Author丨Rédigé par Gabriel Guerin Source丨AI Park

Deep learning models require a lot of data to get good results, and the same goes for object detection models.
To train a YOLOv5 model to automatically detect your favorite toy, you need to take thousands of photos of your toys in different contexts, and for each picture, you need to label the location of the toy in the picture.
This is very time consuming.
This paper proposes a method to automatically generate target detection datasets using image segmentation and stable diffusion.
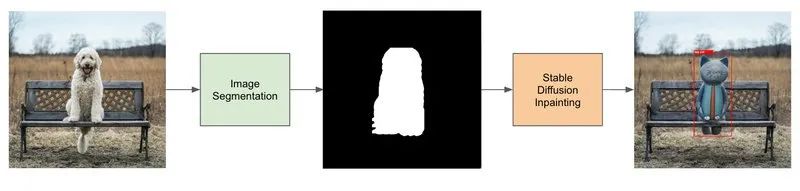
The pipeline to generate the target detection data set contains 4 steps:
Find a dataset that has the same instances as the objects you want to recognize (for example, the dog dataset).
Use image segmentation to generate a dog mask.
Fine-tuning the Stable Diffusion model for image repair.
Use the Stable Diffusion image inpainting model and the generated mask to generate data.
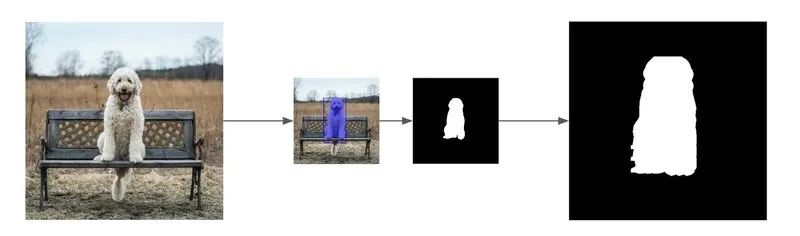
Image segmentation: generate mask image
The Stable Diffusion image repair pipeline requires inputting a prompt, an image and a mask image. This model will only generate a new image from the white pixels in the mask image.
PixelLib is a library that helps us do image segmentation with just a few lines of code. In this example, we will use the PointRend model to detect dogs. The following is the code for image segmentation.
import pixellib
from pixellib.torchbackend.instance import instanceSegmentation
ins = instanceSegmentation()
ins.load_model("pointrend_resnet50.pkl")
target_classes = ins.select_target_classes(dog=True)
results, output = ins.segmentImage(
"dog.jpg",
show_bboxes=True,
segment_target_classes=target_classes,
output_image_name="mask_image.jpg"
)Use pixellib for image segmentation
segmentImageThe function returns a tuple:
results: is a dictionary containing the fields 'boxes', 'class_ids', 'class_names', 'object_counts', 'scores', 'masks', 'extracted_objects'.output: The original image and the mask image are mixed, and ifshow_bboxesset toTrue, there will also be a bounding box.
Generate mask image
The mask we generate only contains white and black pixels. Our mask will be slightly larger than the dog in the original picture, which will give Stable Diffusion enough space to repair. In order to achieve this effect, we translated the mask 10 pixels to the left, right, up, and down respectively.
from PIL import Image
import numpy as np
width, height = 512, 512
image=Image.open("dog.jpg")
# Store the mask of dogs found by the pointrend model
mask_image = np.zeros(image.size)
for idx, mask in enumerate(results["masks"].transpose()):
if results["class_names"][idx] == "dog":
mask_image += mask
# Create a mask image bigger than the original segmented image
mask_image += np.roll(mask_image, 10, axis=[0, 0]) # Translate the mask 10 pixels to the left
mask_image += np.roll(mask_image, -10, axis=[0, 0]) # Translate the mask 10 pixels to the right
mask_image += np.roll(mask_image, 10, axis=[1, 1]) # Translate the mask 10 pixels to the bottom
mask_image += np.roll(mask_image, -10, axis=[1, 1]) # Translate the mask 10 pixels to the top
# Set non black pixels to white pixels
mask_image = np.clip(mask_image, 0, 1).transpose() * 255
# Save the mask image
mask_image = Image.fromarray(np.uint8(mask_image)).resize((width, height))
mask_image.save("mask_image.jpg")Generate a mask for the image from the output of pixellib
Now, we have the original image of the dog and its corresponding mask.
Fine-tuning the Stable Diffusion image repair pipeline
Dreambooth is a technique for fine-tuning Stable Diffusion. We can teach new concepts to the model using very few photos. We are going to use this technique to fine-tune the image inpainting model. The train_dreambooth_inpaint.py script shows how to fine-tune the Stable Diffusion model on your own data set.
