1. Process creation
1.fork
(1) fork function
The fork function creates a new process from an existing process. The original process is the parent process and the new process is the child process.
#include <unistd.h>
pid_t fork(void);Return value: 0 is returned in the child process, the id of the child process is returned in the parent process, and -1 is returned on error.
The process calls fork. When control is transferred to the fork code in the kernel, the kernel does the following:
Allocate new memory blocks and kernel data structures to the child process
Copy part of the data structure content of the parent process to the child process
Add child process to system process list
fork returns and the scheduler starts scheduling
For the following code:
fork.c
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
#include<stdlib.h>
int main()
{
printf("Before fork: PID = %d\n",getpid());
if(fork()==-1)
{
printf("fork error\n");
exit(1);
}
printf("After fork: PID = %d\n",getpid());
sleep(1);
return 0;
}The running results are as follows:

Befor outputs once and Afetr outputs twice. This is because before fork, there is only one execution flow of the parent process, and the parent process executes independently; after fork, the two execution flows of the parent and child processes execute together:
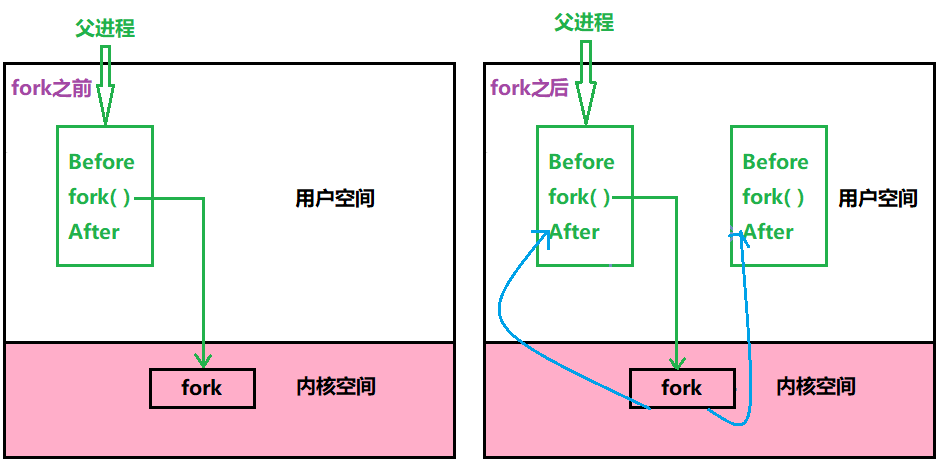
Since all the codes of the created child process and the parent process are shared, even the code that has been executed, in theory, when the parent process executes fork, when the child process returns, it does not return from the before position of the child process. Start execution. This is because when the parent process is executing, there is a pc pointer indicating where the current process is pointing. The data of this pc pointer will be inherited by the child process. Therefore, once the child process is created, the child process will start running from the inherited pc pointer position of the parent process, which is after fork, but in fact, the child process can still see the code before fork, which is before.
After fork, which of the parent and child processes executes first is entirely determined by the scheduler.
(2) fork function return value
Why does the fork function have 2 return values?
After creating the child process, the operating system needs to create the child process control block, child process pcb, child process address space, and child process page table to build the mapping relationship. After the child process is created, the operating system also adds the process control block of the child process to the system process list. At this time, the child process is created.

Before the return statement is executed inside the fork function, the child process has been created. At this time, both the child process and the parent process will execute the return statement, and the fork function will have two return values.
Why return 0 to the child process? What about returning the pid of the child process to the parent process?
给子进程返回0是因为对于子进程来说,父进程不需要被标识。因为一个父进程有多个子进程,因此给父进程返回子进程id来唯一标识一个子进程,当父进程知道子进程的pid后才可以更好地给子进程分配任务。
2.写时拷贝
fork之后,子进程被创建出来了,由于父子进程共享代码和数据,所以父进程和子进程的代码和数据是通过页表映射到物理内存的同一块空间中。只有当父进程或子进程任一方需要修改数据时,才会把父进程的数据在物理内存中重新拷贝一份出来,然后再做修改。请阅读博客【Linux】-- 进程概念一文中第九节的第4小节。
3. fork常规用法
一个父进程希望复制自己,使父子进程同时执行不同的代码段。例如,父进程等待客户端请求,生成子进程来处理请求。
一个进程要执行一个不同的程序,例如子进程从fork返回后,调用exec函数。
4. fork调用失败的原因
系统中有太多的进程。
实际用户的进程数超过了限制。
二、进程终止
1.进程退出场景
进程在以下三种场景下会退出:
代码运行正确,进程退出
代码运行不正确,进程退出
代码异常终止(程序崩溃了)
2.进程退出码
当程序通过./可执行程序把程序转化为进程,然后执行代码当中main函数内部代码,执行到return运行结束后,进程的退出码会被父进程也就是shell读取到。假如代码执行成功就让main函数返回99:
#include<stdio.h>
int main()
{
printf("This is a program\n");
return 99;
}可以通过
echo $?来查看进程退出码:

main函数调用结束后,要给操作系统返回相应的退出信息,main函数的返回值是进程的退出码。因此操作系统规定,main函数返回值0表示代码执行成功,返回值非0表示代码执行出现错误,这就是为什么main函数都以return 0作为代码结尾的原因。
为什么要规定返回0就代表代码执行成功,返回非0代表代码执行不成功?
代码执行成功的的情况只有一种,那就是成功了;但是代码执行不成功的原因可能有很多种:数组越界、堆栈溢出、除数为0、内存不足。
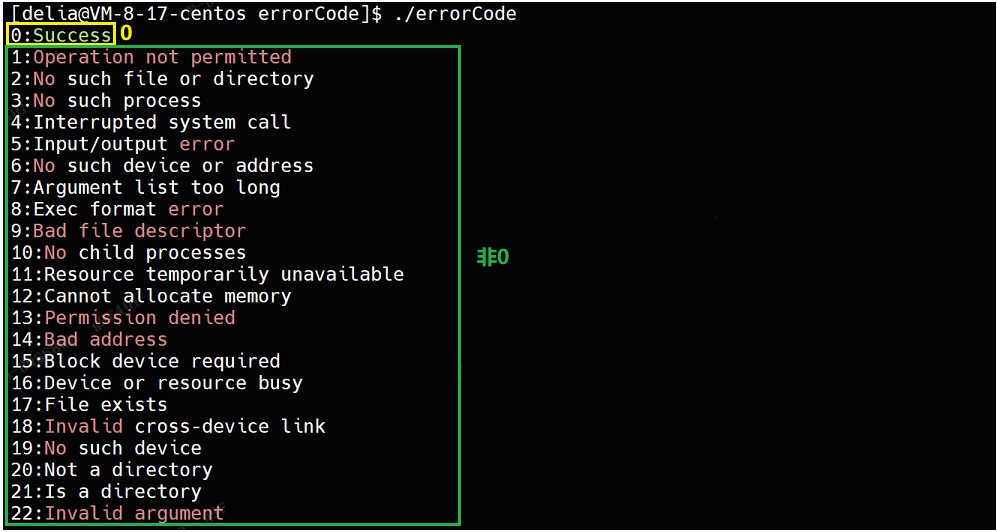
那就可以用0来代表执行成功,用非0分别代表执行不成功的各种原因。通过strerror函数获取错误码和错误码对应的错误信息:
#include<string.h>
char * strerror ( int errnum );将strerror的错误码和错误信息打印出来:
#include<stdio.h>
#include<string.h>
int main()
{
int i = 0;
for(i = 0;i<250;i++)
{
printf("%d:%s\n",i,strerror(i));
}
return 0;
}可以看到0就是执行成功,也能看到非0的所有错误信息:
3.进程常见退出方法
(1)正常终止
从mian函数return
#include<stdio.h>
int main()
{
printf("dell\n");
return 0;
}正常终止,退出码为0:

调用exit
exit函数直接使进程停止运行,清除其使用的内存空间,并销毁其在内核中的各种数据结构,参数就是进程退出时的退出码:
#include<stdlib.h>
void exit (int status);exit执行过程如下:
执行用户通过 atexit或on_exit定义的清理函数。
关闭所有打开的流,所有的缓存数据均被写入
调用_exit
exit函数在进程退出前,会检查文件的打开情况,并把文件缓冲区的内容写回文件:

