Speaking of web crawlers, everyone probably thinks of Python. Before I came into contact with Java crawlers, I only heard that python was born for crawlers. But as the saying goes: Java is the best language in the world
So I searched the Internet for information about Java crawlers. I was shocked if I didn’t check. In fact, Java can also do web crawlers and has special libraries. Java can also crawl some complex pages. Very good, there are many excellent Java web crawler frameworks in the open source community, such as webmagic
Advantages of Python over Java:
- As a dynamic language, Python is more suitable for beginner programmers. Python allows beginners to focus on programming objects and thinking methods without worrying about syntax, types and other external factors. Python's clear and concise syntax also makes it much easier to debug than Java.
- Python has some powerful architectures that Java does not.
- Python has a very powerful asynchronous support framework such as Eventlet Networking Library, and it is much more troublesome for Java to implement these functions. Therefore, Python is suitable for some scalable background applications. (but otherwise Python is not as scalable as Java)
- As a scripting language, Python is more suitable for developing small applications, and it is extremely suitable for prototyping in the early stages of application development
Disadvantages of Python relative to Java:
- Due to the advantages of Python, there will inevitably be sacrifices --- because it is a dynamic language, it is slower than Java.
- Java is very suitable for developing cross-platform applications. Almost all common computers and smartphones can run Java. But Python is different - for general needs, both Java and python can handle it. If you need to simulate login and fight against collection, it is more convenient to choose Python. If you need to process complex web pages, parse web content to generate structured data, or perform detailed analysis of web content, you can choose Java.
But what I want to talk about today is the simpler crawler method in Java:
1. Directly request the data structure
2. After the webpage renders the plaintext content, grab the content from the front-end page
Directly request the data structure
For some pages that are not complex, have simple data and do not have encrypted data, we can directly use F12 to view the interface called by the page to obtain data. Then request the data structure directly. This method is the easiest in crawlers, for example:HttpClient、OKHttp、RestTemplate、Hutool
After the webpage renders the plaintext content, grab the content from the front-end page
Java has a special tool for crawlers: Jsoup (official website address: http://jsoup.org/). jsoup is a Java HTML parser that can directly parse a URL address and HTML text content. It provides a very low-effort API to retrieve and manipulate data through DOM, CSS, and jQuery-like manipulation methods.
Example: Let’s take Bing’s picture library as an example
Crawling our brother’s handsome pictures
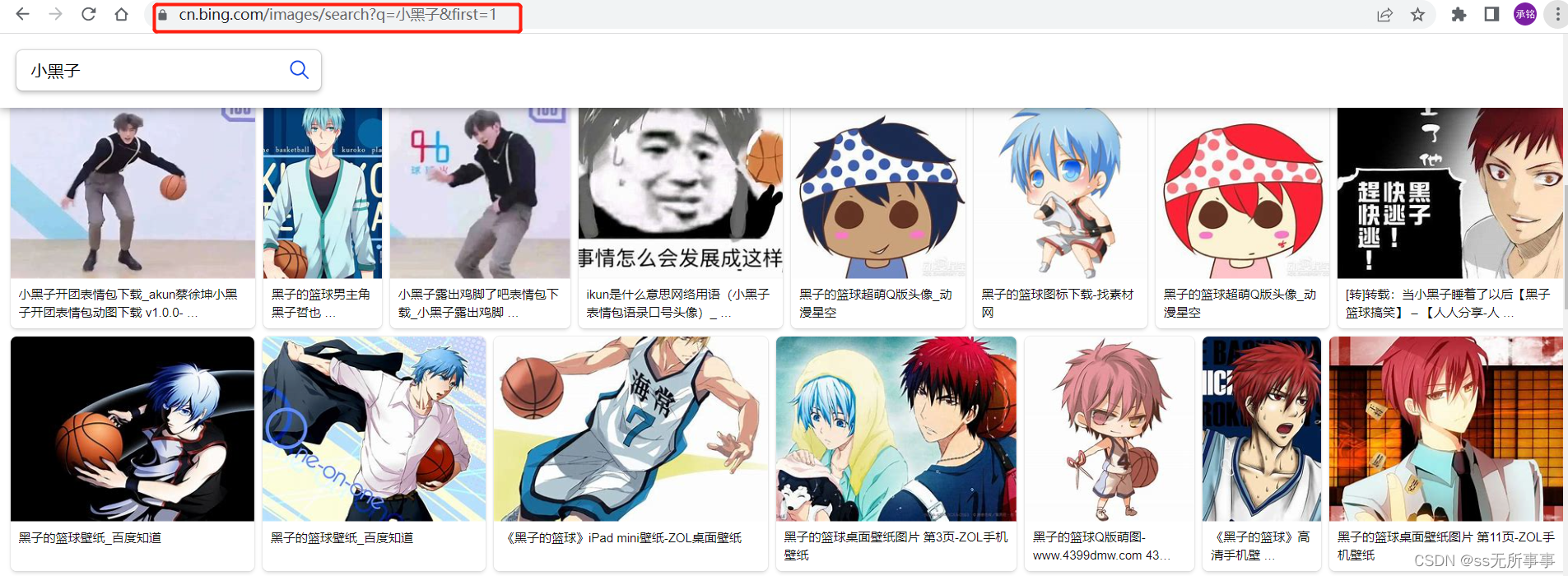
First introduce the jsoup dependency
<--maven 依赖-->
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.15.3</version>
</dependency>
Demo
@Test
void test() throws IOException {
//表示第几个图片开始
int current = 1;
//url地址
String url = "https://cn.bing.com/images/search?q=小黑子&first=" + current;
Document doc = Jsoup.connect(url).get();
//通过css选择器拿到数据
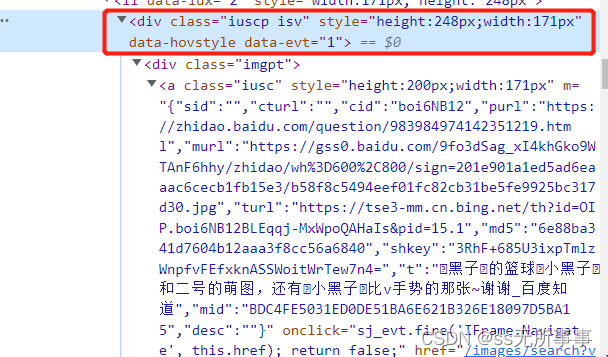
Elements elements = doc.select(".iuscp.isv");
List<Picture> pictures = new ArrayList<>();
for (Element element : elements) {
// 取图片地址(murl)
String m = element.select(".iusc").get(0).attr("m");
Map<String, Object> map = JSONUtil.toBean(m, Map.class);
String murl = (String) map.get("murl");
// System.out.println(murl);
// 取标题
String title = element.select(".inflnk").get(0).attr("aria-label");
// System.out.println(title);
Picture picture = new Picture();
picture.setTitle(title);
picture.setUrl(murl);
pictures.add(picture);
}
System.out.println(pictures);
}
The main thing to use this method is to first understand the css hierarchy of the page you need to crawl
Finally:
Note that crawler technology cannot be abused. Never put pressure on other people’s systems or infringe on other people’s rights!