Preface
In project development, it is often necessary to use data import and export. Import is to import from Excel to DB, and export is to query data from DB and then use POI to write to Excel.
I believe everyone will encounter the import and export of big data in daily development and interviews.
As long as many problems are solved this time, they will always be reviewed and recorded, so that they can be easily solved if they encounter the same problems later. Okay, let's not talk nonsense and start the text!
1. Comparison of advantages and disadvantages of traditional POI versions
In fact, when thinking about the import and export of data, it is natural that Apache's POI technology and Excel version issues come to mind.
- The implementation class HSSFWorkbook
is the object we used most in the early days. It can operate all Excel versions before Excel2003 (including 2003). Before 2003, the version suffix of Excel was still .xls - The implementation class XSSFWorkbook
can be found in many companies and is still in use. It is a version between Excel2003–Excel2007, and the extension of Excel is .xlsx - The implementation class SXSSFWorkbook
is only available in versions after POI3.8. It can operate all versions of Excel after Excel2007. The extension is .xlsx.
HSSFWorkbook
It's the most common way in the POI version, though:
- Its disadvantage is that it can only export up to 65535 rows, that is, if the exported data function exceeds this data, an error will be reported;
- Its advantage is that it will not report memory overflow. (Because the amount of data is less than 7w, the memory is generally enough. First of all, you must clearly know that this method is to read the data into the memory first, and then operate it)
XSSFWorkbook
- Advantages: The appearance of this form is to break through the 65,535-line limitation of HSSFWorkbook, and to export 104w pieces of data at most for the 1,048,576 lines and 16,384 columns of the Excel2007 version;
- Disadvantages: The accompanying problem came. Although the number of exported data rows has increased many times, the subsequent memory overflow problem has also become a nightmare. Because the book, sheet, row, cell, etc. you created are all stored in memory before being written to Excel (this is not counting some styles and formats of Excel, etc.), it is conceivable that if the memory does not overflow, the It’s a bit unscientific! ! !
SXSSFWorkbook
Starting from POI version 3.8, a low-memory SXSSF method based on XSSF is provided:
Advantages:
- This method generally does not cause memory overflow (it uses the hard disk in exchange for memory space.
- That is, when the data in the memory reaches a certain level, the data will be persisted to the hard disk for storage, and all the data stored in the memory are the latest data),
- And supports the creation of large Excel files (more than enough to store millions of data).
shortcoming: - Since part of the data is persisted to the hard disk and cannot be viewed and accessed, it will cause,
- At the same time, we can only access a certain amount of data, that is, the data stored in memory; the sheet.clone() method will no longer be supported, or because of persistence;
- The evaluation of formulas is no longer supported, or because of persistence, the data in the hard disk cannot be read into the memory for calculation;
- When using the template method to download data, the table header cannot be changed, or because of the persistence problem, it cannot be changed after writing to the hard disk;
2. Which way to use depends on the situation
After understanding and knowing the advantages and disadvantages of these three Workbooks, which method to use depends on the situation:
I generally make analysis choices based on the following situations:
1. When the data we often import and export does not exceed 7w Under the circumstances, you can use either HSSFWorkbook or XSSFWorkbook;
2. When the data volume exceeds 7w and the exported Excel does not involve operations on Excel styles, formulas, and formats, it is recommended to use SXSSFWorkbook; 3. When the data
volume Checked 7w, and we need to operate the table header, style, formula, etc. in Excel. At this time, we can use XSSFWorkbook to cooperate with batch query and write to Excel in batches to do it;
3. Millions of data import and export
To solve a problem, we must first understand what the problem is?
1. The amount of data I encountered is extremely large. Using the traditional POI method to complete the import and export will obviously cause memory overflow, and the efficiency will be very low; 2. If the amount of data is large, directly
using select * from tableName will definitely not work, and it will be found out at once. 300w pieces of data will definitely be very slow;
3. When exporting 300w data to Excel, it must not be written in one Sheet, so the efficiency will be very low; it may take a few minutes to open;
4. 300w data must not be exported to Excel line by line Export to Excel. Frequent IO operations are absolutely not acceptable;
5. When importing, 3 million data are stored in the DB, and it is definitely not possible to insert them one by one in a loop;
6. When importing 3 million data, it is definitely not possible to use Mybatis batch insertion, because Mybatis batch insertion is actually a SQL cycle ; also very slow.
