Elasticsearch is a distributed, free and open search and analysis engine for all types of data, such as textual, numerical, geospatial, structured and unstructured data. It is built on Apache Lucene, a full-text search engine available for various programming languages. Due to its speed, scalability, and ability to index different types of content, Elasticsearch has been used in a variety of use cases, such as:
- enterprise search
- Logging and Log Analysis
- application search
- business analysis
- Geospatial Data Analysis and Visualization
How does it work?
Instead of storing information as columnar rows of data, Elasticsearch stores complex data structures serialized into JSON documents. Each document consists of a set of keys (names of fields or properties in the document) and their corresponding values (strings, numbers, Booleans, dates, arrays of values, geographic locations, or other types of data). Using a data structure called an inverted index, it lists every unique word that occurs in any document and identifies all documents in which each word occurs.
Field Type - Analyzed or Not Analyzed
String literals in Elasticsearch are either parsed or not. So what exactly does analytics mean? Analyzed fields are fields that have undergone an analysis process prior to being indexed. The results of this analysis are then stored in the inverted index. The analysis process basically involves tokenizing and normalizing chunks of text. The fields are tokenized into terms, and the terms are converted to lowercase. This is the behavior of the standard analyzers, and is the default. However, we can specify our own analyzer if desired, for example if you also want to index special characters, which the standard analyzer won't do. If you want to know more about analyzer, please read the article " Elasticsearch: analyzer ".

We try to use the following commands for word segmentation:
GET _analyze
{
"analyzer": "standard",
"text" : "Beijing is a beautiful city"
}Elasticsearch's standard analyzer converts this text into the following:
{
"tokens": [
{
"token": "beijing",
"start_offset": 0,
"end_offset": 7,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "is",
"start_offset": 8,
"end_offset": 10,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "a",
"start_offset": 11,
"end_offset": 12,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "beautiful",
"start_offset": 13,
"end_offset": 22,
"type": "<ALPHANUM>",
"position": 3
},
{
"token": "city",
"start_offset": 23,
"end_offset": 27,
"type": "<ALPHANUM>",
"position": 4
}
]
}A Quick Introduction to Wildcard Search
Wildcards are special characters that act as placeholders for unknown characters in text values and are a convenient way to find multiple items with similar but not identical data. Wildcard searches are based on character pattern matches between characters mentioned in a query and words in documents that contain those character patterns.
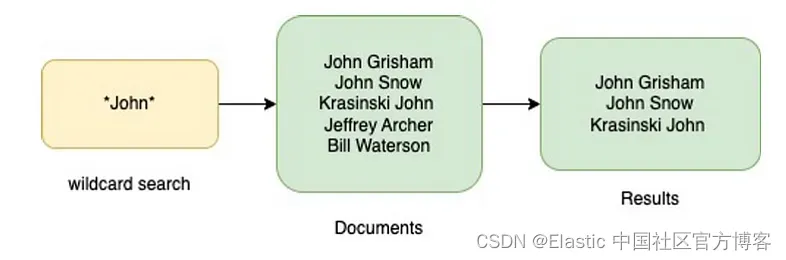
Now that we have a basic understanding of how Elasticsearch works, analyzing fields and what a wildcard search is, let's take a deeper look at what this article is about - string fields and run a wildcard search on them.
String fields and wildcard searches
Every field in Elasticsearch has a field data type. This type indicates the type of data the field contains (such as string or Boolean) and its intended use. The two field types available for strings in Elasticsearch are — text (default) and keyword. The main difference between them is that text fields are analyzed at index time while keyword fields are not. This means that text fields are normalized and broken into individual tokens before being indexed, while keyword fields are stored as-is. Also, since text fields are normalized, they support case-insensitive searches. To achieve the same effect for key fields, we must define a normalizer when creating the index, and then specify the same normalizer when defining the field mapping. For a detailed introduction to nomalizers, read the article " Elasticsearch: Using Normalizers in Word Analysis ".
PUT wildcard
{
"settings": {
"analysis": {
"normalizer": {
"lowercase_normalizer": {
"type": "custom",
"char_filter": [],
"filter": [
"lowercase",
"asciifolding"
]
}
}
}
},
"mappings": {
"properties": {
"text-field": {
"type": "text"
},
"keyword-field": {
"type": "keyword",
"normalizer": "lowercase_normalizer"
}
}
}
}Now for wildcard queries, let's say we have the following documents and we want to run some wildcard searches on them:
PUT wildcard/_doc/1
{
"text-field": "Mockingbirds don’t do one thing but make music for us to enjoy.",
"keyword-field": "Mockingbirds don’t do one thing but make music for us to enjoy."
