Article directory
1.Domain Adaptation (DA: Domain Adaptation)
First of all, before introducing these issues, we need to know one point
The success of deep learning is mainly due to the assumption that a large number of labeled data and training sets are independent from the test set and come from the same probability distribution , and then design corresponding models and discriminant criteria to predict the output of the samples to be tested. However, in actual scenarios, the probability distributions of training and test samples are different.
Source domain and target domain:
It can be simply understood that the source domain is the training set, and the target domain is the test set.
Professional terminology: Source Domain is the existing knowledge field; Target Domain is the field to be studied
The difference between the source domain and the target domain is mainly reflected in the data distribution. This problem is divided into three major categories:
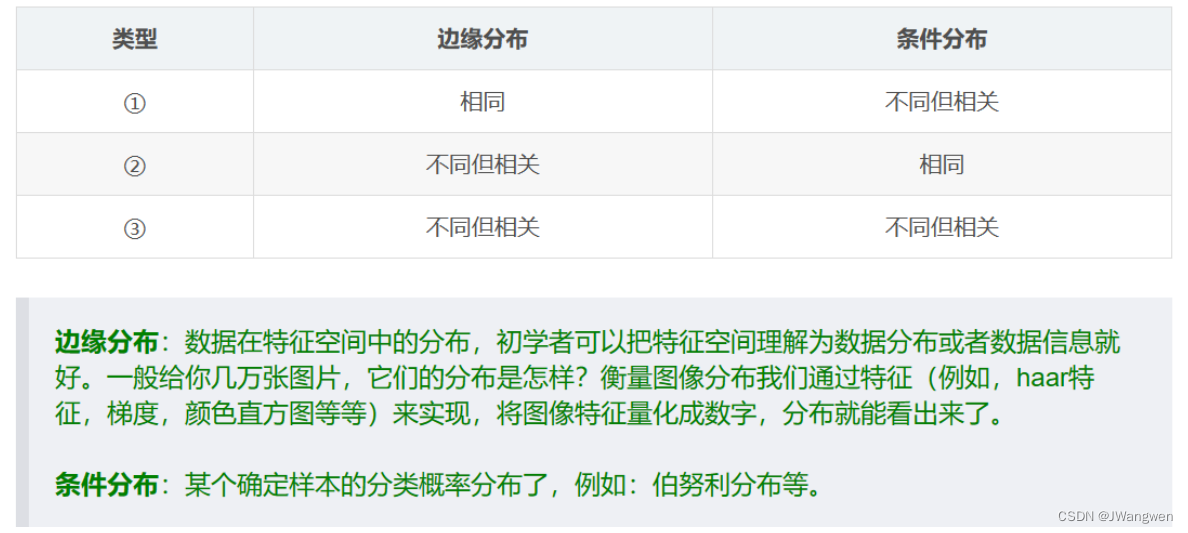
Domain shift:
If training and testing come from different distributions, the model will perform poorly on the test set. This problem is called Domain shift.
DA research questions:
When the source domain and the target domain are not independent and identically distributed, classical machine learning will have an overfitting problem. DA needs to solve the problem that the source domain and the target domain have inconsistent probability distributions, but the task is the same.
DA goals:
How to reduce the difference between different distributions of source and target
Example: For example, if the training set is a variety of British short-haired blue cats (source domain), and you want to train a model (target domain) that can distinguish pastoral cats, the performance of this model will decrease compared to the recognition of British short-haired blue cats. When the distribution of the training data set and the test data set are inconsistent, the model obtained by training on the training data set according to the empirical error minimum criterion has poor performance on the test data set. Therefore, we introduce DA to solve the problem of training set and test data. The problem is that the set probability distributions are inconsistent but all are the same task.
DA main idea:
Map the data features of the source domain and the target domain (such as two different data sets) to the same feature space , so that data from other domains can be used to enhance the training of the target domain.
For example: For example, the source domain in the image below is black and white handwritten numbers, and the target domain is colored numbers. The two distributions are obviously different. We need to train a feature extractor, and then extract the key features of these samples to reduce the difference between different distributions ( The picture below removes the influence of color and extracts numbers as the most critical feature)

DA three methods:
-
Sample adaptation Instance adaptation: Resample the samples in the source domain to make their distribution close to the distribution of the target domain; find out those long samples from the source domain that are most similar to the target domain, and let them join the target domain with high weight Data learning.
-
Feature adaptation Feature adaptation: Project the source domain and the target domain to the common feature subspace, so that the distribution of the two matches, and learn the common feature representation, so that in the public feature space, the distribution of the source domain and the target domain will be the same .