无论在程序的任何地方执行exit,进程都会退出,不会执行后面的内容:
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
int main()
{
printf("linux-1");
sleep(5);
exit(1);
printf("linux-2\n");
return 0;
}打印第7行后,由于第7行没有\n,不会在显示器上立即刷新,而是保存在用户缓冲区当中,sleep 5秒期间,第7行的内容不会显示出来。 在sleep 5秒后,进程就退出了,退出前会把缓冲区的内容刷新出来,并且不会执行后面的打印了:

这是因为exit和return本身就会要求系统进行缓冲区刷新。
如果不想让子进程执行完子进程自己的代码以后还向下跑去执行父进程的代码,那么就要让子进程执行完后exit退出。
调用_exit
_exit( )函数直接终止进程,缓冲区的数据将会丢失
#include <unistd.h>
void _exit(int status);如下代码,直接关闭进程,并不会打印任何内容:
#include<stdio.h>
#include<unistd.h>
int main()
{
printf("linux-1");
_exit(1);
printf("linux-2");
return 0;
}缓冲区的数据丢失了:

总结:exit的执行包含3步
执行用户通过 atexit或on_exit定义的清理函数
关闭所有打开的流,所有的缓存数据均被写入
调用_exit
exit和_exit的区别如下:
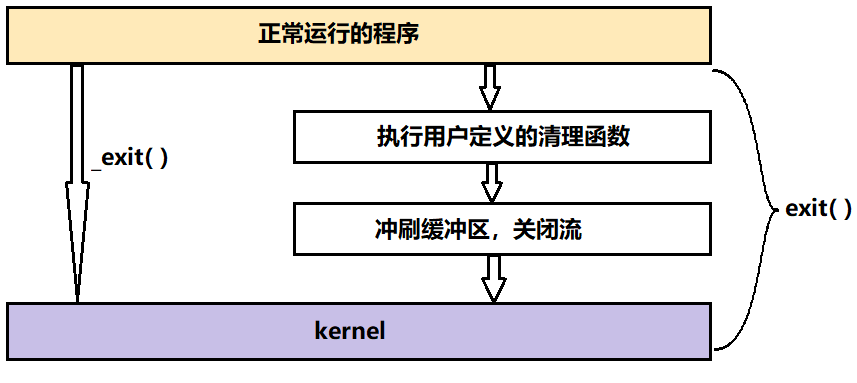
这也就能说明缓冲区不在kernel部分,否则_exit( )也会刷新缓冲区,因此缓冲区不在操作系统层面上,而是用户缓冲区。
(2)异常终止
ctrl + c,信号终止
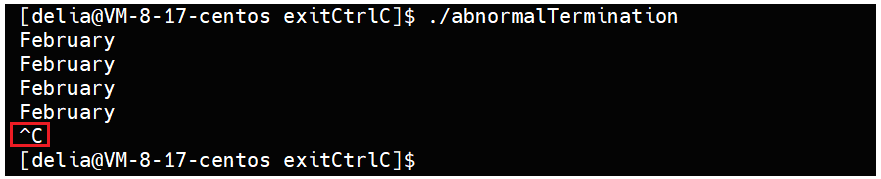
当进程正在运行时,可以通过ctrl + c来终止进程:
#include<stdio.h>
#include<unistd.h>
int main()
{
while(1)
{
sleep(1);
printf("February\n");
}
return 0;
}当使用ctrl+C时,停止了打印:因为此时进程被ctrl+C异常终止了:
(3)进程退出时操作系统做的工作
进程退出时,操作系统做了什么呢?
由于在创建进程时,系统里多了个进程,操作系统所做的工作包括创建进程控制块、创建进程地址空间、创建页表、加载进程代码和数据。
无论对于进程正常终止还是异常终止,在进程退出时,这只是程序层面的退出,这并不意味着进程已经结束了。从系统层面上少了个进程,那么操作系统就要释放PCB、释放进程地址空间、释放页表和各种映射关系、释放代码和数据、释放申请的空间。
三、进程等待
1.进程等待的必要性
当子进程退出时,如果父进程不管不顾,就可能造成僵尸进程,引起内存泄漏
进程一旦变成僵尸状态,那么就会刀枪不入,连kill -9也无效,因为无法杀死一个已经死去的进程
父进程需要知道派给子进程的任务,子进程完成的如何(包括子进程是否运行完成、结果是否正确、子进程是否正常退出)
父进程通过进程等待的方式,回收子进程资源,获取子进程退出信息
2.进程等待的方法
(1)wait
fork出子进程后,子进程和父进程可能都在运行,但并不确定谁先退出。因此父进程需要等待子进程,这是因为:
通过获取子进程退出的信息,能够得知子进程执行结果
保证在时序上,子进程先退出,父进程后退出
进程退出时会先进入僵尸状态,会造成内存泄漏,需要通过父进程wait,释放子进程占用的资源。
那么如何解决进程等待,从而解决僵尸问题呢?
先来看看wait( )函数:
#include <sys/types.h>
#include <sys/wait.h>
pid_t wait(int *status);
//返回值
//非0(即子进程ID):子进程执行成功
//-1:出错父进程让子进程执行自己的代码,子进程运行5秒以后,不想让它再去执行父进程的代码,就让子进程退出。由于父进程什么都没有做,那么父进程刚进来就退出了,但是子进程要运行5秒以后才结束,那么子进程就变成了系统领养的孤儿进程:
#include<stdio.h>
#include<systypes.h>
#include<syswait.h>
int main()
{
int id = fork();
if(id == 0)
{//child,执行5秒后才退出
int count = 5;
while(count > 0)
{
printf("child,count = %d\n",count);
count--;
sleep(1);
}
exit(0);
}
//parent,刚进来就退出
}所以哪怕父进程什么都不做,也要等待子进程执行完,子进程在执行期间,父进程需要一直等待:
#include<stdio.h>
#include<sys/types.h>
#include<sys/wait.h>
#include<unistd.h>
#include<stdlib.h>
int main()
{
int id = fork();
if(id == 0)
{//child,执行5秒后才退出
int count = 5;
while(count > 0)
{
printf("child,count = %d\n",count);
count--;
sleep(1);
}
exit(0);
}
//parent,刚进来就退出
pid_t ret = wait(NULL);
if(ret > 0)
{
printf("father wait:%d,success\n",ret);
}
else
{
printf("father wait failure\n");
}
}看到父进程wait的结果是成功的:
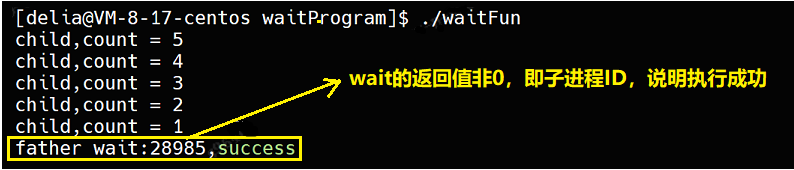
使用监控脚本查看父进程和子进程的进程状态。开两个窗口,一个窗口先监控:
while :; do ps axj | head -1 && ps axj | grep waitFun | grep -v grep; sleep 1;echo "###########################"; done另一个窗口运行程序:
假如父进程等待10秒才执行呢?
#include<stdio.h>
#include<sys/types.h>
#include<sys/wait.h>
#include<unistd.h>
#include<stdlib.h>
int main()
{
int id = fork();
if(id == 0)
{//child,执行5秒后才退出
int count = 5;
while(count > 0)
{
