"Federated Learning in Practice" Chapter 3: Using Python to implement horizontal federated image classification from scratch
1. Environment configuration
The environment has been configured: refer to the cpu version of Pytorch environment configuration_pytorchcpu version_EZVIZ ym's blog-CSDN blog
anaconda python3.8 torch(cpu) in pytorch1

2. Import project
1、File》setting:
2. Command line python main.py -c ./utils/conf.json

The cifar10 dataset will be downloaded to data:
Running, 0 1 2 means that client 1 has trained for three rounds and is running on the CPU, which is extremely slow.
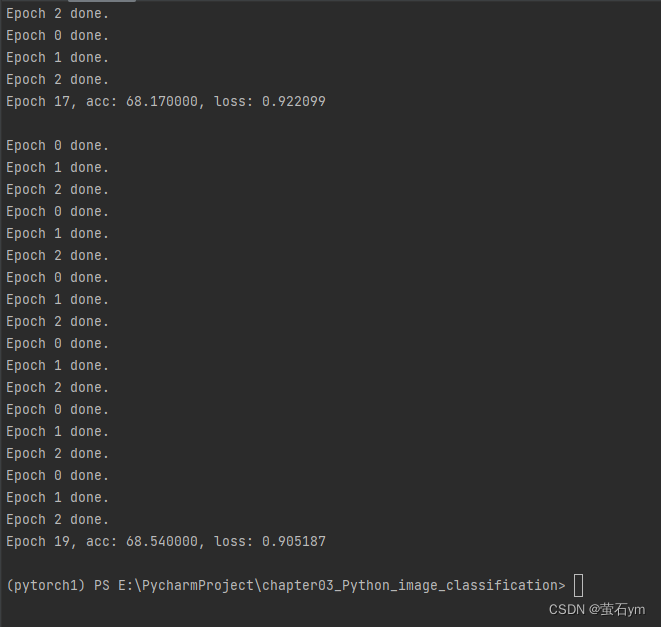
Epoch 45, acc: 76.170000, loss: 0.692326
Epoch 46, acc: 76.360000, loss: 0.681031
Epoch 47, acc: 76.700000, loss: 0.670521 Epoch 49, acc
: 77.140000, loss: 0.6580 76
50 rounds are close to convergence
3. Analysis
3.1 conf.json configuration file: modify as needed
//注:json文件不能这样添加注释
{
"model_name" : "resnet18",
"no_models" : 10, <!--客户端数量-->
"type" : "cifar", //数据集信息
"global_epochs" : 20, //全局迭代次数,即服务端与客户端的通信迭代次数
"local_epochs" : 3, //本地模型训练迭代次数
"k" : 5, //每一轮迭代时,服务端会从所有客户端中挑选k个客户端参与训练。
"batch_size" : 32, //本地训练每一轮的样本
//下边三个为超参数设置
"lr" : 0.001,
"momentum" : 0.0001,
"lambda" : 0.1
}3.2 Dataset: datasets.py
from torchvision.transforms import transforms
from torchvision import datasets
# 获取数据集
def get_dataset(dir, name):
if name == 'mnist':
# root: 数据路径
# train参数表示是否是训练集或者测试集
# download=true表示从互联网上下载数据集并把数据集放在root路径中
# transform:图像类型的转换
train_dataset = datasets.MNIST(dir, train=True, download=True, transform=transforms.ToTensor())
eval_dataset = datasets.MNIST(dir, train=False, transform=transforms.ToTensor())
elif name == 'cifar':
# 设置两个转换格式
# transforms.Compose 是将多个transform组合起来使用(由transform构成的列表)
transform_train = transforms.Compose([
# transforms.RandomCrop: 切割中心点的位置随机选取
transforms.RandomCrop(32, padding=4), transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
# transforms.Normalize: 给定均值:(R,G,B) 方差:(R,G,B),将会把Tensor正则化
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
train_dataset = datasets.CIFAR10(dir, train=True, download=True, transform=transform_train)
eval_dataset = datasets.CIFAR10(dir, train=False, transform=transform_test)
return train_dataset, eval_dataset
3.3 Client: client.py
The client class includes two functions: constructor + local training function.
The main work of the client includes:
first, copy the configuration information to the client;
then, obtain the model according to the model information in the configuration, and usually the server passes the model parameters. To the client, the client overwrites the local model with the global model;
finally, configure the local training data
. After obtaining the cifar10 data set through the datasets module in torchvision, it is divided according to the client ID. Different clients have different sub-data. set, there is no intersection between
3.3.1 Define the constructor
class Client(object):
def __init__(self, conf, model, train_dataset, id = 1):
# 配置文件
self.conf = conf
# 客户端本地模型
self.local_model = model
# 客户端ID
self.client_id = id
# 客户端本地数据集
self.train_dataset = train_dataset
# 按ID对训练集合的拆分
all_range = list(range(len(self.train_dataset)))
data_len = int(len(self.train_dataset) / self.conf['no_models'])
indices = all_range[id * data_len: (id + 1) * data_len]
self.train_loader = torch.utils.data.DataLoader(
self.train_dataset,
batch_size=conf["batch_size"],
# sampler定义从数据集中提取样本的策略
sampler=torch.utils.data.sampler.SubsetRandomSampler(indices)
)
3.3.2 Define the model local training function
Here, cross entropy is used as the loss function of the local model, and gradient descent is used to solve and update parameter values.
