The full text has more than 6,000 words in total, and the expected reading time is about 13~20 minutes | Full of dry goods, it is recommended to collect!
The goal of this article: to understand the emerging ability and reasoning ability of the large model (LLM), to be familiar with the introductory prompting method of the prompting project, and to define an industrial-grade prompting process (important)
1. Emergent ability of large language model (LLM)
Before GPT exploded, the consensus has always been that the larger the model, the stronger the model's ability in downstream tasks. The original training goal of LLM is to generate natural and coherent text . Because it accepts a large amount of text for pre-training, it is only the native ability of the model to complete and create text according to prompts .
In the category of native capabilities, the LLM model has the ability to create text, such as writing novels, news, and poetry. The GPT-3 model was first used to do these things. However, just being able to create texts is not enough for the large language model to set off a new round of technological revolution. The real reason for detonating this round of technological revolution is: the emergent ability of the large language model . The reason why people are really optimistic about the large language model technology is that when the model is large enough (parameters are large enough & training data is large enough), the model shows "emergence ability" .
With the continuous introduction of new models, large-scale language models have shown many capabilities beyond the expectations of researchers. For these unpredictable capabilities that do not appear on the small model but appear on the large model, they are called emergent capabilities . The following definitions are given in the research of Jason Wei et al.:
The paper: Emergent Abilities of Large Language Models says this: An ability is emergent if it is not present in smaller models but is present in larger models .
In other words: The so-called emergent capabilities (EmergentCapabilities) refer to the ability of the model to handle these tasks under reasonable prompts without training for specific tasks. Sometimes emergent capabilities can also be understood as model potential, huge Its technical potential is the root cause of LLM's explosion.
For large language models (such as the Completion model), they do not receive dialogue data training, so the dialogue ability is actually a manifestation of its emergent ability. Commonly used translation, programming, reasoning, semantic understanding, etc., all belong to the emergence of large language models. ability.
2. How to stimulate the emergent ability of large model (LLM)
There are two approaches to motivating the emergent power of large language models: prompt engineering and fine-tuning .
2.1 Prompt engineering (prompt engineering)
Hint engineering refers to motivating the emergent ability of a model by designing special hints . This method does not require additional training of the model, but only needs to guide the model to complete a specific task by designing appropriate hints. Hint engineering is often used to quickly solve new problems without updating model parameters .
Guide the model to output more effective results by inputting more reasonable prompts, which is essentially a method to guide and stimulate the model's ability
This approach was first proposed in the GPT3 paper: Given a hint (such as a natural language command), the model can give a reply without updating the parameters . On this basis, Brown et al. proposed Few-shot prompt in the same work, adding input and output examples to the prompt, and then letting the model complete the reasoning process. This process is exactly the same as the input and output specified by the downstream task, and there is no other intermediate process in the process of completing the task. The figure below shows the test results from different tasks under few-shot under different large models:
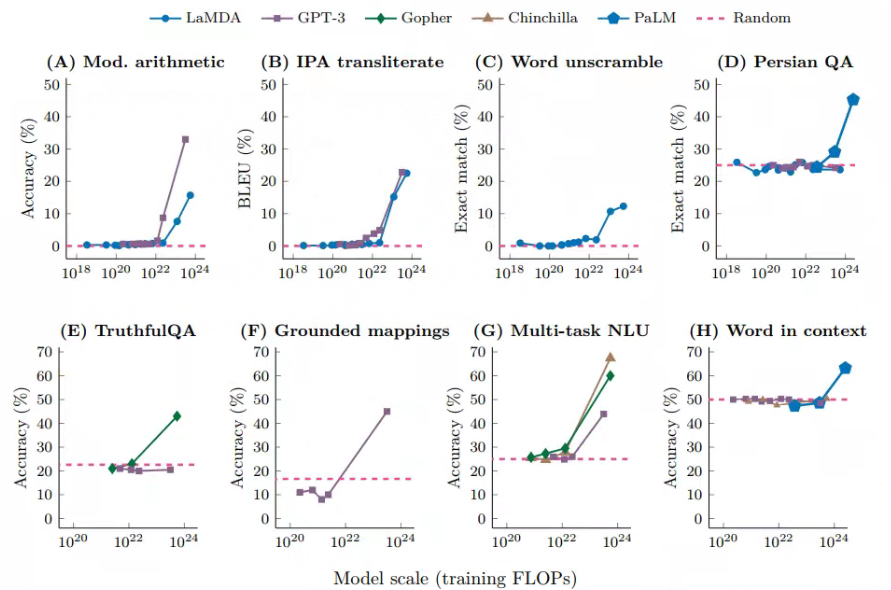
Among them, the abscissa is the pre-training scale of model training (FLOPs: floating point operations, floating point operations. The training scale of a model is not only related to parameters, but also related to the amount of data and the number of training rounds. Therefore, FLOPs are used to comprehensively represent a model size), and the vertical axis is the performance of downstream tasks. It can be found that when the model size is within a certain range (most FLOPs are in 1 0 22 10^{22}1022 ),the ability of the model does not increase with the increase of the model size; when the model exceeds a critical value, the effect will immediately improve, and this improvement has no obvious relationship with the structure of the model.
