Redis, as a high-performance key-value database, has received extensive attention and use because of its rich data types and efficient performance. Of the five main data types in Redis, the Zset (Ordered Set) type is perhaps the most complex, but also the most powerful. Zset can not only store key-value pairs, but also assign a score to each element, and then sort according to this score. This makes Zset ideal for implementing leaderboards, timelines, and more.
In this article, we will fully dissect Redis's Zset type. We'll start with the basic concepts and features of Zset, and then dive into its internal implementation and performance optimizations. We will also show how to use Zset in real applications with practical examples. Whether you are new to Redis or a developer with some experience, I believe you can learn some useful knowledge from this article.
Article Directory
1. Zset data type
1.1 Introduction to Zset type
Zset, or Sorted Set, is a complex data type provided by Redis. Zset is an upgraded version of set, which adds a weight parameter score on the basis of set, so that the elements in the set can be arranged in order according to score.
In Zset, the time complexity of adding, deleting and finding elements in the set is O(1). This is due to the fact that Redis uses a data structure called a skiplist to implement Zset.
Key features of Zset include:
-
Uniqueness: Like the set type, the elements in Zset are also unique, that is, the same element can only appear once in the same Zset.
-
Sorting: The elements in Zset are ordered, and they are arranged according to the value of score from small to large. If multiple elements have the same score, they will be sorted lexicographically.
-
Automatic update sorting: When you modify the score value of an element in Zset, the position of the element will be automatically adjusted according to the new score value.
1.2. Zset application scenarios
Redis' Zset (Ordered Set) type is very useful in many scenarios, the following are some common application scenarios:
-
Leaderboards: Zset is great for implementing leaderboards of all kinds. For example, you could have the user's ID as the element, the user's score as the score, and then use Zset to store and sort all the user's scores. You can easily get the user with the highest score, or get the rank of any user.
-
Timeline: You can use Zset to implement the timeline function. For example, you can use published messages as elements, and the time when the messages were published as scores, and then use Zset to store and sort all the messages. You can easily get the latest news, or news from any time period.
-
Weighted queues: Zset can be used to implement weighted queues. For example, you can have tasks as elements, the priority of tasks as scores, and use Zset to store and sort all tasks. You can easily get the highest priority task, or execute tasks in order of priority.
-
Delay queue: You can use the tasks that need to be delayed as elements, and the execution time of tasks as scores, and then use Zset to store and sort all tasks. You can periodically scan Zset for tasks that have reached execution time.
The above are just some common application scenarios of Zset. In fact, Zset has a wide range of applications. As long as you need sorting and ranking functions, you can consider using Zset.
3. The underlying structure of Zset
3.1 Introduction to the underlying structure of Zset
The underlying implementation of Redis's Zset (ordered set) type will choose to use a compressed list (ziplist) or a skip list (skiplist) according to the actual situation. Redis will dynamically switch between these two underlying structures according to the actual situation to find a balance between memory usage and performance.
This mainly depends on two configuration parameters: zset-max-ziplist-entriesand zset-max-ziplist-value.
-
Use compressed list : When the number of elements stored in Zset is less than
zset-max-ziplist-entriesthe value of and the maximum length of all elements is less thanzset-max-ziplist-valuethe value of , Redis will choose to use compressed list as the underlying implementation. The compressed list occupies less memory, but when the data needs to be modified, the entire compressed list may need to be rewritten, and the performance is low. -
Using skip tables : When the number of elements stored in Zset exceeds
zset-max-ziplist-entriesthe value of , or the length of any element exceedszset-max-ziplist-valuethe value of , Redis converts the underlying structure from a compressed list to a skip table. The performance of searching and modifying data in the jump table is high, but it also takes up more memory.
Both of these parameters can be set in the Redis configuration file. By adjusting these two parameters, you can choose to save memory or improve performance according to your application characteristics.
3.2. Compressed list (ziplist)
A compressed list is a special encoding structure designed to save memory by storing all elements and fractions together compactly. The advantage of this method is that it occupies less memory, but when the data needs to be modified, the entire compressed list may need to be rewritten, and the performance is low. When the number of elements stored in Zset is small and the string length of the elements is short, Redis will choose to use the compressed list as the underlying implementation.
A compressed list has the following structure:
+---------+---------+--------+---------+---------+---------+--------+
| zlbytes | zltail | zllen | entry_1 | entry_2 | ... | zlend |
+---------+---------+--------+---------+---------+---------+--------+
Ps: In the source code of Redis, the structure of the compressed list (ziplist) is not directly defined as a C structure, but a continuous memory is operated through a series of macros and functions.
| Attributes | illustrate |
|---|---|
| “zlbytes” | A 4-byte integer, indicating the number of bytes occupied by the entire compression list, including <zlbytes>its own size. |
| "golden" | A 4-byte integer representing the offset of the last element in the compressed list. This offset is relative to the starting address of the entire compressed list. |
| “zllen” | A 2-byte integer representing the number of elements in the compressed list. If the number of elements exceeds 65535, then this value will be set to 65535, and the entire compressed list needs to be traversed to get the actual number of elements. |
| “entry” | Compress the elements in the list, each element consisting of one or more bytes. The first byte of each element (also known as "entry header") is used to indicate the length of the element and the encoding method. |
| “zlend” | A byte with a value of 255 indicating the end of the compressed list. |
In Zset, each element and its score will be stored as an independent element in the compressed list, and the elements and scores will be stored alternately, that is, the first element is the member, the second element is the score, and the third element is member, the fourth element is the score, and so on.
The advantage of the compressed list is that it occupies less memory, but when the data needs to be modified, the entire compressed list may need to be rewritten, and the performance is low.
3.3, skip list (skiplist)
A jump table is an ordered data structure that can be quickly searched. It achieves fast search by maintaining a multi-level index. The advantage of this method is that the performance of searching and modifying data is high, but it also takes up more memory. When the number of elements stored in Zset is large, or the string length of the elements is long, Redis will choose to use the jump table as the underlying implementation.
A skip list (skiplist) is an ordered data structure that can be quickly searched. It achieves fast search by maintaining a multi-level index.
In the source code of Redis, the structure of the jump table is defined as follows:
typedef struct zskiplistNode {
robj *obj;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned int span;
} level[];
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
in:
-
zskiplistNodeThe structure represents a node in the skip list and contains an element object (obj), a score (score), a pointer to the previous node (backward), and an array of layers (level). Each level contains a pointer to the next node (forward) and a span (span) representing the current node to the next node. -
zskiplistThe structure represents a skip table, including the head node (header), the tail node (tail), the number of nodes in the skip table (length), and the maximum number of layers of the current skip table (level).
The time complexity of the lookup, insertion, and deletion operations of the skip list is O(logN), where N is the number of elements in the skip list. This makes skip tables highly performant when handling large amounts of data.
The jump table adds a multi-level index on the basis of the linked list, and realizes the quick search of elements through the special jump of the multi-level index position
For example, to find 27 below, you need to traverse 6 times
First-level index (one element per interval):

One index, traversing 5 nodes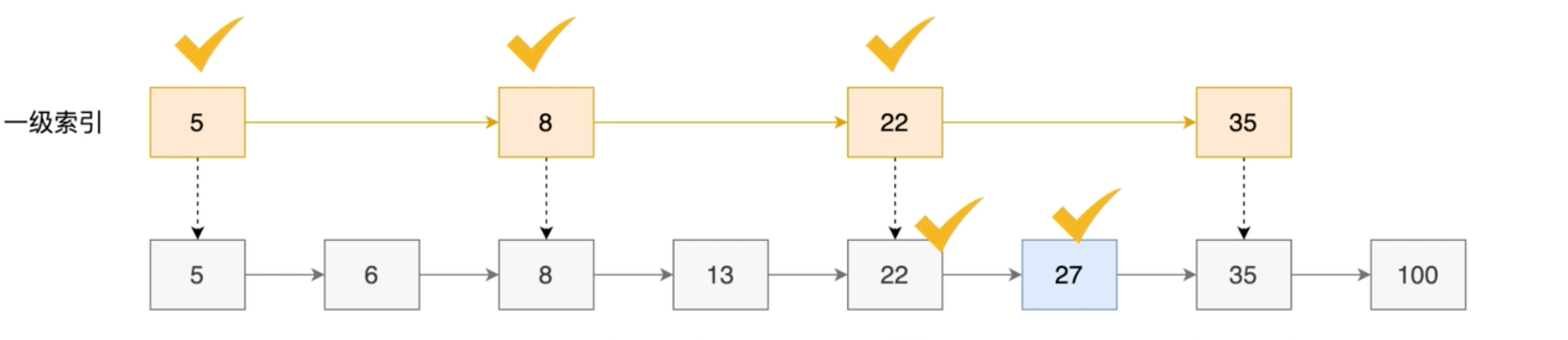
Secondary index (on the basis of an index, every element is spaced):
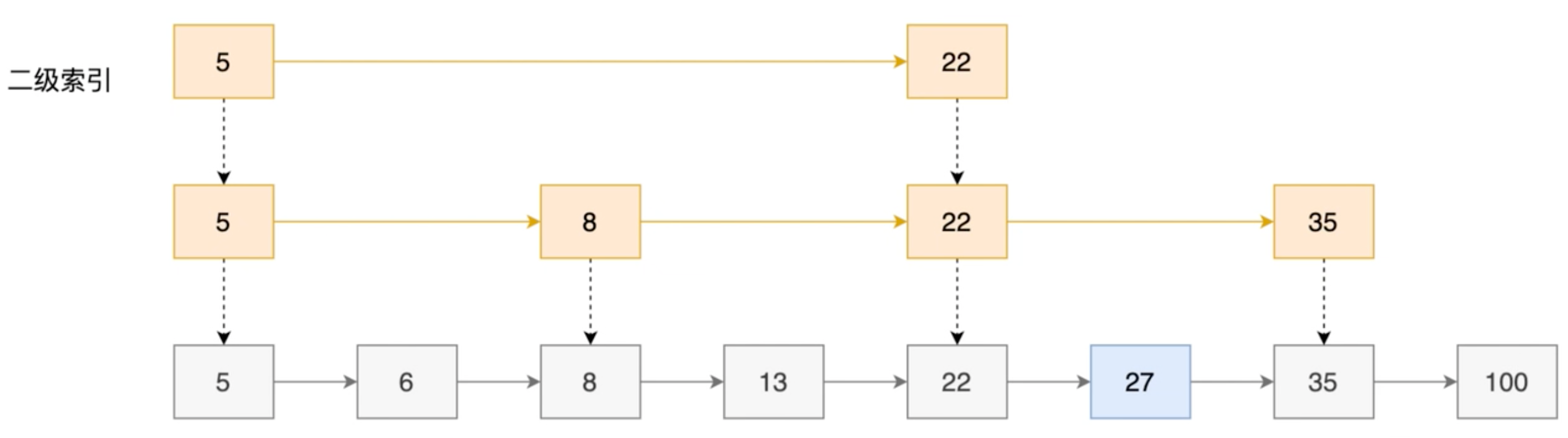
Two indexes, traversing 5 nodes
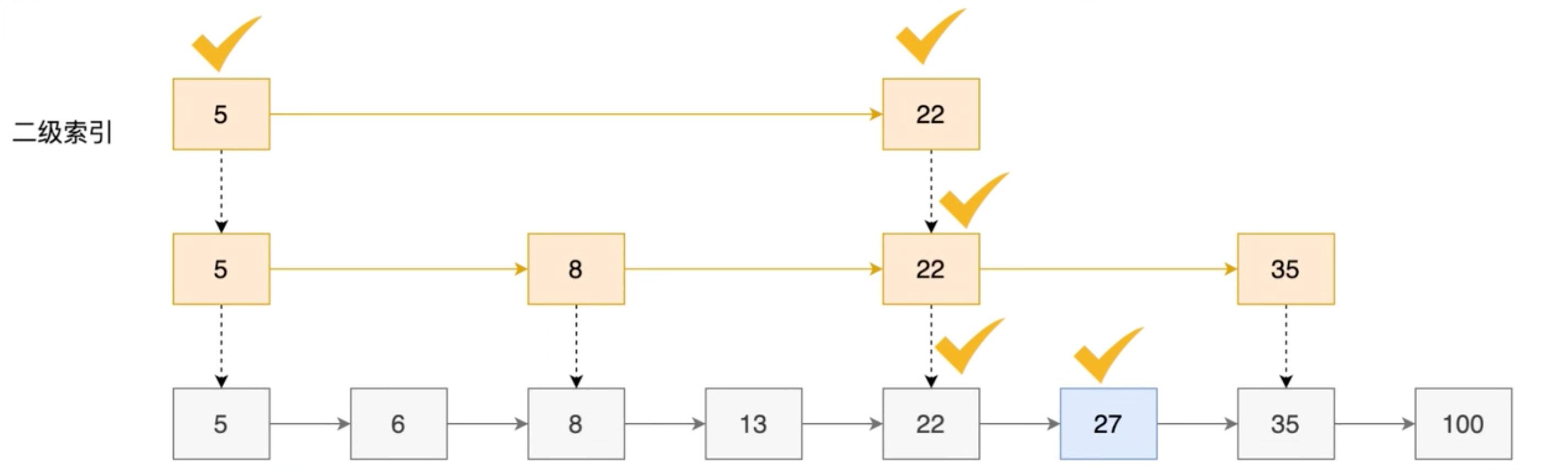
The idea used by itself is similar to the dichotomy
3.4, Redis jump table and MySQLB+ tree
Both MySQL's B+ tree and Redis's jump table are data structures used to store ordered data, but they have some key differences that make them have their own advantages in different scenarios and uses.
