Abstract: This article is compiled from the sharing by Zhou Keyong (Yizhui), head of Alibaba Cloud/Data Lake Spark engine, at the Streaming Lakehouse Meetup. The content is mainly divided into five parts:
- Apache Celeborn's background
- Apache Celeborn - Fast
- Apache Celeborn——Stable
- Apache Celeborn——Bomb
- Evaluation
Click to view the original video & speech PPT
1. Background
There are two sources of intermediate data for big data engines: Shuffle and Spill, the most important of which is Shuffle. According to statistics, more than 15% of resources are consumed in Shuffle.
1.1 Problems with traditional Shuffle
The structure diagram on the right side of the figure below shows the traditional Shuffle process. On the left is the Mapper Task, which sorts the Shuffle data based on the Partition ID, and then writes it to the local disk. At the same time, an index file is written to record the offset and length of each Partition in the file. . When the Reduce Task starts, it needs to read its own data from each Shuffle file.
From the perspective of Shuffle files, it receives a large number of concurrent read requests, and the data read by these requests is random, which will cause random disk I/O.
On the other hand, you can also see from the picture below that the number of network connections is also very large.
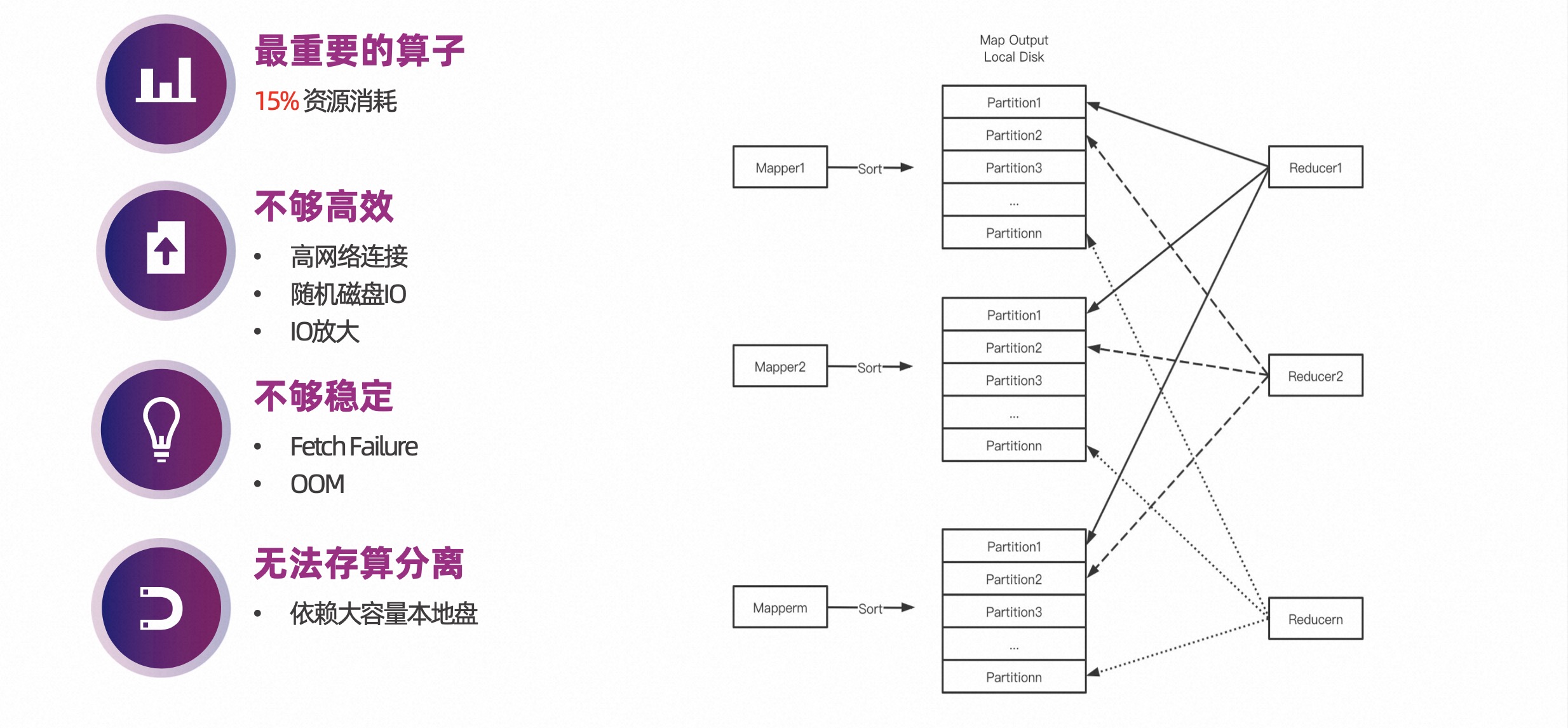
In summary, the Shuffle operator is very important, but there are also some problems:
- As the most important operator, resource consumption exceeds 15%;
-
High network connectivity, random disk I/O, and I/O amplification make it inefficient;
-
Fetch Failure and OOM make it unstable;
-
Relying on large-capacity local disk, storage and calculation cannot be separated.
1.2 Introduction to Apache Celeborn
Apache Celeborn is designed to solve the above Shuffle problems and is positioned to unify intermediate data services.

Apache Celeborn has two dimensions:
-
First, it has nothing to do with the engine. Spark and Flink have been officially implemented. Currently we are also working on the integration of MR and Tez.
-
Second, intermediate data. This refers to including Shuffle and Spill Data. When we host all the intermediate data, its computing nodes do not need such a large local disk, which means that the computing nodes can be truly stateless, which can achieve better results during job running. Scaling to achieve better elasticity and resource usage.
Development history of Apache Celeborn:
-
2020, born in Alibaba Cloud;
-
In December 2021, it will be open sourced to the outside world, and in the same year it will be co-constructed by developers on the cloud to build a diversified community;
-
In October 2022, enter the Apache incubator.
2. Apache Celeborn - fast
The speed of Apache Celeborn will be introduced from four perspectives:
-
core design
-
Row style Shuffle
-
vectorization engine
-
multi-tier storage
2.1 Core design: Push/Aggregation/Spilt
As can be seen from the picture below, the left side is the core design of Apache Celeborn, which is essentially a design of Push Shuffle and Partition aggregation. It will push the same Partition data to the same Celeborn Worker.
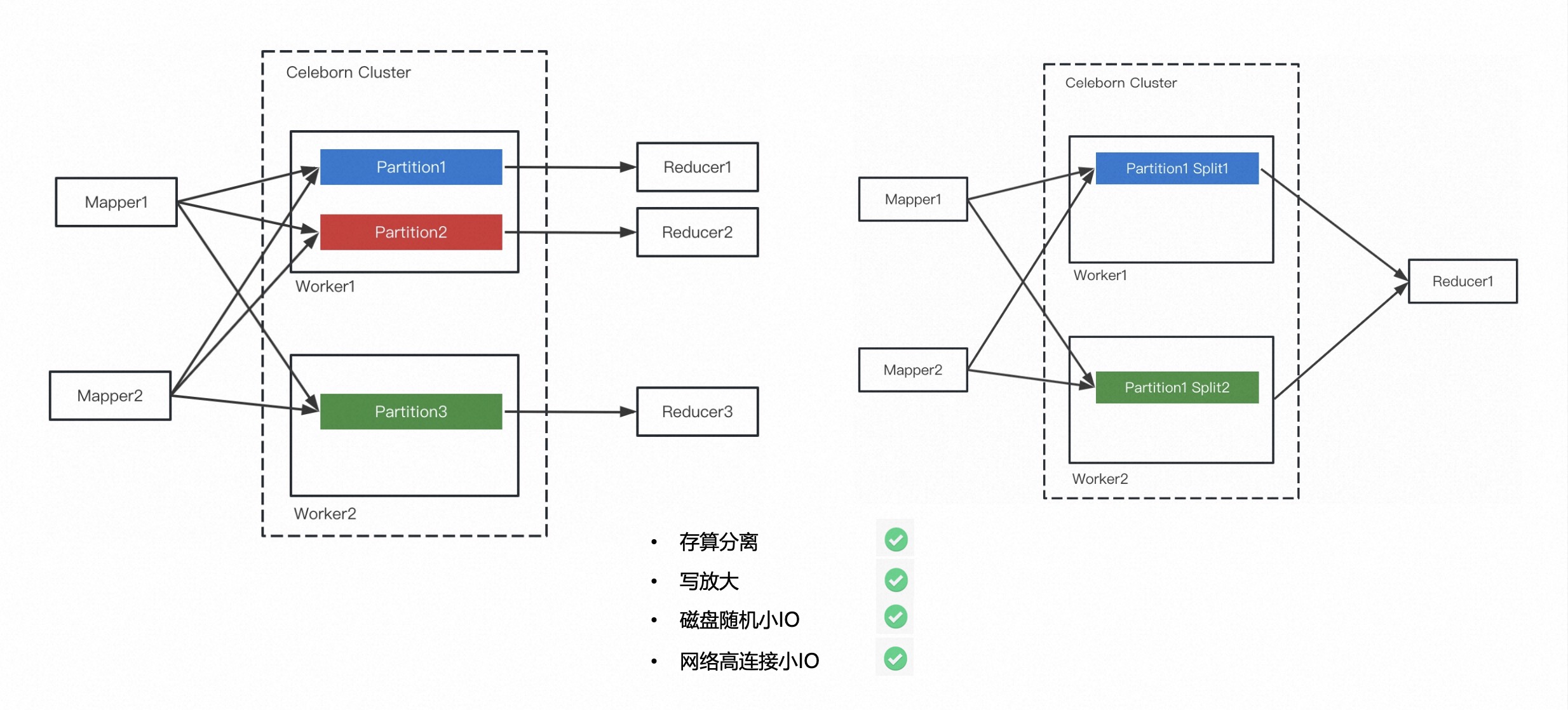
Under normal circumstances, the data of each Partition will eventually form a file, and the Reducer only needs to read one file from the Worker when reading.