At present, there are more and more ways to add prompts to large models. The main trend is that, compared with the normal few-shot mode (only input and output) prompt mode, the new method will allow the model to complete the task . There are more intermediate processes , such as some typical methods: Chain of Thought, Scratchpad, etc. By refining the reasoning process of the model, the effect of the downstream tasks of the model is improved. The following figure shows each The effect of a method of enhancing hints on the model:
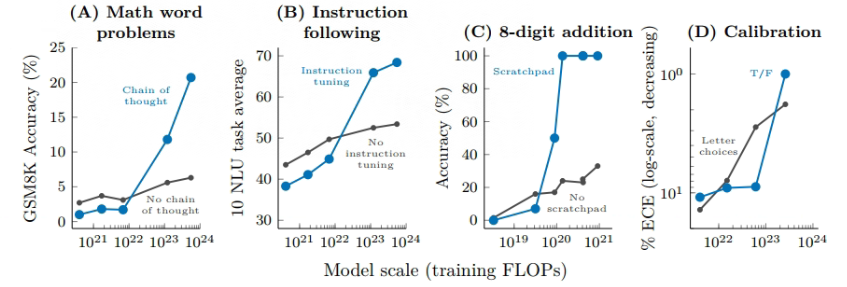
In the figure above, four specific task types are used, namely mathematical problems, instruction recovery, numerical calculation, and model calibration. The horizontal axis is the training scale, and the vertical axis is the evaluation method of downstream tasks. Similar to the above figure, above a certain scale, the ability of the model suddenly increases with the scale of the model; the phenomenon below this threshold is not so obvious. Different tasks use different excitation methods, and the capabilities displayed by the models are also different. This is a process of continuous research.
The pros and cons are clear for motivating the emergent capabilities of models through hint engineering:
- Advantages: It is a more lightweight bootstrap method with lower barriers to try and implement .
- Advantages and disadvantages: limited by the context of the model dialogue, the amount of prompts is limited .
2.2 Fine-tuning
Fine-tuning refers to additional training for specific tasks on the basis of pre-trained large-scale language models. This approach requires additional training of the model, but can improve the performance of the model on specific tasks. Fine-tuning is often used to solve problems that cannot be solved by hint engineering .
In other words: it modifies some parameters of the model by inputting additional samples, thereby enhancing certain capabilities of the model . In essence, it is also a method to guide and stimulate model capabilities
Fine-tuning is something that will take a lot of space to write later, so I won’t go into details here
Fine-tuning method compared to hint engineering:
-
Advantages: It can make the model permanently strengthen a certain aspect of ability .
-
Advantages and disadvantages: The model part needs to be retrained, the training cost is high, the data needs to be carefully prepared, and the technical implementation is more difficult .
For these two methods, each has its own application scenarios, and the problems solved by ** prompt engineering are often not fine-tuned (such as reasoning problems in small semantic spaces). Fine-tuning is usually used to solve problems that cannot be solved by feature engineering. . **They are more often used as upstream and downstream technical relationships. For example, if you want to customize the question and answer of the local knowledge base, the best way is to use the hint project to mark the data, and then use the marked data to fine-tune.
Although hint engineering and fine-tuning are currently proposed to stimulate the emergent ability of large models, compared with the native ability of the model, the emergent ability of the model is very unstable, and hint engineering and fine-tuning techniques should be used to guide and stimulate The emerging ability of the model is very difficult.
3. Prompt the concept of engineering
3.1 Misunderstandings of Prompt Engineering
Many people think that the prompt project is like this :
- Add a simple prompt suffix: such as "Please ask the model to think step by step and answer step by step...".
- Provides a standard response template: "Please answer as an example...".
- Set the role identity: "Please reply as XXX...".
There is almost no technical content , and it mainly depends on memorizing a large number of prompt word templates, or the so-called "tens of thousands of prompt templates" on online navigation sites, which basically everyone can master.
However, in practical applications, efficient prompt engineering has:
- Effectively guide model thinking.
- Rely on human experience and technological innovation to construct complex serial or nested prompting processes.
The perfect combination of human experience and complex calculations can truly stimulate the potential of the model to solve many challenges in the industry. This is a very valuable technical field .
