The purpose of this article is to provide NLP enthusiasts with a detailed analysis of a well-known language model-BERT . The full text will be divided into 4 parts and explained in sequence from the shallower to the deeper.
1. Introduction to Bert
BERT is a pre-training model proposed by Google AI Research Institute in October 2018.
The full name of BERT is Bidirectional Encoder Representation from Transformers. BERT has shown amazing results in the top level test SQuAD1.1 of machine reading comprehension: it has surpassed humans in all two metrics, and achieved SOTA performance in 11 different NLP tests, including pushing the GLUE benchmark to 80.4% (Absolute improvement 7.6%), MultiNLI accuracy reached 86.7% (Absolute improvement 5.6%), becoming a landmark model achievement in the history of NLP development.
2. About Bert's model architecture
Overall architecture: As shown in the figure below, the leftmost one is the architecture diagram of BERT. It can be clearly seen that BERT uses Transformer Encoder block for connection, because it is a typical two-way encoding model.
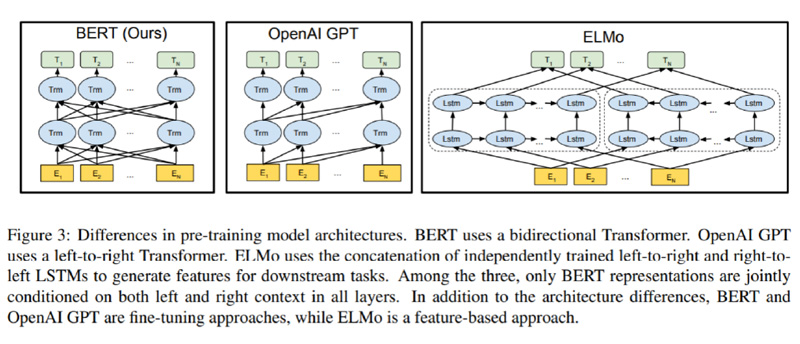
3.1 About the key points in Bert training process
1) Four key words: Pre-trained, Deep, Bidirectional Transformer, Language Understanding
a. Pre-trained: First of all, it is clear that this is a pre-trained language model, and all developers in the future can directly inherit it!
The two biggest highlights of the entire Bert model are focused on the Pre-trained task part.
b. Deep
Bert_BASE:Layer = 12, Hidden = 768, Head = 12, Total Parameters = 110M
Bert_LARGE:Layer = 24, Hidden = 1024, Head = 16, Total Parameters = 340M
Compared with Transformer: Layer = 6, Hidden = 2048, Head = 8, it is shallow and wide, indicating that a deep and narrow model like Bert works better (basically consistent with the overall conclusion in the CV field).
C. Bidirectional Transformer: Bert’s first innovation is a bidirectional Transformer network.
Bert directly refers to the Encoder module in the Transformer architecture, and discards the Decoder module, so that it automatically has two-way encoding capabilities and powerful feature extraction capabilities.
D. Language Understanding: Focus more on language understanding, not just language generation (Language Generation)
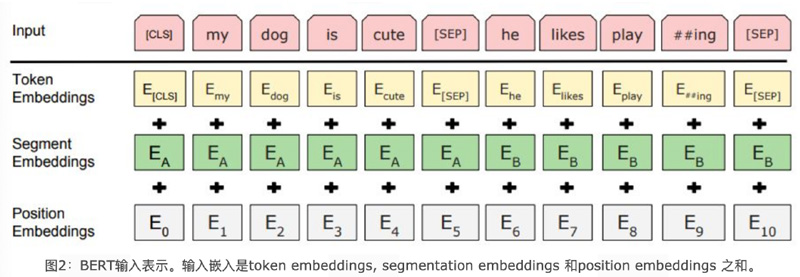
3.2 Bert’s language input representation consists of 3 components: (see the second picture above)
Word embedding tensor: word embeddings
Statement block tensor: segmentation embeddings
Position encoding tensor: position embeddings
The final embedding vector is the direct sum of the above three vectors.
3.3: Two core tasks are introduced into Bert’s pre-training (these two tasks are also the two biggest innovations in Bert’s original paper)
a Introduce Masked LM (language model training with mask)
a.1 In the original training text, 15% of the tokens are randomly selected as objects that will participate in the mask.
a.2 Among these selected tokens, the data generator does not turn them all into [MASK], but has the following three choices:
a.2.1 With 80% probability, replace the token with [MASK] tag, for example, my dog is hairy -> my dog is [MASK]
a.2.2 With a 10% probability, replace the token with a random word, such as my dog is hairy -> my dog is apple
a.2.3 With a probability of 10%, keep the token unchanged, for example, my dog is hairy -> my dog is hairy
a.3 Transformer Encoder does not know which words it will predict during the training process? Which words are the original samples? Which words are masked as [MASK]? Which words are replaced with other words? In a highly uncertain situation, the model is forced to quickly learn the semantics of the distributed context of the token, and try its best to learn how the original language speaks!!! At the same time, because only 15% of the tokens in the original text participate in the MASK operation , will not destroy the expressive ability and language rules of the original language!!!
b Introducing Next Sentence Prediction (the prediction task of the next sentence)
b.1 The purpose is to serve NLP tasks such as question answering, reasoning, and sentence-topic relationships.
b.2 All statements participating in task training are selected to participate.
