BE expansion and contraction of Apache Doris minimalist operation and maintenance (1)
1. Environmental information
Three BE nodes have been deployed and the status shows that they are running normally
hardware information
- CPU :1C
- CPU model : ARM64
- Memory : 2GB
- Hard disk : 36GB SSD
software information
- VM image version : CentOS-7
- Apache Doris version : 1.2.4.1
- Cluster size : 1FE * 3BE
2. Shrinkage
2.1 DROP BACKEND shrink
Note: DROP BACKEND will directly delete the BE, and the data on it will no longer be recoverable! ! !
So it is strongly not recommended to use DROP BACKEND to delete BE nodes. When using this statement, there will be corresponding anti-misoperation prompts.
-- ALTER SYSTEM DROP BACKEND "be_host:be_heartbeat_service_port"; -- 会有误操作提示
-- ALTER SYSTEM DROPP BACKEND "be01:9050"; --直接删除,慎用!
2.2 DECOMMISSION BACKEND shrinkage
DECOMMISSION command description:
- This command is used to safely delete BE nodes. After the command is issued, Doris will try to migrate the data on the BE to other BE nodes, and when all the data is migrated, Doris will automatically delete the node.
- This command is an asynchronous operation. After execution, you can use SHOW PROC '/backends'; to see that the isDecommission status of the BE node is true. Indicates that the node is going offline.
- The command does not necessarily execute successfully. For example, if the remaining BE storage space is not enough to accommodate the data on the offline BE, or the number of remaining machines does not meet the minimum number of copies, the command cannot be completed, and the BE will always be in the state of isDecommission is true.
- The progress of DECOMMISSION can be viewed through SHOW PROC '/backends'; TabletNum, if it is in progress, TabletNum will continue to decrease.
- This operation can be done by:
CANCEL DECOMMISSION BACKEND "be_host:be_heartbeat_service_port";