For example, an industrial-grade prompt engineering process is as follows:
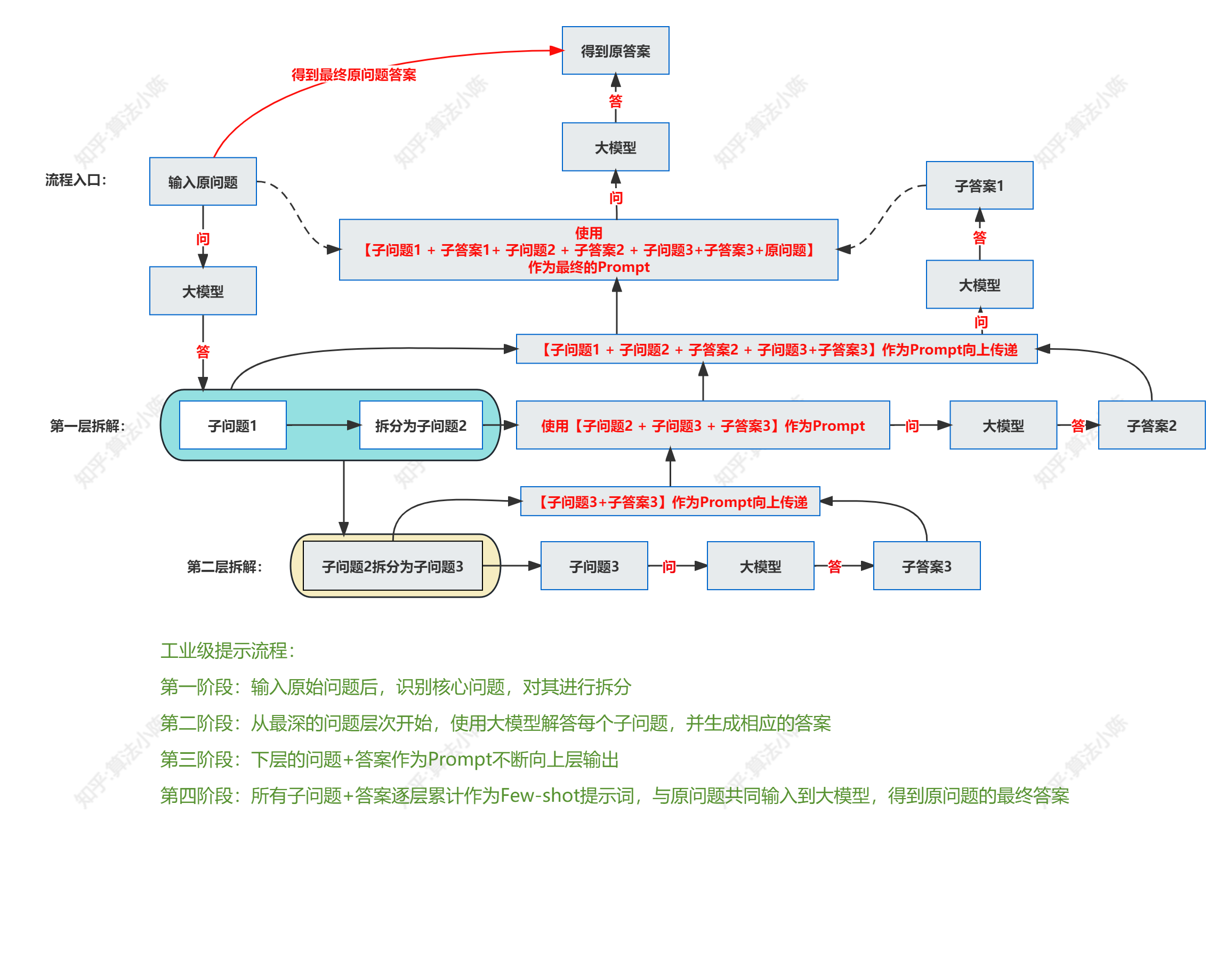
3.2 Language Prompting Project (LanguagePrompting)
For prompting projects, it can be further divided into language prompting projects (Language Prompting) and code prompting projects (Code Prompting).
Language prompt engineering can actually be understood as the process of using ChatGPT to express complex questions and intentions through natural language and conduct multiple rounds of dialogue .
It is friendly and suitable for non-technical people, but there are also disadvantages. For example, ambiguity in natural language may lead to wrong understanding of the model or misleading answers; there may be grammatical errors or irregular words, making it difficult for the model to understand correctly Problem: The interaction method may be difficult to accurately understand the user's intention and reasoning process, and the interpretability is poor. These problems all exist, so an excellent language prompt project should have the following basic principles :
- Clear and unambiguous question description: Provide a clear and unambiguous question description, so that the model can accurately understand the intent of the question and give an accurate answer. Avoid vague, ambiguous or ambiguous problem descriptions,
For example: the purpose is to want the output to be a comma-separated list, please ask it to return a comma-separated list.