-
Structural difference: B+ tree is a multi-way search tree, each node can have multiple child nodes, and jump list is a data structure based on linked list, each node has only one next node, but can have multiple fast channels point to the next node.
-
Space utilization: The disk read and write operations of the B+ tree are in units of pages (usually 4KB). Each node stores multiple key-value pairs, which can make better use of disk space and reduce I/O operations. The space utilization of the jump table is relatively low.
-
Insertion and deletion operations: The insertion and deletion operations of the jump table are relatively simple, the time complexity is O(logN), and there is no need for complex node splitting and merging operations like the B+ tree.
-
Range query: All leaf nodes of the B+ tree form an ordered linked list, so it is very suitable for range query. Although the jump table can also perform range queries, the efficiency is relatively low.
Therefore, B+ trees and skip lists cannot simply replace each other. In scenarios that require heavy disk I/O operations and range queries, such as database indexes, B+ trees may be a better choice. In scenarios where memory operations are mainly performed and frequent insertion and deletion operations are required (such as Redis), skip tables may be more advantageous.
Why does Mysql use B+ tree instead of jump table?
Mysql database is a persistent database, that is, it is stored on the disk, so less disk IO is required when querying, and there are many scenarios where Mysql reads more and writes less. Obviously, B+ tree is more suitable for Mysql.
Why does Redis's ZSet use a jump table instead of a B+ tree
Redis is memory storage, and there is no IO bottleneck, so the time-consuming of jumping the number of layers of the table is negligible, and no overhead is required to balance the data structure (more writes) when inserting data.
3. ZSet common commands
2.1. Add operation
In Redis, ZADDcommands are used to add one or more members to a sorted set (Zset), or to update the score of an existing member. Its basic syntax is as follows:
ZADD key score member [score member ...]
where keyis the name of the ordered set, scoreis the score of the member, and memberis the value of the member. You can add one or more members at a time.
For example, you can myzsetadd a member to a sorted set named onewith a score using the following command 1:
ZADD myzset 1 one
If you want to add multiple members at once, you can list their scores and values in sequence after the command, for example:
ZADD myzset 1 one 2 two 3 three
This command myzsetadds three members to the set with scores , 1, 2and 3.
If the added member already exists in the sorted set, its score will be updated with the new value, and the member's position in the set will change accordingly.
2.2. Return the specified member score
In Redis, ZSCOREthe command is used to return the score of the specified member in the ordered set (Zset). Its basic syntax is as follows:
ZSCORE key member
where keyis the name of the sorted set and memberis the member whose score is to be queried.
For example, you can use the following command to query the score of myzsetthe member in the sorted set named one:
ZSCORE myzset one
If the specified member exists in the sorted set, the command returns the score for that member. The command returns if the specified member does not exist in the sorted set nil.
It should be noted that ZSCOREthe score returned by the command is a floating-point number in the form of a string.
2.3. Return the ranking of the specified member
In Redis, ZRANKthe command is used to return the rank of a specified member in a sorted set (Zset), where the score values are ordered from low to high. Its basic syntax is as follows:
ZRANK key member
where keyis the name of the sorted set and memberis the member to query for rank.
For example, you can use the following command to query the rank of myzsetthe member in the sorted set named one:
ZRANK myzset one
If the specified member exists in the sorted set, the command returns the rank of the member. Ranking is zero-based, that is, the member with the lowest score is ranked zero.
The command returns if the specified member does not exist in the sorted set nil.
It should be noted that ZRANKthe rank returned by the command is an integer in the form of a string.
2.4. Other Zset commands
Some other common commands of Zset in Redis are:
-
ZREVRANK key member: Returns the index of the specified member in the sorted set, sorted by score value from high to low.
-
ZRANGE key start stop [WITHSCORES]: Return the members in the specified interval in the ordered set.
-
ZREVRANGE key start stop [WITHSCORES]: Returns the members in the specified interval in the sorted set, and the score value is from high to low by index.
-
ZREM key member [member ...]: Remove one or more members of the sorted set.
-
ZCARD key: Get the number of members of the ordered set.
-
ZCOUNT key min max: Calculates the number of members with a specified interval fraction in an ordered set.
-
ZINCRBY key increment member: Adds an increment to a member in an ordered set.
The above are just some common commands of other Zse Hash commands. For more commands and detailed usage methods, you can refer to the official documentation of Redis.