Because Shuffle data is stored in Celeborn Cluster and does not need to be stored on the local disk, storage and calculation can be better separated. In addition, it is a Push Shuffle and does not require data sorting for the full Shuffle, so there is no write amplification problem.
Third, the problem of network and disk I/O inefficiency is solved through the aggregation of Partitions.
The architecture on the right side of the figure above shows that data skew is very common. Even in a non-skewed situation, it is easy for a certain Partition to have particularly large data. This will put greater pressure on the disk. So a Split mechanism was made here. To put it simply, Celeborn Cluster will check the size of a certain file. If it exceeds the threshold, Split will be triggered. That is to say, this Partition data will eventually generate multiple Split files, and the Reduce Task will read the Partition data from these Split files. .
2.2 Core design: asynchronous
We have made asynchronousization in many links so that the calculation of the calculation engine itself will not be blocked during writing, reading or Control Message.
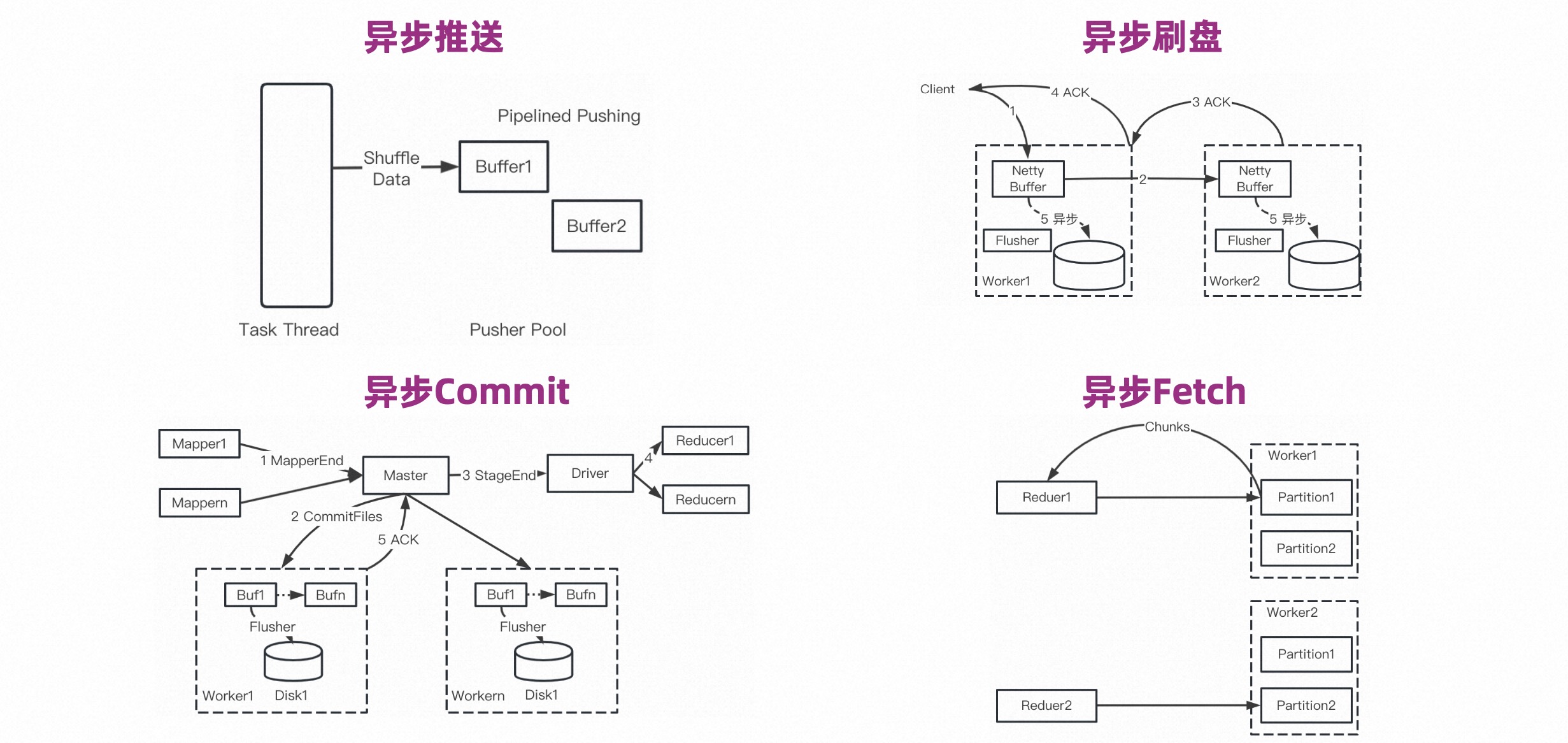
Asynchronous disk flashing, whether it is double backup or single backup, after the Worker receives the data, it can send ACK without waiting for the disk flashing. The disk flushing is asynchronous. When the Netty Buffer belonging to a certain Partition reaches a certain threshold, the disk flushing is triggered, thereby improving the disk flushing efficiency.
Asynchronous Commit means that there will be a Commit process after the Stage ends. Simply speaking, the Worker participating in Shuffle needs to flush the memory data to the disk. This process is also asynchronous.
Asynchronous Fetch is relatively common, which means that the Partition data generates files and is cut into many Chunks. Then multiple Chunks can be fetched during Fetch, so that the Fetch data and Reduce calculation pipeline can be pipelined.
2.3 Row Shuffle
Celeborn supports columnar Shuffle, which performs row-to-column shuffling when writing and column-to-row shuffling when reading. Compared with row storage, column storage has a higher compression rate and the amount of data can be reduced by 40%.
