Here's a paper I just saw recently that proposes Dynamic ReLU (Dynamic ReLU, DY-ReLU), which encodes global context as a hyperfunction and adjusts the piecewise linear activation function accordingly. Compared with the traditional ReLU, the extra computational cost of DY-ReLU is negligible, but the representation ability is significantly enhanced, and the implementation is simple, so our existing model can be modified very simply.
Dynamic ReLU (DY-ReLU)
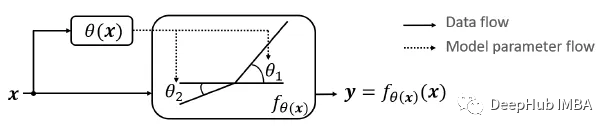
For a given input vector (or tensor) x, DY-ReLU is defined as a function fθ(x)(x) with a learnable parameter θ(x) adapted to the input x, which consists of two functions:
Hyperfunction θ(x): Parameters used to calculate the activation function.
Activation function fθ(x)(x): Generates activations for all channels using parameters θ(x).
1. Function definition
Let a traditional or static ReLU be y = max(x, 0). ReLU can be generalized as a piecewise linear function of the parameters of each channel c.
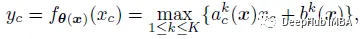
where coefficients ( akc , bkc ) is the output of the hyperfunction (x), as follows:
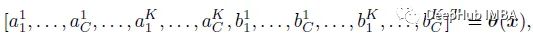
Where K is the number of functions and C is the number of channels. K=2 in the paper.
2. Realization of hyperfunction θ(x)
A lightweight network is used to model the hyperfunction, which is similar to the SE module in SENet (described later).
The output has 2KC elements, corresponding to the residuals of a and b. 2σ(x)-1 is used to normalize the residuals between -1 and 1, where σ(x) represents a sigmoid function. The final output is computed as the sum of initialization and residuals as follows:
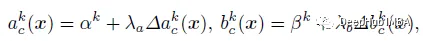
where λ is a scalar, and this formula is our graph above
3. Relationship to previous research
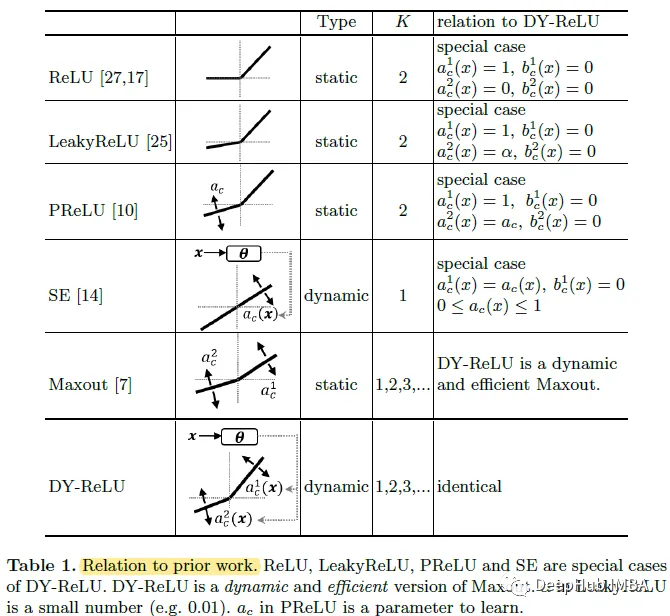
It can be seen that the three special cases of DY-ReLU are equivalent to ReLU, Leaky ReLU and PReLU.
4. Variant of DY-ReLU
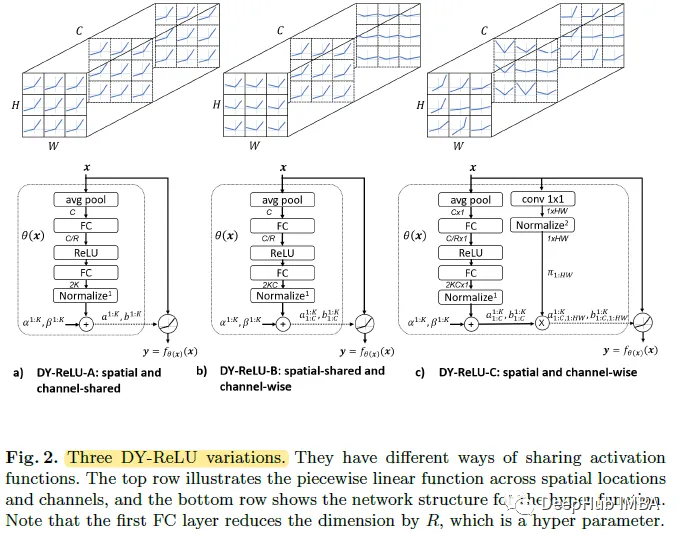
DY-ReLU-A: The activation function is space and channel shared.
DY-ReLU-B: The activation function is spatially shared and channel-dependent.