printf("child,count = %d\n",count);
count--;
sleep(1);
}
exit(0);
}
//parent,父进程等待10秒再wait获取子进程执行结果
sleep(10);
pid_t ret = wait(NULL);
if(ret > 0)
{
printf("father wait:%d,success\n",ret);
}
else
{
printf("father wait failure\n");
}
//父进程再等待10秒,父进程
sleep(10);
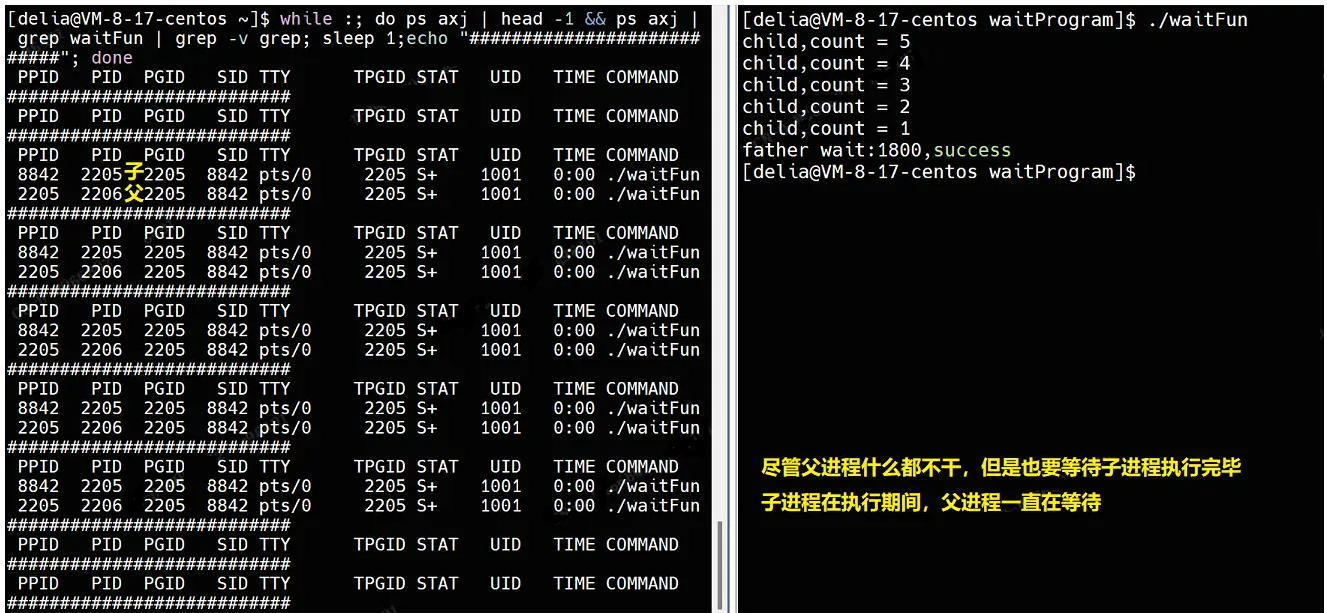
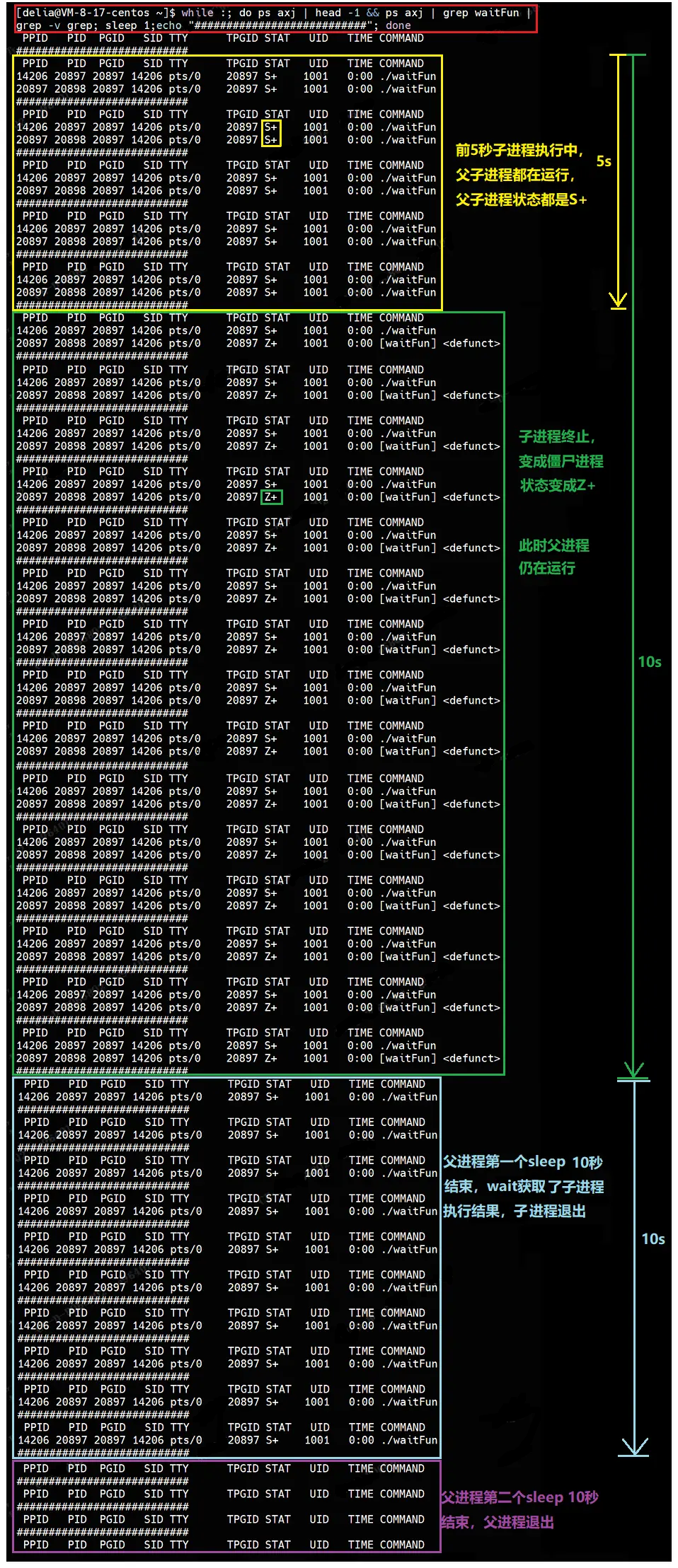
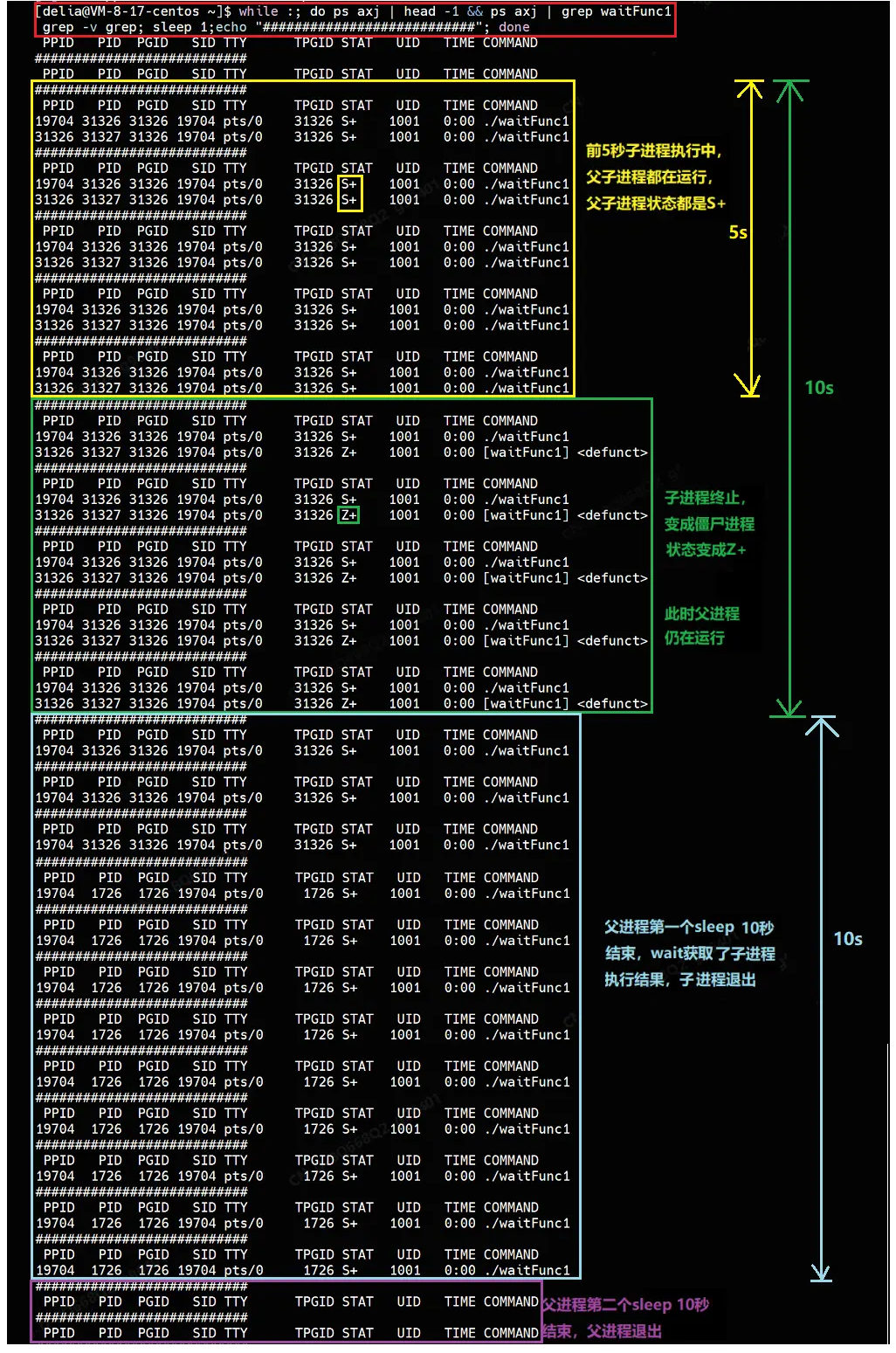
}使用监控脚本查看父进程和子进程的进程状态:
前5秒父进程在等待子进程执行,父子进程的状态都是S+,持续5秒;
5秒后,子进程终止,子进程变成僵尸进程,状态为Z+,父进程状态依旧为S+,持续到第10秒;
10秒后,父进程wait获取子进程的执行结果,子进程退出,父进程继续运行;
20秒后,父进程终止,父进程退出,至此,程序执行完毕。
程序执行结果:
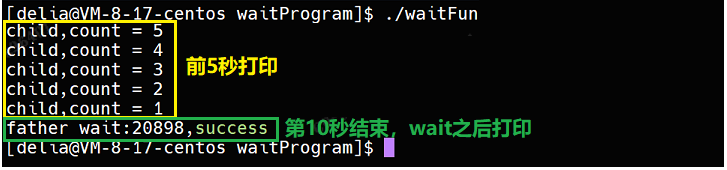
这也就证明了:
wait能够回收僵尸进程
子进程运行时,父进程一直在等待子进程
在时序上,子进程先退出,父进程后退出
(2)waitpid
waitpid如果执行成功,就会返回父进程等待的子进程的PID,如果出错就返回-1
#include <sys/types.h>
#include <sys/wait.h>
pid_t waitpid(pid_t pid, int *status, int options);参数:
pid :
为-1时,等待任意一个子进程,此时waitpid就相当于wait
>0时,等待其进程ID与pid相等的子进程
status 常用的有以下两种:
WIFEXITED(status):若为正常终止子进程返回的状态,则为真(查看进程是否正常退出)
WEXITSTATUS(status):若WIFEXITED非零,提取子进程退出码(查看进程的退出码)
返回值:
当正常返回的时候waitpid返回等待的子进程ID
如果没有设置选项WNOHANG,而调用中waitoid发现没有已退出的子进程可以收集,则返回0
如果调用中出错,则返回-1,这时errno会被设置成相应的值以指示错误所在
如下代码:
waitFunc1.c
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/wait.h>
#include<stdlib.h>
int main()
{
pid_t id = fork();
if(id == 0)//child
{
int count = 5;
while(count)
{
printf("child - %d is running,count = %d\n",getpid(),count);
count--;
sleep(1);
}
exit(0);
}
//father
sleep(10);
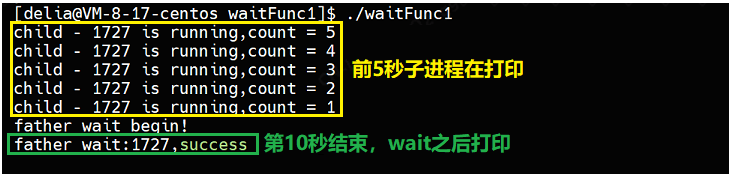
printf("father wait begin!\n");
pid_t ret = waitpid(id,NULL,0);//父进程回收子进程
if(ret > 0)
{
printf("father wait:%d,success\n",ret);
}
else
{
printf("father wait failed!\n");
}
sleep(10);
}使用监控脚本查看父进程和子进程的进程状态:
前5秒父进程在等待子进程执行,父子进程的状态都是S+,持续5秒;
5秒后,子进程终止,子进程变成僵尸进程,状态为Z+,父进程状态依旧为S+,持续到第10秒;
10秒后,父进程waitpid获取子进程的执行结果,子进程退出,父进程继续运行;
20秒后,父进程终止,父进程退出,至此,程序执行完毕。
程序执行结果:
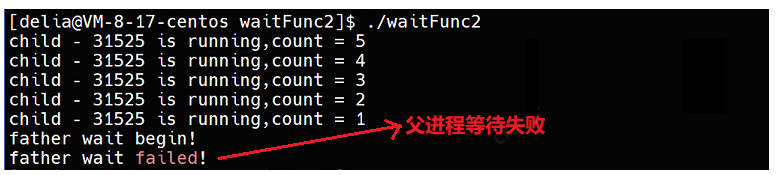
如果父进程等待的ID和子进程实际ID不一致,就会等待失败,如下将父进程等待的pid改为子进程ID+1:
waitFunc2.c
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/wait.h>
#include<stdlib.h>
int main()
{
pid_t id = fork();
if(id == 0)//child
{
int count = 5;
while(count)
{
printf("child - %d is running,count = %d\n",getpid(),count);
count--;
sleep(1);
}
exit(0);
}
//father
sleep(10);
printf("father wait begin!\n");
pid_t ret = waitpid(id+1,NULL,0);//父进程等待的ID和子进程实际ID不一致
if(ret > 0)
{
printf("father wait:%d,success\n",ret);
}
else
{
printf("father wait failed!\n");
}
sleep(10);
}父进程等待失败:
(3)获取子进程status
假如说父进程等待时,status不为NULL呢?
waitFunc3.c
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/wait.h>
int main()
{
pid_t id = fork();
if(id == 0)//child
{
int count = 3;
while(count)
{
printf("child [%d] is running: count is :%d\n",getpid(),count);
count--;
sleep(1);
}
exit(10);
}
//father
printf("father wait begin!\n");
int status = 0;//status不为NULL
pid_t ret = waitpid(id,&status,0);
if(ret > 0)
{
printf("father wait: %d success, status = %d\n",ret,status);
}
else
{
printf("father wait failed!\n");
}
sleep(10);
}发现程序执行完毕后,status变成了2560:

所以有一个猜想:
父进程拿到的status结果一定和子进程如何退出强相关
想要获得子进程的退出结果,得先分析子进程都有哪些情况:
代码运行完毕,结果正确
代码运行完毕,结果不正确
代码异常终止
那么status肯定会反馈出子进程的退出情况,通过status得出子进程的退出情况属于哪一种,进而做出相关决策。所以最终一定要让父进程通过status得到子进程执行的结果。
如何知道代码执行完了呢?代码执行完了结果正切和代码执行完了结果不正确,是由进程退出码决定的,即main函数的return和exit传入的参数,即echo $?打印出来的内容,这就通过查看进程的退出码来确定进程跑完时的结果对还是不对。那么如何确定代码执行完了呢?
status:
wait和waitpid,都有status参数,该参数是一个输出型参数,由操作系统填充
如果传递NULL,表示不关心子进程的退出状态信息
否则,操作系统会根据该参数,将子进程的退出信息反馈给父进程
status不能简单的当作整形来看待,可以当作位图来看待,32个比特位,只使用了低16比特位:
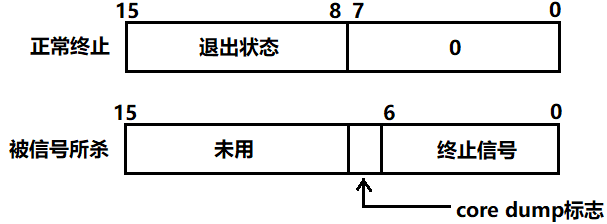
当进程正常终止时,就不会收到信号,这就说明代码是正常跑完的,然后才关心bit8~bit15的退出码,否则不关心退出码。
当进程异常终止时,会被信号所杀,bit0~bit6会收到终止信号。
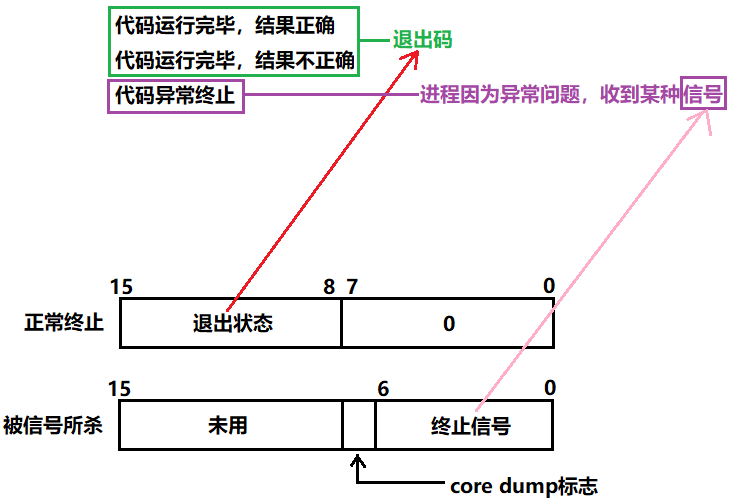
如何拿到退出状态值呢?
对于正常终止的进程,退出码在status 16比特位的高8位,需要先将status向右移8位,就得到了高8位的值,再同0xFF按位与,就得到了状态码
对于异常终止的进程,终止信号在status的低7位,将status同0x7F按位与,就得到了终止信号
status1.c
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/wait.h>
int main()
{
pid_t id = fork();
if(id == 0)//child
{
int count = 3;
while(count)
{
printf("child [%d] is running: count is :%d\n",getpid(),count);
count--;
sleep(1);
}
exit(11);//退出码
}
printf("father wait begin!\n");
int status = 0;
pid_t ret = waitpid(id,&status,0);
if(ret > 0)
{
//打印退出状态值
printf("father wait: %d success, status exit code: %d,status exit signal:%d\n",ret,(status >> 8)&0xFF,status&0x7F);
}
else
{
printf("father wait failed!\n");
}
sleep(10);
}
可以看到退出码是11,终止信号是0,0代表没有收到任何信号,是正常退出的进程,只不过结果不正确,错误的原因是11,我们可以根据退出码自己设定11的具体含义。