-
Model adaptation: considering the error in the target domain, the source domain error function is modified. Assuming that tens of millions of data are used to train a model, when we encounter a new problem in the data field, we don’t need to find tens of millions of data for training, just migrate the original trained model to In new fields, relatively small amounts of data are often required to achieve high accuracy. The principle of implementation is to take advantage of the similarities between models.

DA can be divided into supervised, semi-supervised and unsupervised DA according to the labeling situation of the target domain data . The most studied in academia is unsupervised DA, which is more difficult and of higher value.
If the target domain data has no labels, it is impossible to use Fine-Tune to throw the target domain data into training. At this time, the unsupervised adaptive method is feature-based adaptation. Because there are many mathematical formulas that can measure the distance between the source domain and the target domain data, the distance can be calculated and embedded in the network as Loss for training, so that the distance can be optimized to gradually become smaller, and the final trained model is The source domain and target domain are placed in a sufficiently close feature space.
DDC, MADA, RevGrad and other algorithms specifically used for unsupervised DA need to be read later
2.Domain generalization (DG)
DG is a further promotion of DA. The difference between DG and DA:
DA can get a small amount of target domain data during training. These target domain data may be labeled (supervised DA) or unlabeled (unsupervised DA), but DG cannot see the target domain data during training .
DG research questions:
Learn a general feature representation from labeled source domains and hope that this representation can also be applied to unseen target domains
DG goals:
Learning domain-independent feature representations
Advantages of DA and DG:
- DA focuses on how to use unlabeled target data, while DG mainly focuses on generalization
- DA is not efficient enough. Every time a new domain comes, it needs to be repeatedly adapted, while DG only needs to be trained once;
- The strong assumption of DA is that the data in the target domain is available, and there are clearly some situations where this cannot be satisfied, or is expensive.
- The performance of DA is higher than that of DG, due to the use of data in the target domain;
Simply put, DA has high performance because it needs to use the data in the target domain, and DG learns a general feature representation, so DG has stronger generalization
There is no doubt that DG is a more challenging and practical scenario than DA: after all, we all like a sufficiently generalized machine learning model that "trains once and applies everywhere".
DG classification:
DG is mainly divided into single-source domain DG and multi-source domain DG.
3. Test-time adaptation (TTA)
TTA research questions:
Adjust the model online on the test sample . After getting the sample, the model needs to make a decision and update immediately .
TTA goals:
Finally, the adjusted model can fit the target domain data distribution or map the target domain features to the source domain feature distribution.
TTA, DA, DG classification:
DG needs to make pre-assumptions about the target domain, finetune pre-train the model in the source domain, and then deploy it without any adjustments.
DA is trained on the source domain, and the model is adjusted during training according to the unlabeled target domain
TTA does not need to make pre-assumptions about the target domain like DG, nor does it need to rely on the source domain like DA, but needs to be adapted during testing.
The difference between TTA and DG is that TTA needs to make timely judgments when adjusting the model online, while DG is learning a general feature representation offline, and DA adjusts the model during training.

Related
- (157 messages) Migration Learning - Domain Adaptation_Raywit's Blog-CSDN Blog
- (157 messages) Domain adaptation and Domain generalization_Sheng Jiuyong's Blog-CSDN Blog
- (157 messages) [TL study notes] 1: Domain Adaptation (Domain Adaptation) method overview_LauZyHou's Blog-CSDN Blog
- (157 messages) Summary of model adaptation methods in the testing phase_PaperWeekly's blog-CSDN blog
- Summary of Test time adaptation method - Zhihu (zhihu.com)