Order cancelled. After cancellation, the data on the BE will maintain the current remaining data volume. Subsequent Doris will re-balance the load
-- ALTER SYSTEM DECOMMISSION BACKEND "be_host:be_heartbeat_service_port";
ALTER SYSTEM DECOMMISSION BACKEND "be01:9050";
2.2.1 Before scaling down
http://192.168.31.78:8030/System?path=//backends View be node information
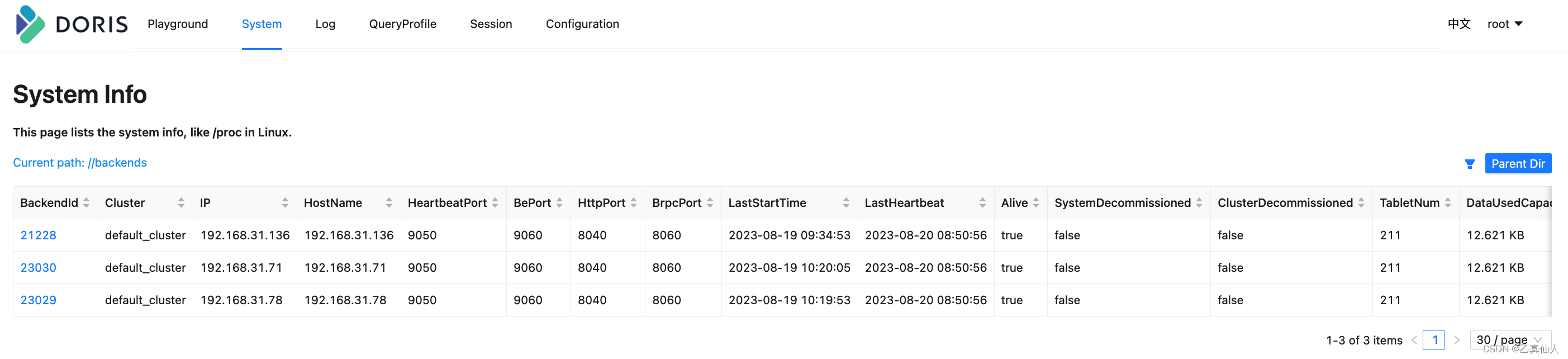
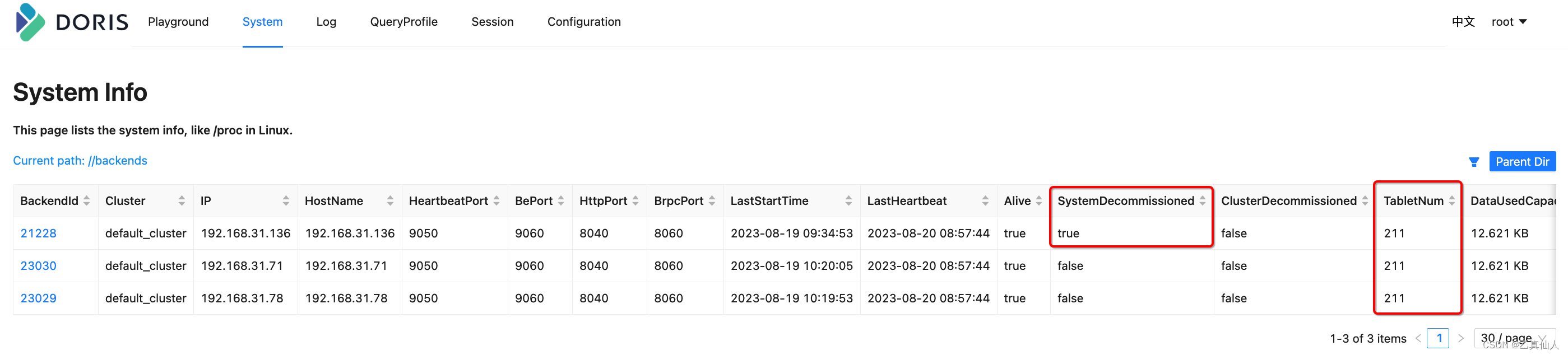
2.2.2 Shrinking
Scaling down failed; the shrinking BE node is always in the state of isDecommission being true , because the number of remaining machines does not meet the minimum number of copies (3 copies).
- Cancel DECOMMISSION BACKEND and adjust the table with 3 copies to 2 copies
-- 取消DECOMMISSION BACKEND
-- CANCEL DECOMMISSION BACKEND "be_host:be_heartbeat_service_port";
CANCEL DECOMMISSION BACKEND "be01:9050";
-- 3副本表调成2副本
-- 非分区部分
ALTER TABLE db.table_name SET ("default.replication_num" = "2");