Solution ideas:
Aiming at 1:
In fact, the problem is memory overflow, we only need to use the POI method introduced above, the main problem is that the original POI is quite troublesome to solve.
After consulting the information, I found a POI packaging tool EasyExcel from Ali. The above problems will be solved;
for 2:
we can’t query all the data at one time, we can query in batches, but the problem of querying several times at times, and the market There are many paging plugins. This problem is easy to solve.
Target 3:
You can write 3 million pieces of data into different Sheets, and only one million pieces of data can be written in each Sheet.
Aiming at 4:
It is not possible to write to Excel line by line, we can write the data queried in batches to Excel in batches.
For 5:
When importing to DB, we can store the data read in Excel into a collection, and when it reaches a certain amount, directly insert it into DB in batches.
For 6:
You cannot use Mybatis's batch insertion. We can use JDBC's batch insertion and cooperate with transactions to complete batch insertion into DB. That is, Excel reads in batches + JDBC inserts in batches + transactions.
3.1 Simulate 500w data export
Requirement: Use EasyExcel to complete the export of 5 million data.
500w data export solutions:
- First, at the query database level, queries need to be carried out in batches (for example, 200,000 per query)
- Every time a query is completed, use the EasyExcel tool to write the data;
- When a Sheet is filled with 100w pieces of data, start to write the queried data into another Sheet;
- This loops until all the data is exported to Excel.
ps: We need to calculate the number of Sheets and the number of loop writes. Especially the number of writes to the last Sheet.
Because you don't know how much data will be written in the last Sheet, it may be 100w, or 25w, because the 500w here is just simulated data, and the exported data may be more or less than 500w ps: We need to calculate the number of writes
, Because we use paging queries, we need to pay attention to the number of writes.
In fact, how many times you query the database is how many times you write.
Preparations
1. Build a springboot project based on maven and introduce easyexcel dependencies. Here I use version 3.0
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>easyexcel</artifactId>
<version>3.0.5</version>
</dependency>
2. Create sql scripts for massive data
CREATE TABLE dept( /*部门表*/
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
dname VARCHAR(20) NOT NULL DEFAULT "",
loc VARCHAR(13) NOT NULL DEFAULT ""
) ;
#创建表EMP雇员
CREATE TABLE emp
(empno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, /*编号*/
ename VARCHAR(20) NOT NULL DEFAULT "", /*名字*/
job VARCHAR(9) NOT NULL DEFAULT "",/*工作*/
mgr MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,/*上级编号*/
hiredate DATE NOT NULL,/*入职时间*/
sal DECIMAL(7,2) NOT NULL,/*薪水*/
comm DECIMAL(7,2) NOT NULL,/*红利*/
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 /*部门编号*/
) ;
#工资级别表
CREATE TABLE salgrade
(