如果把21行的退出码由11改为0,那就对应了代码执行完毕,结果是正确的情况。非0或return非0就代表程序跑完不正确,当然不正确的含义由我们自己来定。
进程没有执行完毕,结果异常:
当子进程正在执行时,杀掉子进程,此时子进程没有执行完毕,结果异常:
status2.c
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/wait.h>
int main()
{
pid_t id = fork();
if(id == 0)//child
{
int count = 20;//改大一点
while(count)
{
printf("child [%d] is running: count is :%d\n",getpid(),count);
count--;
sleep(1);
}
exit(11);
}
printf("father wait begin!\n");
int status = 0;
pid_t ret = waitpid(id,&status,0);
if(ret > 0)
{
printf("father wait: %d success, status exit code: %d,status exit signal:%d\n",ret,(status >> 8)&0xFF,status&0x7F);
}
else
{
printf("father wait failed!\n");
}
sleep(10);
}
当子进程正在执行时,杀掉子进程,终止信号就变成了2,这代表代码没有跑完,结果异常,并且此时进程的退出码已经没有意义了:

通过最近子进程的退出结果来知道子进程运行结果如何,子进程如果出现崩溃、异常、结果不正确,就需要让父进程通过某种方式得到该进程的某些相关信息。
(4)阻塞式等待和非阻塞式等待
阻塞式等待和非阻塞式等待都是等待的一种方式,父进程在等待子进程退出,而子进程退出是由条件或时间触发的。
阻塞式等待
父进程调用waitpid时一定是R运行状态,把父进程的PCB里面的进程状态由R运行状态改为S睡眠状态并放到等待队列中,父进程就什么也不干,代码既不执行也不会被调度,就在等待队列中等待。子进程一旦结束,操作系统识别到子进程结束了,发现父进程是在等待的,就把父进程的节点从等待队列中拿到运行队列中,再执行后续的等待方式,来继续获取子进程的退出结果。
阻塞的本质,是进程的PCB被放入了等待队列,并将进程的状态改为S状态。
返回的本质,是进程的PCB从等待队列拿到R队列,从而被CPU调度,拿到子进程的退出结果
因此,为什么阻塞等待的时候,上层应用就卡住不动了,因为CPU不调度该进程了。当子进程执行,父进程等待期间,父进程会把自己的状态设为非R状态,放在等待队列里,当子进程退出时,CPU会把父进程调度到运行队列。
非阻塞式等待
option如果设置为WNOHANG,那么就是非阻塞式等待,非阻塞式等待的时候,如果子进程没有退出,也没有被阻塞,那么父进程就可以做其他事。父进程等待成功了,就把等待结果拿出来。
四、进程程序替换
现在我们创建子进程的目的是让子进程执行父进程代码的一部分。假如子进程不想执行父进程的一部分代码,只想执行一个全新的程序,该怎么做呢?
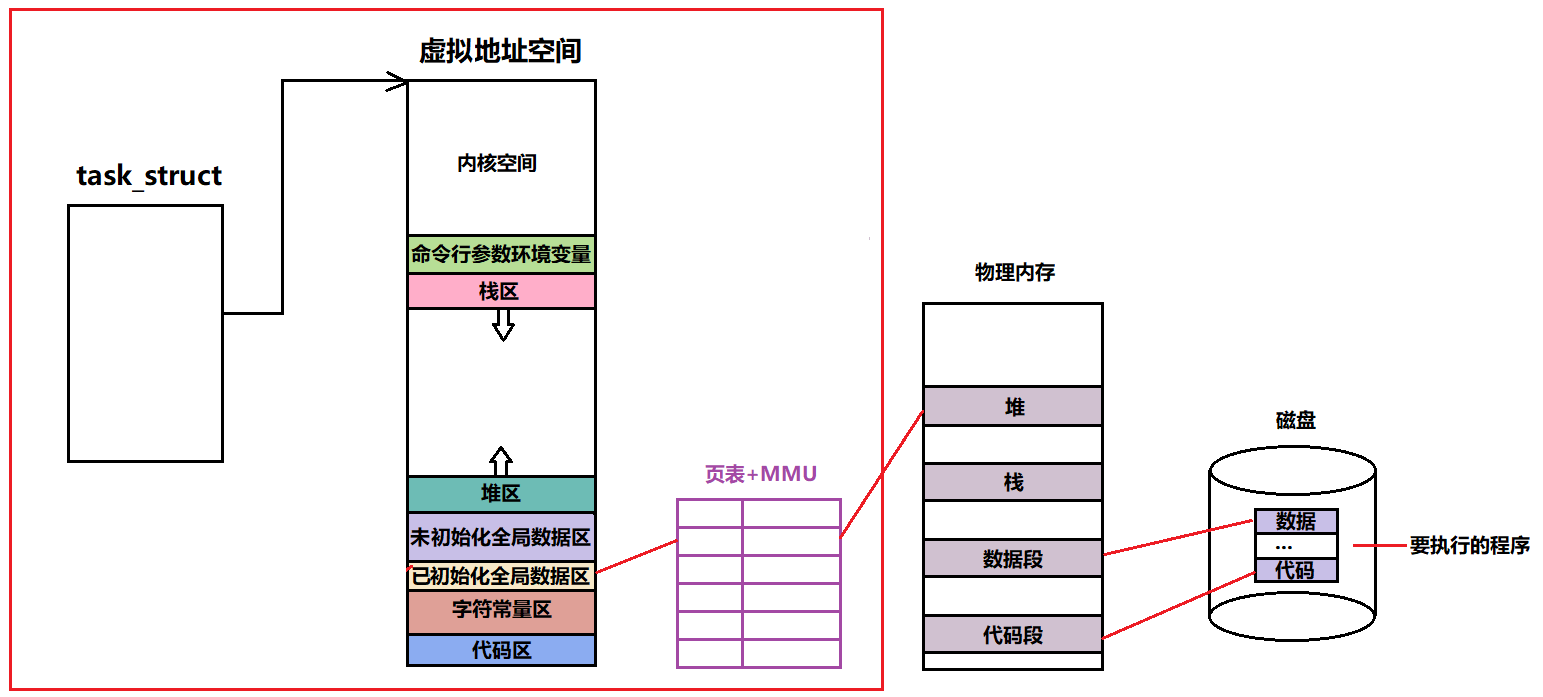
假如现在执行的是A进程的代码和数据,但是现在系统要求去执行B将酿成的代码和数据。那么下面红色的部分,除了映射关系要变,其他都不变。那么这个进程在执行的时候就不执行老的程序的代码和数据,而执行新的程序的代码和数据。
因此,当进程不变,而仅仅替换当前进程的代码和数据的技术,叫做进程的程序替换。
1.替换原理
用fork创建出子进程后,子进程调用exec函数来执行另一个程序,当进程调用exec函数时,进程的用户空间的代码和数据完全被新程序替换,从新的程序开始执行,调用exec并不创建新进程,所以调用exec前后该进程的id并未改变。这就时是进程替换。
程序的本质就是文件,文件=程序代码+程序数据
当文件在磁盘中存放时,可以把这个程序的代码和数据分别加载到当前进程对应的代码段和数据段,在加载的时候地址发生变化,会修改页表,但是代码和数据一旦替换之后,红色框内相关空间并没有发生任何变化,相当于用一个老进程的壳子,去执行一个新的程序的代码和数据,这就叫做程序的进程替换
2.替换函数
(1)如何使用替换函数
先看以下程序:
replace1.c
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/wait.h>
int main()
{
printf("I am a process! pid:%d\n",getpid());
execl("/usr/bin/ls","ls","-a","-l",NULL);//程序替换,不再执行execl函数之后的代码了
printf("this is a process\n");
return 0;
}执行结果如下:
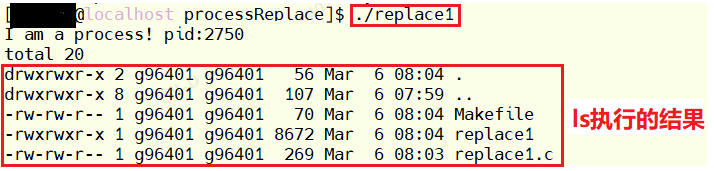
可以看到,打印了第一个printf后,还打印出了ls的内容
为什么执行execl打印出来的结果就是ls的内容?这是因为execl让进程不再执行自己的其他代码,而跑去执行替换掉的新程序的代码。
为什么I am a process被打印出来了,为什么后面的this is a process没有打印出来呢?因为执行第一个printf的时候,execl还没被执行,程序也没有被替换,执行第二个printf时程序的代码和数据已经被替换了,所有execl后面的内容不会被打印,因为已经被替换掉了。
进程替换的本质就是把程序的进程代码+数据加载到特定进程的上下文中,C/C++程序要运行,必须要先使用加载器加载到内存中,这就要用到exec*系列程序替换函数,它们充当了加载器,把磁盘当中的程序加载到内存。
有了程序替换,就可以让子进程执行程序替换,让父进程做自己的事:
replace2.c
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<unistd.h>
#include<sys/wait.h>
#include<sys/types.h>
int main()
{
pid_t id = fork();
if(id == 0)//child
{
printf("I am a process!,pid :%d\n",getpid());
sleep(5);
execl("/usr/bin/ls","ls","-a","-l",NULL);
printf("this is a progress\n");
exit(0);
}
while(1)
{
printf("I am father\n");
sleep(1);
}
}执行结果如下:
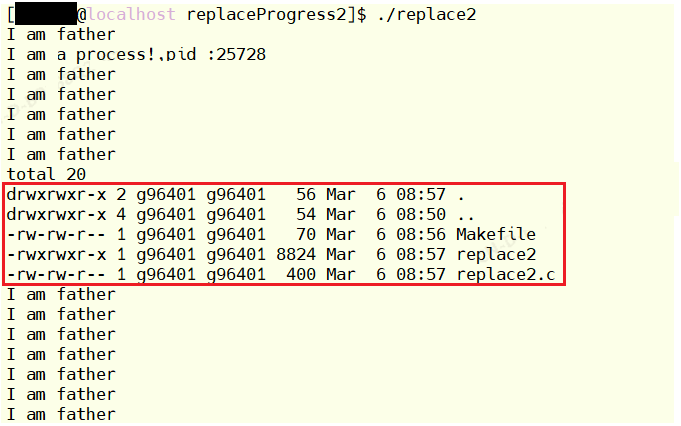
为什么程序替换之后,子进程被替换了,父子进程代码是共享的,而父进程却没有受影响呢?因为进程具有独立性。由于父子进程独立,进程程序替换会更改代码区的代码,也会发生写时拷贝,所以子进程就会去执行新的程序,而父进程不会受到影响。
所以,如果想让子进程执行一个全新的程序,就可以使用程序替换。
exec函数:
如果调用成功,则加载新的程序,从启动代码开始执行,不再返回。
如果调用出错,则返回-1
exec函数只有调用出错的返回值,而没有调用成功的返回值
以execl函数为例:

命令行参数会在进程当只能够以char *argv的形式传进来,参数最终会被程序获得,所以execl第二个参数的底层肯定是把这些若干个参数组成char* argv指针数组的方式去调用ls的main函数。
当在命令行这样执行时:

看下面代码:
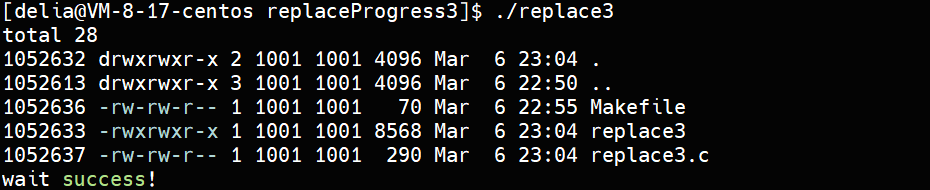
replace3.c
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/wait.h>
int main()
{
pid_t id = fork();
if(id == 0)
{
execl("/usr/bin/ls","ls","-a","-l","-n","-i",NULL);
exit(1);
}
waitpid(-1,NULL,0);
printf("wait success!\n");
}与命令行执行的结果相同:
(2)替换函数家族
有如下替换函数:
#include <unistd.h>
int execl(const char *path, const char *arg, ...);
int execlp(const char *file, const char *arg, ...);
int execv(const char *path, char *const argv[]);
int execvp(const char *file, char *const argv[]);
int execle(const char *path, const char *arg, ...,char *const envp[]);
int execve(const char *file, char *const argv[],char *const envp[]);它们都有同execl同样的规则:
这些函数如果调用成功则加载新的程序从启动代码开始执行,不再返回。
如果调用出错则返回-1
所以exec函数只有出错的返回值而没有成功的返回值。
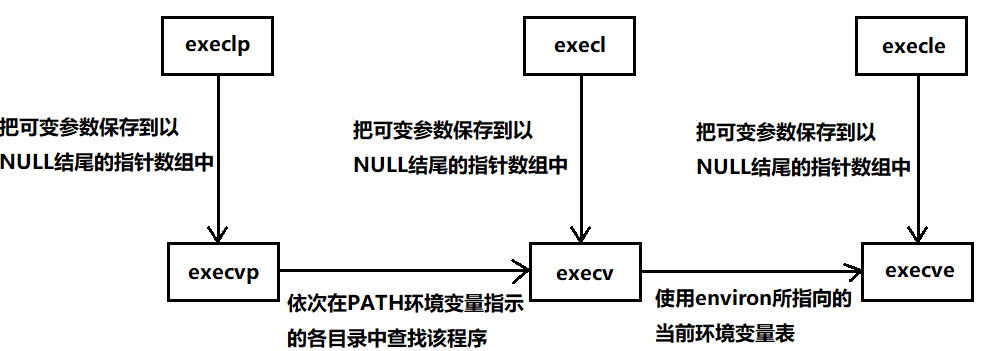
可以发现这些函数包含如下规律:
l(list) : 表示参数采用列表
v(vector) : 参数用数组
p(path) : 自动搜索环境变量PATH
e(env) : 表示自己维护环境变量
函数名 |
参数格式 |
是否带路径 |
是否使用当前环境变量 |
execl |
列表 |
否 |
是 |
execlp |
列表 |
是 |
是 |
execle |
列表 |
否 |
否,需自己组装环境变量 |
execv |
数组 |
否 |
是 |
execvp |
数组 |
是 |
是 |
execve |
数组 |
否 |
否,需自己组装环境变量 |
execl
#include <unistd.h>
int execl(const char *path, const char *arg, ...);execl的第一个参数是路径+文件名,第二个参数arg表明如何在命令行执行这个程序,最后的参数NULL表明参数结束。
如下代码:
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/wait.h>
int main()
{
pid_t id = fork();
if(id == 0)
{
execl("/usr/bin/ls","ls","-a","-l","-n","-i",NULL);
exit(1);
}
waitpid(-1,NULL,0);
printf("wait success!\n");
}执行结果如下:

execv
#include <unistd.h>
int execv(const char *path, char *const argv[]);execv的第一个参数是路径+文件名,第二个参数是指针数组,里面存放一个一个传进来的参数,把命令当中传入的一个一个数组,统一打包到数组里,所以和execl没有差别,execl用的是可变参数列表,而execv用的是指针数组,数组元素个数由我们来定.
如下代码:
execv.c
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/wait.h>
int main()
{
if(fork() == 0)//child
{
printf("command begin..\n");
char *argv[] = {
"ls",
"-a",
"-l",
"-i",
"-n",
NULL
};
execv("/bin/ls",argv);//使用argv作为参数
printf("command end!\n");
exit(1);
}
waitpid(-1,NULL,0);
printf("wait child success!\n");
return 0;
}运行结果:
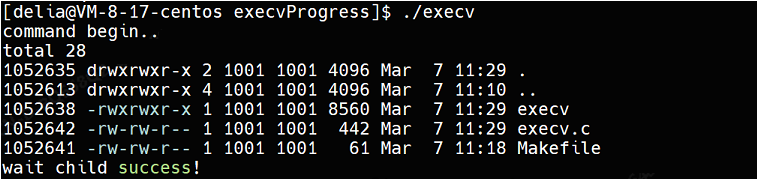
和直接执行ls命令的结果一样:

execlp
#include <unistd.h>
int execlp(const char *file, const char *arg, ...);execlp中的p表示能够自动搜索环境变量PATH,第一个参数是文件名,在执行特定程序时,只要知道程序名系统就会自动在环境变量path中搜索程序位置,不需要知道这个程序在哪里。第二个参数arg表明如何在命令行执行这个程序,最后的参数NULL表明参数结束。
如下代码:
execlp.c
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<sys/wait.h>
int main()
{
if(fork() == 0)//child
{
printf("command begin..\n");
execlp("ls","ls","-a","-l","-i","-n",NULL);//不需要指定路径,只需要指定文件名和可变参数
printf("command end!\n");
exit(1);
}
waitpid(-1,NULL,0);
printf("wait child success!\n");
return 0;
}运行结果和直接执行ls命令的结果一样:
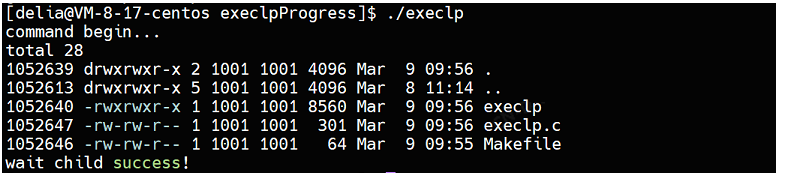
execvp
#include <unistd.h>
int execvp(const char *file, char *const argv[]);v表示参数用数组,p表示自动搜索环境变量PATH,因此execvp的第一个参数是文件名,只要知道程序名系统就会自动在环境变量path中搜索程序位置,不需要知道这个程序在哪里。第二个参数是指针数组,里面存放一个一个传进来的参数,把命令当中传入的一个一个数组,统一打包到数组里。
如下代码:
execvp.c
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
#include<sys/wait.h>
int main()
{
if(fork() == 0)
{
printf("command begin...\n");
char *argv[] = {
"ls",
"-a",
"-l",
"-i",
"-n",
NULL
};
execvp("ls",argv);
printf("command end...\n");
exit(1);
}
}执行结果如下:

execle
#include <unistd.h>
int execle(const char *path, const char *arg, ...,char *const envp[]);第一个参数是路径+文件名,第二个参数arg表明如何在命令行执行这个程序,最后的参数envp是一个以NULL为结尾的指针数组。
在执行替换程序时,如果不想执行系统程序,而是想执行自己生成的程序,不使用默认环境变量,而是想自己传入或者维护环境变量,把环境变量信息传递给子进程,该怎么做呢?如果makefile一次能够形成2个可执行程序,就能帮助我们达到把一个程序运行起来之后替换为另一个程序的目的。
那么问题来了,如何同时形成2个可执行程序呢?
由于makefile默认会形成在依赖关系当中第一个的依赖文件,比如想同时生成func1和func2两个可执行文件,源文件如下所示:
func1.c
#include<stdio.h>
int main()
{
printf("func1\n");
return 0;
}fun2.c
#include<stdio.h>
int main()
{
printf("func2\n");
return 0;
}如果按照如下方式写Makefile,那么就只能生成一个可执行文件:
Makefile
func1:func1.c
gcc -o $@ $^
func2:func2.c
gcc -o $@ $^
.PHONY:clean
clean:
rm -f func1 func2编译之后发现只有func1一个可执行文件,并没有func2可执行文件:
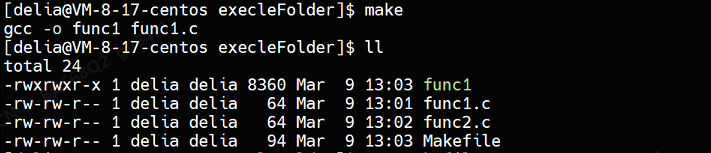
如果交换可执行目标的及其依赖关系的顺序
Makefile
func2:func2.c
gcc -o $@ $^
fun1:func1.c
gcc -o $@ $^
.PHONY:clean
clean:
rm -f func1 func2删除func1可执行文件后再执行make命令,会发现,只形成了func2一个可执行文件,没有func1可执行文件:
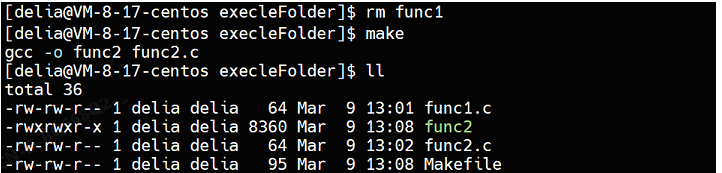
如何才能同时形成两个可执行文件呢?使用伪目标all,伪目标不需要依赖方法,所以不会形成all可执行文件,而且伪目标all总是被执行,为了形成all,会分别形成func1和func2两个可执行文件:
Makefile
.PHONY:all
all: func1 func2
func1:func1.c
gcc -o $@ $^
func2:func2.c
gcc -o $@ $^
.PHONY:clean
clean:
rm -f func1 func2删掉func2之后,再执行make命令,就会发现同时生成了func1和func2两个可执行程序:
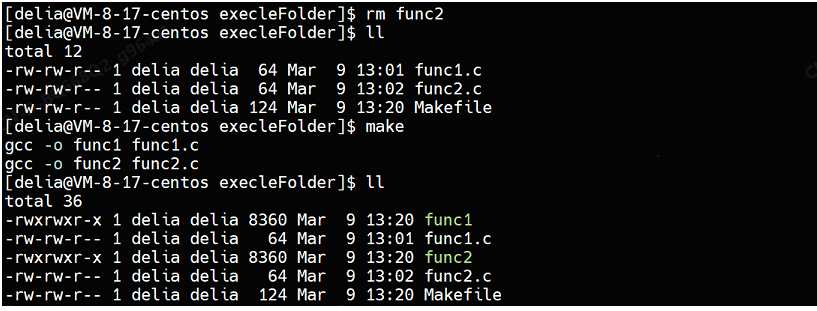
此时想在func1子进程中进行程序替换,替换为执行func2程序,使用execle函数:
func1.c
#include<stdio.h>
#include<unistd.h>
#include<sys/wait.h>
int main()
{
if(fork() == 0)
{
execle("./func2","func2",NULL);//替换为执行func2
}
waitpid(-1,NULL,0);
return 0;
}执行结果如下,成功替换:
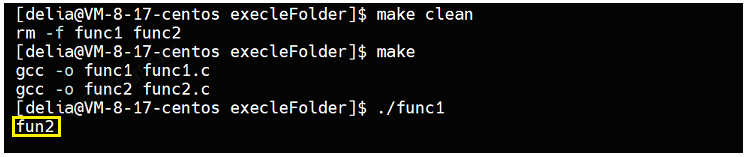
其中func1给func2导入了一个环境变量,如果执行func2行时,不想使用如下的系统默认环境变量:
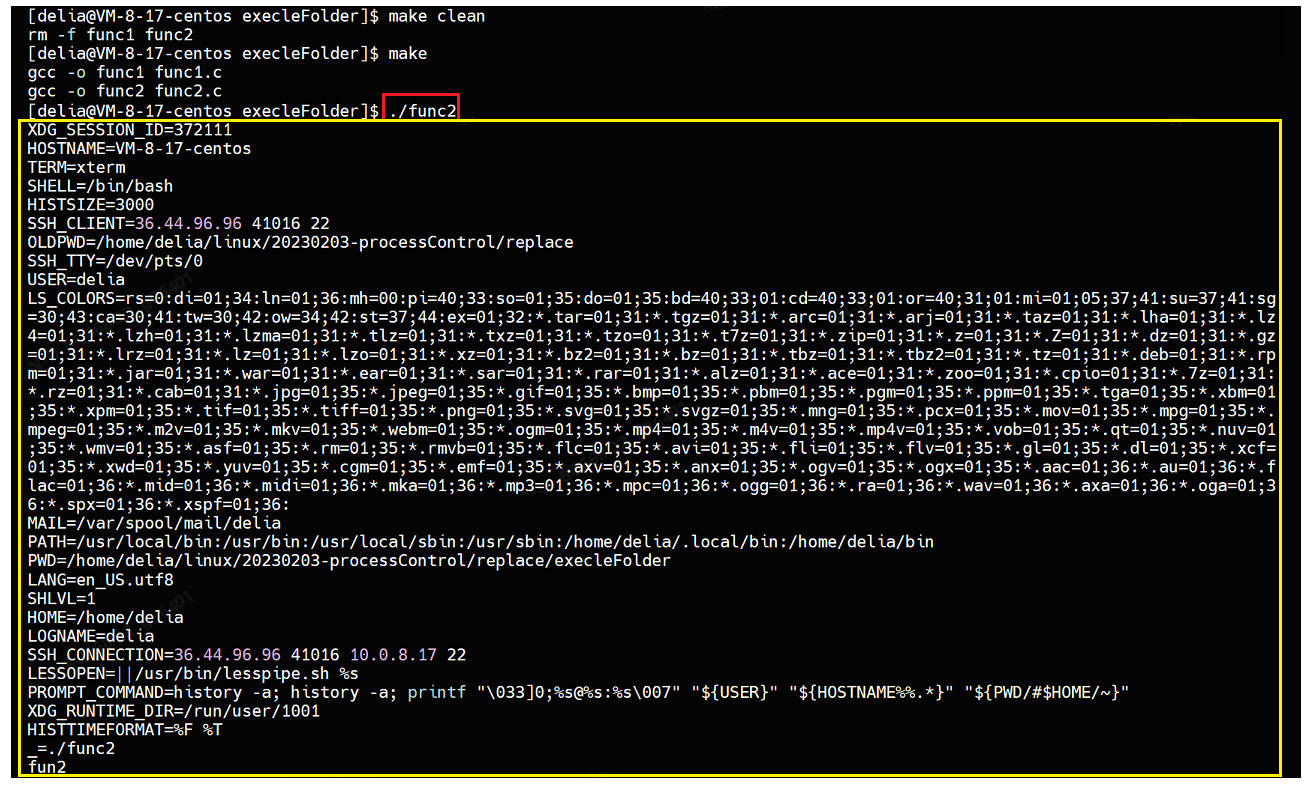
如果想使用自定义的环境变量,那就在func1.c中定义环境变量:
#include<stdio.h>
#include<unistd.h>
#include<sys/wait.h>
int main()
{
if(fork() == 0)
{
//自定义环境变量
char *env[] = {
"newENV1 = ENV1",
"newENV2 = ENV2",
"newENV3 = ENV3",
NULL
};
execle("./func2","func2",NULL,env);//使用自定义环境变量来执行新的替换程序
}
waitpid(-1,NULL,0);
//printf("fun1\n");
return 0;
}结果如下,发现func2的环境变量已经被更改了,再去运行func2,就会使用新的环境变量:
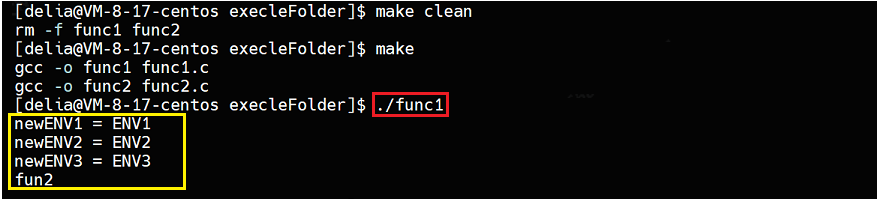
execve
#include<unistd.h>
int execve(const char *file, char *const argv[],char *const envp[]);execve的第一个参数是文件名, 第二个参数是指针数组,里面存放一个一个传进来的参数,把命令当中传入的一个一个数组,统一打包到数组里,最后的参数envp是一个以NULL为结尾的指针数组。
如下代码:
func1.c
#include<stdio.h>
#include<unistd.h>
#include<sys/wait.h>
int main()
{
if(fork() == 0)
{
char *env[] = {
"newENV1 = ENV1",
"newENV2 = ENV2",
"newENV3 = ENV3",
NULL
};
char *argv[] = {
"func2",
NULL
};
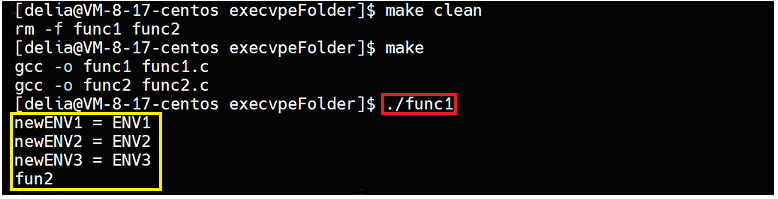
execve("./func2",argv,env);//文件名,运行参数,环境变量
}
waitpid(-1,NULL,0);
return 0;
}func2.c
#include<stdio.h>
#include<unistd.h>
int main()
{
extern char**environ;
int i = 0;
for(i = 0;environ[i];i++)
{
printf("%s\n",environ[i]);
}
printf("fun2\n");
return 0;
}
执行结果如下:
替换函数家族关系:
五、制作一个简易shell
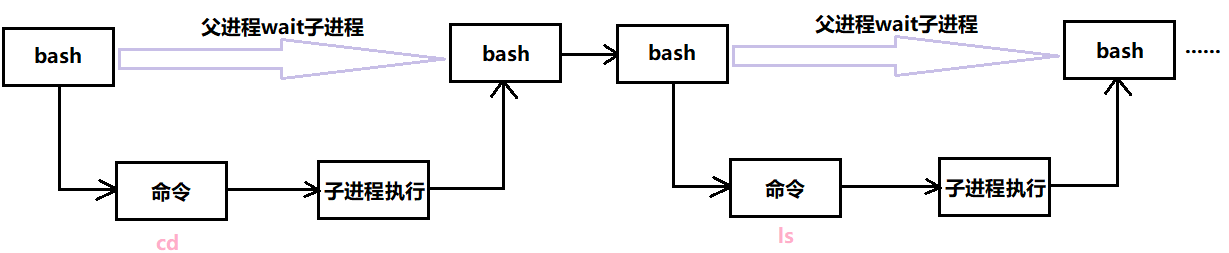
Shell原理如下所示:
由于所有进程的父进程是bash进程,因此父进程bssh在用户输入命令后,会创建子进程,让子进程去执行命令,父进程则等待子进程的执行结果:
要实现一个Shell,那么就要:
打印提示符
获取命令行字符串
解析命令行字符串并传递给指针数组
函数替换
打印退出码
miniShell.c
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
#include<sys/wait.h>
#include<string.h>
#define NUMBER 128
#define CMD_NUMBER 64
int main()
{
char command[NUMBER];
for(;;)
{
char *argv[CMD_NUMBER] = {NULL};
//1.打印提示符
command[0] = 0;
printf("[delia@VM-8-17-centos shell]$");
fflush(stdout);//在不带\n的情况下,想让缓冲区内容立即刷新出来,就要使用fflush
//2.获取命令字符串
fgets(command,NUMBER,stdin);//获取command内容,即命令行参数,获取NUMBER个字符,从stdin获取
command[strlen(command) -1 ] = '\0';//去掉最后的\n,否则按Enter之后光标会跑到下一行
printf("echo:%s\n",command);//打印命令行参数
fflush(stdout);//在不带\n的情况下,想让缓冲区内容立即刷新出来,就要使用fflush,至此获取到的命令行参数是"ls -a -l -i -n\0"的形式
//3.解析命令字符串,把获得的命令行参数以列表的形式传递给指针数组
const char *sep = " ";
argv[0] = strtok(command,sep);
int i = 1;
while(argv[i] = strtok(NULL,sep))
{
i++;
}
//4.函数替换
pid_t id = fork();
int status = 0;
if(id == 0)
{
execvp(argv[0],argv);
exit(1);
}
//5.打印退出码,以区分是系统执行的还是miniShell执行的
pid_t ret = waitpid(id,&status,0);
if(ret > 0)
{
printf("miniShell exit code:%d\n",WEXITSTATUS(status));//打印子进程退出码
}
}
}运行结果:

打印了退出码,说明是miniShell执行的。