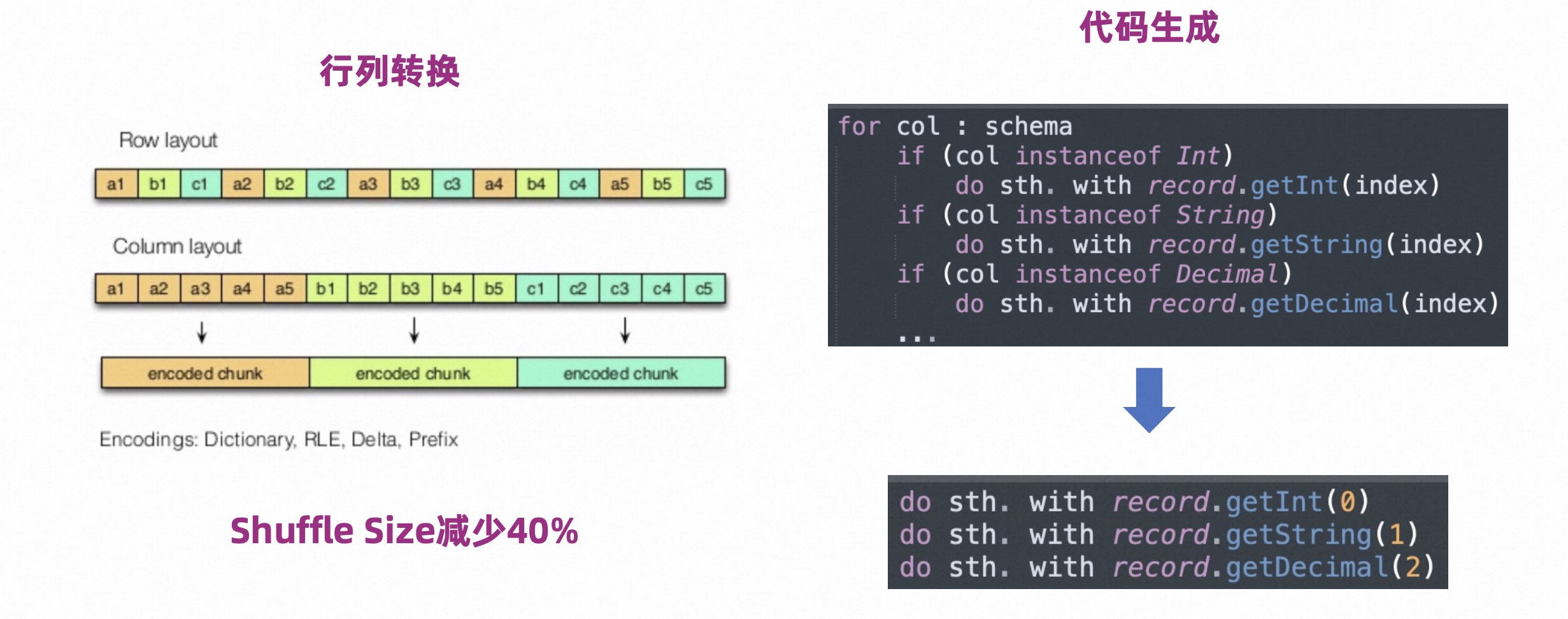
In order to reduce the interpretation execution overhead during row-column conversion, Celeborn introduced the Code Generation technology, as shown on the right side of the figure above.
2.4 Connecting to the vectorization engine
It is a current consensus that big data computing engines use Native vectorization to improve performance. Whether it is Spark or other engines, everyone is exploring in this direction.
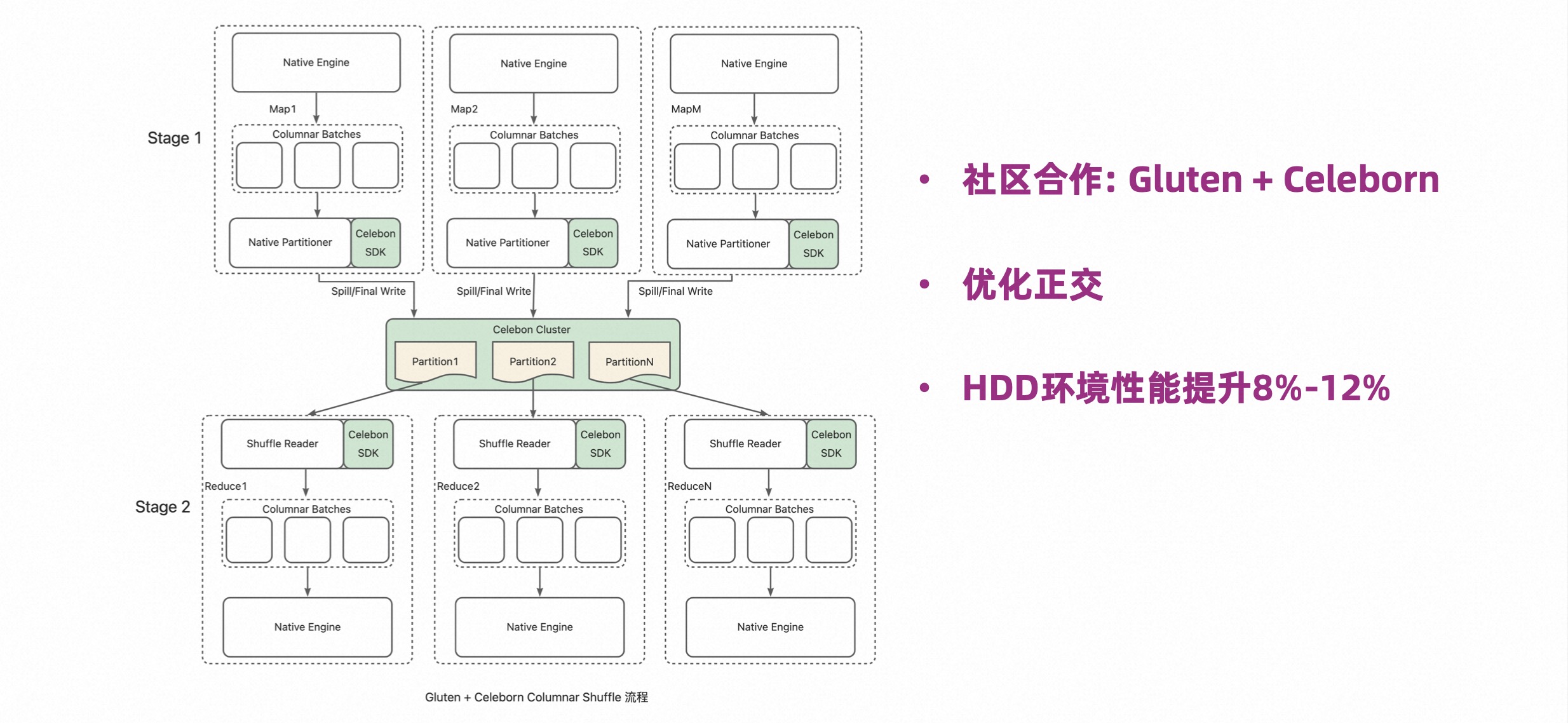
Gluten is a project jointly launched by Intel and Kirin, which allows Spark to integrate other Native engines. In addition, Gluten also does memory management and Native Shuffle. Its Native Shuffle is more efficient than the native Java Shuffle, but it follows the ESS framework, so it has the aforementioned limitations.
When the Celeborn community and the Gluten community cooperate, they can combine the advantages of the two, so that they can be optimized and orthogonal.
2.5 Multi-tier storage
Shuffles can be large or small. Small Shuffles need to go through a layer of network, and the efficiency is difficult to guarantee. Multi-tier storage is optimized from memory caching.
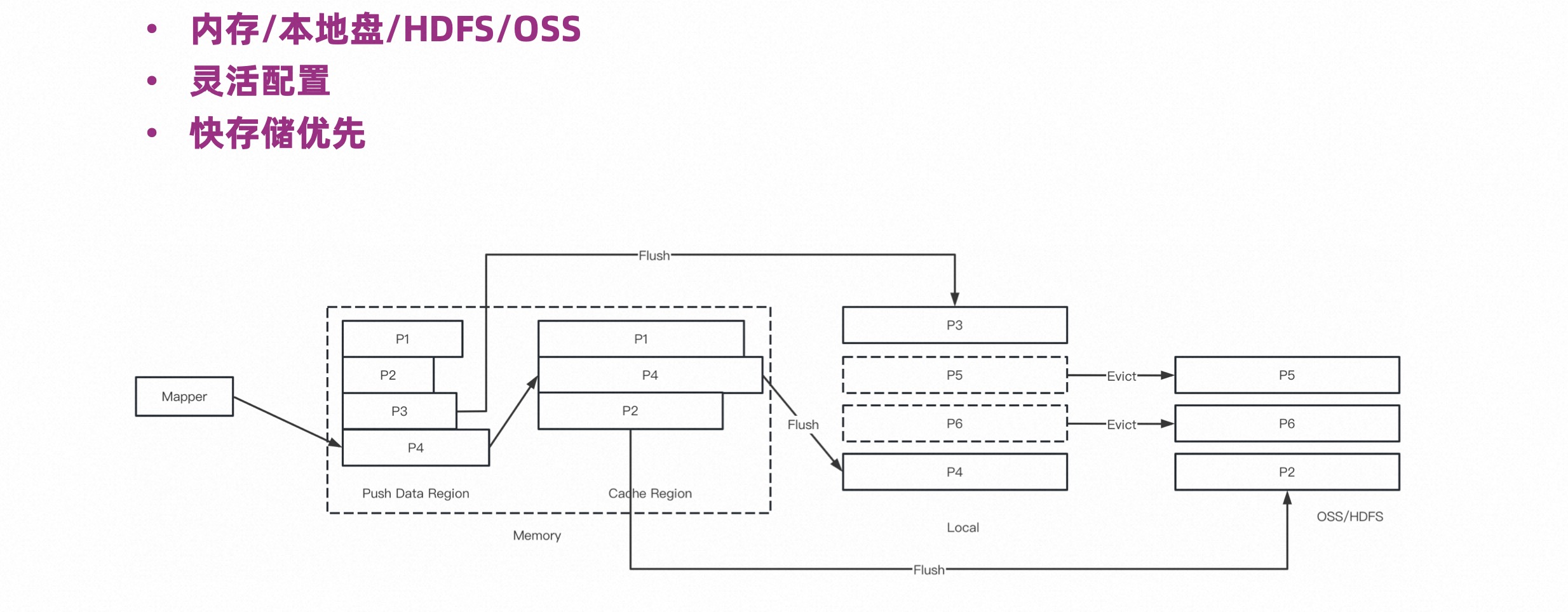
Multi-tier storage defines memory, local disk and external storage. External storage includes HDFS or OSS. The design concept is to store the entire life cycle of the small Shuffle in the memory as much as possible, and to store it on a faster disk as much as possible. .