}A query like the following works fine with text fields:
GET wildcard/_search?filter_path=**.hits
{
"_source": false,
"fields": [
"text-field"
],
"query": {
"wildcard": {
"text-field": {
"value": "*birds*"
}
}
}
}The above search returns results:
{
"hits": {
"hits": [
{
"_index": "wildcard",
"_id": "1",
"_score": 1,
"fields": {
"text-field": [
"Mockingbirds don’t do one thing but make music for us to enjoy."
]
}
}
]
}
}However, the following search will not:
GET wildcard/_search?filter_path=**.hits
{
"_source": false,
"fields": [
"text-field"
],
"query": {
"wildcard": {
"text-field": {
"value": "*birds*music*"
}
}
}
}The result it returns is:
{
"hits": {
"hits": []
}
}The reason is, the words of this field are already analyzed and stored as tokens. Therefore, elasticsearch cannot find the token corresponding to the given expression (*birds*music*).
However, this works for key fields as they are stored as-is. Let's try the following search:
GET wildcard/_search?filter_path=**.hits
{
"_source": false,
"fields": [
"keyword-field"
],
"query": {
"wildcard": {
"keyword-field": {
"value": "*birds*music*"
}
}
}
}The result returned by the above command is:
{
"hits": {
"hits": [
{
"_index": "wildcard",
"_id": "1",
"_score": 1,
"fields": {
"keyword-field": [
"mockingbirds don't do one thing but make music for us to enjoy."
]
}
}
]
}
}Now, let's discuss another string field introduced from ElasticSearch v7.9 - wildcards. This is a specialized field type primarily used for unstructured machine-generated content. For more reading, see the article " Elasticsearch: Find strings within strings faster with the new wildcard field - New in 7.9 ".
Here are the performance statistics for running a few wildcard queries on these 3 field types:
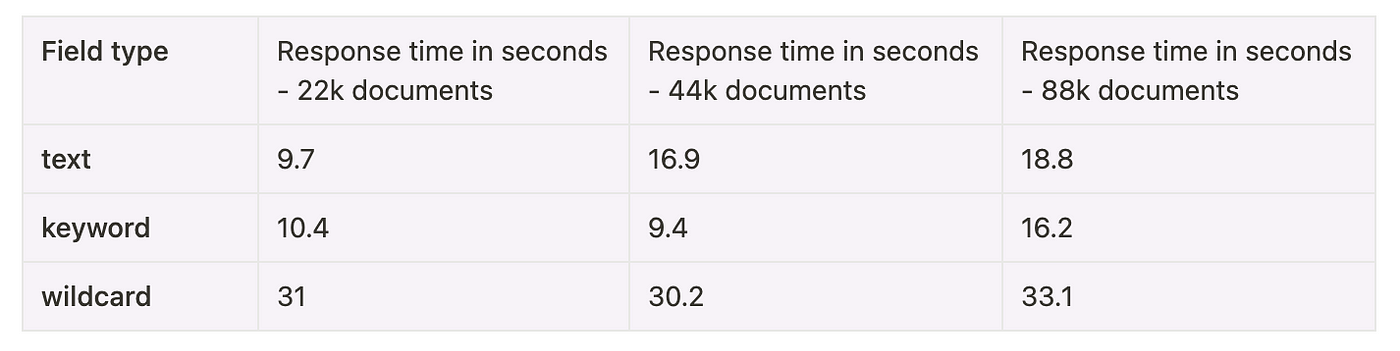
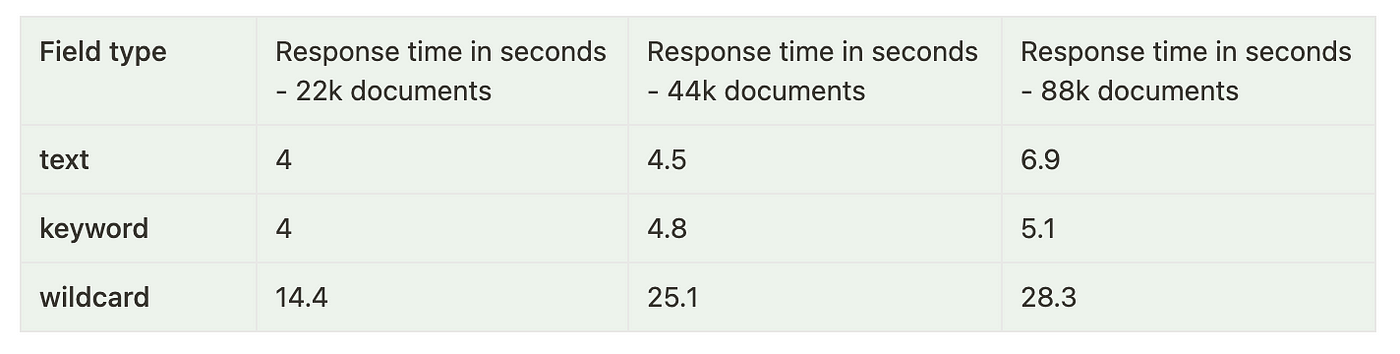
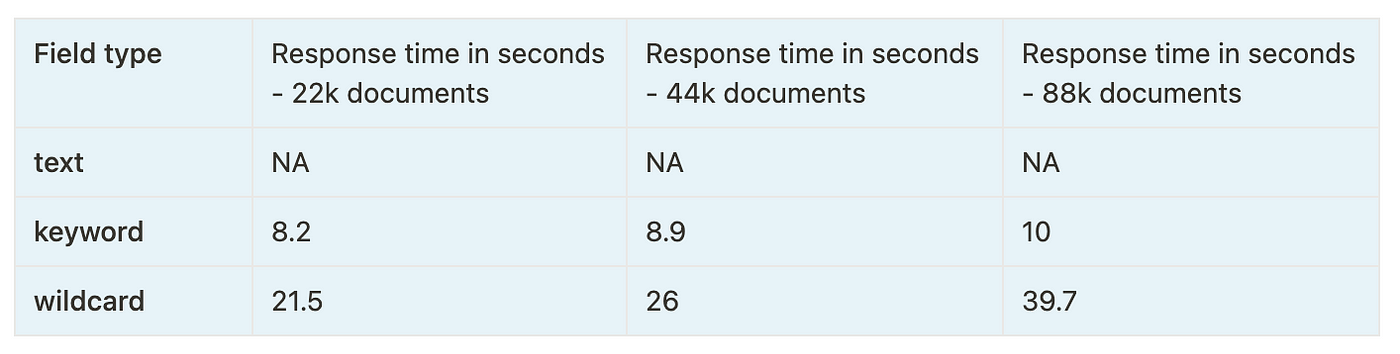
We can clearly see that the performance of the key field is the most consistent across all search queries and index sizes. Text fields also do a decent job, but they can't be used to search for values like *Elastic*stash*, which makes the keyword type the clear winner.
So why introduce wildcard fields? Well, wildcard fields were introduced to address the following limitations that exist for text and keyword fields:
- Text Field - Limits the matching of any wildcard expression to a single token, rather than the original entire value held in the field.
- Keyword fields - Keyword fields are slow when searching for substrings and when there are many unique values. Keyword fields also have the disadvantage of data size limitations. The default string mapping ignores strings longer than 256 characters. This scales up to the Lucene hard limit of 32k for a single token. This can create problems when you try to search system logs and similar documents.