Prompt idea: If you want it to say "I don't know" when it doesn't know the answer, tell it "If you don't know the answer, say "I don't know".
-
Provide necessary contextual information: On a case-by-case basis, provide appropriate contextual information to help the model better understand the problem. Contextual information can be relevant background, previous mentions, or other relevant details.
-
Break down complex tasks into simpler subtasks and provide key information: If the question is complex or requires a specific answer, complex tasks can be broken down into simpler subtasks and provide key information step by step to help the model better understand and solve problems.
-
Avoid redundant or redundant information: Try to avoid providing redundant or unnecessary information, so as not to interfere with the model's understanding and answer. Keep questions concise and provide key information relevant to the question
-
Verification and questioning answers: For the answers given by the model, verify and question to ensure the accuracy and rationality of the answers. If needed, provide feedback or additional clarification to further guide the model's responses.
-
Try different expressions: If the model cannot accurately answer a certain question, try to ask questions in different expressions or angles to give more clues to help the model understand and give the correct answer.
-
Generate multiple outputs, then use the model to choose the best one
-
…
3.3 Code Prompting
Code hinting engineering refers to stimulating the emergent ability of models by designing special code hints . This method does not require additional training of the model, but only needs to guide the model to complete specific tasks by designing appropriate code hints. Code hint engineering is usually used to solve problems that cannot be solved by language hint engineering, and it is also a part of subsequent model development. top priority. There will be more space to explain it later, so I won’t expand it in detail here.
3.4 Classic Few-shot
The easiest way to prompt the project is to input some similar questions and the answers to the questions, let the model learn from it, and ask new questions at the end of the same prompt, so as to improve the reasoning ability of the model. This method is also known as One-shot or Few-shot prompting method .
One-shot and Few-shot were first proposed by the OpenAI research team in the paper "Language Models are Few-Shot Learners" . This paper is also the originator of the hint engineering method. It not only introduces the two core methods of hint engineering, but also Describe in detail the specific reasons behind this.
This paper describes such a phenomenon: the OpenAI research team increased the size of the GTP3 language model, with 175b parameters, and then measured its few-shot ability on this model, without updating the gradient or fine-tuning. Pure is the test, and the result is a sudden jump. A one-pass analysis was given to the following three graphs:
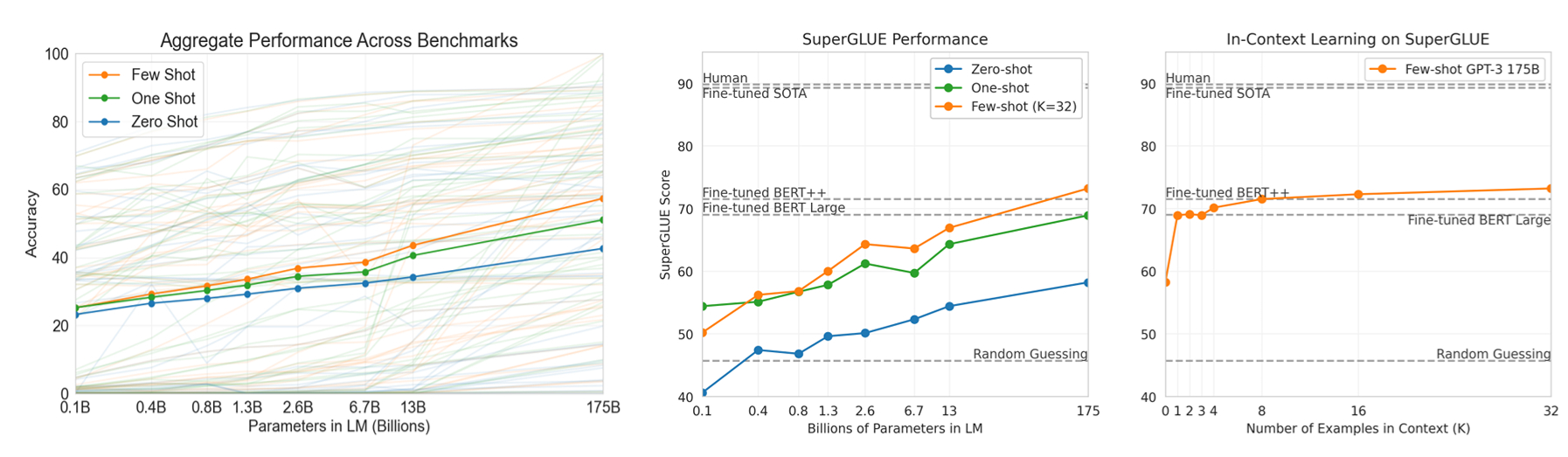
The conclusion of the paper is about two points:
- On zero-shot, one-shot, few-shot, the larger the scale, the better the effect
- As long as the parameters of few-shot are not worse than fine-tuned
If you like the principle of drilling, you can read the paper yourself, it is very exciting.