3. Apache Celeborn——Stable
With the core design of Celeborn, the performance and stability of large Shuffle jobs have been greatly improved. The stability of the Celeborn service itself can be expanded from four angles:
-
fault tolerance
-
Quick rolling upgrade
-
Traffic Control
-
load balancing
3.1 Fault tolerance
As shown in the figure below, at the level of fault tolerance, we have done the following work:
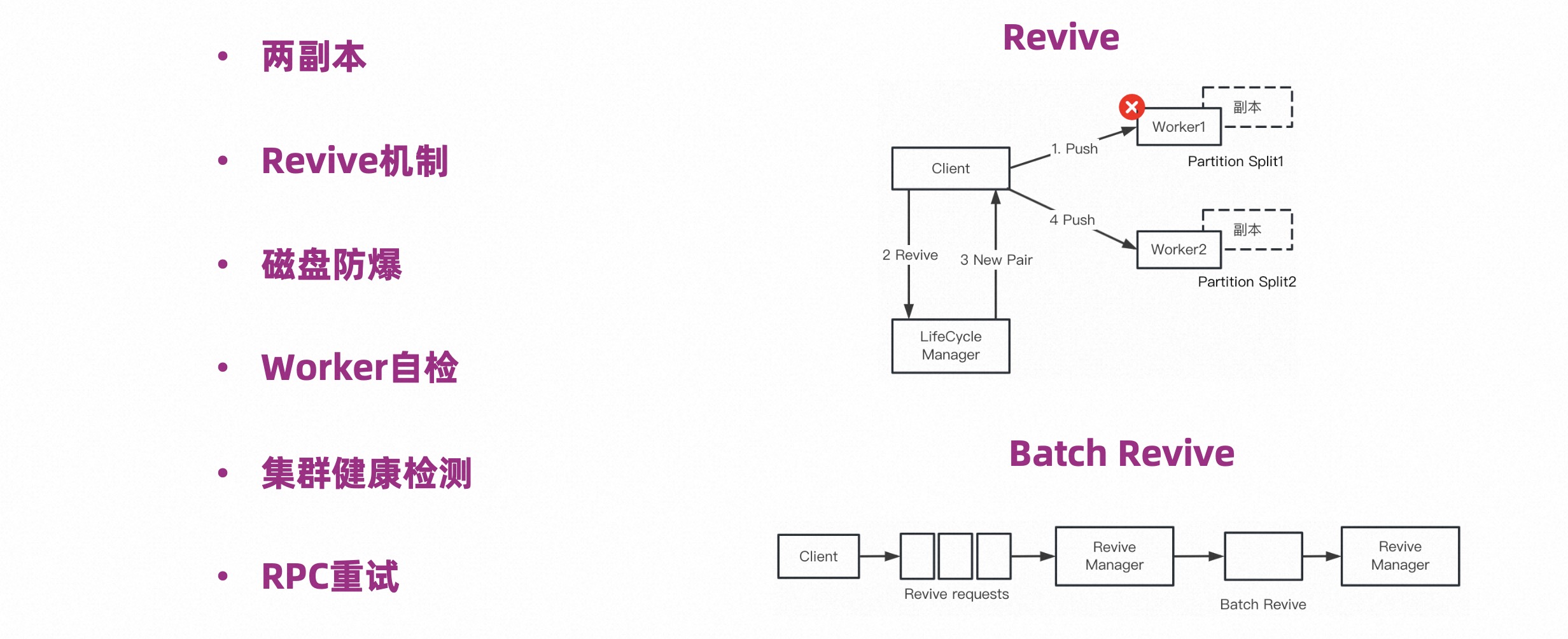
The Revive mechanism is described on the right side of the figure above. Client pushing data is the most frequent operation, and it is also the place where errors are most likely to occur. When the Push fails, we adopt a more tolerant strategy and regard the push as a temporary unavailability of the Worker. We only need to push future data to other Workers. This is the core of the Revive mechanism.
The Batch Revive below on the right is an optimization for the Revive mechanism. That is to say, when the Worker is unavailable, all data requests pushed to the Worker will fail, and a large number of Revive requests will be generated. In order to reduce the number of these requests, we batch Revive. After batching, they can be processed in batches. Handle errors.
As mentioned above about disk explosion-proof, we will detect the size of a single file and split it. In addition, it will also check whether the available capacity of the current disk is sufficient. If it is insufficient, Split will be triggered.
3.2 Rapid rolling upgrade
The figure below details how the rolling upgrade of Celeborn Worker is completed without affecting the currently running jobs.
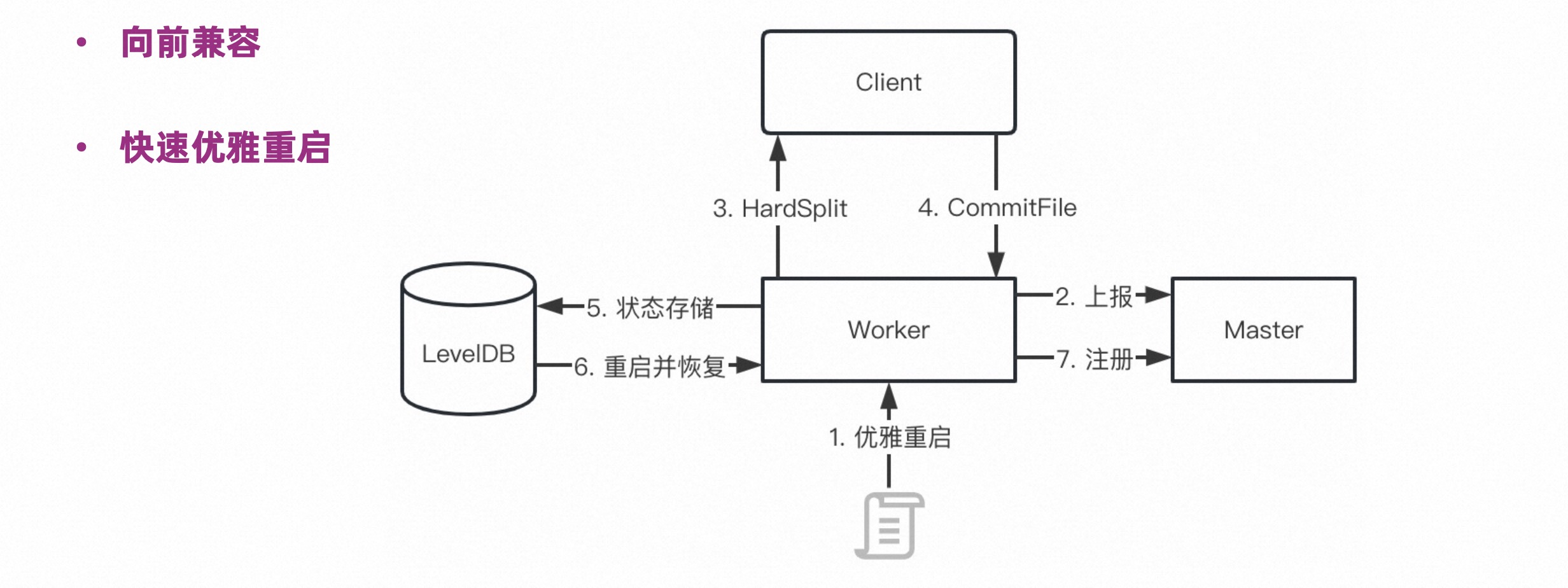
After the Worker triggers a graceful shutdown, it reports the status to the Master, and the Master will not continue to allocate load to the Worker. At the same time, the Partition request being served on the Worker will receive a HardSplit mark, and then trigger Revive, and the Client will no longer push data here. , and at the same time, a CommitFile will be sent to the Worker to trigger the flushing of memory data. At this time, the Worker will not receive new loads, old loads will not be pushed, and all data in the memory will be written to the disk. At this point, the Worker can exit safely after storing the memory state in the local LevelDB. After restarting, read the status from LevelDB and continue to provide services.
