Table of contents
1. Introduction to data types (key points)
2. Basic classification of types
3. Storage of integer data in memory:
1. Original code, inverse code, complement code
2.Introduction to big and small endian:
(1) Introduction to big and small endian:
(2) Reasons for the occurrence of big and small endianness:
4. Storage of floating point data in the computer:
Rules for floating point number storage:
As for the index E, the situation is more complicated.
First, E is an unsigned integer (unsigned int)
1. Introduction to data types ( key points )
char //Character data type
short //Short integer data type
int //integer data type
long //Long integer data type
long long //Longer integer type
float //single precision floating point number
double //double precision floating point number
2. Basic classification of types
Integer family:
char
unsigned char
signed char
short
unsigned short [int]
signed short [int]
int
unsigned int
signed int
long
unsigned long [int]
signed long [int]
Floating point family:
float
double
Construction type:
> Array type
> Structure type struct
> Enumeration type enum
> Union type union
Pointer type:
int * pi;
char * pc;
float * pf;
void * pv;
Empty type:
void represents the empty type (no type)
and is usually applied to the return type of a function, the parameters of a function, and pointer types.
3. Storage of integer data in memory:
1. Original code, inverse code, complement code
There are three binary representation methods for integers in computers, namely original code, complement code and complement code.
The three representation methods all have two parts: sign bit and numerical bit. The sign bit uses 0 to represent "positive" and 1 to represent "negative", while the numerical bit
The original, inverse, and complement codes of positive numbers are the same.
There are three ways to represent negative integers in different ways.
The original
code can be obtained by directly translating the numerical value into binary in the form of positive and negative numbers.
The one's complement code
can be obtained by keeping the sign bit of the original code unchanged and inverting the other bits bit by bit.
Complementary code
The complement code is obtained by adding 1 to the complement code.
For shaping: the data stored in the memory actually stores the complement code.
Why does the computer store complement codes?
In computer systems, numerical values are always represented and stored using two's complement codes. The reason is that using the complement code, the sign bit and the numerical field can be
processed uniformly;
at the same time, addition and subtraction can also be processed uniformly (the CPU only has an adder). In addition, the complement code and the original code are converted to each other, and the operation process
is the same. No additional hardware circuitry is required.


2.Introduction to big and small endian:
(1) Introduction to big and small endian:
Big-endian (storage) mode means that the low-order bits of data are stored in the high addresses of the memory, and the high-order bits of the data are stored in the low addresses of the memory; little-endian (storage) mode means that the low-order bits of the data are stored in the low addresses
of
the memory. address, and the high bits of the data are stored in the high
address of the memory.
(2) Reasons for the occurrence of big and small endianness:
Why are there big and small endian modes? This is because in computer systems, we use bytes as units. Each address unit
corresponds to a byte, and a byte is 8 bits. However, in C language, in addition to the 8-bit char, there are also the 16-bit short
type and the 32-bit long type (depending on the specific compiler). In addition, for processors with more than 8 bits, such as 16-bit Or for a 32-
bit processor, since the register width is larger than one byte, there must be a problem of how to arrange multiple bytes. This
leads to big-endian storage mode and little-endian storage mode.
For example: a 16-bit short type x, the address in the memory is 0x0010, and the value of x is 0x1122, then 0x11 is the
high byte and 0x22 is the low byte. For big-endian mode, put 0x11 in the low address, that is, 0x0010, and 0x22 in the high
address, that is, 0x0011. Little endian mode is just the opposite. Our commonly used X86 structure is little endian mode, while KEIL C51
is big endian mode. Many ARM and DSP are in little-endian mode.
Some ARM processors can also select big-endian or little-endian mode by hardware .