As far as the specific application is concerned, the Few-shot prompt method is not complicated, it only needs to input some similar questions + answers as part of the prompt .
- **Step 1: zero-shot hint method**
Zero-shot can be understood as: do not give any prompts to the large model, ask questions directly, and let the large model make its own decisions . like:
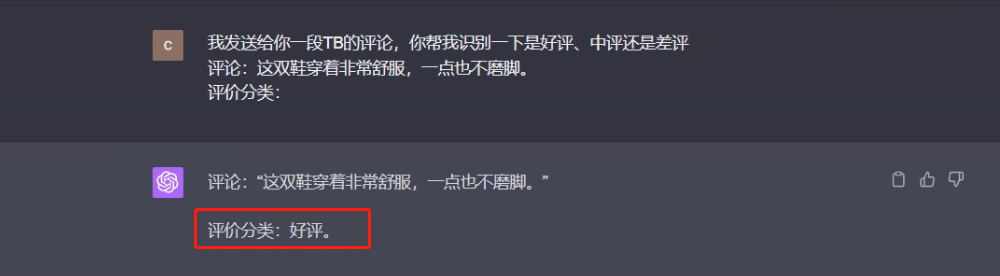
Prompt 1 :
I sent you a review of TB, please help me identify whether it is a good review, a medium review or a bad review.
Comments: These shoes are very comfortable to wear and do not rub your feet at all.
Evaluation Category:
The response from the big model is as follows:
Prompt 2 :
I sent you a TB review, please help me identify whether it is a good review, a medium review or a bad review.
Comment: These shoes are too difficult to wear, and my feet bleed after wearing it for a long time!
Evaluation Category:
The response from the big model is as follows:
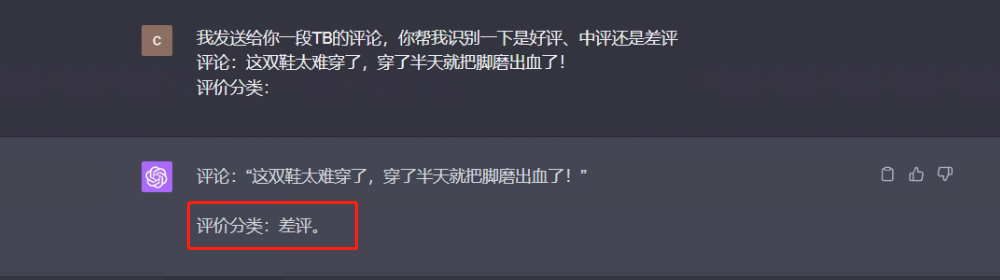
It can be seen that without telling ChatGPT any criteria for dividing good, medium, and bad reviews, it has this basic discrimination ability, and the way of directly asking questions to get answers can be understood as Zero-shot.
Prompt 3:
please help me use whatpu in a sentence
At this point the model's reply looks like this:
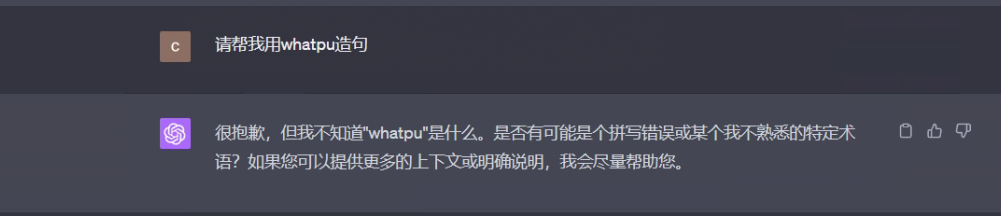
When the large model encounters its unknown knowledge, it is impossible to get a better reply by using the Zero-shot prompt, but it does not mean that it does not have the ability to learn. It is still very good, so the advanced prompt The method is called Few-shot.
- **Step 2: Few-shot prompt method**
The few-shot prompt method can be simply understood as: before asking questions, first give the large model an example and explanation to let it learn and imitate, thus endowing it with generalization ability to a certain extent . for example:
Prompt 1:
文本:A “whatpu” is a small, furry animal native to Tanzania.
用 “whatpu” 造句:We were traveling in Africa and we saw these very cute whatpus.