Through the above mechanism, rapid rolling upgrades can be achieved.
3.3 Traffic Control
The purpose of Traffic Control is not to exhaust the Worker's memory, nor does it want to exhaust the Client's memory. As shown in the figure below, three mechanisms are provided:
First, the counterpressure mechanism. From the perspective of the Worker, there are two sources of data. One is the data pushed to it by the Mapper, and the other is if two copies are opened, the master copy will send data to the slave copy.
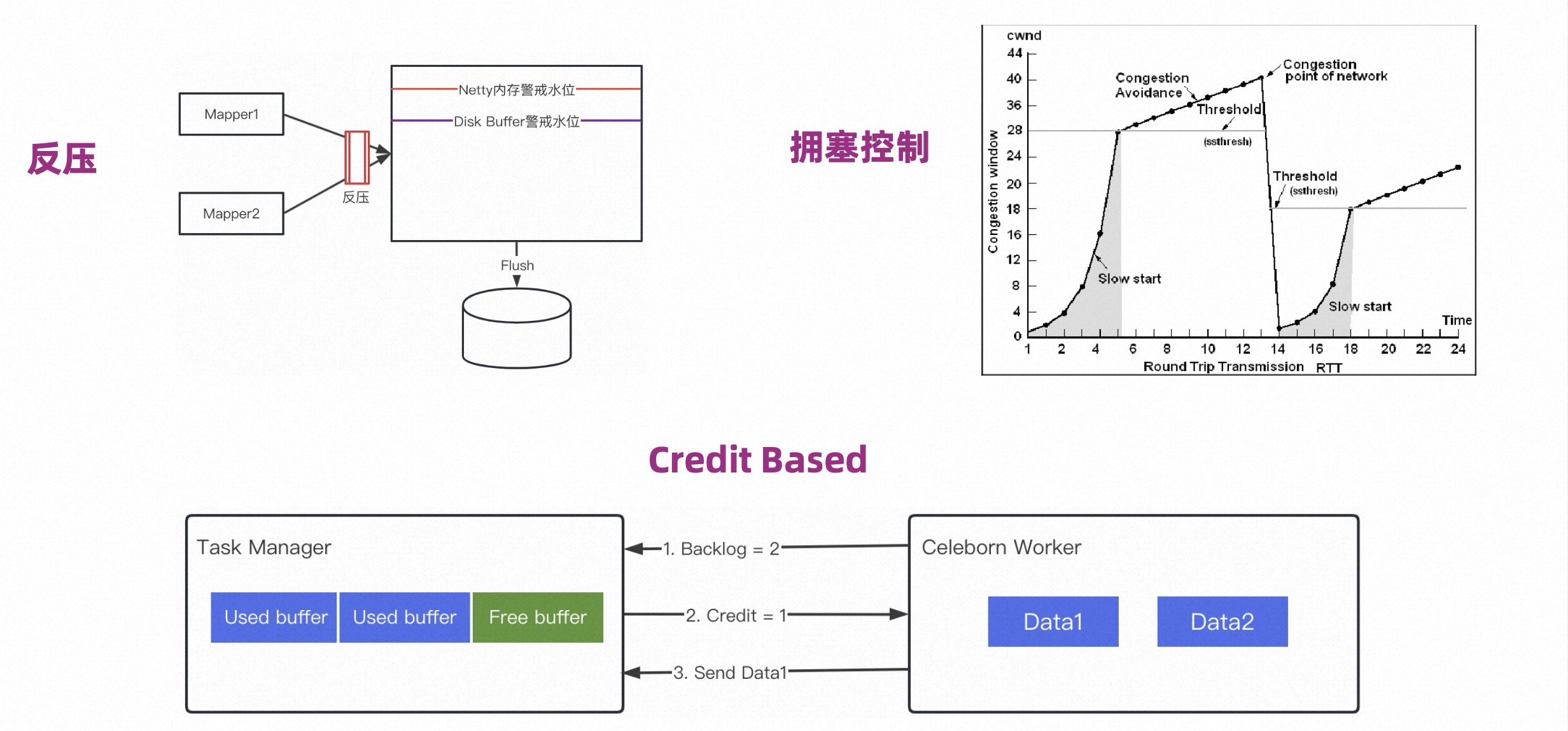
Then when the memory reaches the warning line, the data source will stop pushing data, and it will also need to "flood" to remove the memory.
Second, congestion control. The Shuffle Client uses TCP-like congestion control to proactively control the rate of pushed data to prevent instantaneous traffic from overwhelming the Worker memory.
In the Slow Start state at the beginning, the push rate is low, but the rate increases rapidly. When it reaches the congestion avoidance stage, the rate increase will slow down. Once it receives the congestion control signal from the Worker side, it will immediately return to the Slow Start state. The Worker side will record the amount of data pushed from each user or each job in the past period, and then decide who should be controlled by congestion.
Third, Credit Based. Used in Flink Read scenarios. During Shuffle Read, it is necessary to ensure that the read data is managed by Flink. To put it simply, the Worker needs to get the Credit before pushing the data to the Task Manager.
3.4 Load balancing
This mainly refers to disk load balancing, which is aimed at heterogeneous cluster scenarios.

In heterogeneous situations, the processing power, disk capacity, and disk health of machines are all different. Each Worker will self-check the health status and performance of the local disk and report the results to the Master so that the Master has a global view of the disk and can distribute load among these disks according to certain strategies to achieve better load balancing. .
4. Apache Celeborn——Bomb
There are three typical scenarios for using Apache Celeborn: complete co-location, independent deployment of Celeborn, and separation of storage and computing.
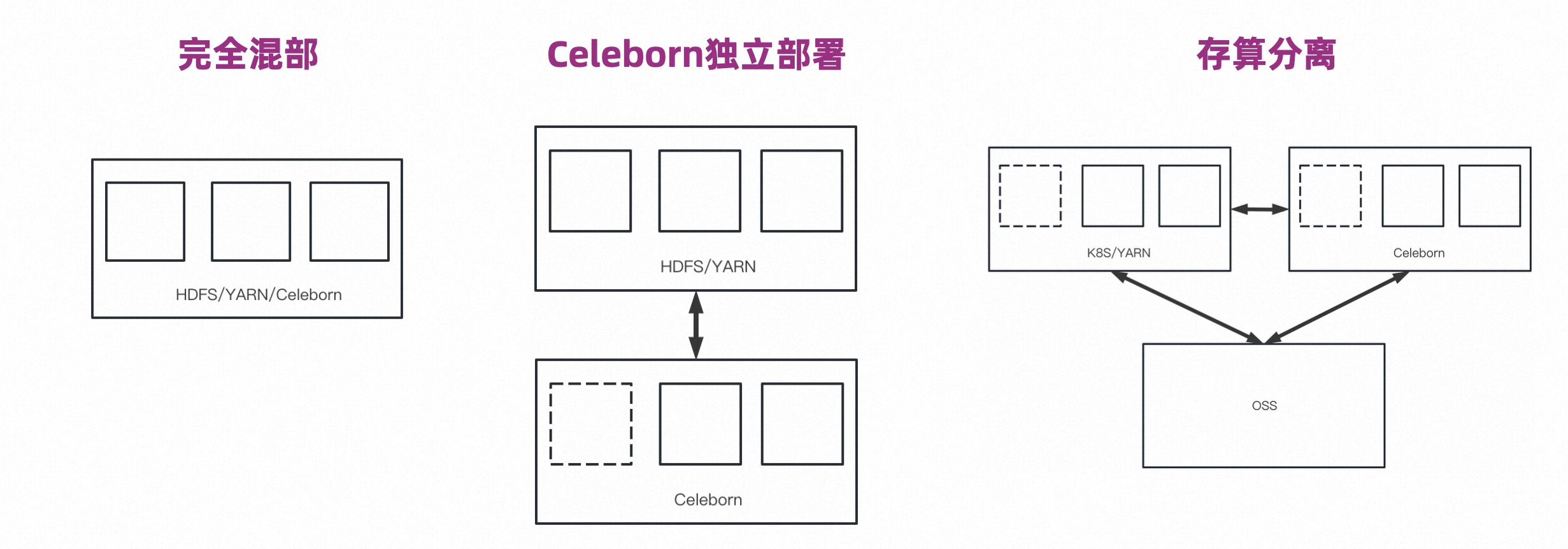
The benefits of complete colocation are mainly to improve performance and stability, but its resources are fixed, so it is difficult to achieve flexibility.
Celeborn is deployed independently. Celeborn's I/O and HDFS's I/O can be isolated to avoid mutual influence, and the Celeborn cluster has a certain degree of flexibility.
Storage and calculation separation, computing and storage are separated, and the Celeborn cluster is deployed independently. The computing cluster can achieve good elasticity because Shuffle becomes stateless. The Celeborn cluster itself also has elasticity capabilities, and the storage side can also charge according to the storage amount. So this is a cost-effective solution.
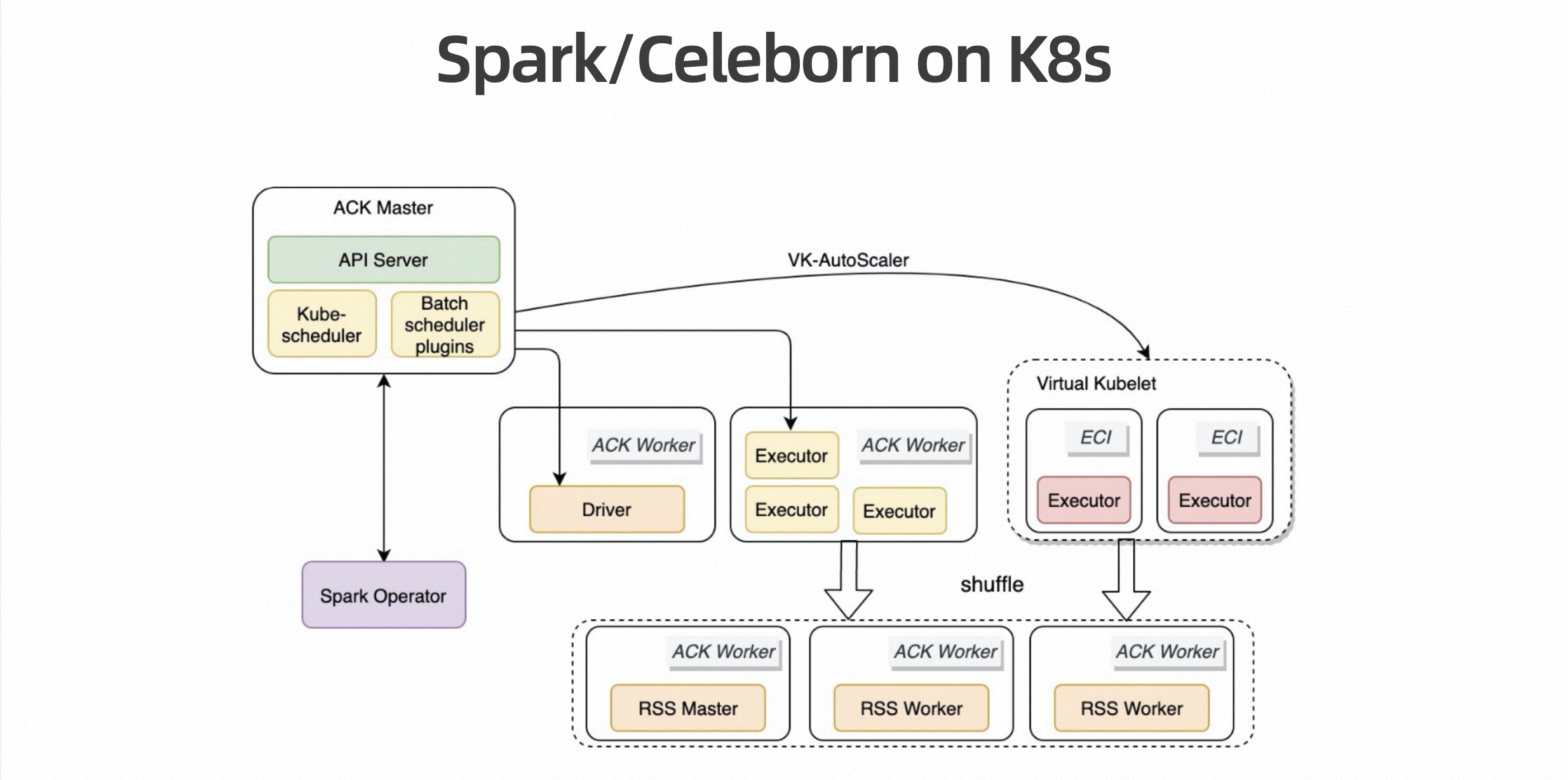
五、Evalution
5.1 Stability
- Spark big job
Scenario: Mixed method, using Spark on Yarn + Celeborn. 1,000 Celeborn Workers are deployed, but the worker resource usage is relatively small, the memory is about 30g, and the daily Shuffle data volume is several PB.
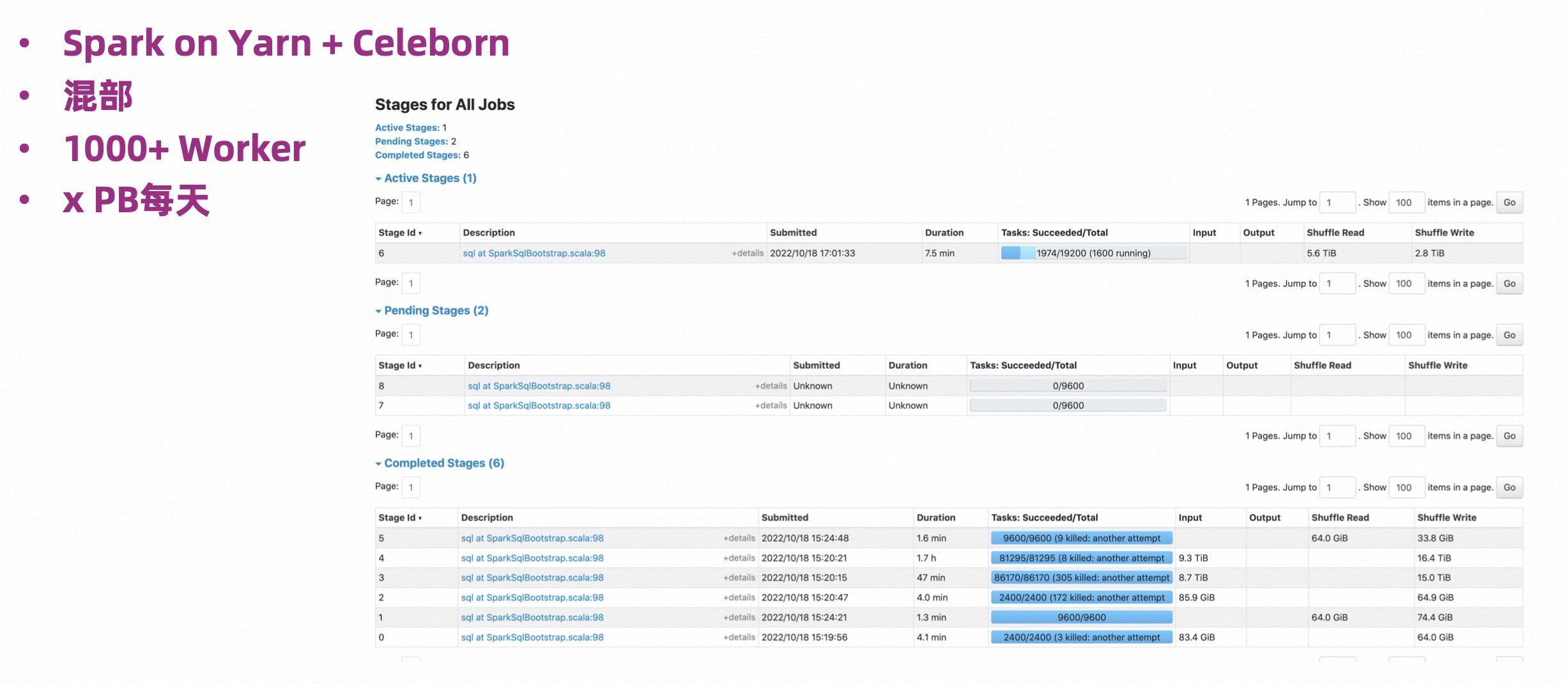
As can be seen from the above figure, this is a very typical large job, with tens of thousands of concurrent jobs, and it is still very stable during the operation.