grade MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
losal DECIMAL(17,2) NOT NULL,
hisal DECIMAL(17,2) NOT NULL
);
#测试数据
INSERT INTO salgrade VALUES (1,700,1200);
INSERT INTO salgrade VALUES (2,1201,1400);
INSERT INTO salgrade VALUES (3,1401,2000);
INSERT INTO salgrade VALUES (4,2001,3000);
INSERT INTO salgrade VALUES (5,3001,9999);
delimiter $$
#创建一个函数,名字 rand_string,可以随机返回我指定的个数字符串
create function rand_string(n INT)
returns varchar(255) #该函数会返回一个字符串
begin
#定义了一个变量 chars_str, 类型 varchar(100)
#默认给 chars_str 初始值 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ'
declare chars_str varchar(100) default
'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
declare return_str varchar(255) default '';
declare i int default 0;
while i < n do
# concat 函数 : 连接函数mysql函数
set return_str =concat(return_str,substring(chars_str,floor(1+rand()*52),1));
set i = i + 1;
end while;
return return_str;
end $$
#这里我们又自定了一个函数,返回一个随机的部门号
create function rand_num( )
returns int(5)
begin
declare i int default 0;
set i = floor(10+rand()*500);
return i;
end $$
#创建一个存储过程, 可以添加雇员
create procedure insert_emp(in start int(10),in max_num int(10))
begin
declare i int default 0;
#set autocommit =0 把autocommit设置成0
#autocommit = 0 含义: 不要自动提交
set autocommit = 0; #默认不提交sql语句
repeat
set i = i + 1;
#通过前面写的函数随机产生字符串和部门编号,然后加入到emp表
insert into emp values ((start+i) ,rand_string(6),'SALESMAN',0001,curdate(),2000,400,rand_num());
until i = max_num
end repeat;
#commit整体提交所有sql语句,提高效率
commit;
end $$
#添加8000000数据
call insert_emp(100001,8000000)$$
#命令结束符,再重新设置为;
delimiter ;
3. Entity class
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Emp implements Serializable {
@ExcelProperty(value = "员工编号")
private Integer empno;
@ExcelProperty(value = "员工名称")
private String ename;
@ExcelProperty(value = "工作")
private String job;
@ExcelProperty(value = "主管编号")
private Integer mgr;
@ExcelProperty(value = "入职日期")
private Date hiredate;
@ExcelProperty(value = "薪资")
private BigDecimal sal;
@ExcelProperty(value = "奖金")
private BigDecimal comm;
@ExcelProperty(value = "所属部门")
private Integer deptno;
}
4.vo class
@Data
public class EmpVo {
@ExcelProperty(value = "员工编号")
private Integer empno;
@ExcelProperty(value = "员工名称")
private String ename;
@ExcelProperty(value = "工作")
private String job;
@ExcelProperty(value = "主管编号")
private Integer mgr;
@ExcelProperty(value = "入职日期")
private Date hiredate;
@ExcelProperty(value = "薪资")
private BigDecimal sal;
@ExcelProperty(value = "奖金")
private BigDecimal comm;
@ExcelProperty(value = "所属部门")
private Integer deptno;
}
Export core code
@Resource
private EmpService empService;
/**
* 分批次导出
*/
@GetMapping("/export")
public void export() throws IOException {
StopWatch stopWatch = new StopWatch();
stopWatch.start();
empService.export();
stopWatch.stop();
System.out.println("共计耗时: " + stopWatch.getTotalTimeSeconds()+"S");
}
public class ExcelConstants {
//一个sheet装100w数据
public static final Integer PER_SHEET_ROW_COUNT = 1000000;
//每次查询20w数据,每次写入20w数据
public static final Integer PER_WRITE_ROW_COUNT = 200000;
}
@Override
public void export() throws IOException {