ALTER TABLE db.table_name SET ("default.replication_allocation" = "tag.location.default: 2");
-- 分区部分
ALTER TABLE zbh_test.dwd_lbu_mbi_bil_income_d02 MODIFY PARTITION (逗号分隔可填写多个分区名) SET("replication_num"="2");
-- 如下图所示tablet数开始减少至2副本的量
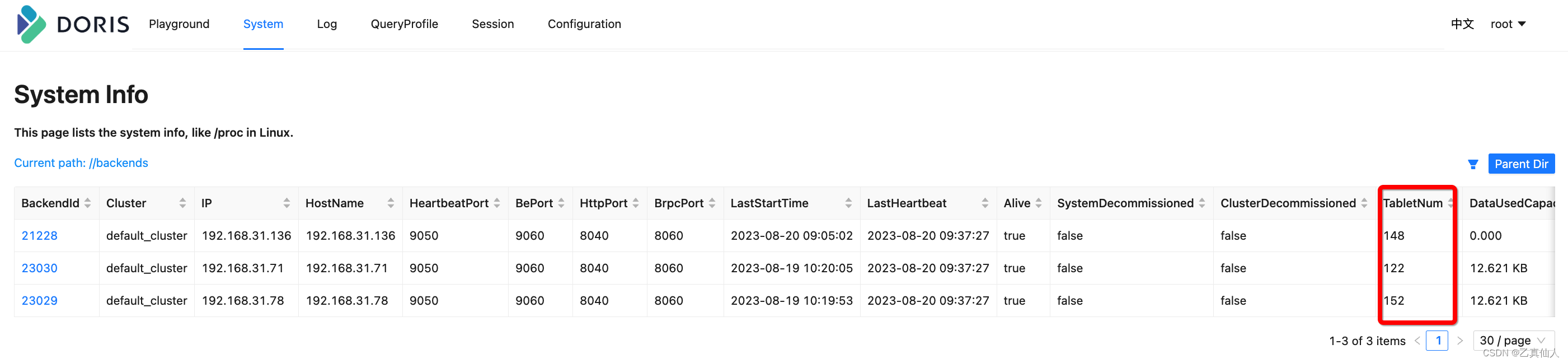
- Re-execute DECOMMISSION BACKEND after meeting the copy requirements for shrinking
-- ALTER SYSTEM DECOMMISSION BACKEND "be_host:be_heartbeat_service_port";
ALTER SYSTEM DECOMMISSION BACKEND "be01:9050";
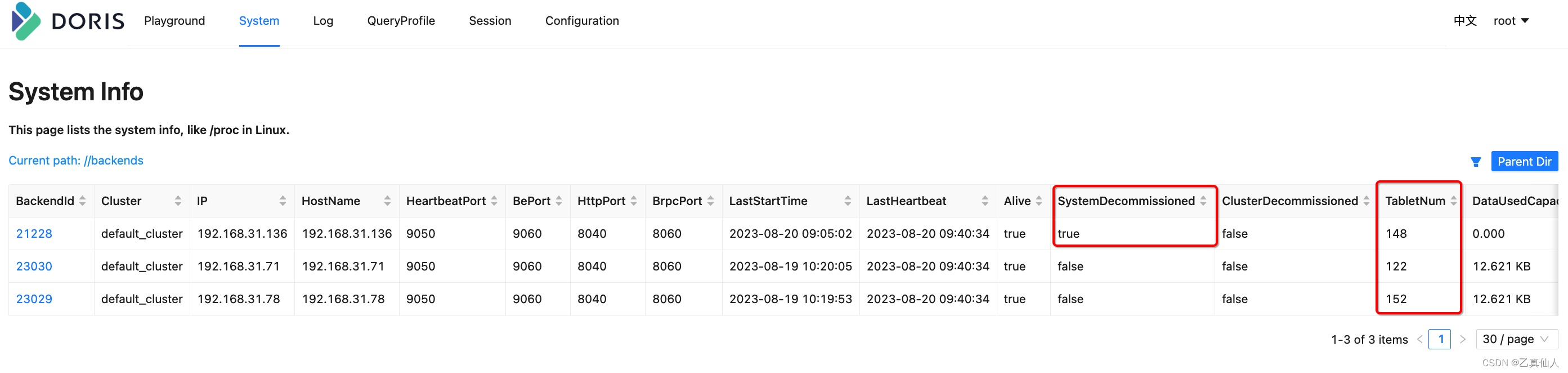
2.2.3 After scaling down
The copy is automatically balanced to non-offline nodes. After the copy is balanced, it will automatically drop the offline be node, but the process needs to stop by itself
# 需要手动停止be进程
sh bin/stop_be.sh
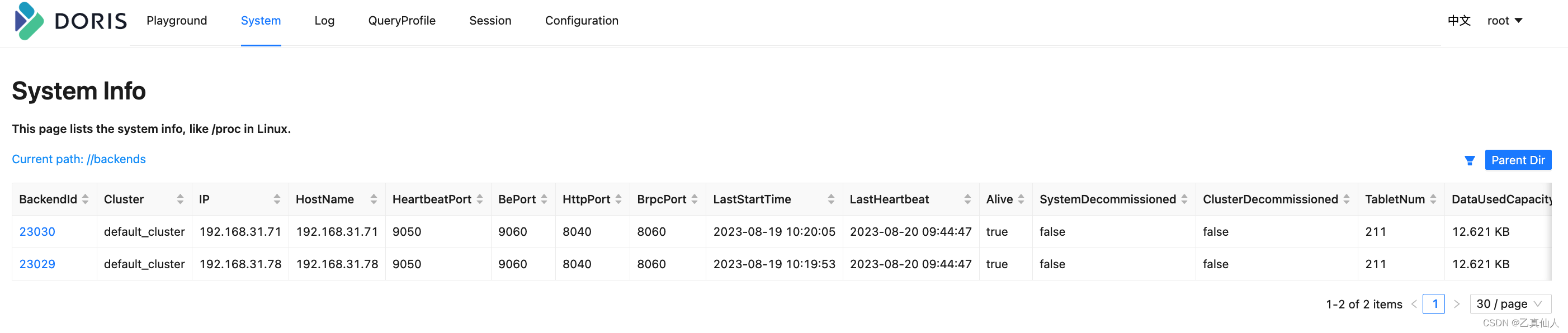
3. Expansion
3.1 Before expansion
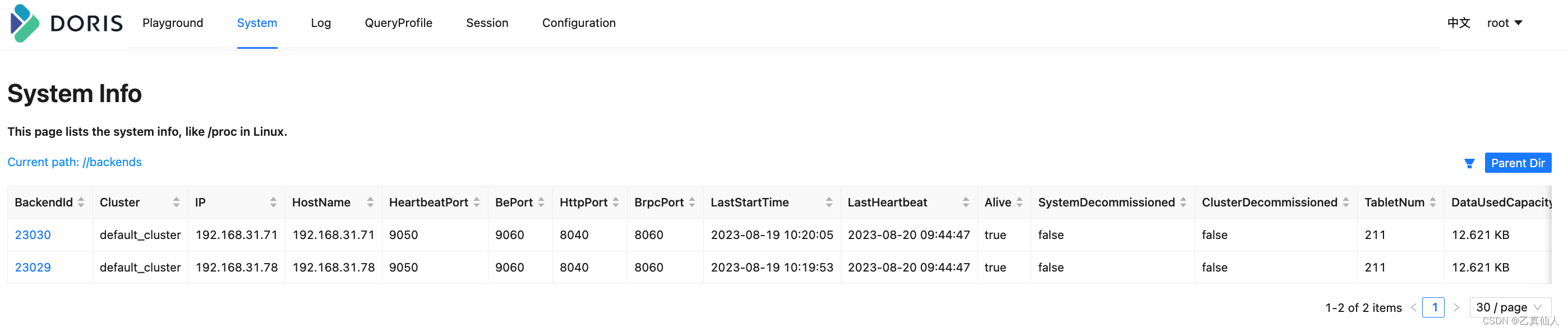
3.2 Expanding capacity
-- 新增be节点,需要确保已经start相应的be进程
