1. Architecture
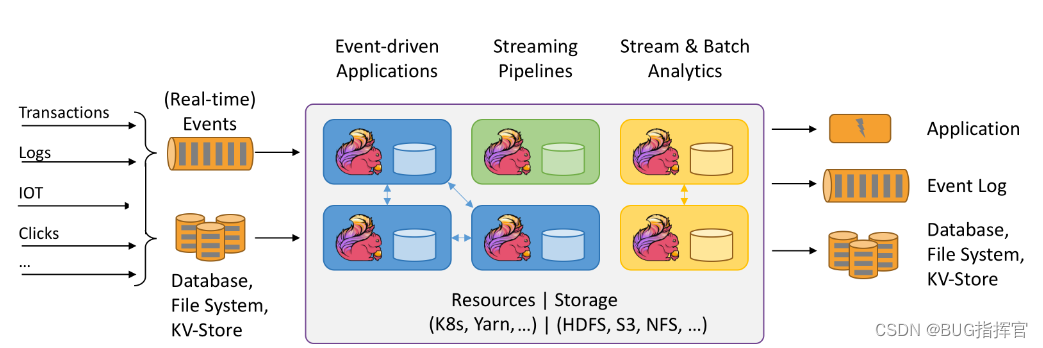
2. Application scenarios
Flink is powerful and supports the development and running of many different kinds of applications. Its main features include: batch-stream integration, sophisticated status management, event time support, and precise one-time status consistency guarantee. With the high availability option enabled, there is no single point of failure. Facts have proven that Flink can scale to thousands of cores, and its state can reach the TB level, while still maintaining high throughput and low latency. Many demanding stream processing applications around the world run on Flink.
Core points:
1. High throughput, low latency
2. Accuracy of results
3. Accurate state consistency guarantee
4. High availability, supporting dynamic expansion

Event-driven applications
What are event-driven applications?
An event-driven application is a stateful application that extracts data from one or more event streams and triggers calculations, state updates, or other external actions based on incoming events.
Event-driven applications are evolved on the basis of traditional applications where computing and storage are separated. In traditional architectures, applications need to read and write to remote transactional databases.
In contrast, event-driven applications are based on stateful stream processing. Data and calculation are not separated. The application only needs to access local (memory or disk) to obtain data. The realization of system fault tolerance depends on periodically writing checkpoints to remote persistent storage. The diagram below depicts the difference between a traditional application and an event-driven application architecture.

What are the advantages of event-driven applications?
Event-driven applications do not need to query remote databases, and local data access enables higher throughput and lower latency. And because regular checkpoint work to remote persistent storage can be completed asynchronously and incrementally, it has little impact on normal event processing. The benefits of event-driven applications extend beyond local data access. Under a traditional layered architecture, multiple applications usually share the same database, so any changes to the database itself (for example, changes in data layout caused by application updates or service expansion) need to be carefully coordinated. In contrast, event-driven applications only need to consider their own data, so the coordination work required when changing data representation or service expansion will be greatly reduced.
Core points:
1. Periodic checkpoints to remote persistent storage can be completed asynchronously and incrementally, with little impact on normal event processing. 2.
Under traditional layered architecture, multiple applications usually share the same database and data security needs to be considered.
3. Event-driven applications only need to consider their own data, and the coordination work required when changing data or expanding services will be greatly reduced.
How does Flink support event-driven applications?
Event-driven applications are subject to the underlying stream processing system's ability to control time and status. Many of Flink's excellent features are designed around these aspects. It provides a rich set of state operation primitives that allow the merging of massive-scale (TB level) state data with exactly-once consistency semantics. In addition, Flink also supports event time and customized window logic with a high degree of freedom, and its built-in ProcessFunction supports fine-grained time control to facilitate the implementation of some advanced business logic. At the same time, Flink also has a Complex Event Processing (CEP) class library that can be used to detect patterns in data streams.
The star feature of Flink for event-driven applications is savepoint. A savepoint is a consistent state image that can be used to initialize any state-compatible application. After completing a savepoint, you can safely upgrade or expand the application, and you can also start multiple versions of the application to complete the A/B test.
Core points:
1. Allow to merge state data of massive scale (TB level) with exactly once consistency semantics.
2. It supports event time and customized window logic with a high degree of freedom, and the built-in ProcessFunction supports fine-grained time control.
3. Savepoint is a consistent state image. After completing a savepoint, you can safely upgrade or expand the application.
Data Analysis Application
What is a Data Analysis Application?
Data analysis tasks require extracting valuable information and metrics from raw data. Traditional analysis methods are usually done by using batch queries, or logging events and building applications based on this limited data set. In order to get the analysis results of the latest data, you must first add them to the analysis data set and re-execute the query or run the application, and then write the results to the storage system or generate a report.