OutputStream outputStream =null;
try {
//记录总数:实际中需要根据查询条件进行统计即可
//LambdaQueryWrapper<Emp> lambdaQueryWrapper = new QueryWrapper<Emp>().lambda().eq(Emp::getEmpno, 1000001);
Integer totalCount = empMapper.selectCount(null);
//每一个Sheet存放100w条数据
Integer sheetDataRows = ExcelConstants.PER_SHEET_ROW_COUNT;
//每次写入的数据量20w,每页查询20W
Integer writeDataRows = ExcelConstants.PER_WRITE_ROW_COUNT;
//计算需要的Sheet数量
Integer sheetNum = totalCount % sheetDataRows == 0 ? (totalCount / sheetDataRows) : (totalCount / sheetDataRows + 1);
//计算一般情况下每一个Sheet需要写入的次数(一般情况不包含最后一个sheet,因为最后一个sheet不确定会写入多少条数据)
Integer oneSheetWriteCount = sheetDataRows / writeDataRows;
//计算最后一个sheet需要写入的次数
Integer lastSheetWriteCount = totalCount % sheetDataRows == 0 ? oneSheetWriteCount : (totalCount % sheetDataRows % writeDataRows == 0 ? (totalCount / sheetDataRows / writeDataRows) : (totalCount / sheetDataRows / writeDataRows + 1));
ServletRequestAttributes requestAttributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes();
HttpServletResponse response = requestAttributes.getResponse();
outputStream = response.getOutputStream();
//必须放到循环外,否则会刷新流
ExcelWriter excelWriter = EasyExcel.write(outputStream).build();
//开始分批查询分次写入
for (int i = 0; i < sheetNum; i++) {
//创建Sheet
WriteSheet sheet = new WriteSheet();
sheet.setSheetName("测试Sheet1"+i);
sheet.setSheetNo(i);
//循环写入次数: j的自增条件是当不是最后一个Sheet的时候写入次数为正常的每个Sheet写入的次数,如果是最后一个就需要使用计算的次数lastSheetWriteCount
for (int j = 0; j < (i != sheetNum - 1 ? oneSheetWriteCount : lastSheetWriteCount); j++) {
//分页查询一次20w
Page<Emp> page = empMapper.selectPage(new Page(j + 1 + oneSheetWriteCount * i, writeDataRows), null);
List<Emp> empList = page.getRecords();
List<EmpVo> empVoList = new ArrayList<>();
for (Emp emp : empList) {
EmpVo empVo = new EmpVo();
BeanUtils.copyProperties(emp, empVo);
empVoList.add(empVo);
}
WriteSheet writeSheet = EasyExcel.writerSheet(i, "员工信息" + (i + 1)).head(EmpVo.class)
.registerWriteHandler(new LongestMatchColumnWidthStyleStrategy()).build();
//写数据
excelWriter.write(empVoList, writeSheet);
}
}
// 下载EXCEL
response.setContentType("application/vnd.openxmlformats-officedocument.spreadsheetml.sheet");
response.setCharacterEncoding("utf-8");
// 这里URLEncoder.encode可以防止浏览器端导出excel文件名中文乱码 当然和easyexcel没有关系
String fileName = URLEncoder.encode("员工信息", "UTF-8").replaceAll("\\+", "%20");
response.setHeader("Content-disposition", "attachment;filename*=utf-8''" + fileName + ".xlsx");
excelWriter.finish();
outputStream.flush();
} catch (IOException e) {
e.printStackTrace();
} catch (BeansException e) {
e.printStackTrace();
}finally {
if (outputStream != null) {
outputStream.close();
}
}
}
This is the memory usage and CPU usage of my computer during the test, of course I opened some other applications.
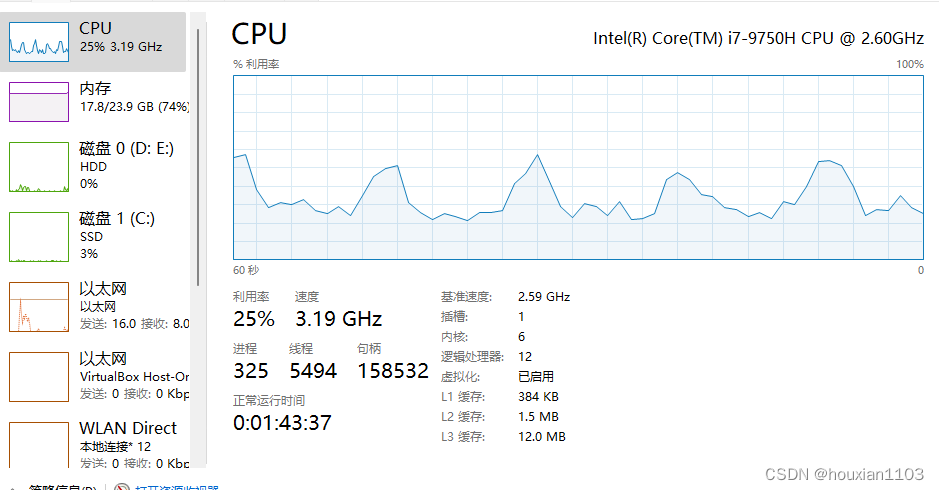
It takes about 400 seconds to export 500w data. Of course, business complexity and computer configuration must also be considered. Here is just an exported demo that does not involve other business logic. In actual development, it may take longer than this Some.
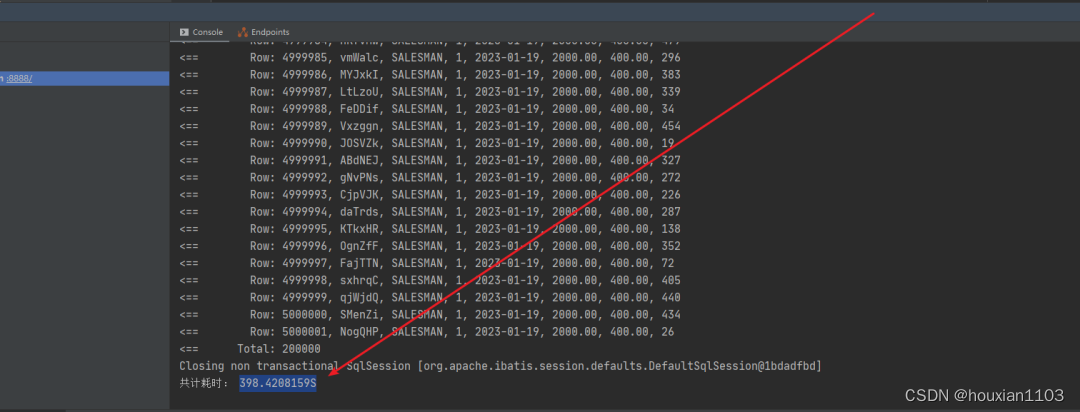
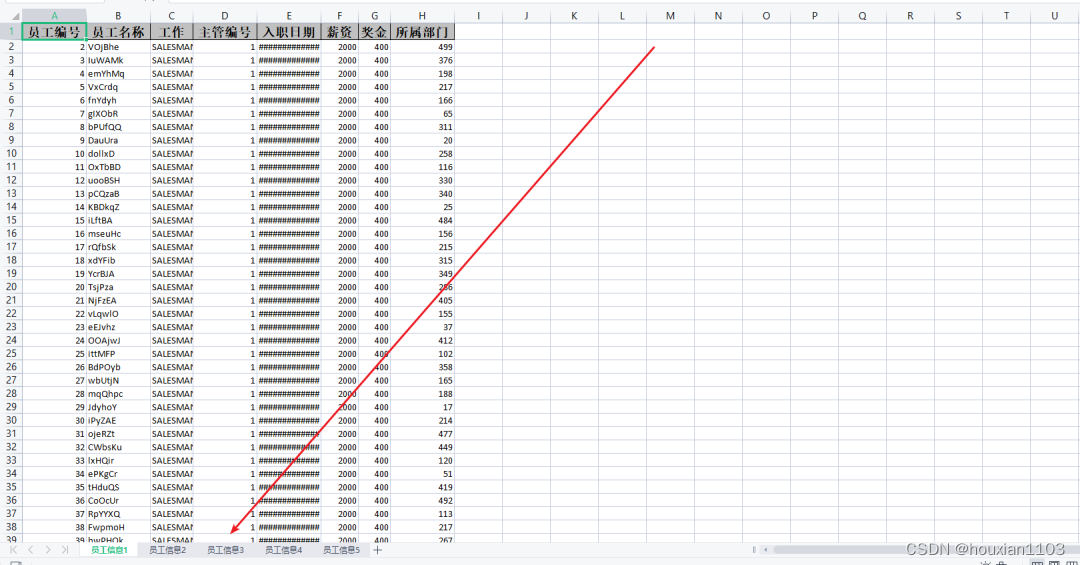
Look at the export effect, my above script inserts 500w data, 100w a sheet so exactly five
3.2 Simulate 5 million data import
Solution ideas for importing 500W data
1. The first step is to read the 500w data in Excel in batches. EasyExcel has its own solution for this. We can refer to the Demo. We only need to increase the parameter 5000 in batches.
2. The second is to insert into the DB. How to insert these 200,000 pieces of data, of course, you can’t loop one by one. You should insert these 200,000 pieces of data in batches. Also, you can’t use the batch insertion language of Mybatis, because the efficiency is also low.
3. Use the batch operation of JDBC+ transaction to insert data into the database. (Batch read + JDBC batch insert + manual transaction control)
The code implements
the controller layer test interface
@Resource
private EmpService empService;
@GetMapping("/importData")
public void importData() {
String fileName = "C:\\Users\\asus\\Desktop\\员工信息.xlsx";
//记录开始读取Excel时间,也是导入程序开始时间
long startReadTime = System.currentTimeMillis();
System.out.println("------开始读取Excel的Sheet时间(包括导入数据过程):" + startReadTime + "ms------");
//读取所有Sheet的数据.每次读完一个Sheet就会调用这个方法
EasyExcel.read(fileName, new EasyExceGeneralDatalListener(empService)).doReadAll();
long endReadTime = System.currentTimeMillis();
System.out.println("------结束读取Excel的Sheet时间(包括导入数据过程):" + endReadTime + "ms------");
System.out.println("------读取Excel的Sheet时间(包括导入数据)共计耗时:" + (endReadTime-startReadTime) + "ms------");
}
Excel import event monitoring
// 事件监听
public class EasyExceGeneralDatalListener extends AnalysisEventListener<Map<Integer, String>> {
/**
* 处理业务逻辑的Service,也可以是Mapper
*/
private EmpService empService;
/**
* 用于存储读取的数据
*/
private List<Map<Integer, String>> dataList = new ArrayList<Map<Integer, String>>();
public EasyExceGeneralDatalListener() {
}
public EasyExceGeneralDatalListener(EmpService empService) {
this.empService = empService;
}
@Override
public void invoke(Map<Integer, String> data, AnalysisContext context) {
//数据add进入集合
dataList.add(data);
//size是否为100000条:这里其实就是分批.当数据等于10w的时候执行一次插入
if (dataList.size() >= ExcelConstants.GENERAL_ONCE_SAVE_TO_DB_ROWS) {
//存入数据库:数据小于1w条使用Mybatis的批量插入即可;
saveData();
//清理集合便于GC回收
dataList.clear();
}
}
/**
* 保存数据到DB
*
* @param
* @MethodName: saveData
* @return: void
*/
private void saveData() {
empService.importData(dataList);
dataList.clear();
}
/**
* Excel中所有数据解析完毕会调用此方法
*
* @param: context
* @MethodName: doAfterAllAnalysed
* @return: void
*/
@Override
public void doAfterAllAnalysed(AnalysisContext context) {
saveData();
dataList.clear();
}
}
Core business code
public interface EmpService {
void export() throws IOException;
void importData(List<Map<Integer, String>> dataList);
}
/*
* 测试用Excel导入超过10w条数据,经过测试发现,使用Mybatis的批量插入速度非常慢,所以这里可以使用 数据分批+JDBC分批插入+事务来继续插入速度会非常快
*/
@Override
public void importData(List<Map<Integer, String>> dataList) {
//结果集中数据为0时,结束方法.进行下一次调用
if (dataList.size() == 0) {
return;
}
//JDBC分批插入+事务操作完成对20w数据的插入
Connection conn = null;
PreparedStatement ps = null;
try {
long startTime = System.currentTimeMillis();
System.out.println(dataList.size() + "条,开始导入到数据库时间:" + startTime + "ms");
conn = JDBCDruidUtils.getConnection();
//控制事务:默认不提交
conn.setAutoCommit(false);
String sql = "insert into emp (`empno`, `ename`, `job`, `mgr`, `hiredate`, `sal`, `comm`, `deptno`) values";
sql += "(?,?,?,?,?,?,?,?)";
ps = conn.prepareStatement(sql);
//循环结果集:这里循环不支持lambda表达式
for (int i = 0; i < dataList.size(); i++) {
Map<Integer, String> item = dataList.get(i);
ps.setString(1, item.get(0));
ps.setString(2, item.get(1));
ps.setString(3, item.get(2));
ps.setString(4, item.get(3));
ps.setString(5, item.get(4));
ps.setString(6, item.get(5));
ps.setString(7, item.get(6));
ps.setString(8, item.get(7));
//将一组参数添加到此 PreparedStatement 对象的批处理命令中。
ps.addBatch();
}
//执行批处理
ps.executeBatch();
//手动提交事务
conn.commit();
long endTime = System.currentTimeMillis();
