process.
ScoreThe value range is usually between 0.0 and 1.0, where:
- 0.0 means no correction has been made and the corrected word does not match the uncorrected classification result at all.
- 1.0 means that the corrected word exactly matches the uncorrected classification result without any correction.
ScoreThe calculation method usually considers the following factors: - Number of characters corrected: Correction may decrease as more characters are corrected
Score. - Number of alternative categories discarded: This may also be reduced if multiple alternative categories are discarded during correction to make the word match the expression
Score.
In terms of the number of parameters, it is much more complicated do_ocr_word_mlpthan do_ocr_multi_class_mlp.
Some problems can be seen from the fact that one is called word and the other is called multi_class. do_ocr_word_mlpIs an operator that classifies a set of related characters.
Unlike do_ocr_multi_class_mlp, do_ocr_word_mlpa character group is treated as an entity and a word is generated by concatenating the category names of each character region. This allows limiting the allowed classification results at the text level by specifying expressions that describe the desired words.
Then the key to the entire function lies in the parameters, Expression! Making good use of this parameter can help us improve the accuracy of recognition! For example:
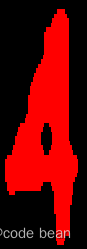
This picture is actually 4, but sometimes it is recognized as A during the recognition process, then Expressionit can play a role!
This is an example that comes with halcon:
* Process Date Text
sort_region (CharactersDate, SortedDate, 'character', 'true', 'row')
* Classify the data string without restriction (for comparison)
do_ocr_word_mlp (SortedDate, ImageOCR, OCRHandle, '.*', 5, 5, Class, Confidence, OriginalDateText, DateScore)
* Classify the data string using a regular expression
do_ocr_word_mlp (SortedDate, ImageOCR, OCRHandle, '^([0-2][0-9]|30|31)/(0[1-9]|10|11|12)/0[0-5]$', 10, 5, Class, Confidence, DateText, DateScore)
I would like to compare the difference between using regular constraints and not using regular constraints!
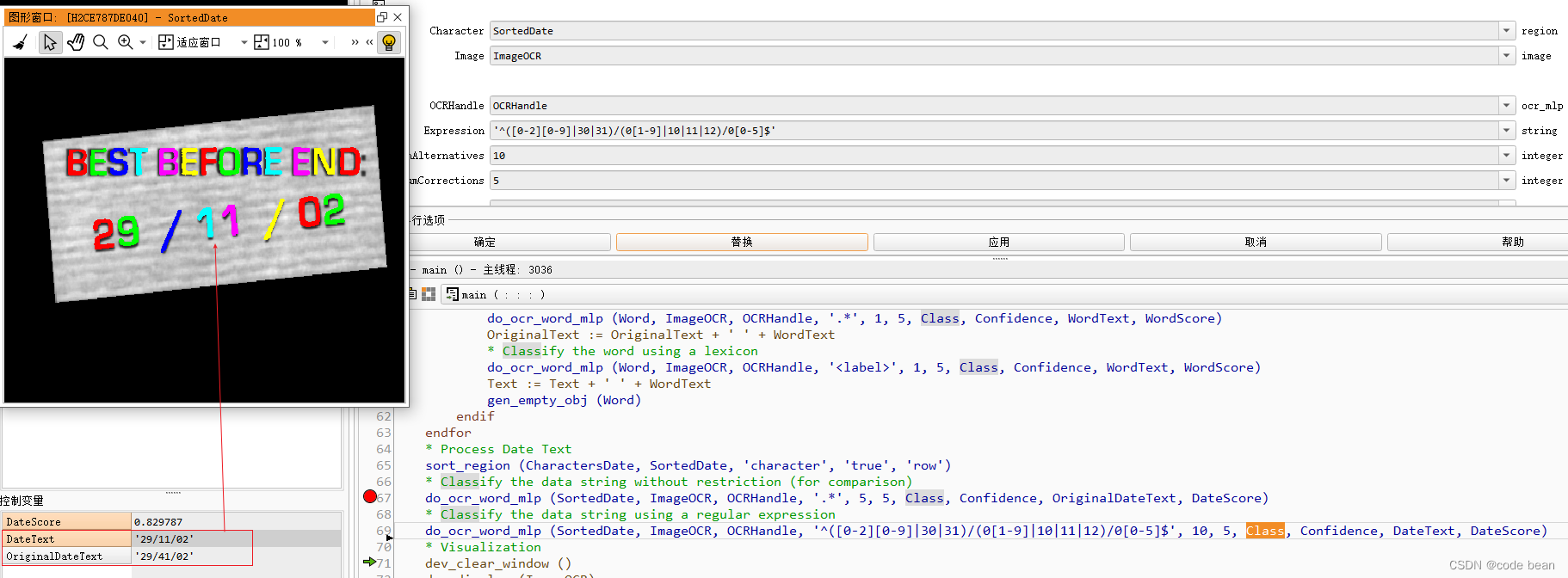
This example shows that if the regular ".*" is used (that is, there is no constraint to match any characters), the original 11 is recognized as 41, and the DataScore score is full score at this time 1.
