Computing power conversion
Theoretical peak value = the number of GPU chips, the number of GPU Boost main frequency cores * the number of floating-point calculations that can be processed in a single clock cycle
It’s just that the single-precision and double-precision floating-point computing capabilities in the GPU need to be calculated separately. Take the latest Tesla P100 as an example:
Double-precision theoretical peak value = FP64 Cores * GPU Boost Clock * 2 = 1792 * 1.48GHz * 2 = 5.3 TFlops
Single-precision theoretical peak value = FP32 cores * GPU Boost Clock * 2 = 3584 * 1.58GHz * 2 = 10.6 TFlop
TFLOPS
FLOPS is the abbreviation of Floating-point Operations Per Second, which represents the number of floating-point operations performed per second. The current standard for measuring computing power is TFLOPS (trillion floating-point operations per second)
NVIDIA graphics card computing power table: https://developer.nvidia.com/cuda-gpus#compute
But now the standard for measuring computing speed is TFLOPS** (trillion floating-point operations per second), note that GPU is a floating-point operation.
The point is to pay attention to how its flops are calculated.
The theoretical peak calculation formula of the single-precision computing capability of GPU devices:
Peak value of single-precision computing capability = single-core single-cycle calculation times × number of processing cores × main frequency
For example: Take GTX680 as an example, the number of single-precision calculations per clock cycle of a single core is two times, the number of processing cores is 1536, and the main frequency is 1006MHZ, then the peak value P of its computing power is:
P = 2 × 1536 × 1006MHZ = 3.09TFLOPS
Here 1MHZ = 1000000HZ, 1T is 1 trillion, that is to say, GTX680 can perform more than 3 trillion single-precision operations per second.
The meaning of various FLOPS
MFLOPS (megaFLOPS): One million (=10^6) floating-point operations per second
GFLOPS (gigaFLOPS): One billion (=10^9) floating-point operations per second
TFLOPS (teraFLOPS): One trillion (=10^12) floating-point operations per second
PFLOPS (petaFLOPS): One quadrillion (=10^15) floating-point operations per second
Supplement:
computing power unit
TOPS (Tera Operations Per Second:) 1TOPS processor can perform one trillion (10^12) operations per second.
GOPS (Giga Operations Per Second): 1GOPS processor can perform 100 million (10^9) operations per second.
MOPS (Million Operation Per Second): 1MOPS processor can perform one million (10^6) operations per second.
In some cases, TOPS/W is also used as a performance index to evaluate the computing power of the processor. TOPS/W is used to measure how many trillion operations the processor can perform under the condition of 1W power consumption.
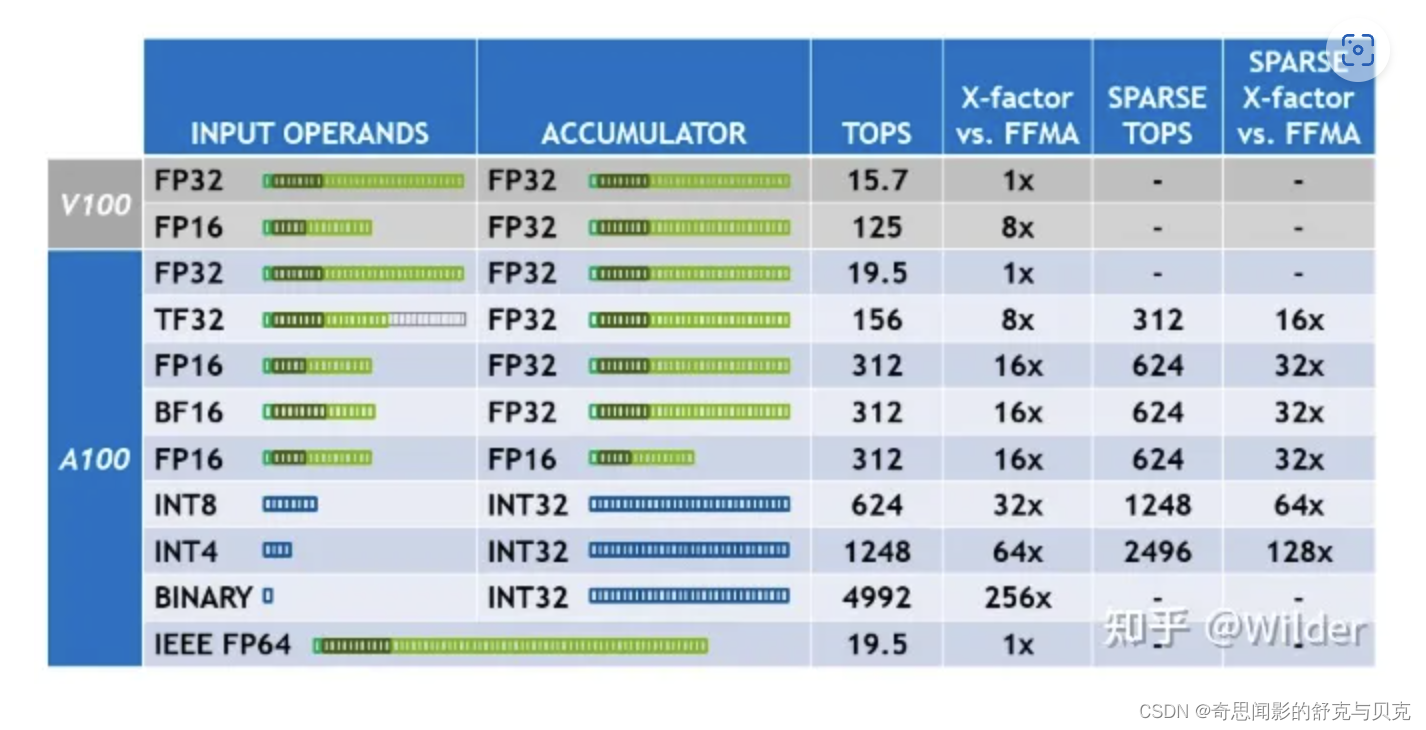
FP32 = float32 single precision floating point format
The IEEE 754-2008 standard specifies additional floating-point types, such as 64-bit base-2 double precision, and more recently base-10 representations.