·50% of B is the next sentence that actually follows A in the original text. (Marked as IsNext, representing a positive sample)
·50% of B is a randomly selected sentence from the original text. (Marked as NotNext, representing a negative sample)
b.3 In this task, the Bert model can achieve an accuracy of 97-98% on the test set.
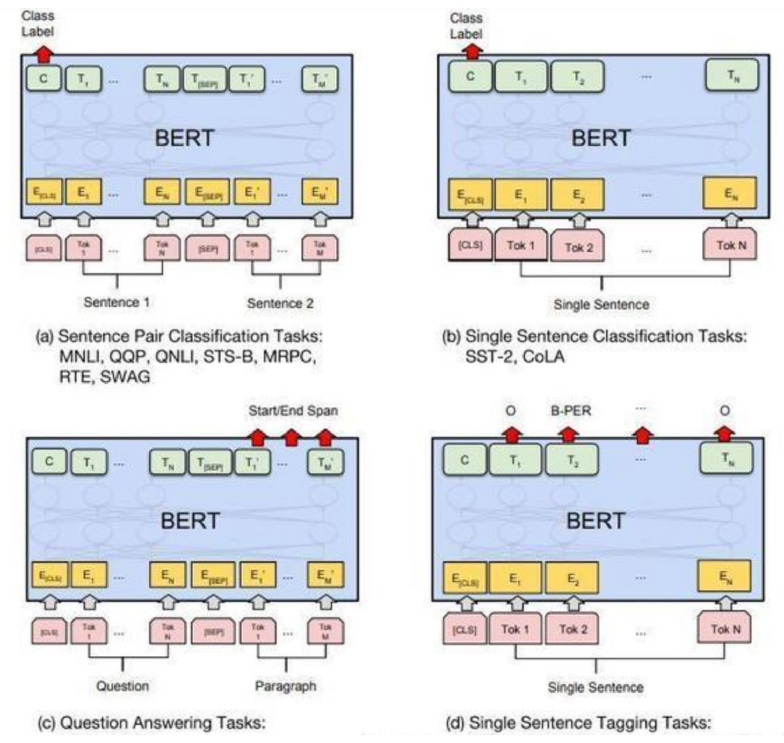
3.4 About Bert-based model fine-tuning (fine-tuning)
You only need to insert the input and output of a specific task into Bert, and use the powerful attention mechanism of Transformer to simulate many downstream tasks. (Sentence pair relationship judgment, single text topic classification, question and answer task (QA), single sentence labeling (named entity recognition))
Some experiences with fine-tuning:
batch size:16,32
epochs:3,4
learning rate:2e-5,5e-5
Fully connected layer added: layers:1-3, hidden_size:64,128
4. The advantages and disadvantages of the Bert model itself.
Advantages: Bert is based on transformer and has powerful language representation and feature extraction capabilities. Reached the state of the art on 11 NLP benchmark tasks. At the same time, it is once again proven that the ability of the two-way language model is more powerful.
Disadvantages:
1) Poor reproducibility, basically impossible to do, can only be used directly!
2) During the training process, because only 15% of the data in each batch_size participates in prediction, the model converges slowly and requires powerful computing power support!
Extension:
1) Deep learning is representation learning
·In the 11 language model competitions of Bert, the basic idea is that the two-way Transformer is responsible for extracting features, and then the entire network adds a fully connected linear layer as fine-tuning fine-tuning. But even with such a fool-like assembly, in the famous difficult task in NLP-NER (Named Entity Recognition), even the CRF layer is directly removed, which still greatly surpasses the combined effect of BiLSTM + CRF. Where does this go???
2) The extreme importance of scale (Scale matters)
Whether it is Masked LM or Next Sentence Prediction, it is not the first concept. It has been proposed in other models before, but because of the data scale + computing power limitations, the world has not been able to see the potential of this model. Those Paper It's not worth anything anymore. But when it comes to Google, the result of not losing money is that Paper is valuable!!
3) Regarding further research showing what Bert learned at different layers.
·The lower network layers capture information about phrase structure.
·The characteristics of words and characters are represented in layers 3-4, the characteristics of syntactic information are represented in layers 6-9, and the characteristics of sentence semantic information are represented in layers 10-12.
·The feature of subject-verb agreement is shown in layers 8-9 (a type of syntactic information).