If you use the regular '^([0-2][0-9]|30|31)/(0[1-9]|10|11|12)/0[0-5]$', the correct result is identified . At this time the DataScore score is 0.829points.
This means that regularization has a certain ability to correct errors.
但是这个是有一个前提的:
The correct result is indeed among the alternatives for recognition. For example, if 1 is not among the alternatives for halcon recognition results, then the regular rule will not correct the error, and the DataScore at this time will be equal to 0, because the regular match The results are inconsistent with the identified results .
Also note:
do_ocr_word_mlp (SortedDate, ImageOCR, OCRHandle, '^([0-2][0-9]|30|31)/(0[1-9]|10|11|12)/0[0-5]$', 10, 5, Class, Confidence, DateText, DateScore)
Class outputs an uncorrected character array, while DateText outputs a regular corrected string.
An example I encountered :

This area was identified 7, and I tried to correct it to 1 through regularization, but it had no effect at all, and the score was always 0.
This means that it 1is not among the alternatives at all! (As a human intuition, 1 should be in the alternative! But it is not in the halcon recognition result. I mistakenly thought that the regular rule was invalid, but in fact it is not in the alternative)
do_ocr_single_class_mlp
do_ocr_multi_class_mlp We have talked about
the comparison between do_ocr_single_class_mlp and do_ocr_multi_class_mlp before
. It is easy to understand:
do_ocr_single_class_mlp recognizes one area at a time (one area corresponds to one character)
do_ocr_multi_class_mlp recognizes multiple areas at one time (one area corresponds to one character)
sort_region (RegionTrans, SortedRegions1, 'first_point', 'true', 'column')
for i := 1 to Number by 1
select_obj (SortedRegions, ObjectSelected, i)
do_ocr_single_class_mlp (ObjectSelected, Image, OCRHandle, 1, Class, Confidence)
* 显示相应的识别内容在区域上方
disp_message (WindowHandle, Class, 'image', MeanRow-10, Column[i-1]-10, 'red', 'true')
endfor
The sorting here is for the identified categories and identified areas to correspond one-to-one in the specified order (such as from left to right).
Sometimes, we may need to process areas one by one (for example, if we need to additionally process each character defect), we can use do_ocr_single_class_mlp.
Here, some students may ask questions, why haven’t I seen the sorting step before? This is the sorting that should be done by automatic and manual readers for us. So, if we
divide it ourselves, we need to complete this sorting ourselves. .
Summary of OCR recognition process
The entire OCR recognition process is:
1. Obtain the trained OCR recognition handle
2. Split the characters into individual areas
3. Call the corresponding method for recognition.
1 Obtain the trained OCR recognition handle
We can create_text_model_reader ('auto', 'Document_Rej.omc', OCRHandle)get it through (this is the way of the automatic reader)
or read it directly through the function read_ocr_class_mlp:read_ocr_class_mlp ('DotPrint_0-9A-Z_NoRej.omc', OCRHandle)
2 Split characters into individual regions
First, by using create_text_model_reader ('manual', [], TextModel)to get a segmentation handle, set the corresponding parameters, and automatically segment the character image.
