With the advent of the digital age, big data has become an indispensable resource in all walks of life. However, effectively analyzing and utilizing big data remains a challenge. In this context, Code Interpreter launched by OpenAI is having a subversive impact on the field of data analysis.
How to disrupt the field of data analysis? With this question in mind, let's discuss it together.
What is data analysis?
Data analysis is the process of collecting, cleaning, transforming and interpreting data to gain meaningful information, insights and knowledge. It involves logical and statistical analysis of large volumes of data to discover patterns, trends, correlations and anomalies to support decision making, problem solving and business optimization. Data analysis is not just about presenting data as charts and graphs, but also about deeply understanding and interpreting the meaning and value behind the data.
The process of data analysis usually includes the following key steps:
-
Data collection: Collect data from various sources, which can be structured (such as tabular data in databases) or unstructured (such as text, images, and audio).
-
Data cleaning: clean and preprocess the data, remove duplicate, missing and erroneous data, and ensure the accuracy and consistency of the data.
-
Data Transformation: Transform and integrate data for subsequent analysis. This may include reshaping, merging and aggregation of data.
-
Exploratory Data Analysis (EDA): Perform a preliminary analysis of data to explore the distribution, associations, and characteristics of the data. This helps to spot patterns and trends in the data.
-
Statistical Analysis: Apply statistical methods to test hypotheses, make inferences, and confirm relationships among data. This can include descriptive statistics, hypothesis testing, regression analysis, etc.
-
Data visualization: Presenting data with charts, graphs, and visualization tools to better understand the meaning and trends of the data.
-
Model building: Based on the analysis results of the data, a mathematical or statistical model is established to predict future trends, classify or cluster, etc.
-
Insights and Interpretation: Interpret analysis results, extract insights and knowledge, and provide support for business decisions.
-
Decision Support: Based on the results of data analysis, it provides suggestions and guidance for the organization's decision-making.
Data analysis has a wide variety of applications in various fields, including business, science, healthcare, finance, marketing, and more. It can reveal information hidden in data, helping organizations better understand market trends, customer needs, business performance, and more to make smarter decisions.
Pain points of traditional data analysis
Traditional data analysis often requires professional data scientists or analysts to write and execute complex queries and algorithms to extract valuable information from big data. This requires in-depth technical knowledge and programming skills, limiting the participation of ordinary business personnel in data analysis. In addition, the data analysis process is usually tedious, requires a lot of time and effort, and the results may not always be satisfactory.
Among them, data visualization is the key to extracting insights from the massive amounts of data we browse every day, allowing us to transform large-scale raw data into graphics that are both visually appealing and easy to understand. However, the specific process of realizing visualization is often daunting, involving complex data processing, design and debugging.
A revolution in data analytics
With ChatGPT Code Interpreter, the only thing we have to do is ask questions. Simply instruct the AI in simple language and it will do the rest, creating detailed and accurate visualizations based on real-world data.
At present, many netizens have shared how they use this AI tool to generate insightful visualization results. For example, Ethan Mollick, a professor at the Wharton School of Business at the University of Pennsylvania, shared his experience of using ChatGPT Code Interpreter. He uploads an XLS file and asks the AI three questions:
"Can you help me understand the content of the data through visualization and descriptive analysis?"
"Can you try to find patterns in it using regression analysis?"
"Can you run regression diagnostics?"
Code Interpreter completed the data processing and gave accurate visualization and analysis results according to Ethan's requirements, demonstrating the powerful ability to easily handle complex data interpretation tasks.
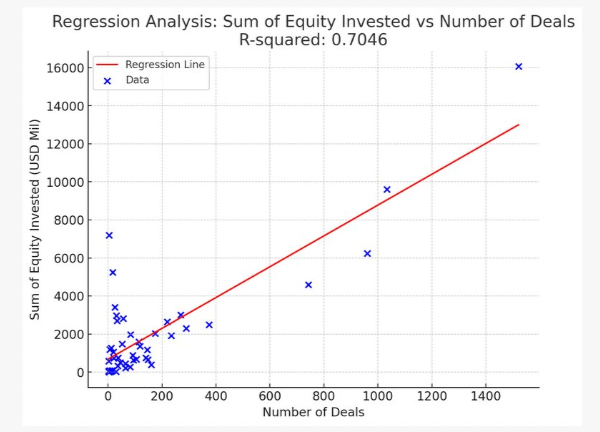
Another user generated a complete HTML heatmap based on the data content, showing the potential to quickly create data visualizations using different datasets.
These real-world examples illustrate the power of ChatGPT Code Interpreter in simplifying the process of data visualization. By asking questions in conversations, users can gain valuable insights and graphical representations of data without writing a single line of code. Ethan called Code Interpreter "the most useful and fun AI mode I've ever used".
Potential challenges and room for improvement
Although Code Interpreter of Smart Q&A Assistant brings many benefits in terms of data visualization, there are still some potential challenges and room for improvement. One of the challenges is the quality and accuracy of the generated code. Due to the ambiguity and uncertainty of natural language, the system may make mistakes when generating code. In order to solve this problem, OpenAI can continuously optimize the training data and model to improve the accuracy of generated code.
Another challenge is the diverse data visualization needs. Different users may have different data visualization needs, covering various chart types and levels of complexity. Smart Q&A assistants need to be able to understand more diverse natural language descriptions and generate codes that adapt to various needs. This requires continuous model training and improvement.
Summarize
The AI big model is becoming a subversive in the field of data analysis, changing our cognition and methods of data analysis. Through natural language dialogue, ordinary people can easily conduct data analysis without writing complicated codes. The emergence of this technology promises to narrow the technology divide and allow more people to participate in data-driven decision-making. Although there are still some challenges, as the technology continues to develop, we can expect AI to bring more innovations and advancements in the field of data analysis. In the era of big data, AI big models open up a new chapter in the field of data analysis.
Book Sweepstakes

brief introduction
A practical guide on data analysis and ChatGPT application, designed to help readers understand the basics of data analysis and use ChatGPT for efficient data processing and analysis. With the advent of the big data era, data analysis has become a key driving force for the development of modern enterprises and industries. This book was born to meet this market demand.
It is divided into 8 chapters, covering basic knowledge of data analysis, common statistical methods, data preparation using ChatGPT, data cleaning, data feature extraction, data visualization, regression analysis and predictive modeling, classification and cluster analysis, and Comprehensive content such as deep learning and big data analysis. Each chapter introduces in detail the use of ChatGPT to solve practical problems in the process of data analysis, and provides a wealth of examples to help readers quickly master relevant skills.
It is suitable for data analysts, data scientists, researchers, business managers, students, and readers interested in data analysis and artificial intelligence technology. By reading this book, readers will master the core concepts and methods of data analysis, and learn to use ChatGPT to bring higher efficiency and value to data analysis work.
Dangdang purchase link: http://product.dangdang.com/29606385.html
Jingdong purchase link: https://item.jd.com/13810483.html
2 books will be given away in this event, and 2 friends will be selected in the comment area to send books
Activity time: Until 20:00 on August 30, 2023
Participation method: Like, bookmark this article, and comment arbitrarily (just don’t fold it)
Lucky draw time: 2023.08.30
Announcement time: 2023.08.30
Notification method: Announced in the exchange group or private message notification
More activities can continue to pay attention to the blog, good luck will always be your turn! ! !