Data analysis can also be done in real time thanks to some advanced stream processing engines. Unlike traditional models that read limited data sets, streaming queries or applications access real-time event streams and continuously generate and update results as events are consumed. This result data may be written to an external database system or maintained in the form of internal state. The dashboard application can accordingly read data from an external database or directly query the application's internal state.
Core points:
1. The traditional way is to extract useful information from raw data to generate reports through batch processing.
2. Streaming queries or applications will access real-time event streams and continue to generate and update results as events are consumed.
As shown in the figure below, Apache Flink supports both streaming and batch analysis applications.

What are the advantages of streaming analytics applications?
Compared with batch analysis, since streaming analysis eliminates the need for periodic data import and query processes, the latency of obtaining indicators from events is lower. Furthermore, batch queries must deal with artificial data boundaries caused by regular imports and input boundedness, which streaming queries do not have to consider.
Streaming analytics, on the other hand, simplifies the application abstraction. A batch query pipeline usually consists of multiple independent components that need to be periodically scheduled to fetch data and execute queries. It is not easy to operate such a complex pipeline. Once a component fails, it will affect the subsequent steps of the pipeline. The entire streaming analysis application runs on a high-end stream processing system such as Flink, covering all steps from data access to continuous result calculation, so it can rely on the failure recovery mechanism provided by the underlying engine.
How does Flink support data analysis applications?
Flink provides good support for both continuous streaming analysis and batch analysis. Specifically, it has a built-in SQL interface conforming to the ANSI standard, which unifies the semantics of batch and streaming queries. The same SQL query yields consistent results whether on a static dataset of recorded events or a real-time stream of events. At the same time, Flink also supports rich user-defined functions, allowing custom code to be executed in SQL. If you need to further customize the logic, you can use the Flink DataStream API and DataSet API for lower-level control. In addition, Flink's Gelly library provides algorithm and building block support for large-scale high-performance graph analysis on batched datasets.
Data Pipeline Application
What is a data pipeline?
Extract-Transform-Load (ETL) is a common method for converting and migrating data between storage systems. ETL jobs are typically triggered periodically to copy data from a transactional database to an analytical database or data warehouse.
Data pipelines and ETL jobs serve similar purposes, transforming, enriching, and moving data from one storage system to another. But data pipelines run in continuous streaming mode, not periodically triggered. So it supports reading records from a source that is continuously generating data and moving them to a destination with low latency. For example: a data pipeline might be used to monitor a file system directory for new files and write their data to an event log; another application might materialize an event stream to a database or incrementally build and optimize an index for a query.
The following diagram depicts the difference between periodic ETL jobs and continuous data pipelines.
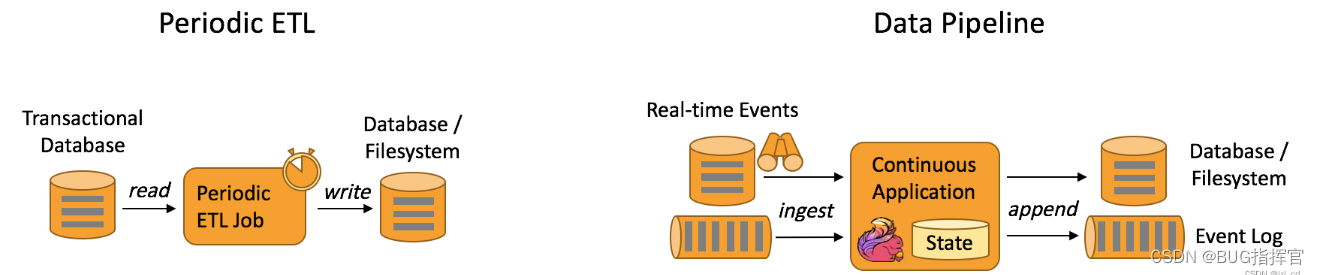
What are the advantages of data pipelines?
Compared with periodic ETL jobs, continuous data pipelines can significantly reduce the latency of moving data to the destination. Additionally, because it can continuously consume and send data, it is more versatile and supports more use cases.
How does Flink support data pipeline applications?
Many common data conversion and enhancement operations can be solved using Flink's SQL interface (or Table API) and user-defined functions. If the data pipeline has more advanced requirements, you can choose the more general DataStream API to achieve it. Flink has built-in connectors for various data storage systems (such as: Kafka, Kinesis, Elasticsearch, JDBC database system, etc.). At the same time, it also provides a continuous data source and data sink of the file system, which can be used to monitor directory changes and write files in a time-partitioned manner.
Layered API
Flink is layered according to the level of abstraction and provides three different APIs. Each API has a different focus on simplicity and expressiveness, and targets different application scenarios.