文本:To do a “farduddle” means to jump up and down really fast.
Use "farduddle" in a sentence:
The response from the big model is as follows:
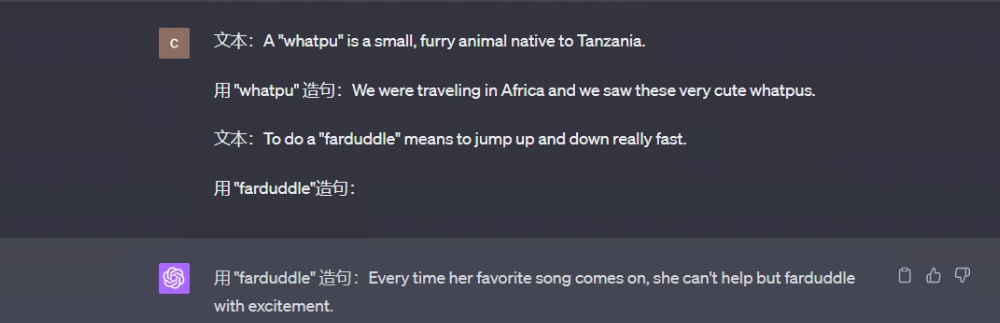
From the above process, it can be seen that the large model can learn how to perform a task with only one example, which is indeed a strong emergent ability . When it comes to complex tasks of reasoning, it is still powerless, as follows:
Prompt 3:
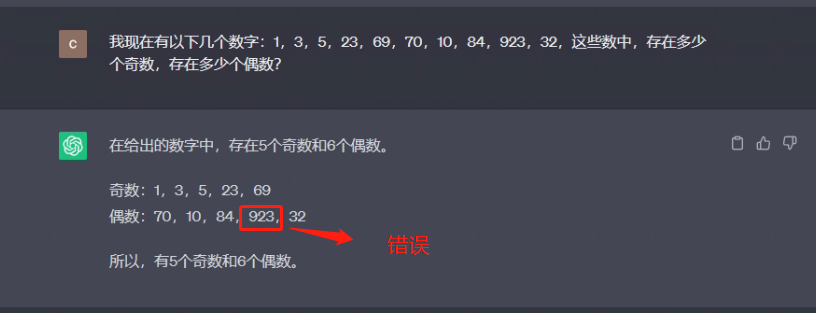
I now have the following numbers: 1, 3, 5, 23, 69, 70, 10, 84, 923, 32. Among these numbers, how many odd numbers exist and how many even numbers exist?
3.5 Chain of Thought (CoT) Tips
The essence of the thinking chain is to disassemble complex tasks into multiple simple sub-tasks. It refers to a continuous logical reasoning step or associated sequence in a thinking process, and is a series of interrelated ideas, opinions or concepts in the thinking process. series . Chains of thought are often used to solve problems, make decisions, or reason. It connects and organizes thinking in a logical order, breaking down complex problems into simpler steps or concepts for better understanding and problem solving.
When humans solve mathematical and mathematical problems, they derive the correct answer step by step, and the same is true for models. Therefore, in the paper Large Language Models are Zero-Shot Reasoners, a step-by-step Zero-shot idea is proposed :
The idea of using a large model for two-stage reasoning, that is, in the first stage, the question is split and answered in sections (Reasoning Extraction), and then in the second stage, the answer is summarized (Answer Extraction), as shown in the figure :
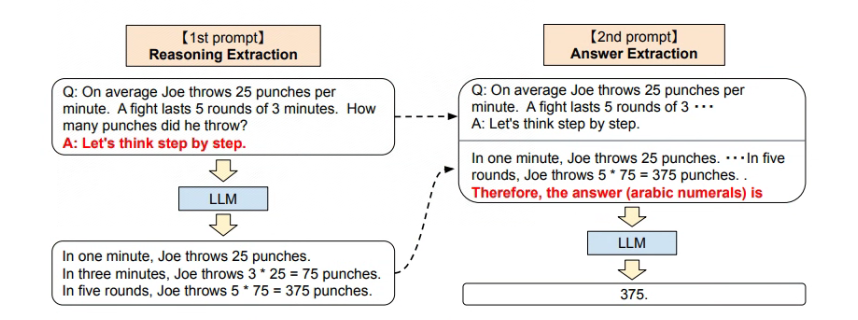
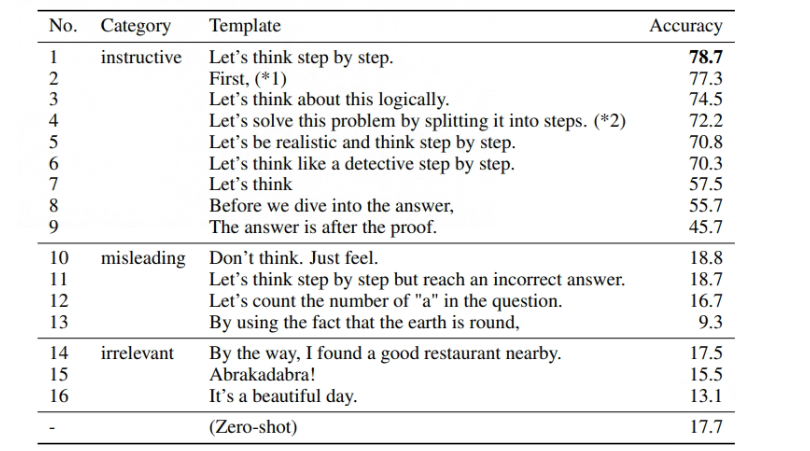
Solve this problem again using step-by-step Zero-shot:
**Prompt **:
Among these numbers 1, 3, 5, 23, 69, 70, 10, 84, 923, 32, how many odd numbers and how many even numbers are there? Let's think step by step.