DY-ReLU-C: The activations are spatially and channel-wise separated.
Result display
1. Ablation research

All three variations improve over the baseline, but channel-separated DY-ReLU (variations B and C) significantly outperforms channel-shared DY-ReLU (variation A).
So according to the above results, use DY-ReLU-B for ImageNet classification, and use DY-ReLU-C for COCO key point detection.
2. ImageNet classification
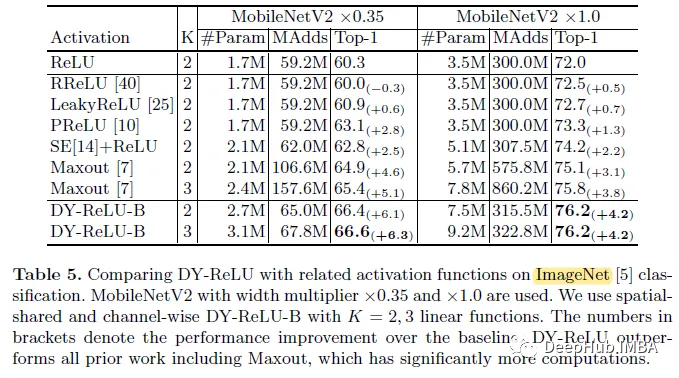
Use MobileNetV2 (×0.35 and ×1.0), replacing ReLU with different activation functions. The proposed method significantly outperforms all previous work including Maxout with more computational cost. This shows that DY-ReLU not only has stronger representation ability, but also has high computational efficiency.
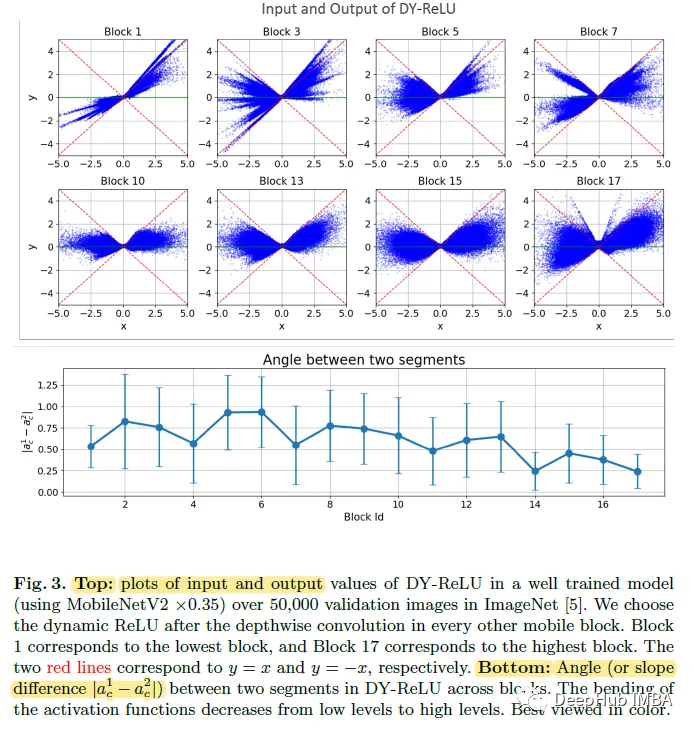
The figure above plots the DY-ReLU input and output values of 50,000 verification images in different blocks (from low to high). It can be seen that the learned DY-ReLU is characteristically dynamic, because for a given input x, the activation value (y) varies within a range (the range covered by the blue dots).
The figure below analyzes the angle between the two segments in DY-ReLU (that is, the slope difference |a1c-a2c|). The activation function has lower curvature at higher levels.
3. COCO key point estimation
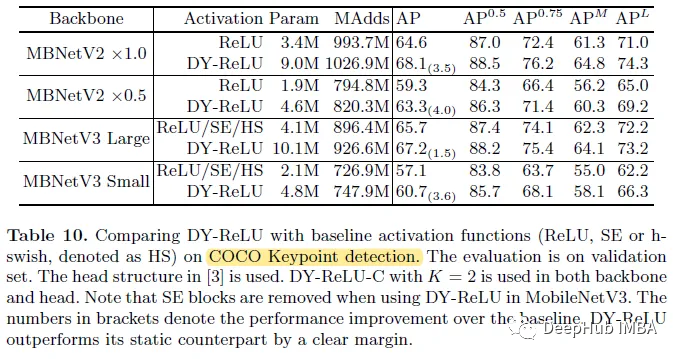
When using MobileNetV3 as the backbone, after removing the SENet module and replacing ReLU and h-Swish with DY-ReLU, the results are also improved.
Summarize
It can be seen that just replacing the existing activation function with DY-ReLU, the model performs significantly better than the baseline model.
This is a paper of ECCV2020, we directly post the address of paperswithcode here, so that it can be used directly
https://avoid.overfit.cn/post/8db206f03cd54167b9eb2d06ebaffc6b
Author: sh-tsang