System.out.println(dataList.size() + "条,结束导入到数据库时间:" + endTime + "ms");
System.out.println(dataList.size() + "条,导入用时:" + (endTime - startTime) + "ms");
} catch (Exception e) {
e.printStackTrace();
} finally {
//关连接
JDBCDruidUtils.close(conn, ps);
}
}
}
jdbc tool class
//JDBC工具类
public class JDBCDruidUtils {
private static DataSource dataSource;
/*
创建数据Properties集合对象加载加载配置文件
*/
static {
Properties pro = new Properties();
//加载数据库连接池对象
try {
//获取数据库连接池对象
pro.load(JDBCDruidUtils.class.getClassLoader().getResourceAsStream("druid.properties"));
dataSource = DruidDataSourceFactory.createDataSource(pro);
} catch (Exception e) {
e.printStackTrace();
}
}
/*
获取连接
*/
public static Connection getConnection() throws SQLException {
return dataSource.getConnection();
}
/**
* 关闭conn,和 statement独对象资源
*
* @param connection
* @param statement
* @MethodName: close
* @return: void
*/
public static void close(Connection connection, Statement statement) {
if (connection != null) {
try {
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (statement != null) {
try {
statement.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
/**
* 关闭 conn , statement 和resultset三个对象资源
*
* @param connection
* @param statement
* @param resultSet
* @MethodName: close
* @return: void
*/
public static void close(Connection connection, Statement statement, ResultSet resultSet) {
close(connection, statement);
if (resultSet != null) {
try {
resultSet.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
/*
获取连接池对象
*/
public static DataSource getDataSource() {
return dataSource;
}
}
druid.properties configuration file
Here I create the file under the class path. It should be noted that when connecting to the mysql database, you need to specify rewriteBatchedStatements=true batch processing to take effect. Otherwise, the efficiency of inserting one by one is low. allowMultiQueries=true means that there can be multiple inserts in the sql statement Or the update statement (with semicolons between the statements), which can be ignored here.
# druid.properties配置
driverClassName=com.mysql.jdbc.Driver
url=jdbc:mysql://localhost:3306/llp?autoReconnect=true&useUnicode=true&useSSL=false&serverTimezone=GMT%2B8&allowMultiQueries=true&rewriteBatchedStatements=true
username=root
password=root
initialSize=10
maxActive=50
maxWait=60000
Test Results
------开始读取Excel的Sheet时间(包括导入数据过程):1674181403555ms------
200000条,开始导入到数据库时间:1674181409740ms
2023-01-20 10:23:29.943 INFO 18580 --- [nio-8888-exec-1] com.alibaba.druid.pool.DruidDataSource : {
dataSource-1} inited
200000条,结束导入到数据库时间:1674181413252ms
200000条,导入用时:3512ms
200000条,开始导入到数据库时间:1674181418422ms
200000条,结束导入到数据库时间:1674181420999ms
200000条,导入用时:2577ms
.....
200000条,开始导入到数据库时间:1674181607405ms
200000条,结束导入到数据库时间:1674181610154ms
200000条,导入用时:2749ms
------结束读取Excel的Sheet时间(包括导入数据过程):1674181610155ms------
------读取Excel的Sheet时间(包括导入数据)共计耗时:206600ms------
Here I delete some of the logs. As you can see from the print results, it takes more than 200 seconds to import 5 million data on my computer. Of course, the company's business logic is very complex, the amount of data is relatively large, and there are many fields in the table. The speed of import and export will be slower than the current test.
4. Summary
1. The export and import operations of such a large amount of data will occupy a large amount of memory. In actual development, the number of operators should be limited.
2. When importing large quantities of data, you can use jdbc to manually start transactions and submit them in batches.