
In this article you will find a summary of my latest research on AI and work (exploring the impact of AI on productivity while opening up discussions about long-term implications), an example of a quasi-experimental approach (illustrated via ChatGPT and Stack Overflow , learn how to extract data from Stack Overflow using simple SQL queries.
As with most technological revolutions, the release of ChatGPT was accompanied by novel and revolutionary innovations. For one thing, in just two months, the app hit 100 million monthly active users, breaking the record for the fastest-growing consumer app in history. On the other hand, a Goldman Sachs report claims that such technology could displace more than 300 million jobs worldwide. Additionally, Elon Musk signed an open letter with more than 1,000 technology leaders and researchers urging a moratorium on state-of-the-art artificial intelligence development.
“We can only see a short distance ahead, but we can see much that needs to be done.” Alan Turing
Following the quote from Alan Turing, this article does not attempt to predict the distant future of artificial intelligence and its impact. However, I focus on one of the main observable consequences affecting us: how AI changes the way we code.
The birth of ChatGPT changed the world. At least, as someone who codes every day, my world changed overnight. Instead of spending hours on Google looking for the right solution, or digging into answers on Stack Overflow, and converting the solution to my exact problem with the correct variable names and matrix dimensions, I can just ask ChatGPT. Not only will ChatGPT give me the answer in the blink of an eye, but the answer will be tailored to my specific situation (e.g. correct names, dataframe dimensions, variable types, etc.). I was blown away and my productivity suddenly skyrocketed.
Therefore, I decided to explore the large-scale impact of the ChatGPT release and its potential impact on productivity and ultimately the way we work. I defined three hypotheses (Hs) and tested them using Stack Overflow data.
H1: ChatGPT reduces the number of questions asked on Stack Overflow. If ChatGPT can solve coding problems in seconds, we can expect fewer questions on the coding community platform because it takes time to ask questions and get answers.
H2: ChatGPT improves the quality of questions asked. If ChatGPT was used heavily, the remaining questions on Stack Overflow must be better documented, as ChatGPT might have been helpful.
H3: The remaining questions are more complex. We can expect the remaining questions to be more challenging, as ChatGPT may not be able to answer them. So to test this, we're testing whether the proportion of unanswered questions increases. Additionally, I tested whether the number of views for each question changed. If the number of views per question remains stable, it would be an additional sign that the complexity of the remaining questions has increased, and that this finding is not simply caused by a decrease in activity on the platform.
To test these hypotheses, I'll take advantage of ChatGPT, which was suddenly released on Stack Overflow. When OpenAI publicly releases their ChatGPT in November 2022, there are no alternatives available (such as Google Bard), and access is free (not limited to paid subscriptions like OpenAI ChatGPT 4 or Code Interpreter). Thus, it was possible to observe how activity in the online coding community changed before and after the shock. However, no matter how "clean" the shock is, other effects may be confounded, calling into question causation. Especially with seasonality (e.g. year-end holidays after publication) and the newer the question, the lower the number of views and the probability of finding the answer.
Ideally, in order to mitigate the impact of potentially confounding variables such as seasonality and measure causal effects, we would like to observe the world without ChatGPT releases, which is not possible (e.g. fundamental problems of causal inference). Nonetheless, I will address this challenge by exploiting the fact that the quality of ChatGPT's answers to encoding-related questions varies from one language to another, and using a quasi-experimental approach to limit the risk of other factors confounding the effect ( Difference-in - difference).
To do this, I will compare Stack Overflow activity between Python and R. Python is an obvious choice, as it is arguably
one of the most popular programming languages (e.g., ranked #1 in TIOBE).
Python's extensive online resources provide a rich training set for ChatGPT such as ChatGPT. Now, for comparison with Python, I chose R. Python is often considered the best alternative to R, and both are free. However, R is less popular (e.g., ranked 16th in the TIOBE Programming Community Index), so the training data is likely smaller, meaning ChatGPT's performance is poorer. The evidence confirms this difference (see the Methods section for more details on the method). Therefore, R represents a valid counterfactual for Python (it is affected by seasonality, but we can expect a negligible effect from ChatGPT).

Figure 1: Impact of ChatGPT on the number of weekly questions asked on Stack Overflow
The chart above shows the raw weekly data. We can see that after the release of ChatGPT 3.5, the number of questions asked about Python per week on Stack Overflow suddenly dropped significantly (21.2%), while the impact on R was slightly smaller (down 15.8%).
These “qualitative” observations were confirmed by statistical models. The econometric model described later found that Python weekly questions on Stack Overflow dropped by an average of 937.7 questions (95% CI: [-1232.8, -642.55]; p-value = 0.000), which was statistically significant. Subsequent analysis, using the Diff-in-Diff method, further revealed an increase in question quality (measured by scores on the platform), as well as an increase in the proportion of unanswered questions (while the average number of views per question appeared to have increased ). constant). Therefore, this study provides evidence for the three hypotheses defined previously.
These findings underscore the profound role artificial intelligence will play in the way we work. By solving day-to-day queries, generative AI enables individuals to devote their energy to more complex tasks while increasing their productivity. However, important long-term potential adverse effects are also discussed in the Discussion section.
The remainder of this article presents the data and methods, followed by the results, and concludes with a discussion.
data
Data was extracted using SQL queries on the Stack Overflow data browser portal (License: CC BY-SA ). This is the SQL command used:
SELECT Id, CreationDate, Score, ViewCount, AnswerCount
FROM Posts
WHERE Tags LIKE '%<python>%'
AND CreationDate BETWEEN '2022–10–01' AND '2023–04–30'
AND PostTypeId = 1;I then aggregated the data by week to reduce noise, resulting in a dataset from Monday, October 17, 2022, to March 19, 2023, with information on weekly number of posts, views, views per issue Information about the number of times, the average score for each question and the proportion of unanswered questions. Scores are defined by platform users, who can vote up or down on whether a question shows "research effort; whether it is useful and clear."
method
To measure causal effects, I use a difference-in-differences model, an econometric method that typically exploits change over time and compares treated units to an untreated group.
Briefly, the Diff-in-Diff model computes double differences to identify causal effects. This is a simplified explanation. First, the idea is to calculate two simple differences: the "average" difference between the pre (before ChatGPT is released) and post periods for the treated and untreated groups (here, Python and R questions respectively). What we care about is the impact of processing on processing units (here is the impact of ChatGPT release on Python issues). However, as mentioned previously, there may be another effect that remains confounded with treatment (e.g. seasonality). To solve this problem, the idea of the model is to calculate double differences to check how the first difference of the treatment group (Python) differs from the second difference (the difference of the control group R).
This is a slightly more formal expression.
First difference in reference values:
Here i and t refer to the language (R or Python) and week respectively. While Treat refers to issues related to Python, Post refers to the period when ChatGPT was available. This simple difference may represent a causal effect of ChatGPT (β) + some temporal effect λₜ (e.g. seasonality).
The first difference between control variable groups:
The simple difference in the control group does not include the treatment effect (because it was untreated), but only λ.
Therefore, double differencing will give:
Assuming that λ is the same for both groups (parallel trends assumption, discussed below), the double difference will allow us to identify β, the causal effect.
The essence of the model lies in the parallel trends assumption. To assert a causal effect, we should believe that the evolution of Python (processed) and R (unprocessed) posts on Stack Overflow during the processing period (after November 2022) would be the same without ChatGPT. However, this is clearly impossible to observe and therefore cannot be tested directly (see Basic Problems in Causal Inference). However, it is possible to test whether the trends before the shock were parallel, suggesting that the control group is a potentially good “counterfactual.” Two different placebo tests on the data show that we cannot reject the hypothesis of parallel trends in the pre-ChatGPT period (tested p-values of 0.722 and 0.397 respectively (see Online Appendix B)).
