LEQNet: Light Earthquake Deep Neural Network for Earthquake Detection and Phase Picking Paper Reading Notes
Summary
- This paper designs a lightweight deep neural network model
- The model can run on lightweight edge devices
- Deep learning model size reduction using deeper bottleneck recurrent structured depthwise separable convolutions
- Trained using the Stanford earthquake dataset
- The benchmark EQTransformer model size is reduced by 87.68% but the performance of our model is comparable to that of EQTransformer
INTRODUCTION
- Traditional P/S wave detection method: STA/LTA uses short-term and long-term average values of continuous seismic wave travel amplitudes to process seismic signals. Disadvantages: need to go out of various noises caused by the geographical location and environment of seismic monitoring equipment
- PhaseNet EQTransformer uses deep learning methods to detect seismic signals
- EQTransformer uses an encoder and three decoders to compose them to compress and restore data, using long short-term memory network LSTM and attention mechanism connection, EQTransoformer model outputs the probability statistics map of earthquakes and P/S waves
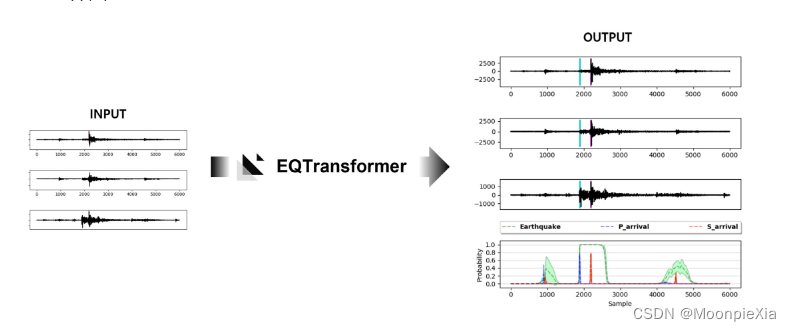
The green dotted line in the figure above indicates the probability of an earthquake, the blue dotted line indicates the starting point of the P wave, and the red dotted line indicates the starting point of the S wave
-
Although the EQTransformer model can detect earthquakes and P/S phase picking with high accuracy, it is almost impossible to deploy on seismic instruments equipped with limited computing resources
-
LEQNET uses various lightweight deep learning techniques, such as recursive deeper bottleneck depthwise separable convolution to reduce the size of deep learning models, using the STEAD dataset evaluation system LEQNET not only greatly reduces parameters, but also has no significant performance drop
-
LEQNet consists of four main parts: an encoder using depthwise separable convolution with recurrent CNN, a decoder using depthwise separable CNN with recurrent CNN, residual bottleneck CNN and LSTM & Transformer
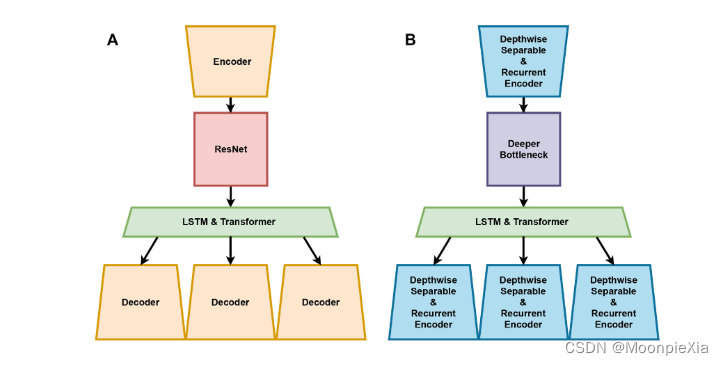
Baseline model EQTransformer
-
EQTransformer uses the structure designed by encoder, decoder, ResNet and LSTM and Transformer. The encoder consists of seven convolutional neural network (CNN) layers. In terms of seismic signals, this reduces the STEAD seismic signal data to lower dimensions and allows reducing the number of parameters in the model
-
EQTransformer has three decoders, ResNet consists of five residual blocks, and each residual block output adds input and output in two linearly connected CNN layers. The introduction of residuals avoids the performance degradation caused by a large number of layers , LSTM learns the sequential features extracted by the encoder, and the network carries the features of the seismic signal to each decoder
-
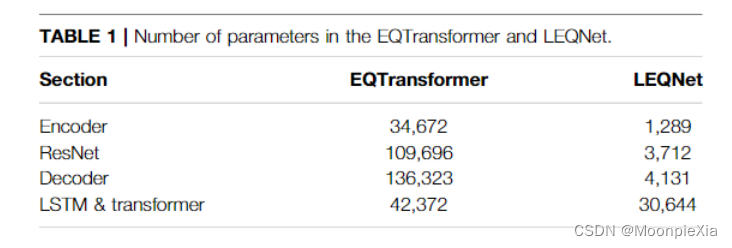
The EQTransformer structure uses a total of 323,063 parameters. A total of 34,672 parameters were used by the encoder, 109,696 by ResNet, and 42,372 by LSTM and Transformer.
Technologies used by LEQNET
- LEQNet consists of four main parts: an encoder using a depthwise separable convolution with a recurrent CNN, a decoder using a depthwise separable CNN with a recurrent CNN, a residual bottleneck CNN and LSTM, and a Transformer.
The following figure shows the amount of parameters for each part:
Model Lightweight Technology
Depthwise Separable CNN Depth Separable Convolution
-
Depthwise convolution extracts channel features by performing a convolution operation on each channel, so the input and output channels contain the same number of channels
-
Pointwise convolution compresses data at the same location within each channel. Extract features between channels, control the number of channels between input and output, when the convolution operation in CNN is redundantly performed between multiple channels, depth separable convolution reduces the large amount of calculations required between channels
Deeper bottleneck architecture BottleNeck
Using multiple small convolution kernels instead of one large convolution kernel greatly reduces the amount of parameters
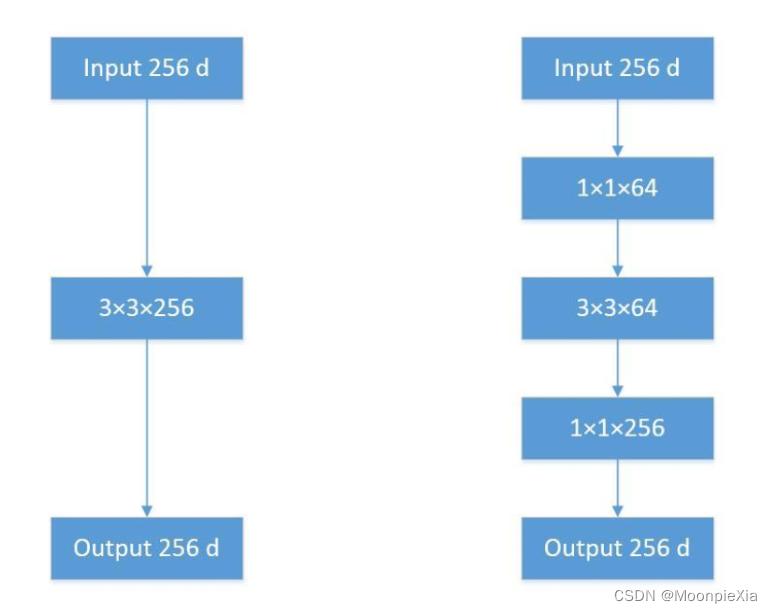
-
The first one directly uses the 3 x 3 convolution kernel 256-dimensional input to pass through the convolution layer, and the output gets a 256 feature map parameter amount: 256 x 3 x 3 x 256 = 589824
-
The second one uses 1x1 first, then uses 3 x 3 and then uses 1x 1, the parameter amount is 256 x 1 x 1 x 64 + 64 x 3 x 3 x 64 + 64 x 1 x 1 x 256 = 69632
-
The number of parameters is greatly reduced!
Recurrent CNN Recursive CNN
- Recursive CNN is a concept of reusing the output of a CNN layer
- To use a recursive CNN the input and output need to have equal number of channels and same kernel shape
- We apply recursive CNN to encoder and decoder separately to reduce model size by reusing parameters
- where the convolutional layers are reused without introducing new layers to achieve better performance, saving a lot of parameters due to the reuse of layers
- Can reduce the memory access cost (MAC), because the reused layer parameters can only be fetched once
paper:
Convolutional Neural Networks with Layer Reuse
LEQNET
- A detection model is learned from 50,000 sets of seismic data and noise data sampled by STEAD, and the learning process is repeated for ten cycles
- Seismic detection probability and thresholds for P and S phase picking are set to detection probability = 0.5, P = 0.3 and S = 0.3 Benchmark EQTransformer
structure
- Depthwise separable convolutions are applied to the encoder and decoder in the feature compression and decompression steps
- deeper bottleneck
- Recursive CNN greatly reduces memory access time and reduces model size by only obtaining parameters once
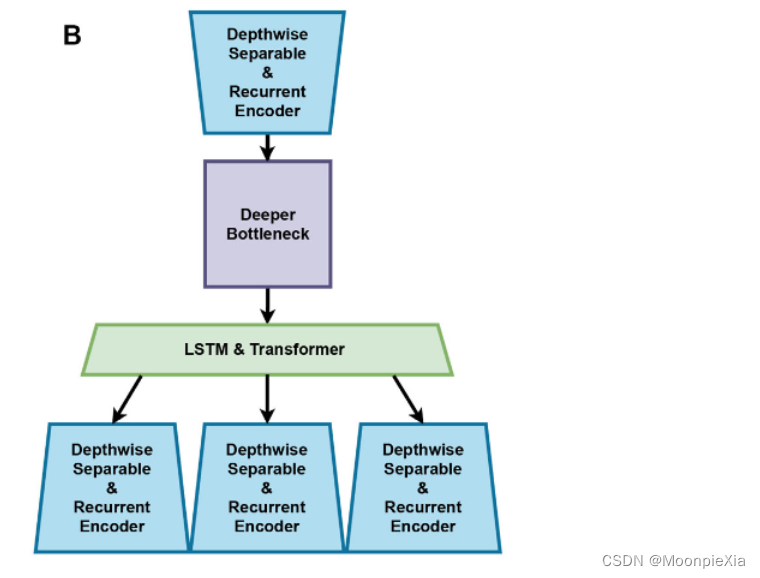
- The encoder and decoder in LEQNET are composed of four layers of BottleNeck. The number of output channels of the encoder is 32, which is similar to the number of input channels. EQTransformer is 64
Model size reduction
LEQNet greatly reduces the number of parameters and calculation time through lightweight technology. Compared with EQTransformer, the number of parameters of LEQNet in this study is reduced by 88%. The number of counted floating point operations has been reduced from 79687040 to 5271488. These results reduce the model size by about 79% compared to EQTransformer (4.5MB down to 0.94MB)
performance comparison
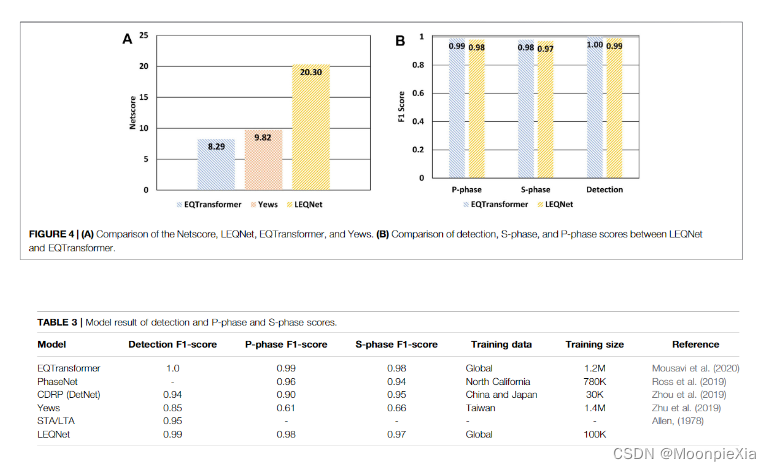
- Comparing LEQNet to other methods EQTransformer PhaseNet Yews STA/LTA method
- The F1 scores of LEQNet and EQTransformer are almost the same
- LEQNet is 0.02 points higher than PhaseNet when picking up the P phase, and 0.03 points higher than PhaseNet when picking up the S phase
discuss
- Compared with EQTransformer, the number of parameters in the CNN layer is reduced by 87.68%, and the optimization of the model is achieved by applying depthwise separable convolution and recursive CNN
- Reducing the number of output channels in ResNet also helps to reduce the number of parameters in LEQNet, but when some parameters in the encoder and decoder are reduced, the performance drops. To solve this problem, a deeper bottleneck architecture EQTransformer is used in the model , which increases the information density of LEQNet and the Netscore