def local_train(self, model):
for name, param in model.state_dict().items():
# 客户端首先用服务器端下发的全局模型覆盖本地模型
self.local_model.state_dict()[name].copy_(param.clone())
# 定义最优化函数器,用于本地模型训练
optimizer = torch.optim.SGD(self.local_model.parameters(), lr=self.conf['lr'], momentum=self.conf['momentum'])
# 本地训练模型
self.local_model.train()
for e in range(self.conf["local_epochs"]):
for batch_id, batch in enumerate(self.train_loader):
data, target = batch
# 数据加载到gpu
if torch.cuda.is_available():
data = data.cuda()
target = target.cuda()
# 梯度清0
optimizer.zero_grad()
# 训练预测
output = self.local_model(data)
# 使用cross_entropy交叉熵计算损失函数
loss = torch.nn.functional.cross_entropy(output, target)
# 反向传播
loss.backward()
# 更新参数
optimizer.step()
print("Epoch %d done" % e)
diff = dict()
for name, data in self.local_model.state_dict().items():
# 计算训练后与训练前的差值
diff[name] = (data - model.state_dict()[name])
print("Client %d local train done" % self.client_id)
return diff
3.4 Server server.py
The server class Server mainly includes three functions:
- define constructor
- Model Aggregation Function
- Model evaluation function
3.4.1 Define the constructor
class Server(object):
# 定义构造函数
def __init__(self, conf, eval_dataset):
# 导入配置文件
self.conf = conf
# 根据配置获取模型文件
self.global_model = models.get_model(self.conf["model_name"])
self.eval_loader = torch.utils.data.DataLoader(
eval_dataset,
# 设置单个批次大小
batch_size=self.conf["batch_size"],
# 打乱数据集
shuffle=True
)
3.4.2 Model aggregation function
The classic FedAvg algorithm is used here
def model_aggregate(self, weight_accumulator):
# weight_accumulatot存储了每一个客户端的上传参数变化值
# 遍历服务器的全局模型
for name, data in self.global_model.state_dict().items():
# 更新每一层
update_per_layer = weight_accumulator[name] * self.conf["lambda"]
# 累加和
if data.type() != update_per_layer.type():
# 因为update_per_layer的type是floatTensor,所以将起转换为模型的LongTensor(有一定的精度损失)
data.add_(update_per_layer.to(torch.int64))
else:
data.add_(update_per_layer)
3.4.3 Model evaluation function
For the current global model, use evaluation data to evaluate the performance of the current global model.
def model_eval(self):
self.global_model.eval()
total_loss = 0.0
correct = 0
dataset_size = 0
# 遍历评估数据集合
for batch_id, batch in enumerate(self.eval_loader):
data, target = batch
# 获取所有的样本总量大小
dataset_size += data.size()[0]
# 将数据存储到gpu
if torch.cuda.is_available():
data = data.cuda()
target = target.cuda()
# 加载到模型中训练
output = self.global_model(data)
# 聚合所有的损失 cross_entropy交叉熵函数计算损失
total_loss += torch.nn.functional.cross_entropy(output,target,
reduction='sum'
).item()
# 获取最大的对数概率的索引值,在预测结果中选择可能性最大的作为最终的分类结果
pred = output.data.max(1)[1]
# 统计预测结果与真实标签相同的总个数
correct += pred.eq(target.data.view_as(pred)).cpu().sum().item()
# 计算准确率
acc = 100.0 * (float(correct) / float(dataset_size))
# 计算损失值
total_1 = total_loss / dataset_size
return acc, total_1
3.5 Model file models.py
The models.py file in the project folder is used for various machine learning models.
import torch
from torchvision import models
# 各种机器学习模型
def get_model(name="vgg16", pretrained=True):
if name == "resnet18":
model = models.resnet18(pretrained=pretrained)
elif name == "resnet50":
model = models.resnet50(pretrained=pretrained)
elif name == "densenet121":
model = models.densenet121(pretrained=pretrained)
elif name == "alexnet":
model = models.alexnet(pretrained=pretrained)
elif name == "vgg16":
model = models.vgg16(pretrained=pretrained)
elif name == "vgg19":
model = models.vgg19(pretrained=pretrained)
elif name == "inception_v3":
model = models.inception_v3(pretrained=pretrained)
elif name == "googlenet":
model = models.googlenet(pretrained=pretrained)
if torch.cuda.is_available():
return model.cuda()
else:
return model
3.6 main file main.py
First, read the configuration file information
# 读取配置文件
with open(args.conf, 'r') as f:
conf = json.load(f)
Next, define a server object and multiple client objects respectively to simulate a horizontal federated learning scenario.
train_datasets, eval_datasets = datasets.get_dataset("./data/", conf["type"])
server = Server(conf, eval_datasets)
# 客户端列表
clients = []
# 添加10个客户端到列表
for c in range(conf["no_models"]):
clients.append(Client(conf, server.global_model, train_datasets, c))
In each round of iteration, the server will randomly select a part of the current clients to participate in this round of training. The selected clients use the local training interface local_train to perform local training. Finally, the server calls the model aggregation function to update the global model.
for e in range(conf["global_epochs"]): print("Global Epoch %d" % e) # 随机采样k个客户端参与本轮联邦训练 candidates = random.sample(clients, conf["k"]) print("select clients is: ") for c in candidates: print(c.client_id) weight_accumulator = {} # 初始化模型参数weight_accumulator for name, params in server.global_model.state_dict().items(): # 生成一个和参数矩阵大小相同的0矩阵 weight_accumulator[name] = torch.zeros_like(params) # 遍历被挑选的客户端,本地训练模型 for c in candidates: diff = c.local_train(server.global_model) for name, params in server.global_model.state_dict().items(): weight_accumulator[name].add_(diff[name]) # 模型聚合 server.model_aggregate(weight_accumulator) # 模型评估 acc, loss = server.model_eval() print("Epoch %d, acc: %f, loss: %f\n" % (e, acc, loss))