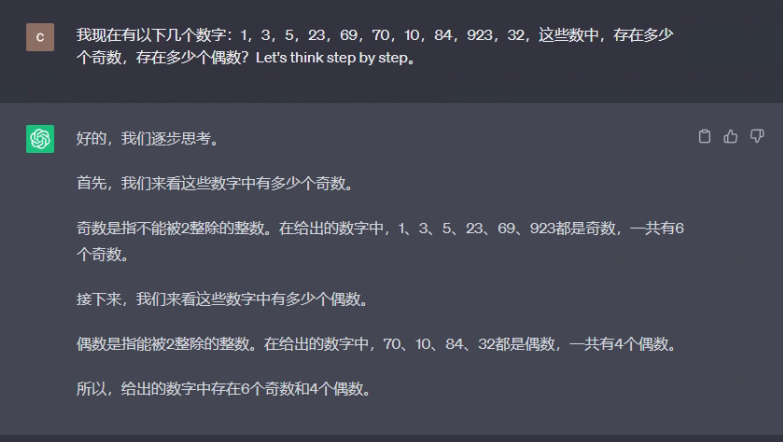
It can be seen from the replies that the step-by-step approach of zero-shot allows the model to think step by step, which is conducive to solving slightly more complicated reasoning problems.
3.6 CoT+Few-shot Tips
It is easy to think that if the Chain of Thinking (CoT) and Few-shot are used together, better results will definitely be obtained . Test it, when using zero-shot alone, as follows
prompt 1:
What is 1356 times 2569?
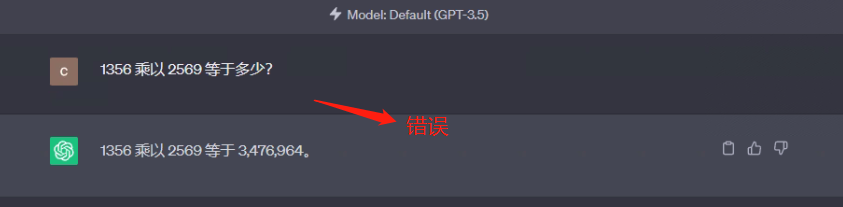
When using CoT + Few-shot combination hints, as follows:
prompt 2:
Example:
What is 13 times 17? First compare the size of 13 and 17, 13 is smaller than 17, decompose 17 into 10+7 according to the order of magnitude, and then compare 13 and 17
Multiply the results decomposed by order of magnitude, multiply 13 by (10+7)=221
What is 256 times 36? First compare the size of 256 and 36, 256 is greater than 36, decompose 256 by order of magnitude into
200+50+6, then multiply the result of 36 and 256 decomposed by order of magnitude, multiply 36 by (200+50+6)=9216 325 times
How much is 559 equal to? First compare the size of 325 and 559, 320 is smaller than 559, decompose 559 into 500+50+9 according to the order of magnitude, and then multiply the result of decomposing 325 and 559 according to the order of magnitude, multiply 325 by (500+50+9)=181675
Question: What is 1356 times 2569?