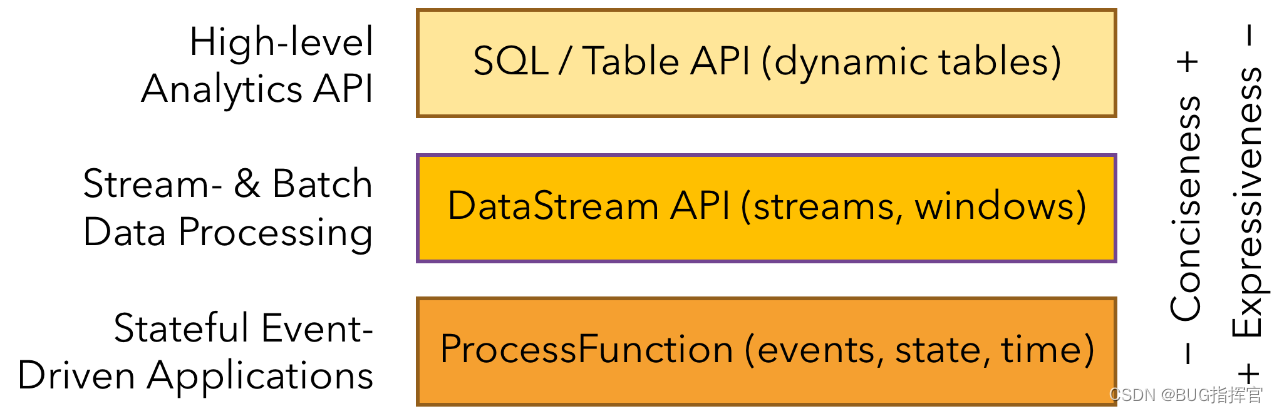
1. The higher the level of abstraction, the simpler the meaning and the easier it is to use.
2. The lower the level, the more specific it is, the richer the expression ability, and the more flexible the use.
Flink VS Spark
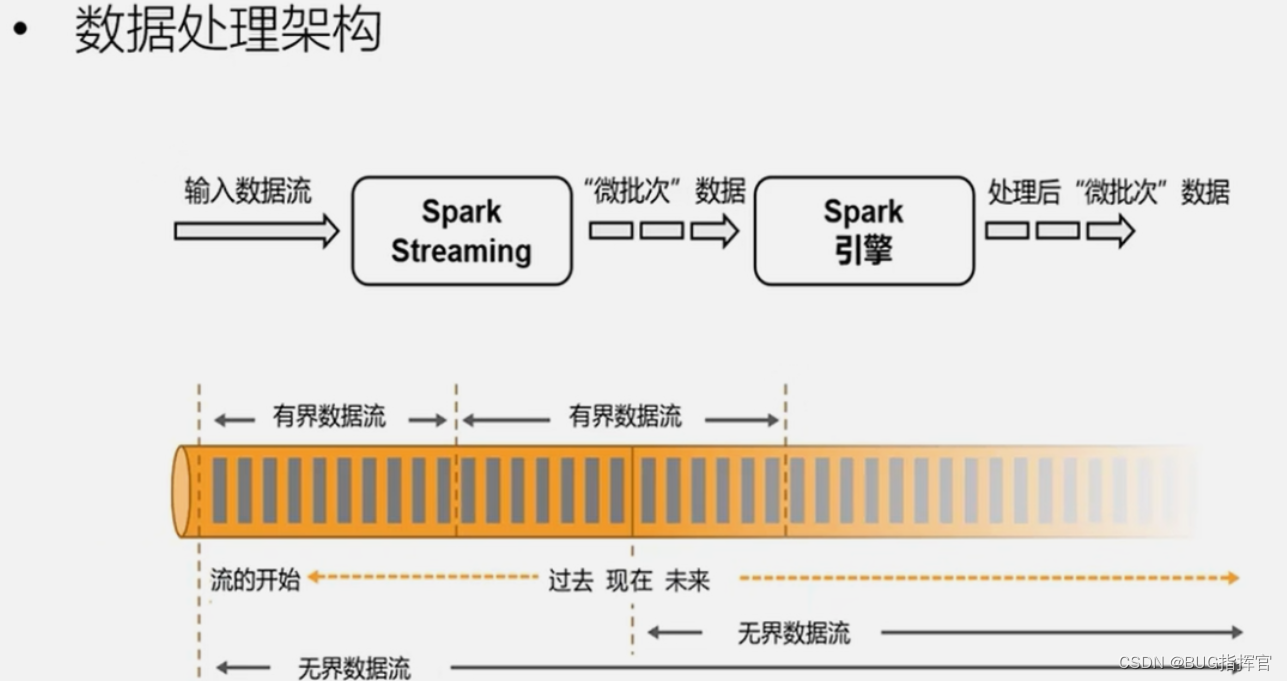
data model
Spark adopts the RDD model. The DStream of Spark Streaming is actually a collection of small batches of data RDD.
The basic data model of flink is data flow and time series.
runtime architecture
Spark is a batch calculation, which divides the DAG into different Stages, and the next one can be calculated only after one is completed.
Flink is a standard stream execution mode. After an event is processed on one node, it can be directly sent to the next node for processing.