The second is to segment character images through blob analysis, image filtering, and morphological operations.
Segmentation is actually the key to the entire OCR recognition!
3 Call the corresponding method to identify
Three methods are currently introduced:
- do_ocr_multi_class_mlp
- do_ocr_single_class_mlp
- do_ocr_word_mlp
Summary of usage experience
The advantage of manual text readers and automatic text readers is that the recognition process can be standardized, and we only need to configure some parameters.
However, there will be some restrictions:
1. The picture is required to be relatively clear.
2. The space between letters and letters should be similar, and it is best not to contain some special characters.
 ![Insert picture description here]
![Insert picture description here]
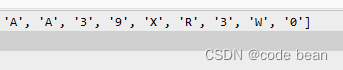
For example, here, 3- is recognized as X. (It’s because the two areas are not separated)
Also, the two A’s here are very close. When processing the image, pay attention to whether the obtained area is divided into two areas.
If the areas are connected together, be careful to adjust the parameters.
My feeling after using it is that I segment the character pictures through blob analysis, image filtering, and morphological operations. Then use
do_ocr_word_mlp that supports regularization for identification, which I would like to call the strongest combination. The universality is still better, the recognition is more accurate, and it is suitable for more demanding recognition needs.
Selection of pre-trained character library
The pre-trained character libraries are .omc files, which can be accessed in the ocr subdirectory of the folder where HALCON is installed. Pretrained fonts are trained using dark characters on light backgrounds. that's why
- do_ocr_multi_class_mlp
- do_ocr_single_class_mlp
- The reason why do_ocr_word_mlp
requires image input must be black text on a white background.
NoRej andRej
All pre-trained OCR fonts are available in two versions. Font names ending in _NoRej have regularization weights but no rejection classes, font names ending in _Rej have regularization weights and rejection classes. Pre-trained OCR fonts provide more meaningful confidence due to regularization. Use rejection-type fonts to distinguish characters from cluttered backgrounds. Fonts with reject classes return ASCII Code 26.
If it appears: the string contains the number "\032" (it can also be displayed as "\0x1A"), it means that the area has been classified as a rejection category, which means that no judgment is made and a judgment is refused.
OCR font nomenclature
- 0-9: OCR font contains numbers 0 to 9.
- AZ: OCR font contains uppercase characters A to Z.
- +: OCR font contains special characters. The list of special characters is slightly different than a single OCR font.
- _NoRej: OCR font has no reject class.
- _Rej: OCR fonts have rejection classes.
Listed below are all pre-trained character libraries of halcon
"Document_A-Z+_Rej.omc",
"Document_NoRej.omc",
"Document_Rej.omc",
"DotPrint_0-9_NoRej.omc",
"DotPrint_0-9_Rej.omc",
"DotPrint_0-9+_NoRej.omc",
"DotPrint_0-9+_Rej.omc",
"DotPrint_0-9A-Z_NoRej.omc",
"DotPrint_0-9A-Z_Rej.omc",
"DotPrint_A-Z+_NoRej.omc",
"DotPrint_A-Z+_Rej.omc",
"DotPrint_NoRej.omc",
"DotPrint_Rej.omc",
"HandWritten_0-9_NoRej.omc",
"HandWritten_0-9_Rej.omc",
"Industrial_0-9_NoRej.omc",
"Industrial_0-9_Rej.omc",
"Industrial_0-9+_NoRej.omc",
"Industrial_0-9+_Rej.omc",
"Industrial_0-9A-Z_NoRej.omc",
"Industrial_0-9A-Z_Rej.omc",
"Industrial_A-Z+_NoRej.omc",
"Industrial_A-Z+_Rej.omc",
"Industrial_NoRej.omc",
"Industrial_Rej.omc",
"OCRA_0-9_NoRej.omc",
"OCRA_0-9_Rej.omc",
"OCRA_0-9A-Z_NoRej.omc",
"OCRA_0-9A-Z_Rej.omc",
"OCRA_A-Z+_NoRej.omc",
"OCRA_A-Z+_Rej.omc",
"OCRA_NoRej.omc",
"OCRA_Rej.omc",
"OCRB_0-9_NoRej.omc",
"OCRB_0-9_Rej.omc",
"OCRB_0-9A-Z_NoRej.omc",
"OCRB_0-9A-Z_Rej.omc",
"OCRB_A-Z+_NoRej.omc",
"OCRB_A-Z+_Rej.omc",
"OCRB_NoRej.omc",
"OCRB_passport_NoRej.omc",
"OCRB_passport_Rej.omc",
"OCRB_Rej.omc",
"Pharma_0-9_NoRej.omc",
"Pharma_0-9_Rej.omc"
Document
'Document' can be used to read characters printed in fonts such as Arial, Courier or Times New Roman. These are typical fonts used for printing documents or letters. Note that the characters I and l for the font Arial cannot be distinguished. This means that l can be mistaken for I and vice versa.
Available special characters: - = + < > . # $ % & ( ) @ * e £ ¥
DotPrint
Some dot printers and inkjet machines print out characters consisting of small dots. It does not contain lowercase characters.
Available special characters: - / . * :

Industrial
'Industrial' can be used to read characters printed in Arial, OCR-B or other sans-serif fonts etc. These fonts are often used for printing labels, for example.
Available special characters: - / + . $ % * e £
Industrial is translated as industrial. I found that this character set is Imore accurate in identifying the characters !
However, it seems that the horizontal bar cannot be recognized. (It may be that I use a library of characters and numbers. If it is a single number library, it may be able to identify "Industrial_0-9+_Rej.omc" because if it is a library of characters and numbers, there is no numbered one. There will be follow- +up Please verify again!)
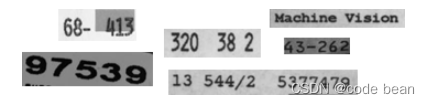
HandWritten
As the name suggests, this is to recognize handwritten characters. Currently, it only supports digital handwriting.

OCR-A
'OCR-A' can be used to read characters printed in the font OCR-A.
Available special characters: - ? ! / {} = + < > . # $ % & ( ) @ * e £ ¥

OCR-B
'OCR-B' can be used to read characters printed in the font OCR-B.
Available special characters: - ? ! / {} = + < > . # $ % & ( ) @ * e £ ¥

Pharma
'Pharma' can be used to read characters printed in fonts such as Arial, OCR-B, and other fonts commonly used in the pharmaceutical industry (see Figure 18.18). This OCR font does not contain lowercase characters.
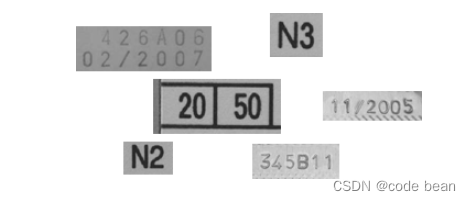
SEMI
'SEMI' can be used to read characters printed in a SEMI font, which consists of characters that are easily distinguishable from each other. It has a limited set of characters, which can be seen in Figure 18.19. This OCR font does not contain lowercase characters.
Available special characters: - .

Universal
'Universal' can be used to read a variety of different characters. This CNN-trained font is based on characters such as 'Document', 'DotPrint', 'SEMI' and 'Industrial'.
Available special characters: - / = + : < > . # $ % & ( ) @ * e £ ¥
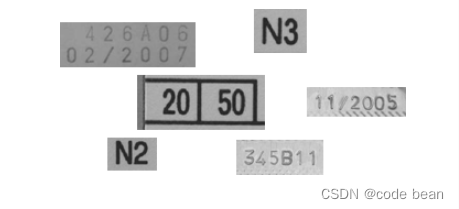
If none of these pre-trained character libraries can solve your existing recognition problems, then you need to train your own character library! Follow us and see you in the next article
Reference article
The selection of pre-training character library mainly refers to Mr.Devin’s article:
https://blog.csdn.net/IntegralforLove/article/details/83756956
Mr.Devin is really a god~~~