- Flink big job
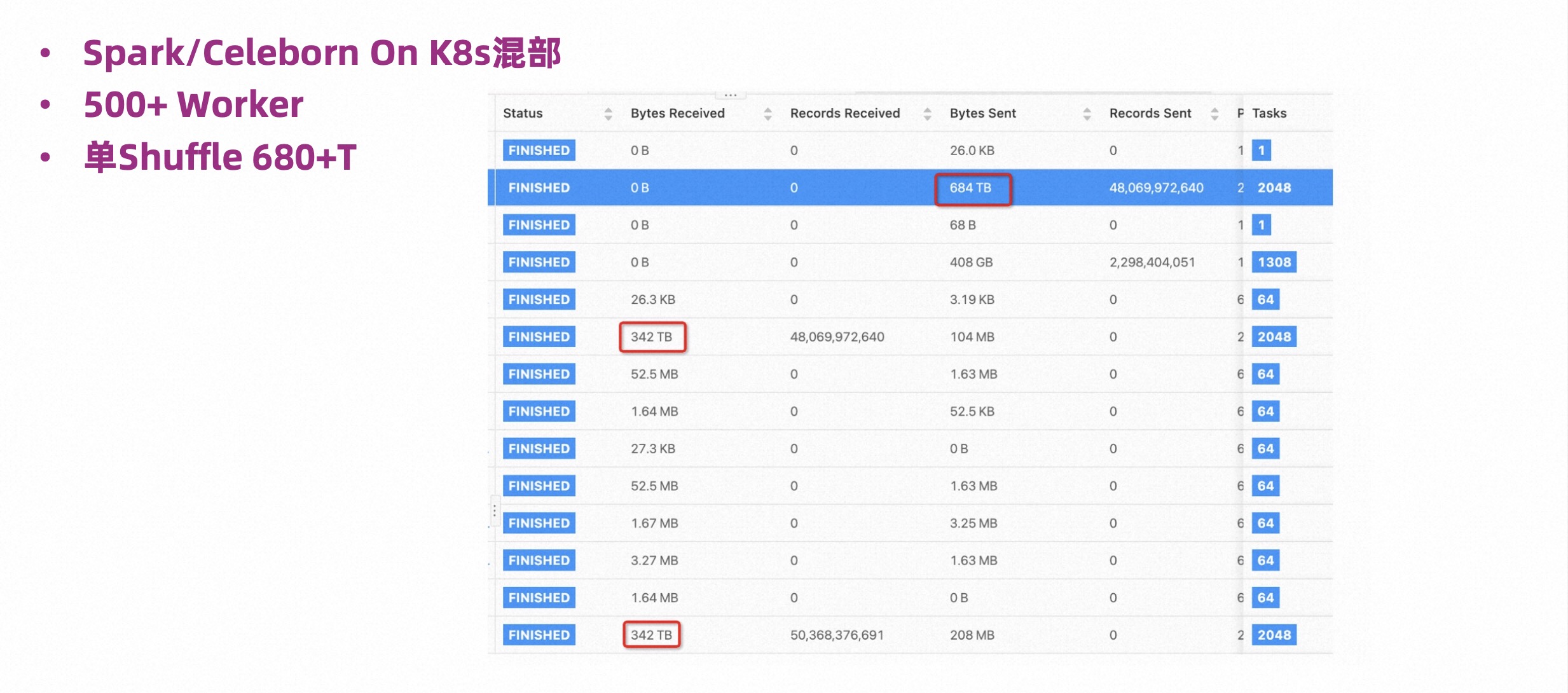
The picture below is a screenshot of Alibaba’s internal Flink Batch job. The deployment method is Flink on K8s + Celeborn On K8s. 500 Workers are deployed, and each Worker has 20G of memory.
This is also a very large job. You can see that a single Shuffle has 680TB, but the running process is also very stable.
5.2 Rolling restart
The figure below shows the rolling restart of the Worker while the job has been tested. Stop a Worker, wait for the process to exit, and then restart it. As can be seen from the time points in the figure below, it stopped at 19 minutes and 44 seconds, exited the job at 19 minutes and 53 seconds, restarted and completed registration at 20 minutes and 1 second, and continued to provide services. The entire process only takes 27 seconds, and the job is not affected at all.
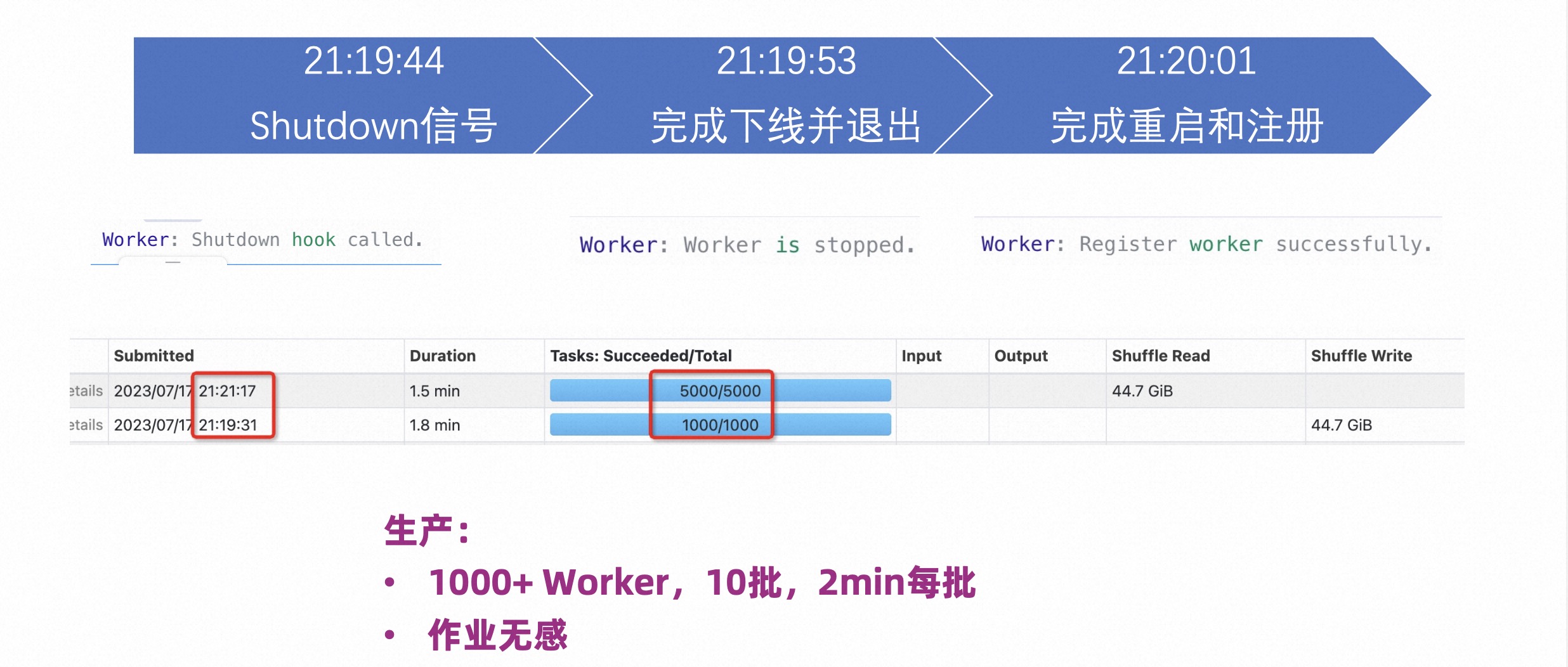
Another user performed a rolling restart upgrade in production, rolling restarted 1,000 Workers, and executed them in 10 batches. It was observed that a batch of restarts can be completed every 2 minutes, without affecting the job at all.
5.3 Performance
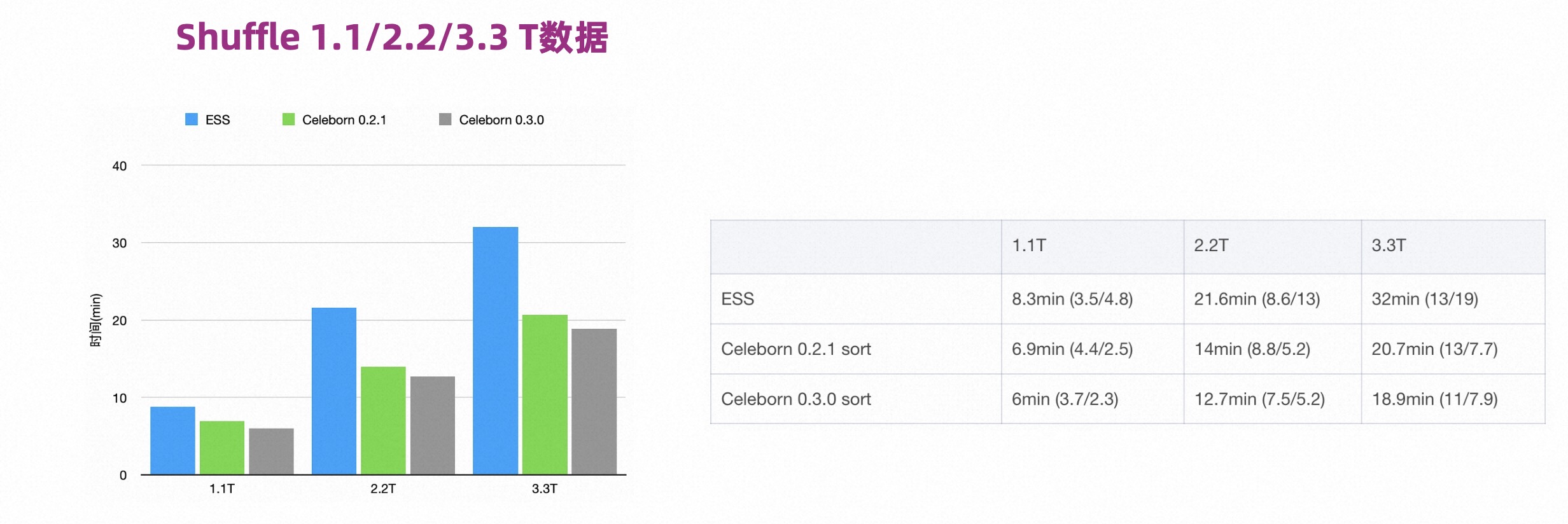
As shown in the figure below, Celeborn0.2 and 0.3 have obvious performance improvements compared to ESS. At the same time, version 0.3 has further performance improvements than version 0.2.
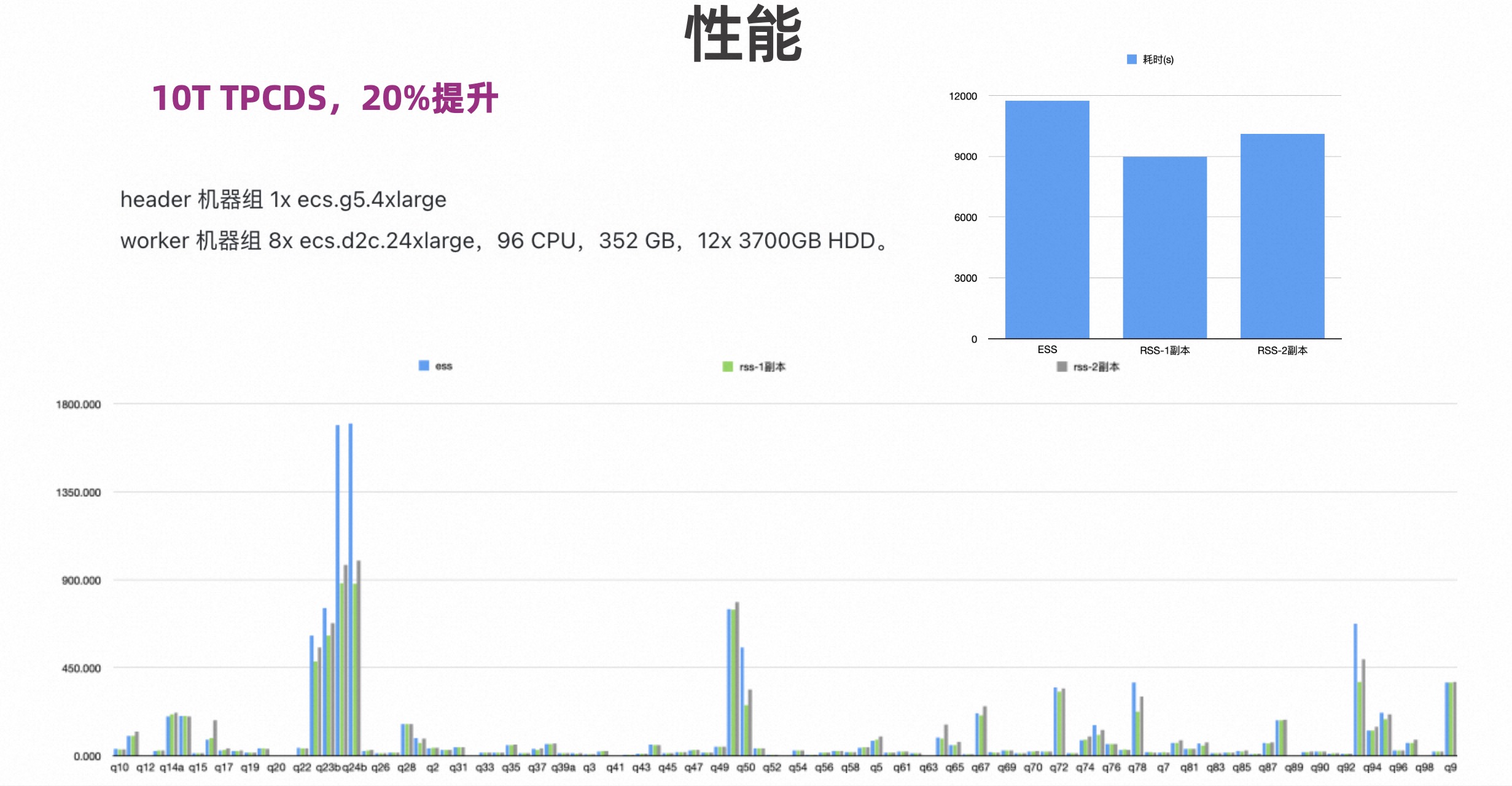
The picture below tests TPCDS, comparing ESS, Celeborn single copy and two copies. It can be seen that the performance of a single copy has been improved by more than 20%, and the performance of two copies has been improved by 15%.
5.4 Flexibility
As shown in the figure below, a storage-computing separation architecture is used to deploy 100 Workers. The computing is Spark On K8s, and tens of thousands of Pods can be scaled every day.

join us
-
DingTalk group: 41594456
-
Add friends to the group on WeChat: brick_carrier
-
WeChat public account: Apache Celeborn incubation
Q&A
Q: Would it be better to put the optimization methods mentioned above locally and achieve better results?
A: Spark has a LinkedIn-led Magnet optimization, but because Shuffle still uses Node Manage management, there will be some problems.
The first problem is that it cannot solve the problem of separation of storage and calculation; secondly, from a performance perspective, Magnet retains two methods. It retains writing local Shuffle and does Push Shuffle at the same time, that is, after asynchronously reading the local Shuffle file, Then push to the remote ESS instead of pushing while generating data.
This brings about a problem. When Shuffle ends, there is no guarantee that all data will be pushed to the remote end. In order to avoid excessive waiting time, it will forcibly interrupt the process. That is to say, part of the data is eventually pushed to the remote end, and part of it is not.
In this case, from the control logic point of view, when reading data, try to read the push shuffle first, and if not, read the local shuffle. This is a mixed process. There are overheads to this process.
Q: Will deploying Shuffle separately bring additional network overhead?
A: This is actually a matter of architecture choice. If you do not need to separate storage and computing, and do not need to elastically expand the computing cluster, but just to solve performance and stability problems, you can choose hybrid deployment. If computing flexibility is required, it is more likely to be deployed separately.
Q: During the execution of Spark, the Stage may fail. In this case, how to deal with it?
A: This is actually a question of data correctness. Spark Task recalculation will lead to the push of duplicate data, and Celeborn Client may also push data repeatedly.
First, Spark will record which attempt was successful, and Celeborn needs to get this information.
Second, each data pushed will have a Map ID, attempt ID and Batch ID. This Batch ID is the globally unique ID in the attempt. During Shuffle read, only the successful attempt data is read; secondly, for this attempt data, all previously read Batch IDs will be recorded. If previously read data is found, it will be ignored directly.
This ensures that neither data is lost nor duplicated.
Q: If Spark or Flink is used together with Celeborn, if a Spark task is submitted, will Celeborn itself take over the state during the intermediate Shuffle process, or can we directly use Celeborn to implement these functions?
A: This is a matter of usage. If you want to use Celeborn, you first need to deploy the Celeborn cluster; second, copy the Jar of the Celeborn client to the Jars directory of Spark or Flink; third, add some more parameters when starting the job. After completing these steps, you can use Celeborn normally.