Formal definition:
“i” and “t” correspond to the topic (i ∈ {R; Python}) and week of the question on Stack Overflow respectively. Yᵢ represents the outcome variables: number of questions (H1), average question score (H2), and proportion of unanswered questions (H3). Pythonᵢ is a binary
variable that takes the value 1 if the question is related to Python, and
0 otherwise (relevant to R). ChatGPTₜ is another binary variable
whose value is 1 starting from ChatGPT version and later,
and 0 otherwise. uᵢ are error terms clustered at the coding language level (i)
.
The essence of the model lies in the parallel trends assumption. To assert a causal effect, we should believe that the evolution of Python (processed) and R (unprocessed) posts on Stack Overflow during the processing period (after November 2022) would be the same without ChatGPT. However, this is clearly impossible to observe and therefore cannot be tested directly (see Basic Problems in Causal Inference). However, it is possible to test whether the trends before the shock were parallel, suggesting that the control group is a good “counterfactual.” In this case, two different placebo tests show that we cannot reject the hypothesis of parallel trends in the pre-ChatGPT period (the p-values of the tests are 0.722 and 0.397 respectively (see Online Appendix B)).
result
H1: ChatGPT reduces the number of questions asked on Stack Overflow.
As mentioned in the introduction, the Diff-in-Diff model estimates that Python questions on Stack Overflow have dropped by an average of 937.7 questions per week (95% CI: [-1232.8, -642.55]; p-value = 0.000) (see Figure 2 below) . This represents an 18% drop in the number of questions per week.
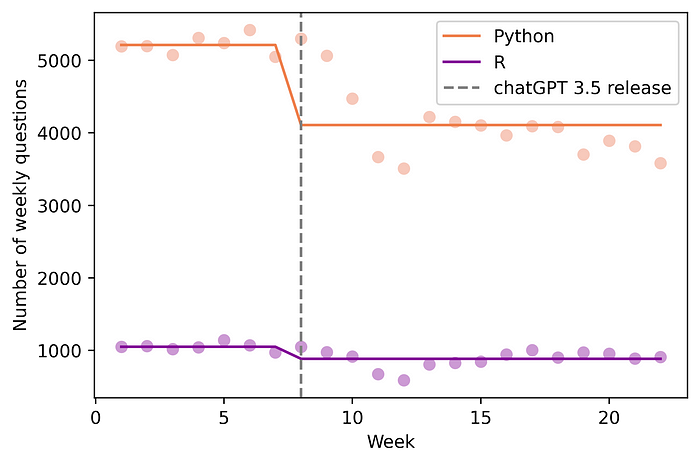
Figure 2: Impact of ChatGPT on the number of questions per week
H2: ChatGPT improves the quality of questions asked.
ChatGPT may help answer the question (see H1). However, when ChatGPT doesn't solve a problem, it may allow people to go further and get more information about the problem or some elements of the solution. The platform allows us to test this hypothesis, as if the user thinks "this question shows research results; useful and clear" (increase 1 point) , or not (decrease 1 point) . The second regression estimates an average increase in question scores of 0.07 points (95% CI: [-0.0127, 0.1518]; p-value: 0.095) (see Figure 3), which is an increase of 41.2%.

Figure 3: Impact of ChatGPT on question quality (image provided by the author)
H3: The remaining questions are more complex.
Now that we have some evidence that ChatGPT can provide significant assistance (resolving problems and helping to document others), we want to confirm that the remaining problems are more complex. To do this, we have to consider two things. First, I found that the proportion of unanswered questions was increasing (no answers may indicate a more complex question). More precisely, I found that the proportion of unanswered questions increased by 2.21 percentage points (95% CI: [0.12, 0.30]; p-value: 0.039) (see Figure 4), which represents an increase of 6.8%. Second, we also find that the number of views per question has not changed (we cannot reject the null hypothesis that it has not changed, with a p-value of 0.477).

Figure 4: Impact of ChatGPT on the proportion of unanswered questions
discuss
These findings support the idea that generative AI can revolutionize our jobs by tackling routine problems, allowing us to focus on more complex problems that require specialized knowledge, while increasing our productivity.