Fine-tuning required hardware resources
gradient_checkpointingModels can be fine-tuned using and on a single 24GB GPU mixed_precision. For larger batch_sizeand faster training, a GPU of at least 30GB is required.
Install dependencies
Before running the script, make sure these dependencies are installed:
pip install git+https://github.com/huggingface/diffusers.git
pip install -U -r requirements.txtAnd initialize the acceleration environment:
accelerate configYou need to register as a Hugging Face Hub user. You will also need a token to use these codes. Run the following command to authorize your token:
huggingface-cli loginfine-tuning samples
When running these computationally intensive trainings, hyperparameter fine-tuning is critical. You need to try different parameters on the machine you are running the training on. The parameters I recommend are as follows:
$ accelerate launch train_dreambooth_inpaint.py \
--pretrained_model_name_or_path="runwayml/stable-diffusion-inpainting" \
--instance_data_dir="dog_images" \
--output_dir="stable-diffusion-inpainting-toy-cat" \
--instance_prompt="a photo of a toy cat" \
--resolution=512 \
--train_batch_size=1 \
--learning_rate=5e-6 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--max_train_steps=400 \
--gradient_accumulation_steps=2 \
--gradient_checkpointing \
--train_text_encoderRun the Stable Diffusion image repair pipeline
Stable Diffusion image restoration is a text2image diffusion model that uses an image with a mask and text input to generate a real image. Use https://github.com/huggingface/diffusers to implement this function.
from PIL import Image
from diffusers import StableDiffusionInpaintPipeline
# Image and Mask
image = Image.open("dog.jpg")
mask_image = Image.open("mask_image.jpg")
# Inpainting model
pipe = StableDiffusionInpaintPipeline.from_pretrained(
"stable-diffusion-inpainting-toy-cat",
torch_dtype=torch.float16,
)
image = pipe(prompt="a toy cat", image=image, mask_image=mask_image).images[0]Run Stable Diffusion image inpainting using the fine-tuned model.
ConclusionConclusion
in conclusion:
Use pixellib to perform image segmentation and obtain the image mask.
Fine-tuning
runwayml/stable-diffusion-inpaintingthe model allows the model to learn new toy cat types.Run on the dog image using the fine-tuned model and the generated mask
StableDiffusionInpaintPipeline.
final result
After all steps are completed, we generate a new image with the toy cat in place of the original dog, so that both images can use the same bounding box.

We can now generate new images for all images in the dataset.
limitation
Stable Diffusion cannot generate good results every time. After the data set is generated, it needs to be cleaned.
This pipeline is very computationally intensive. Fine-tuning of Stable Diffusion requires a graphics card with 24GB of memory, and a GPU is also required for inference.
This method of building a dataset is useful when the images in the dataset are difficult to obtain. For example, if you need to detect forest fires, it is better to use this method instead of setting fires in the forest. However, for ordinary scenarios, data annotation is still the most standard approach.
Original English text: https://www.sicara.fr/blog-technique/dataset-generation-fine-tune-stable-diffusion-inpainting
Follow the public account [Machine Learning and AI Generated Creation], more exciting things are waiting for you to read
A simple introduction to ControlNet, a controllable AIGC painting generation algorithm!
Classic GAN must read: StyleGAN
 Click me to view GAN’s series of albums~!
Click me to view GAN’s series of albums~!
A cup of milk tea and become the cutting-edge trendsetter of AIGC+CV vision!
The latest and most complete collection of 100 articles! Generate diffusion modelsDiffusion Models
ECCV2022 | Summary of some papers on Generative Adversarial Network GAN
CVPR 2022 | 25+ directions, the latest 50 GAN papers
ICCV 2021 | Summary of 35 topic GAN papers
Over 110 articles! CVPR 2021 most comprehensive GAN paper review
Over 100 articles! CVPR 2020 most comprehensive GAN paper review
Unpacking a new GAN: decoupling representation MixNMatch
StarGAN version 2: multi-domain diversity image generation
Attached download | "Explainable Machine Learning" Chinese version
Attached download | "TensorFlow 2.0 Deep Learning Algorithm Practice"
Attached download | Sharing of "Mathematical Methods in Computer Vision"
"A Review of Surface Defect Detection Methods Based on Deep Learning"
"A Review of Zero-Sample Image Classification: Ten Years of Progress"
"A Review of Few-Sample Learning Based on Deep Neural Networks"
"Book of Rites·Xue Ji" says: If you study alone without friends, you will be lonely and ignorant.
Click on a cup of milk tea and become the cutting-edge trendsetter of AIGC+CV vision! , join the planet of AI-generated creation and computer vision knowledge!