This paper proposes an effective training strategy and lightweight pre-processing model to solve the pre-processing problem of traditional video encoders. After testing, it can achieve certain gain effects on H.264, H.265 and H.266.
introduction
Over the past few decades, many advances have been made in the field of video compression, including traditional video codecs and deep learning-based video codecs. However, few studies focus on using pre-processing techniques to improve rate-distortion performance. In this paper, we propose a rate-aware optimized pre-processing (RPP) method.
We first introduce an adaptive discrete cosine transform loss function that can save bitrate and maintain necessary high-frequency components. Furthermore, we incorporate several state-of-the-art techniques in the field of low-level vision into our approach, such as high-order degradation models, efficient lightweight network design, and image quality assessment models. By using these powerful techniques together, our RPP method can work on different video encoders such as AVC, HEVC and VVC, saving an average of 16.27% in bit rate compared to these traditional encoders.
During the deployment phase, our RPP approach is very simple and efficient and does not require any changes to the settings for video encoding, streaming, and decoding. Each input frame only needs to go through RPP once before entering the video encoder. Additionally, in our subjective visual quality tests, 87% of users rated videos using RPP as better or equal to videos compressed using only the codec, and these videos using RPP achieved an average bitrate savings of about 12% . Our RPP framework has been integrated into the production environment of our video transcoding service, serving millions of users every day. Our code and models will be released after the paper is accepted.
method
overall framework

The left side of the figure above shows the workflow of the preprocessor in this article: single-frame processing of input frames, applicable to all standard video codecs. Right: The code rate difference between H.265 and RPP + H.265 under the same MS-SSIM.
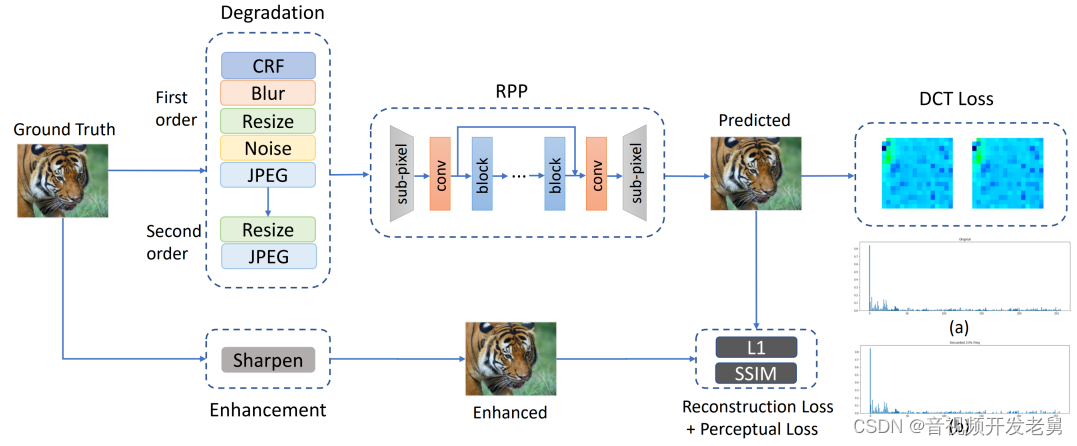
The goal of our pre-processing model is to provide an input frame that is simultaneously optimized in terms of bitrate and perception through a learnable pre-processing neural network. Specifically, to achieve an optimal balance of the model between code rate and distortion, we design an adaptive DCT loss that can reduce spatial redundancy and preserve key high-frequency components in perception. On the other hand, for the perceptual optimization part, we aim to perceptually enhance our pre-processed input frames by using MultiScale-SSIM. We use this as the loss function during training. Furthermore, we incorporate a high-order degradation modeling process to simulate real-world complex degradations. By using this high-order degradation method to generate training data pairs, our pre-processing network can be trained to handle some complex degradations in the real world, thereby improving the perceptual quality of the network output. Furthermore, for performance and efficiency, we build a lightweight fully convolutional neural network that incorporates a channel attention mechanism. In the deployment framework, for a given video frame

Second-order Degradation
The way the degradation of training data is modeled is very important to improve the visual quality during network training. We include some common degradation methods into our degradation model, such as blurring, noise, resizing, and JPEG compression. For blur, we use isotropic and anisotropic Gaussian filters to model blur degradation. We selected two commonly used noise types, namely Gaussian noise and Poisson noise. For resizing, we used upsampling and downsampling, including area, bilinear, and bicubic interpolation. Since in real applications, the input frames of our framework are mostly decoded from compressed videos, we add video compression degradation, which may introduce blocking and ringing artifacts in both spatial and temporal domains. As we mentioned before, higher-order degradation modeling has been proposed to better simulate complex real-world degradations. We also use this idea in our image degradation model. By using these degraded models to generate training pairs, we aim to equip the models with the ability to remove common noise and compression noise, which can also optimize bitrate since video codecs do not encode noise well.
DCT Loss
Although many years have passed since DCT was first introduced in image/video compression algorithms, DCT-like transformations are still mainstream transformations due to their efficiency and ease of use. Generally speaking, the basis function of two-dimensional DCT can be expressed as:

In an image, most of the energy will be concentrated in lower frequencies, so in traditional compression algorithms, they simply discard higher frequency coefficients to reduce spatial redundancy. However, some high-frequency components also play a very important role in the visual quality of the entire frame. We introduce an adaptive DCT loss for video preprocessing. After we convert the frame to frequency domain using DCT, we select the frequency coefficients belonging to high frequency components by sequential traversal using ZigZag
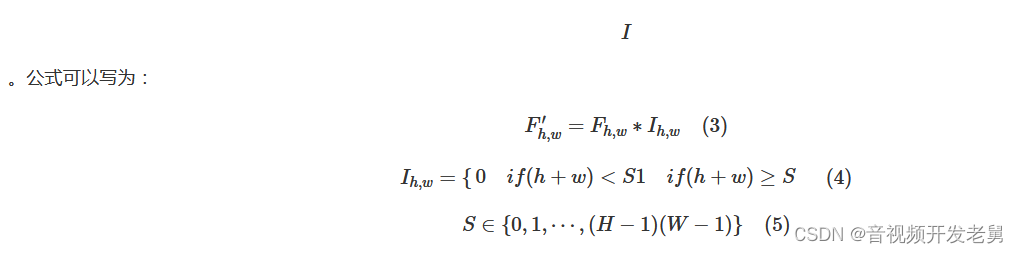
In the DCT frequency domain, the value of the frequency coefficient represents the energy of the frequency component in the entire frame. If the energy of a frequency component is small, it means that the frequency component is relatively less important in reconstructing the frame. Therefore, we wish to discard some high-frequency components with relatively small coefficient values. In this case, we average the absolute values of these selected coefficients to get a threshold

experiment
Performance improvements to traditional encoders
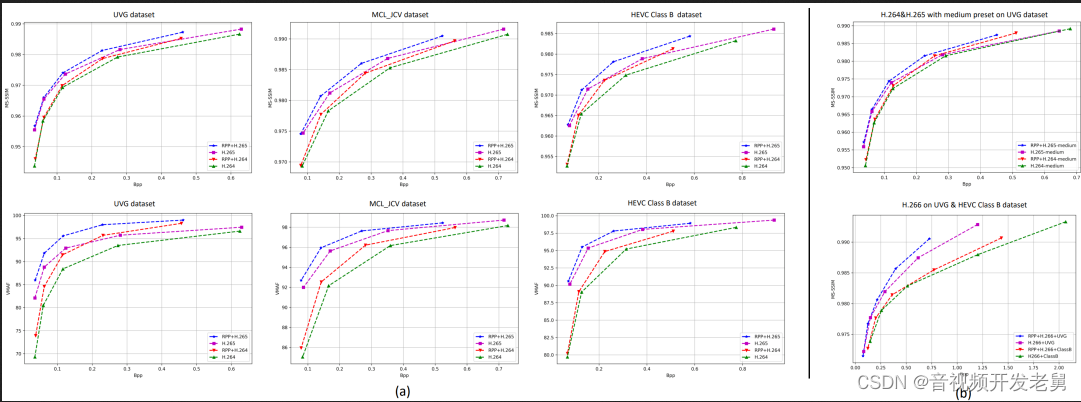
The results in the above figure and the following three tables show that the method we proposed can significantly improve the BD-rate of the two indicators VMAF and MS-SSIM of the standard codec on the three data sets. Under VMAF, RPP + H.264 saves an average of 18.21% of bitrate. Save 8.73% bit rate under MS-SSIM. Under VMAF, RPP + H.265 saves an average of 24.62% of the code rate, and under MS-SSIM it saves 13.51% of the code rate. Some learning-based video encoders can outperform traditional standard codecs only in the "very fast" preset. To demonstrate the generality of our approach, we also tested our RPP approach using the “medium” preset. As shown in the top panel of (b), our method still outperforms the standard codec, which is consistent with the "very fast" preset result in (a). In addition, we also tested our RPP method using H.266 on the UVG dataset and HEVC Class B dataset. As shown in the bottom graph of (b) in the figure, the average code rate saving rate of RPP + H.266 is 8.42% under MS-SSIM on these two datasets. As we expected, our method achieves significant improvements when used in conjunction with all major standard codecs.

As a benefit of this article, you can receive free C++ audio and video learning materials package, technical videos/codes, including (audio and video development, interview questions, FFmpeg, webRTC, rtmp, hls, rtsp, ffplay, codec, push-pull streaming, srs)↓↓↓ ↓↓↓See below↓↓Click at the bottom of the article to get it for free↓↓