alter system add backend "192.168.31.136:9050"
-- 如下图所示新be已经加入集群并开始自动进行数据均衡了
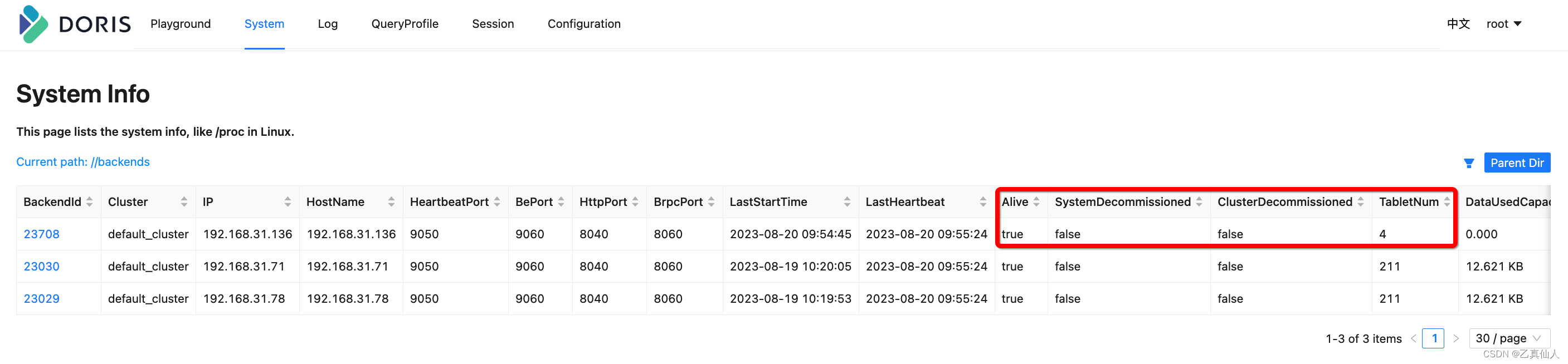
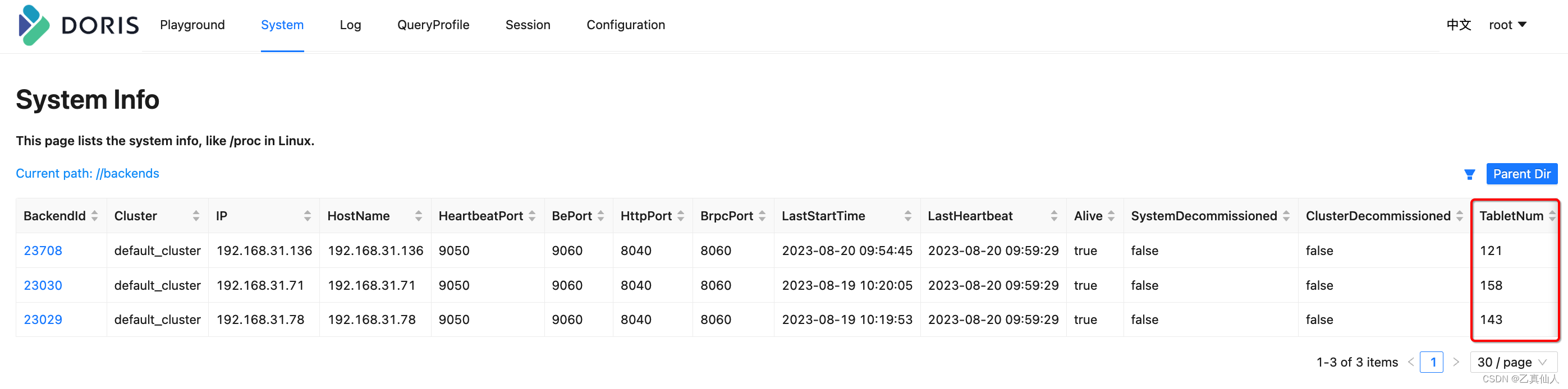
3.3 After expansion
After the data is fully balanced, as shown in the figure below, it is almost equivalent to the tablet distribution of the 2 copies before the be shrinking is completed
Four. Summary
- Capacity expansion will automatically balance data
- Scaling will automatically perform data balance, but you need to pay attention not to DROP directly, you need to go DECOMMISSION and sh stop_be.sh
- Migration efficiency reference: Copy migration started at 16:32 ( 1.590 TB / 141tablets); migration was completed at 17:39, with an average of 1667235m / 4020s = 414m/s (Large tables are time-consuming, you can check the still-migrating tablets through the statistics of weiui); After the migration, the node will be offline, and the show PROC '/backends' will not show the offline node.