TF32 = TensorFlow-32 NVIDIA's single-precision floating-point format instead of FP32
A new data type in NVIDIA A100/Ampere GPUs , TF32 uses the same 10-bit mantissa as half-precision (FP16) math, indicating sufficient margin for the precision requirements of AI workloads. And TF32 uses the same 8-bit exponent as FP32, so it can support the same range of values.
TF32 is a balance of performance, range and precision.
TF32 uses the same 10-bit mantissa precision as half-precision (FP16) mathematics, which is much higher than the precision requirements of AI workloads and has sufficient margin. At the same time, TF32 uses the same 8-bit exponent as FP32 and can support the same range of numbers.
This combination makes TF32 an excellent replacement for FP32 for single-precision math calculations , especially for the massive multiply-accumulate calculations that are at the heart of deep learning and many HPC applications.
With the help of NVIDIA's library, users can make full use of the advantages of TF32 in their applications without modifying the code. TF32 Tensor Core performs calculations based on FP32 input and generates results in FP32 format. Currently, other non-matrix calculations still use FP32.
For optimal performance, the A100 also features enhanced 16-bit math. It supports FP16 and Bfloat16 (BF16) at twice the speed of TF32. With automatic mixed precision, users can further increase performance by a factor of 2 with just a few lines of code.
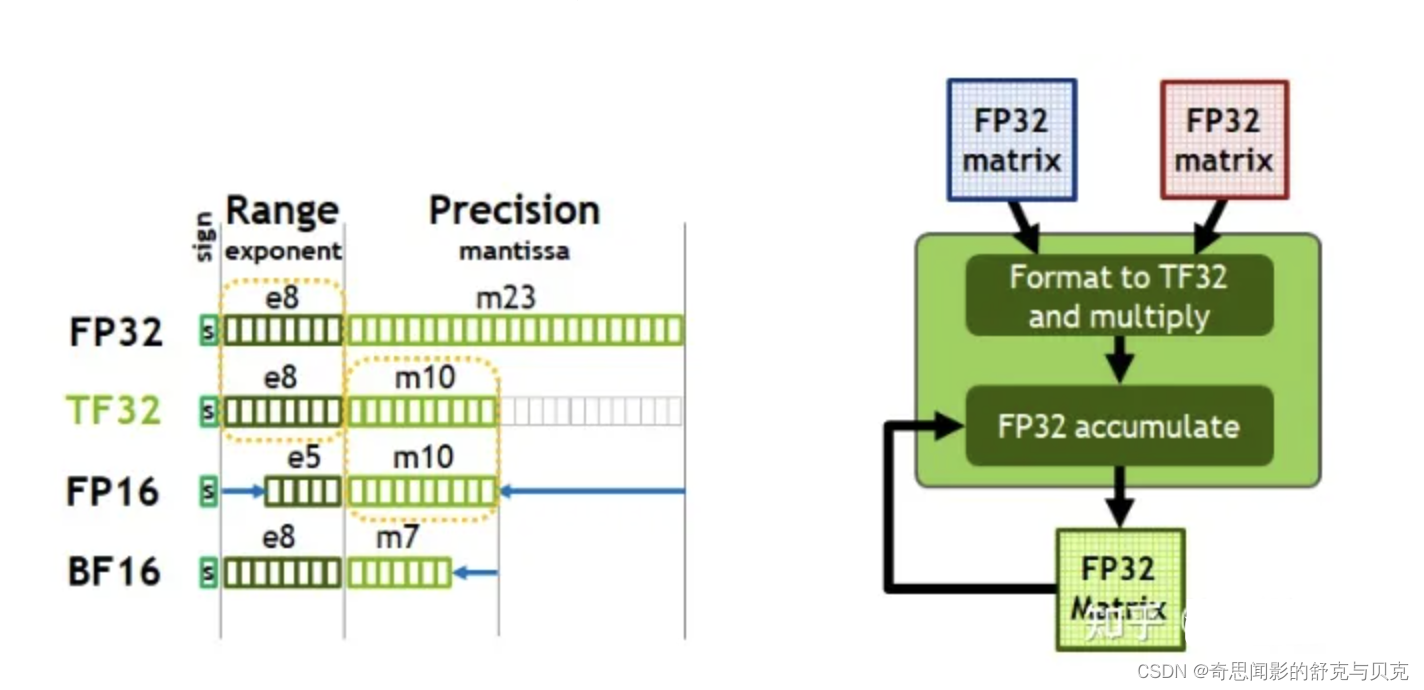
Therefore, by reducing the precision, the new single-precision data type of TF32 replaces the original single-precision data type of FP32, thereby reducing the space occupied by the data and allowing more and faster operation under the same hardware conditions.