
Introduction
Recently, significant progress has been made in the research and implementation of large-scale language models ( ), taking important steps toward realizing general artificial intelligence (AGI) and performing well in various language applications. Large Language Models, LLMsFor example, the system released at the end of 2022 ChatGPTcan generate answers and interact with context based on the patterns and statistical rules seen in the pre-training stage. It can truly chat and communicate like humans, and can even complete email writing, copywriting, translation, coding, and knowledge Q&A. Wait for the task. Leveraging these large language models as language decoders and pre-trained visual large models as visual feature encoders, LMMs have also shown remarkable results in understanding visual and language data. The multi-modal large model can extract the information of the input image/video, combine it with the inherent world knowledge of the large language model, and conduct logical reasoning and answers to the input natural language instructions.
This research was jointly completed by the University of Science and Technology of China and ByteDance, and was uploaded to on August 23, 2023. For the arXivoriginal link, please click at the end of the article to read the original text and jump directly. In this study, the author proposes UniDoca unified multi-modal large model for text scenes . UniDoc focuses on the task of multimodal understanding of images containing text. Compared with existing multi-modal large models, UniDoc integrates text detection , recognition , and end-to-end OCR (spotting) capabilities that other multi-modal large models do not have. The study points out that the learning of these abilities mutually enhances each other. The paper provides qualitative and quantitative results on multiple test benchmark data sets of four tasks. The results show UniDoc's powerful recognition and understanding capabilities. On some text recognition test benchmark data sets, UniDoc achieves almost the same performance as supervised learning.
method
frame

As shown in the figure, UniDoc unifies tasks such as text detection, recognition, spotting and multi-modal understanding in a multi-modal instruction fine-tuning framework. Specifically, after inputting an image and instructions (such as detection, recognition, spotting or semantic understanding), UniDoc will extract visual and textual information from the image, and complete the answer based on the knowledge base of a large language model combined with the instruction content.

data
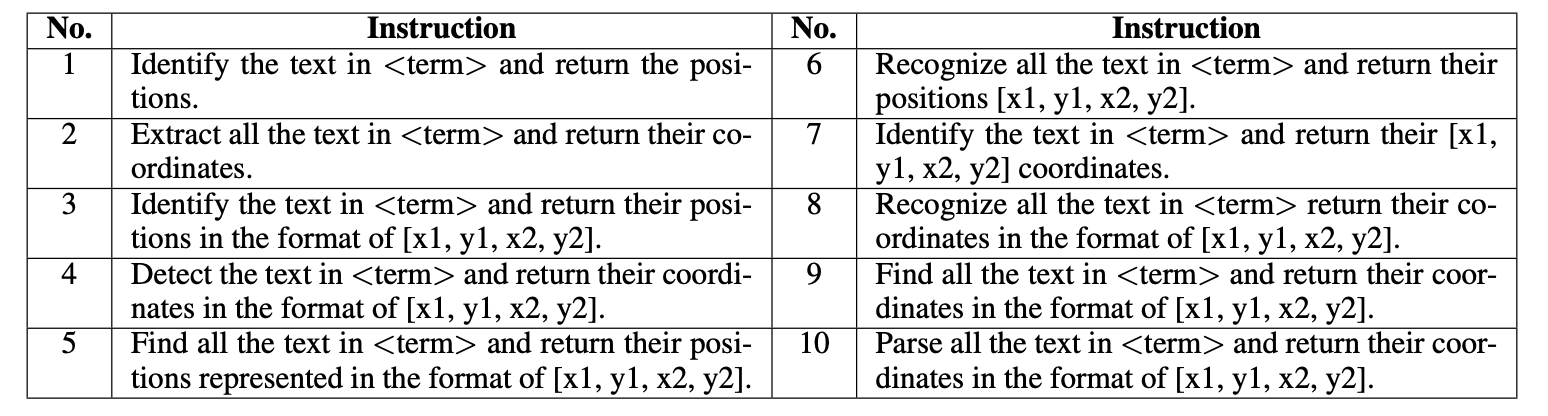
The team collected a large collection of PPTimages and extracted all text instances and their bounding boxes (bboxes) from them. Based on these data, a data set suitable for multi-task fine-tuning was constructed. Considering that the text in PPT has various sizes , fonts , colors, and styles , and its visual elements are rich and diverse, these PPT images are very suitable for use as training data for multi-modal text image tasks. Taking the end-to-end OCR task (spotting) as an example, its input instructions are as shown in the table below. The "term" represents random image nouns such as "image" and "photo" to enrich the diversity of instructions.
experiment
Text detection, recognition and end-to-end OCR
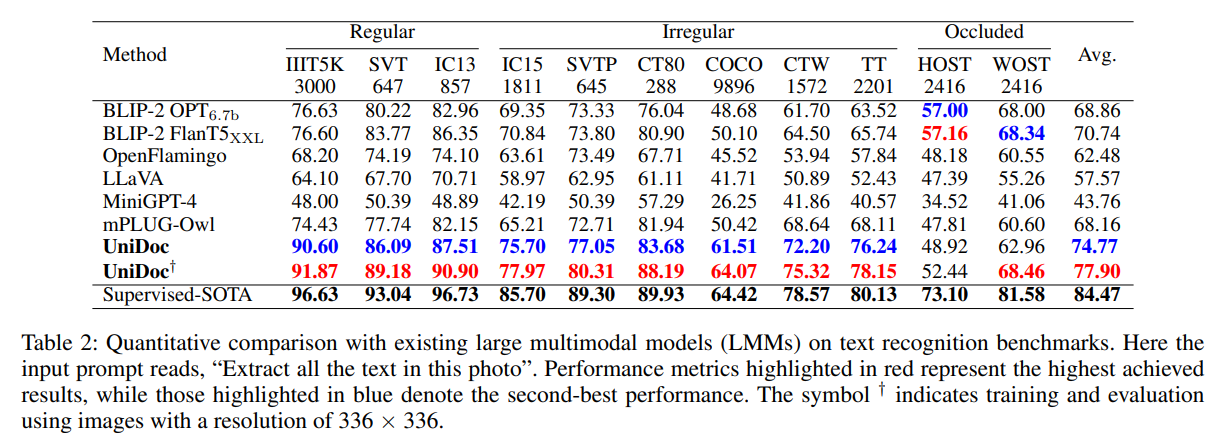
UniDoc has demonstrated excellent performance on multiple text recognition benchmark data sets. Each column in the table is a recognition benchmark data set. The research team presents quantitative results on two input image scales. It is worth noting that UniDoc was not trained separately using the training sets of these datasets. In addition, on some datasets (such as COCO), the recognition accuracy of UniDoc is almost the same as that of supervised learning (training using the training set of this dataset alone).

As shown in the figure above, the first row of samples comes from the WordArt data set, while the second row of four samples comes from the TotalText data set. Although these text images exhibit various fonts and irregular text distribution (which do not appear in the ppt data), UniDoc can still accurately recognize them.

The picture above is a sample from the Host data set. The results show that UniDoc can still accurately recognize even when part of the text is occluded or missing.


The figure above shows the text detection effect UniDocon TotalTextthe dataset.
Multimodal Q&A
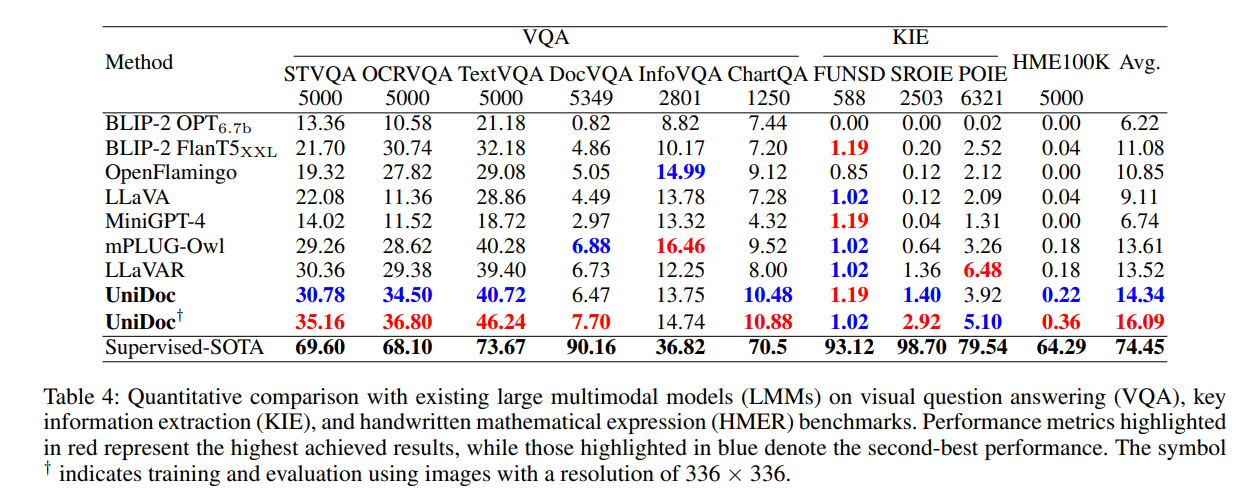
UniDoc shows excellent performance on multiple multi-modal question answering standard datasets. The research team presents quantitative results on two input image scales.


As shown in the above examples, UniDoc is not only able to effectively extract visual and textual information from images, but also combines it with its rich pre-trained knowledge to formulate reasonable answers. For example, in the example of the Forrest Gump movie poster above, it can know from the text in the movie poster that this is the movie "Forrest Gump". Furthermore, it can answer the movie content based on the world knowledge of the pre-trained large language model (information from the movie "Forrest Gump").

UniDoc can also accurately answer questions for images without text.
ablation experiment

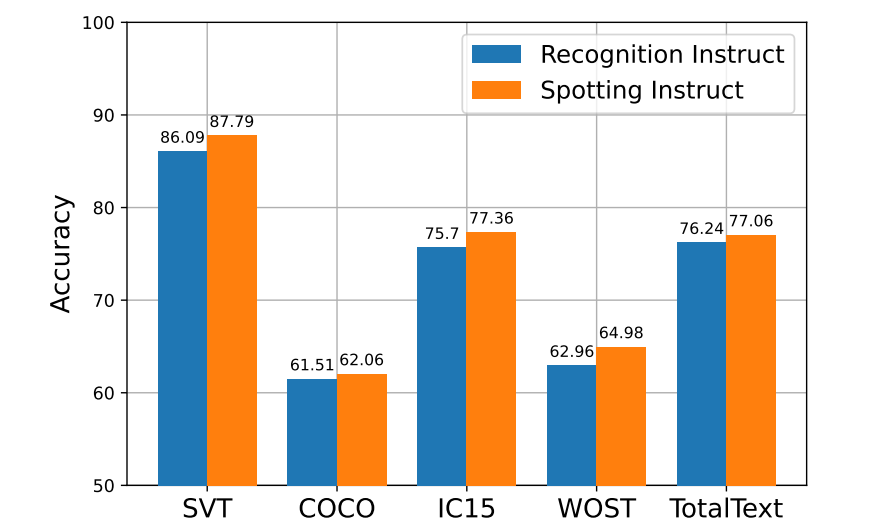
The paper provides an interesting experiment: inputting the same image (left), using the spotting command (right) can avoid recognition omissions that occur when using the recognition command (middle). According to the paper analysis, this is because the detection introduces prior information (there may be text in a certain area). As shown in the table below, the author conducted experiments on multiple test benchmark data sets, and the spotting instructions were consistently better than the recognition instructions.
Summarize
This paper introduces new work on UniDoca general large-scale multimodal model for simultaneous text detection, identification, identification, and understanding. Through the proposed unified multimodal instruction adjustment, UniDoc effectively exploits the beneficial interactions between text-based tasks, not only solving the shortcomings of existing large multimodal models, but also enhancing their original functionality. Furthermore, to implement UniDoc, the research team contributed a large-scale multimodal instruction that follows the dataset. Experiments show that UniDoc sets state-of-the-art scores on multiple benchmarks. However, currently UniDoc cannot extract fine-grained visual features for detection and recognition, and the resolution of the input image is still a limitation, which would be a good improvement.