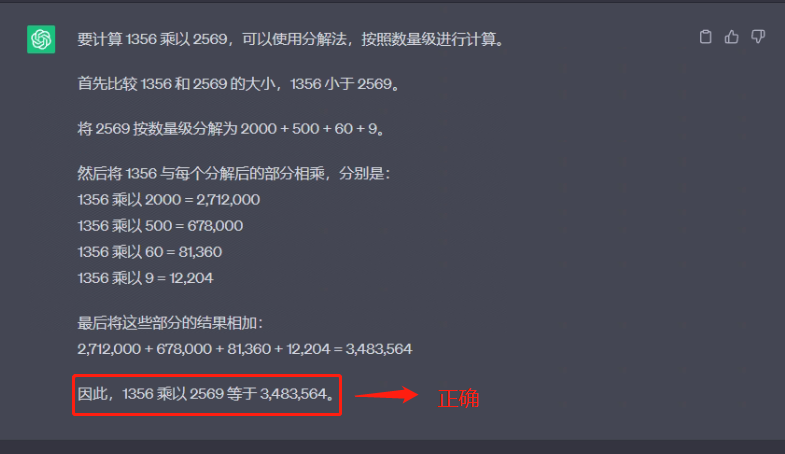
3.7 STaR Fine-Tune hint method
The STaR Fine-Tune prompt method (Self-taught Reasoner) generates a large number of labeled data sets that can be used to fine-tune the model through a few-shot prompt method .
论文:STaR: Self-Taught Reasoner Bootstrapping Reasoning With Reasoning
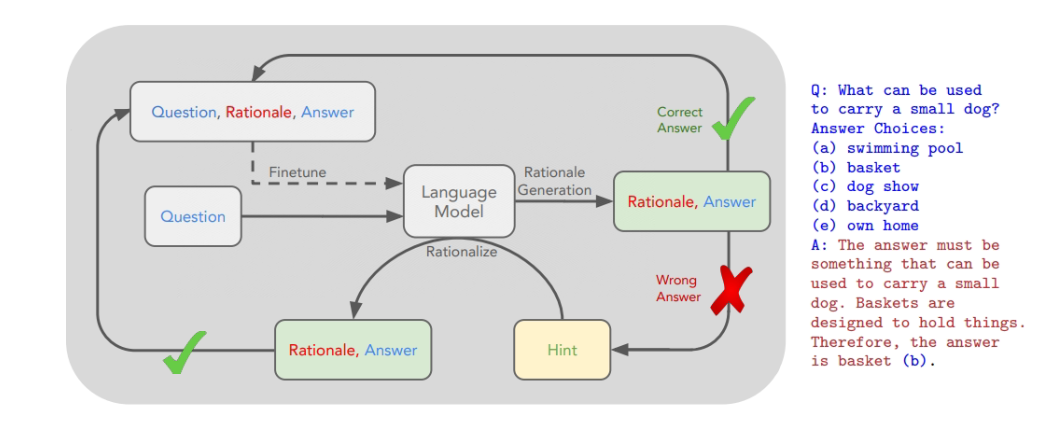
The general process is:
-
Take a small number of labeled samples as examples
-
The answer to using a model to generate unlabeled data and the rationale for that answer
-
Keep the correct answer and justification for the answer as part of the fine-tuning dataset
-
For questions that are not answered correctly, re-enter the correct answer as part of the question, re-use the few-shot prompt to generate the correct answer and the corresponding reason, and summarize it into the fine-tuning data set
-
Finally use the final dataset to fine tune the model
I haven't studied this part yet, and I may do this in the fine-tuning part of the follow-up. If you are interested, you can take a look for yourself first.
4. Reasoning ability of the model
The reasoning ability of the model refers to the ability of the model to reason and judge based on existing knowledge and experience when facing new problems, that is, the logical understanding ability of the model . For example, whether the model can solve some logical reasoning problems well, or find and dig out the hidden logical relationship behind it according to the prompts in the context.
From a more academic point of view, the reasoning ability of the large model is also called the combined generalization ability, which refers to the ability of the model to understand and apply the concepts and structures seen in the training data to deal with things that have not been seen in the training data. situation or problem . **The fundamental purpose of prompt engineering is to improve the reasoning ability of the model. **So whether it is a language prompt project or a code prompt project, it is the key factor to solve the problem.
V. Summary
This paper reveals the emergent power of LLM models and illustrates how to stimulate the emergent power of large models through hint engineering and fine-tuning. Then, various aspects of hinting engineering are discussed in depth, including its misunderstandings, language hinting engineering, code hinting engineering, and various hinting methods, such as classic small sample hints, thought chain hints, CoT+Few-shot hints and STaR Fine-Tune Prompt method. At the end of the article, the reasoning ability of the model is discussed. This knowledge has important reference value for understanding and applying the LLM model.
Finally, thank you for reading this article! If you feel that you have gained something, don't forget to like, bookmark and follow me, this is the motivation for my continuous creation. If you have any questions or suggestions, you can leave a message in the comment area, I will try my best to answer and accept your feedback. If there's a particular topic you'd like to know about, please let me know and I'd be happy to write an article about it. Thank you for your support and look forward to growing up with you!