Wildcard fields address the above limitations. Instead of treating a string as a collection of tokens separated by punctuation, it performs pattern matching by first performing an approximate match on all documents, and then applying a detailed comparison to the subset of documents received through matching.
A detailed comparison between text, keyword and wildcard fields can be read here .
The statistics above were obtained by running a search on an elasticsearch index running on v8.9, mapped as follows:
{
"wildcard-search-demo-index": {
"mappings": {
"properties": {
"field1": {
"type": "text"
},
"field2": {
"type": "keyword"
},
"field3": {
"type": "wildcard"
}
}
}
}
}Indexed documents have uniform data across all fields, i.e. all 3 fields in a document have the same value. For example,
"hits": [
{
"_index": "wildcard-search-demo-index",
"_type": "_doc",
"_id": "vlPiHYYB6ikeelRg4I8n",
"_score": 1.0,
"_source": {
"field1": "It started as a scalable version of the Lucene open-source search framework then added the ability to horizontally scale Lucene indices.",
"field2": "It started as a scalable version of the Lucene open-source search framework then added the ability to horizontally scale Lucene indices.",
"field3": "It started as a scalable version of the Lucene open-source search framework then added the ability to horizontally scale Lucene indices."
}
},
{
"_index": "wildcard-search-demo-index",
"_type": "_doc",
"_id": "v1PiHYYB6ikeelRg4I87",
"_score": 1.0,
"_source": {
"field1": "Elasticsearch allows you to store, search, and analyze huge volumes of data quickly and in near real-time and give back answers in milliseconds.",
"field2": "Elasticsearch allows you to store, search, and analyze huge volumes of data quickly and in near real-time and give back answers in milliseconds.",
"field3": "Elasticsearch allows you to store, search, and analyze huge volumes of data quickly and in near real-time and give back answers in milliseconds."
}
}
]To sum up, there are no fixed rules for the selection of field types. It depends on various factors such as data types, different sets of use cases that must be covered, etc.
When setting up a data store, deciding on the field type is a very critical factor as it greatly affects performance and should be decided by considering all possible scenarios and factors.
Elasticsearch also has a query type called wildcard that can be used to run wildcard queries.
It is also worth pointing out that: due to the wildcard search brings a lot of performance problems, and sometimes even consumes a lot of system resources. In the production environment, some suggest to turn off this function to avoid affecting the operation of the system. Suggested reading articles: