What I want to share in this article is the basic content of C++. The birth of C++ is simply to fill the grammatical pit in the C language. At the same time, it adds many convenient grammatical rules compared to the C language. It is much more convenient to use than the C language. However, the learning difficulty is also greatly enhanced, but the difficulty increases linearly, and you can learn in depth step by step.
Table of contents
1.3 Namespace partial expansion
1.5 Namespace automatic merging
3.1 Simple use of default parameters
I won’t share too much about the history of C++ in this article. Those who are interested can learn about it on their own. Next, let’s start directly with the code.
First of all, what we want to celebrate is that when we use VS to create files, we no longer need to create .c files. We can directly create .cpp files.


We all know that .c files are created when we learn C language, and .cpp files are files created when learning C++. Because the syntax of C++ includes C language, you may not pay attention to the files when learning C language. suffix, but now that you want to study, you must understand these details with a rigorous attitude.
When we first came into contact with the C language, the first piece of code we typed was to print hello world.

Now let’s get started with C++. We also start by printing hello world. The following is C++ printing hello world.
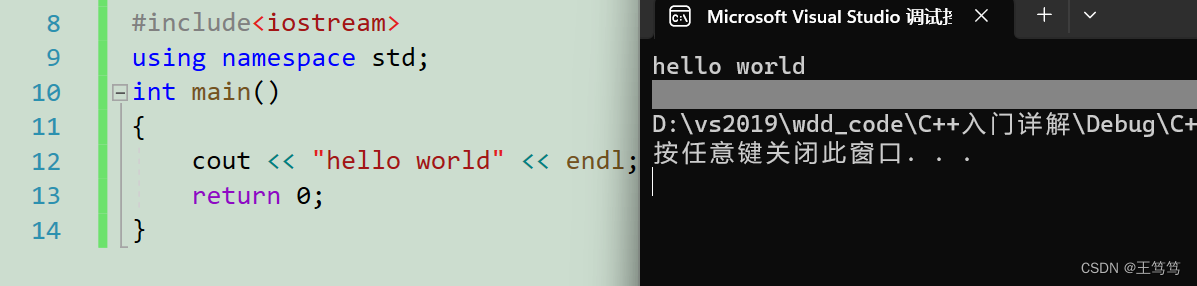
You can see that hello world is printed on the video screen;
This is what you need to focus on when getting started with C++: namespaces and io streams
Many of the grammatical rules of C++ are to fill in the holes left by the C language, that is, the unreasonable design of the C language, so we might as well explain the meaning of the above C++ code by comparing it with the C language;
1. Namespace
The following C language code
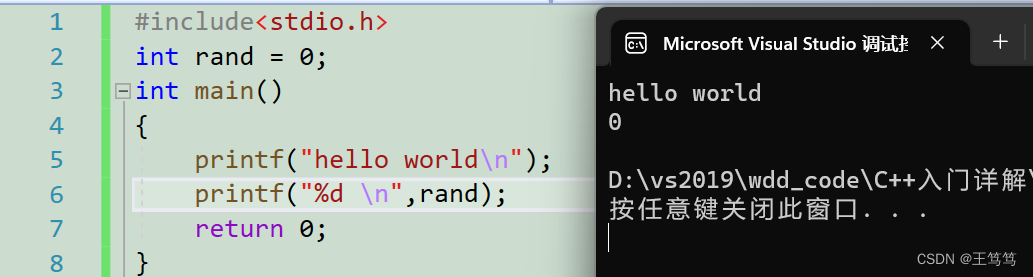
You can see that the integer rand is defined here, and it can be printed out smoothly, but if we do a little manipulation

You can see that we cannot print if we include a stdlib header file. This is a flaw of the C language.
1.1 Namespace specified use
C language faces the problem of naming conflict , because the stdlib header file also contains a function named rand. Faced with such a situation in C language, we can only change the rand defined by ourselves to other names. At work If a colleague in the same group uses the same variable name as you, you can only decide who changes the name.
However, there is an updated usage in C++, which is namespace. The usage is as follows
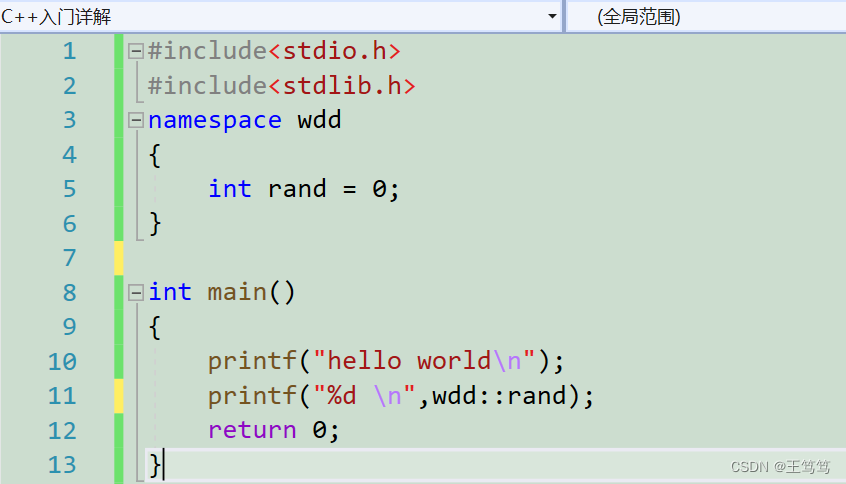
We can use namespace+naming to create a namespace and isolate the global variables in the header file from the variables defined by ourselves, so that there will be no naming conflicts. Similarly, when we need to access the data in the namespace, we need to do as shown above. Use space name:: to access, otherwise the global variable will be accessed, so there is a new symbol in C++: scope qualifier::
In fact, the namespace can be understood abstractly as a small house in the square. If you need to access the variables, functions or structures in the namespace, you need to use scope qualifiers to access them, just like the key to the small house.
After a brief understanding of how to use namespaces, let’s take a look at his other ways to play.
namespace wdd
{
int rand = 0;
int Add(int x, int y)
{
return x + y;
}
struct wdd
{
struct Node* next;
int val;
};
}
int main()
{
struct wdd::Node node;
printf("%d \n", wdd::rand);
printf("%d \n", wdd::Add(1,2));
return 0;
}As shown in the above code, in fact, the namespace can also contain many things. If you need to access the data in the namespace, you need a "key" to access it. At the same time, you must also pay attention to the definition method of the structure type.
We also defined the Add function in the namespace at the same time
namespace wdd
{
int rand = 0;
int Add(int x, int y)
{
return x + y;
}
}
int Add(int x, int y)
{
return (x + y)*10;
}
int main()
{
printf("%d \n", wdd::rand);
printf("%d \n", wdd::Add(1,2));
printf("%d \n", Add(1, 2));
return 0;
}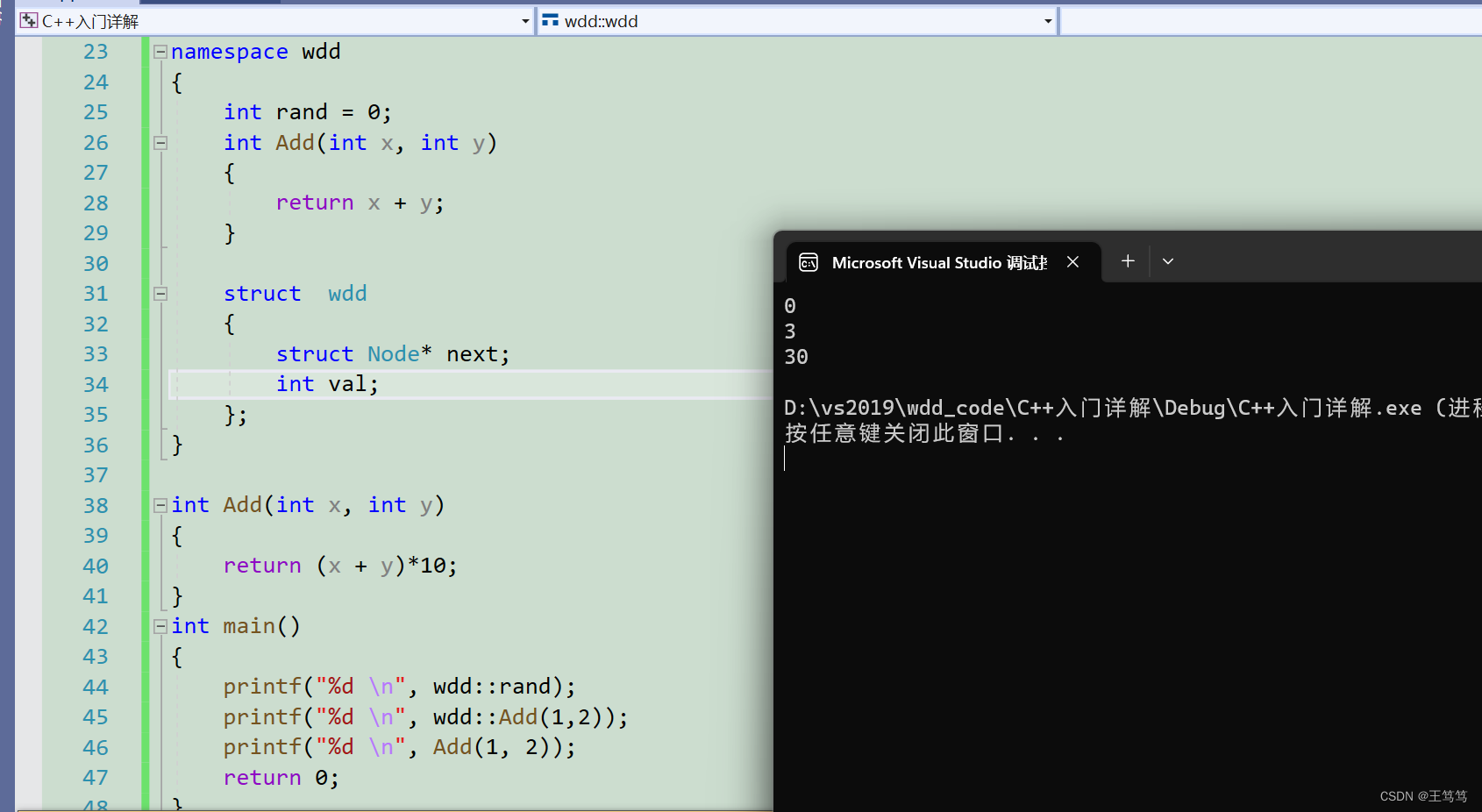
It can be seen that functions that do not operate through domain scope qualifiers will call the Add function of global variables.
1.2 Expand all namespaces
It's a bit troublesome to use the domain scope operator once to use it like above. Is there a more convenient method?
We can expand the scope directly, as follows
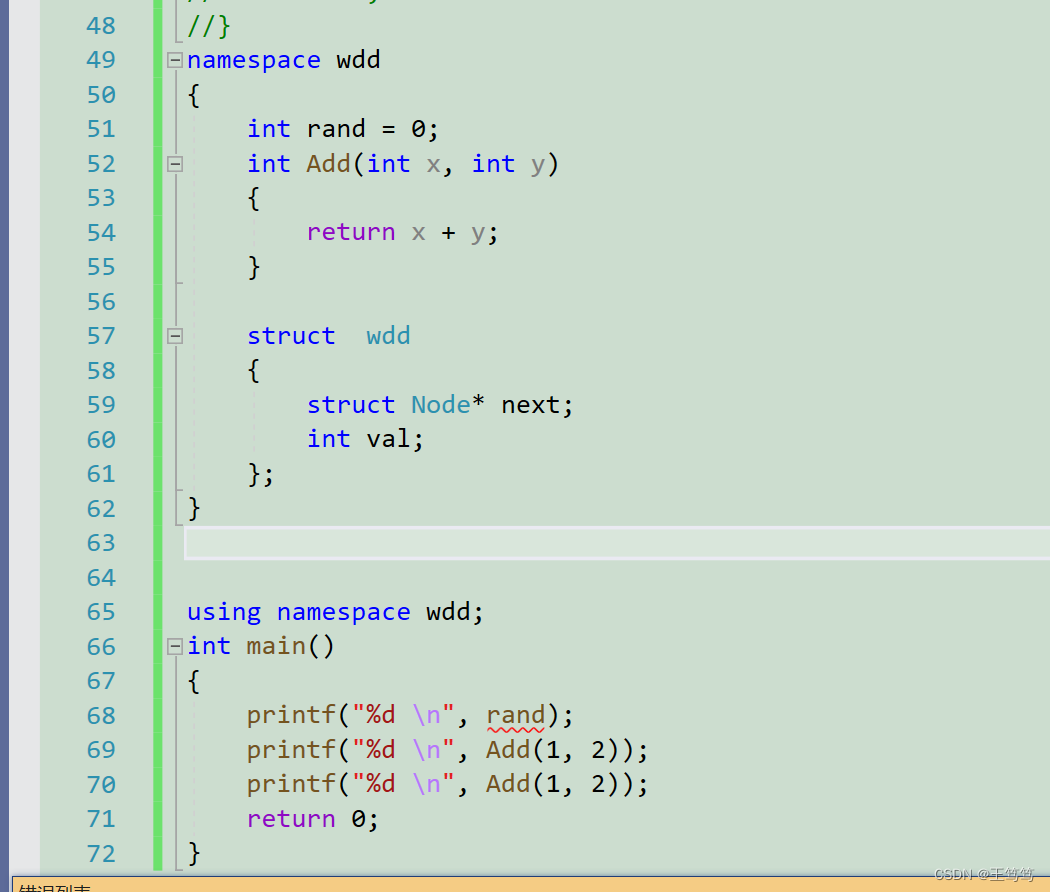
We can use using namespace+space name directly outside the namespace to expand all corresponding space names .
Such an operation means demolishing the small house in the square, and all resources in the small house will become public, so the operation of expanding the namespace is very dangerous.
After expanding the namespace, you can see that an error has occurred with rand, because it is not known whether the rand in the header file or the rand in the namespace is being called.
1.3 Namespace partial expansion
Another way is to use the environment. If we want to call functions or variables in the namespace multiple times, there is another method as follows:
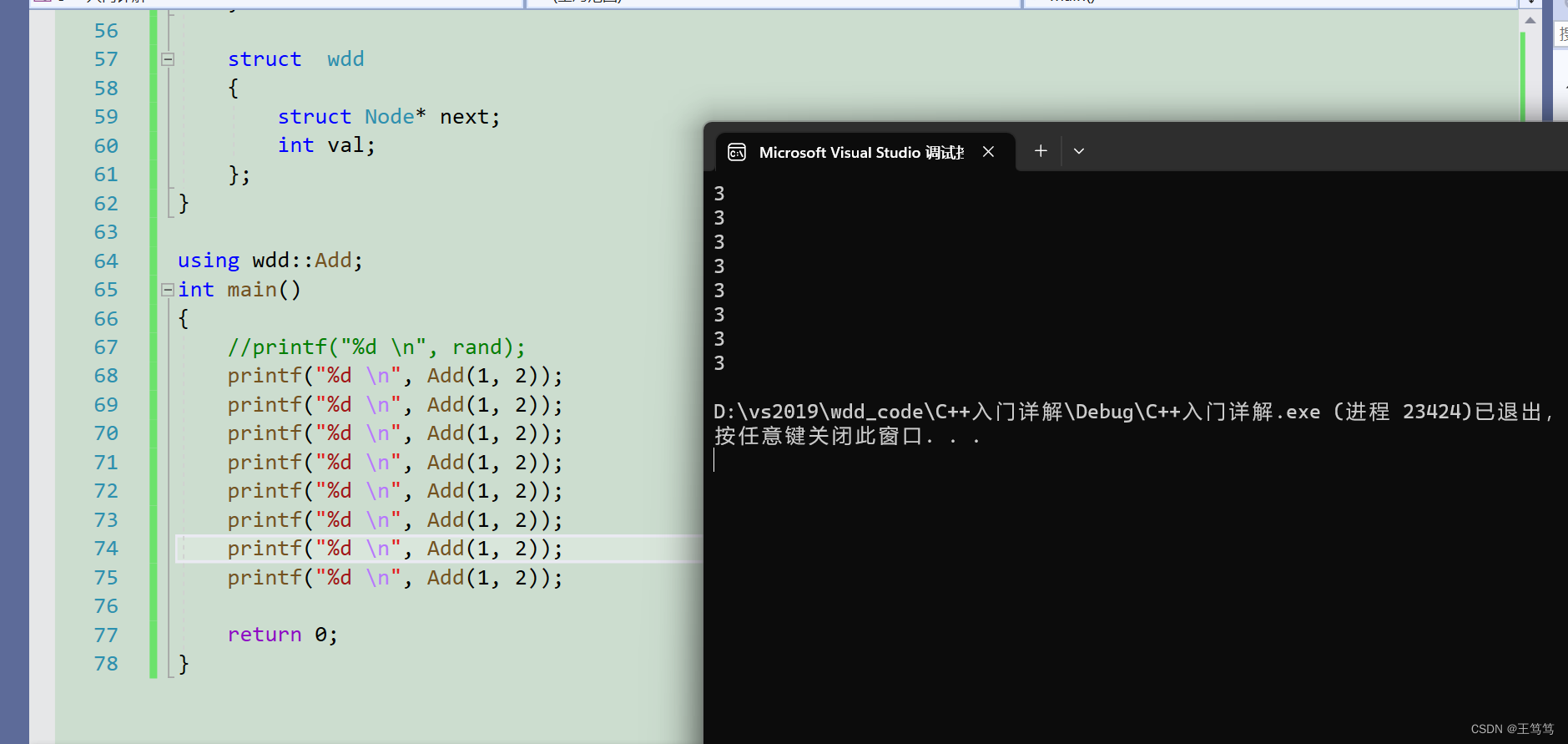
When using it, you can specify functions or other data in the expansion namespace, and you can directly call the functions inside. We call it partial expansion.
1.4 Namespace nesting
Namespaces can also be nested using the following code
namespace wdd
{
int rand = 0;
int Add(int x, int y)
{
return x + y;
}
struct wdd
{
struct Node* next;
int val;
};
namespace zmj
{
int rand = 1;
}
}
int main()
{
printf("%d \n", wdd::zmj::rand);
}
The running result is as shown in the figure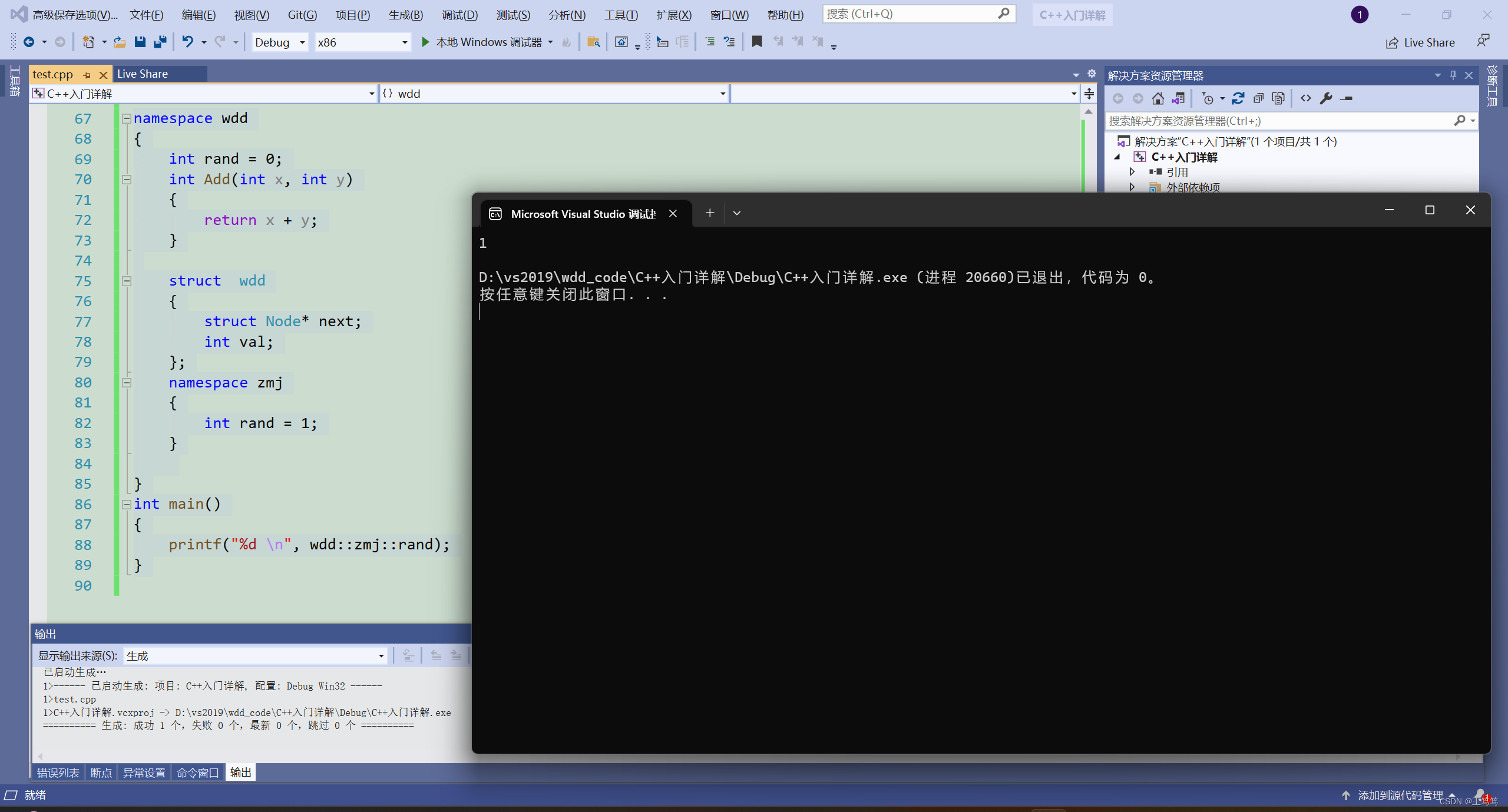
This is the use of namespace nesting.
Then let’s go back and look at the code that uses C++ to print hello world
#include<iostream>
using namespace std;
int main()
{
cout << "hello world" << endl;
return 0;
}Obviously using namespace std is to expand the std namespace. std is the namespace of the C++ standard library, in order to prevent conflicts with self-defined variable names.
In the same way, cout can only be used when std is expanded. We can also use cout in the following ways:
1. Partially expand
#include<iostream>
using std::cout;
using std::endl;
int main()
{
cout << "hello world " << endl;
return 0;
}2. Specify expansion
#include<iostream>
int main()
{
std::cout << "hello world " << std::endl;
return 0;
}Through the above learning, we can use these methods to expand std and print hello world.
1.5 Namespace automatic merging
If we define a namespace with the same name, the compiler will automatically merge the namespaces with the same name, as follows:
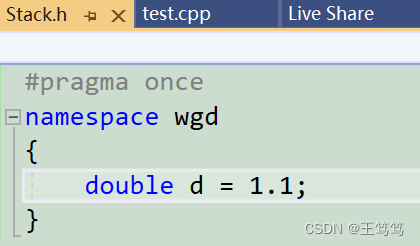
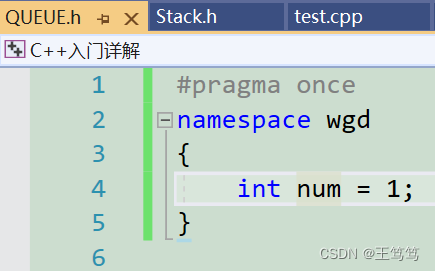
You can see that namespaces with the same name are defined in two different header files, which means that multiple namespaces with the same name will not conflict.
2. About cout and endl
Because the detailed implementation of cout and endl is about classes and objects, here is a brief introduction to their use;
In cout and endl, the c in cout means console, which means console. Then cout means output on the console, which is the black box printed out. endl means line break and has the same purpose as \n
cout << "hello world" << endl;The << symbol is a stream insertion input symbol, so the meaning of the above code is very vivid: hello world flows to cout and is output;
In the same way, when there is insertion, there is extraction. >> is called stream extraction and is usually used with cin.
int i=0;
std::cin>>i;What this means is to enter i.
The important thing here is that cout and cin can automatically identify the type, which printf and scanf cannot do;
#include<iostream>
using namespace std;
int main()
{
int i = 0;
double j = 0;
cin >> i >> j;
cout << i << endl;
cout << j << endl;
return 0;
}
You can see that i and j can automatically identify the type after testing.
3.Default parameters
3.1 Simple use of default parameters
Go directly to the code to explain the grammar rules
#include<iostream>
using namespace std;
void Func(int a = 1)
{
cout << a << endl;
}
int main()
{
Func(2);
Func();
}The default parameter is to add the default value when defining the function parameters. As shown in the above code, you can see that the integer is defined and assigned a value in the parameter when defining the function;
When we use it in the main function, we can pass parameters or not; the following are the running results
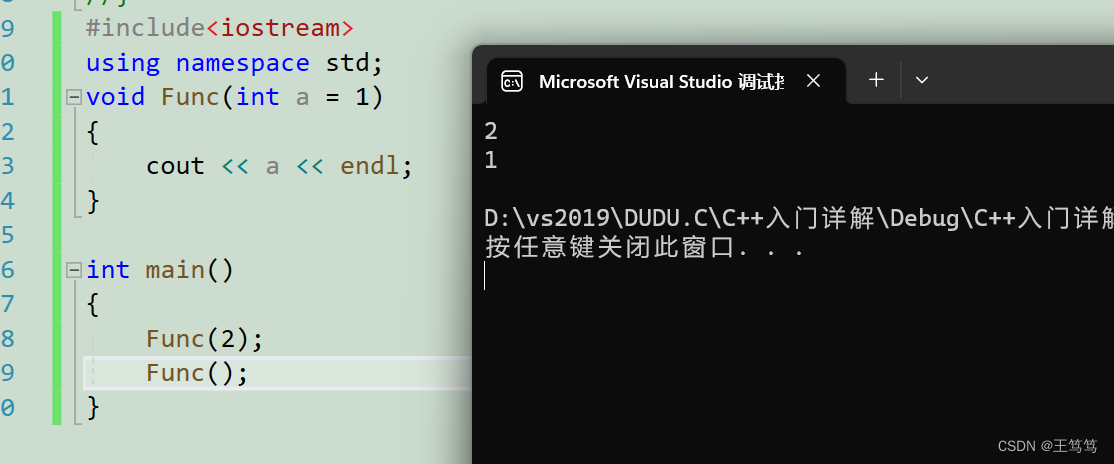
You can see that when we call a function, if we pass in parameters, the function will use the parameters we passed in; if we do not pass in parameters, the function will use the default parameters.
3.2 All default parameters
You can also define multiple default parameters for various ways of playing.
#include<iostream>
using namespace std;
void Func(int a = 1, int b = 2,int c=3)
{
cout << a << ' ' ;
cout << b <<' ';
cout << c << endl;
}
int main()
{
Func();
Func(10);
Func(10,20);
Func(10,20,30);
}The running results are as follows
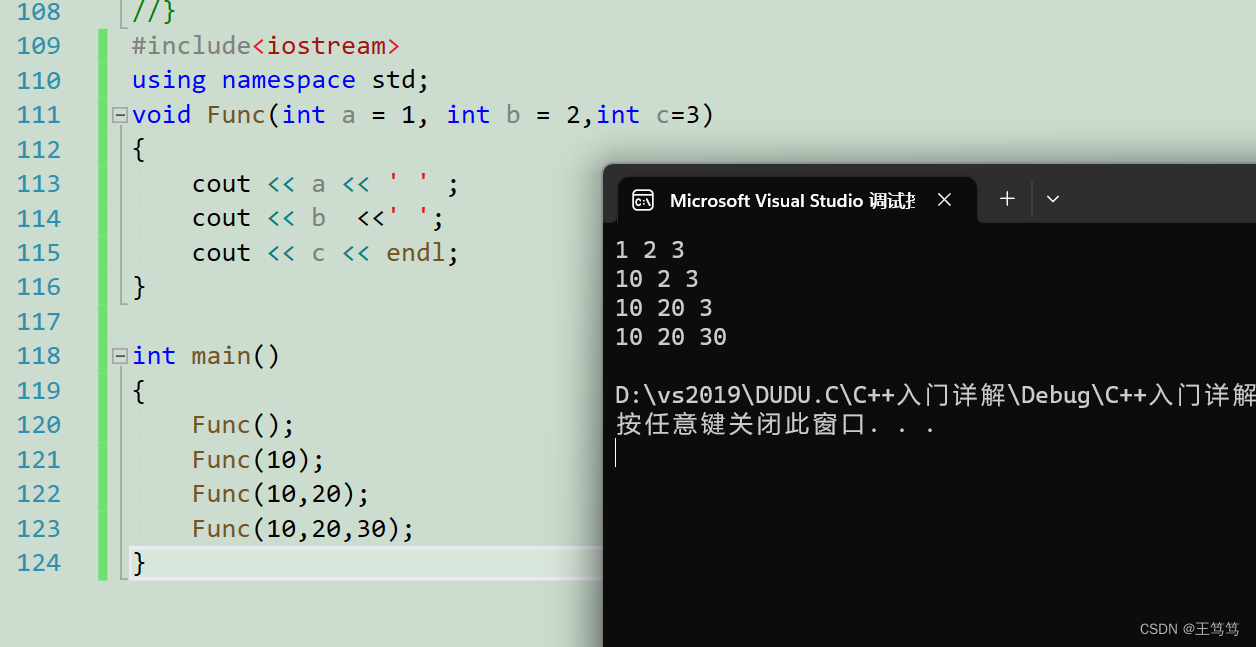
However, it should be noted that parameters cannot be passed at intervals.
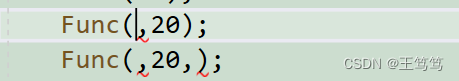
Passing parameters in this way will not only call the second parameter, and passing parameters in this way is against the rules.
3.3 Semi-default parameters
Similar to full default, semi-default is partial assignment when defining a function.
void Func(int a , int b = 2, int c = 3)
{
cout << a << ' ';
cout << b << ' ';
cout << c << endl;
}Semi-default parameters can only give default values from right to left, and if no default value is given in the function, the parameters must be passed when calling the function.
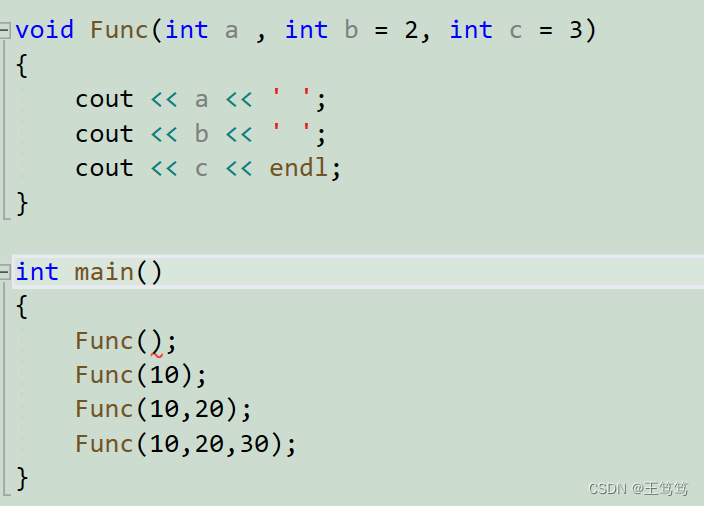
Otherwise, an error will be reported.
It should also be noted that the definition and declaration of default parameters cannot be separated. The following code example is used
First we define the default parameters in the .cpp file
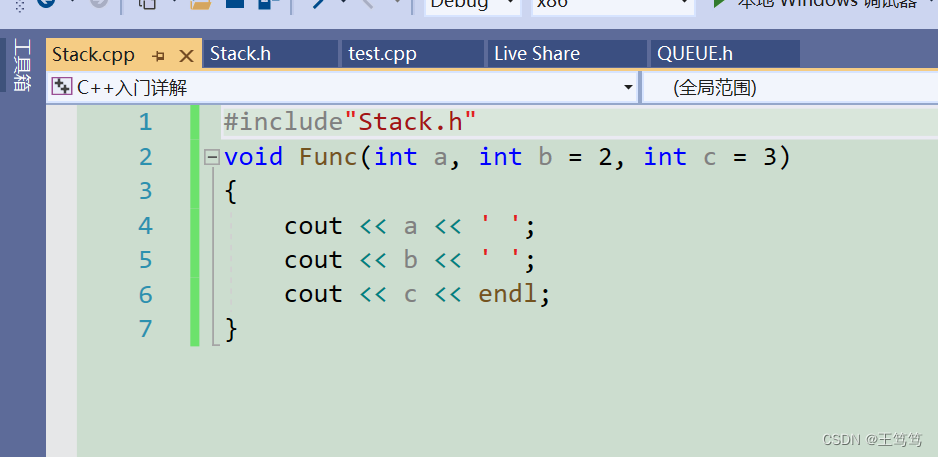
Let’s add a statement to the header file
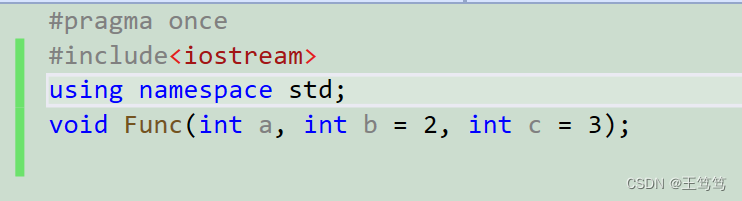
Continue testing in the main function
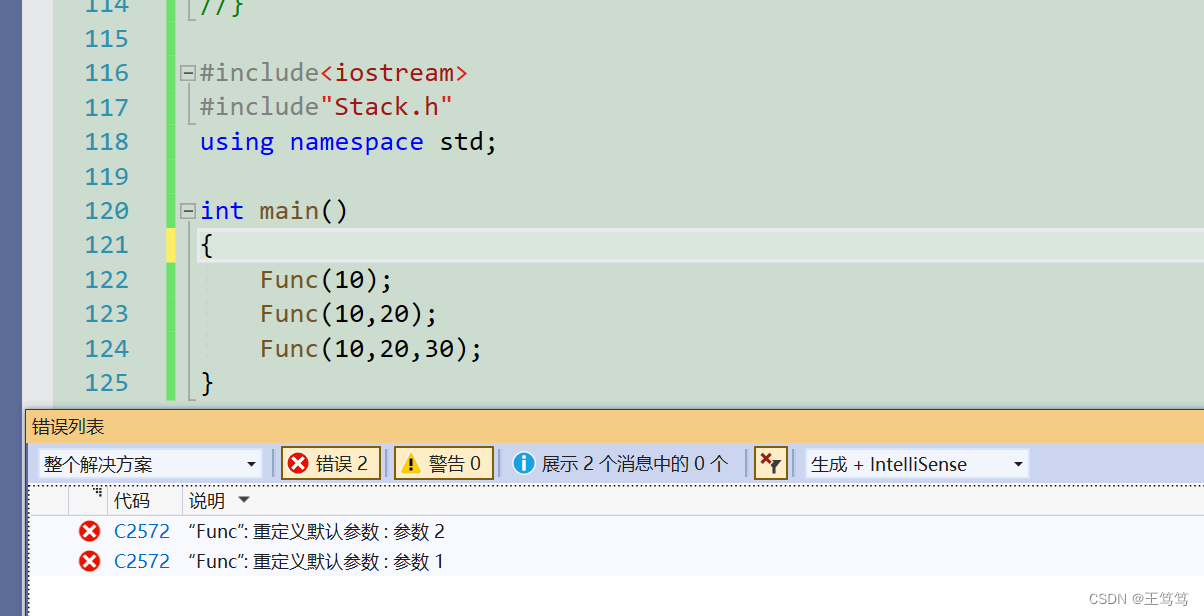
You can see that an error is reported. The reason is very simple: when the compiler calls a function, it cannot determine whether it is calling the default value in the declaration in the h file or the default value in the .cpp file. If the function declared and defined is default If the values are not the same, conflicts will occur.

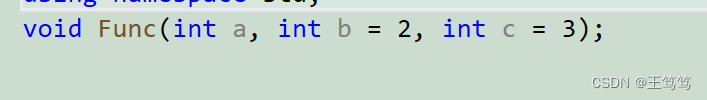
It can be seen that the above situation occurs when declaration and definition are separated.
Therefore, declaration and definition are not allowed to give default parameters at the same time.
4. Function overloading
First of all, we need to know what overloading means. In terms of language learning, overloading means a word with multiple meanings. There was a joke before that there are two sports in China that you don’t need to read at all. One is table tennis and the other is football; table tennis No one can beat it, no one can beat football, this sentence constitutes an overload;
Function overloading: It is a special case of functions. C++ allows you to declare several functions of the same name with similar functions in the same scope.
These different formal parameter lists (number of parameters or types or type order). It is commonly used Handles the problem of implementing functionally similar data types
but with different ones.
Similarly, C language does not support functions with the same name, but C++ does, but it requires overloading (same function name, different parameters).
Directly explain the code
#include<iostream>
#include"Stack.h"
using namespace std;
int Add(int x, int y)
{
cout << "int Add(int x, int y)" << endl;
return x + y;
}
double Add(double x, double y)
{
cout << "double Add(double x, double y)" << endl;
return x + y;
}
int main()
{
cout << Add(1, 2) << endl;
cout << Add(1.1, 2.2) << endl;
}The following is the running result

You can see that types can be automatically identified in C++, which is much more convenient than C language.
In addition to the above different parameter types, there are also the following situations that can also constitute overloading
// 2、参数个数不同
void f()
{
cout << "f()" << endl;
}
void f(int a)
{
cout << "f(int a)" << endl;
}
// 3、参数类型顺序不同
void f(int a, char b)
{
cout << "f(int a,char b)" << endl;
}
void f(char b, int a)
{
cout << "f(char b, int a)" << endl;
}However, it should be noted that if the return value is different, it cannot constitute an overload.
Another situation is functions in different scopes. The situation is as follows
Likewise, this cannot constitute overloading of the function because their scopes are different. In the interpretation of the concept, different scopes cannot constitute function overloading.
The above is what I want to share in this video. There will be more C++ learning content in the sequel. If it is helpful to you, please support me three times. Thank you for reading.