4. Storage of floating point data in the computer:
Example of floating point number storage:
int main()
{
int n = 9;
float *pFloat = (float *)&n;
printf("n的值为:%d\n",n);
printf("*pFloat的值为:%f\n",*pFloat);
*pFloat = 9.0;
printf("num的值为:%d\n",n);
printf("*pFloat的值为:%f\n",*pFloat);
return 0;
}The effect of executing this code is:
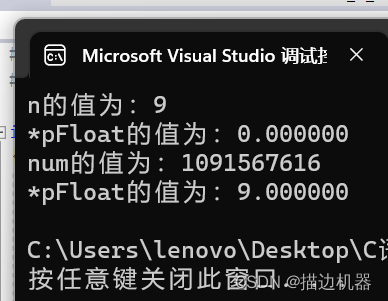
Rules for floating point number storage:
num and *pFloat are obviously the same number in memory. Why are the interpretation results of floating point numbers and integers so different?
To understand this result, you must understand how floating point numbers are represented internally in the computer.
Detailed interpretation:
According to the international standard IEEE (Institute of Electrical and Electronics Engineering) 754, any binary floating point number V can be expressed in the following form:
(-1)^S * M * 2^E
(-1)^S represents the sign bit , when S=0, V is a positive number; when S=1, V is a negative number.
M represents a valid number, greater than or equal to 1 and less than 2.
2^E represents the exponent bit.
For example:
5.0 in decimal is 101.0 in binary, which is equivalent to 1.01×2^2.
Then, according to the format of V above, we can get S=0, M=1.01, E=2.
-5.0 in decimal is -101.0 written in binary, which is equivalent to -1.01×2^2. Then, S=1, M=1.01, E=2.
IEEE 754 stipulates that
for a 32-bit floating point number, the highest 1 bit is the sign bit S, the next 8 bits are the exponent E, and the remaining 23 bits are the significant digit M.


IEEE 754 also has some special provisions for the significant digit M and the exponent E.
As mentioned before, 1≤M<2, that is to say, M can be written in the form of 1.xxxxxx, where xxxxxx represents the decimal part.
IEEE 754 stipulates that when M is stored inside the computer, the first digit of this number is always 1 by default, so it can be discarded and only the following
xxxxxx parts are saved. For example, when saving 1.01
, only 01 is saved, and when reading, the first 1 is added. The purpose of this is to save 1 significant figure. Taking a 32-bit
floating point number as an example, only 23 bits are left for M.
After the first 1 is rounded off, 24 significant digits can be saved.
As for the index E, the situation is more complicated.
First, E is an unsigned integer (unsigned int)
This means that if E is 8 bits, its value range is 0~255; if E is 11 bits, its value range is 0~2047. However, we
know that E in scientific notation can be
a negative number, so IEEE 754 stipulates that an intermediate number must be added to the real value of E when stored in memory. For an 8-bit E, this intermediate number is
127 ;For an 11-digit E, this intermediate
number is 1023. For example, the E of 2^10 is 10, so when it is saved as a 32-bit floating point number, it must be saved as 10+127=137, which is
10001001.
E is not all 0 or not all 1
At this time, the floating point number is represented by the following rules: subtract 127 (or 1023) from the calculated value of the exponent E to obtain the real value, and then add the
first 1 before the significant digit M.
For example:
The binary form of 0.5 (1/2) is 0.1. Since the positive part must be 1, that is, the decimal point is moved to the right by 1 place, it is
1.0*2^(-1), and its exponent code is -1+127= 126, expressed as
01111110, and the mantissa 1.0 removes the integer part to 0, and fills in 0 to 23 digits 000000000000000000000000, then its binary
representation is:0 01111110 00000000000000000000000
E is all 0
At this time, the exponent E of the floating point number is equal to 1-127 (or 1-1023), which is the real value. The
effective number M no longer adds the first 1, but is reduced to a decimal of 0.xxxxxx. This is done to represent ±0, and
very small numbers close to 0.
E is all 1
At this time, if the significant digits M are all 0, it means ±infinity (the sign bit depends on the sign bit s);