Article directory

Relevant information on the implementation of the paper address
code
Abstract: This paper describes HayStack, an object storage system optimized for Facebook's Photos application. Facebook currently stores more than 260 billion images, which equates to more than 20 petabytes of data. Users upload 1 billion new images (∼60 TB) every week, and at peak times provide more than 1 million images per second.
Haystack provides a cheaper, more performant solution than our previous approach. Our main observation was that traditional designs would cause too many disk operations due to too many lookup metadata, so we reduced the metadata per image so that Haystack storage can perform all metadata lookups in main memory. This saves disk operations to read the actual data, increasing overall throughput.
1. Introduction
Sharing pictures is one of the most popular features of Facebook. To date, users have uploaded more than 65 billion pictures, making Facebook the largest photo-sharing site in the world. For every uploaded picture, Facebook will generate and store four pictures of different sizes, which translates into more than 260 billion images and more than 20 petabytes of data. Users upload 1 billion new images (∼60TB), and Facebook's weekly service peaks at more than 1 million images per second. As we can expect these numbers to increase in the future, this poses a significant challenge to Facebook's infrastructure.
This paper presents the design and implementation of HayStack, Facebook's image storage system, which has been in use for the past 24 months. Hystack is an object store we designed for sharing pictures on Facebook, where data is written once, read often, never modified, and rarely deleted. We designed our own storage system for images because traditional file systems performed poorly under our workload.
From our experience, we find that the traditional POSIX [21]-based file system has the disadvantage of directories and per-file metadata. For images, most metadata such as permissions are unused, thus wasting storage capacity.
However, the bigger cost is that in order to find the file itself, the file's metadata must be read from disk into memory. While insignificant on a small scale, multiplying billions of images and petabytes of data, accessing metadata is the throughput bottleneck. We found this to be a critical issue when using network attached storage (NAS) devices mounted on NFS. Reading an image requires several disk operations: one (or usually more) to convert the filename to an inode number, another to read the inode from disk, and a final time to read the file itself. In short, using disk IO for metadata is our limiting factor for read throughput. Note that in practice, this problem comes at an additional cost, as we have to rely on the CDN to serve most of the read traffic.
Considering the shortcomings of traditional methods, we designed HayStack to achieve four main goals:
- High throughput and low latency. Our image storage system must keep up with user requests. Requests that exceed our capacity to handle are either ignored, which is unacceptable for user experience, or handled by the CDN, which is expensive and reaches a point of diminishing returns. Also, images should be served quickly to facilitate a good user experience. Hystack achieves high throughput and low latency by requiring at most one disk operation per read. We do this by keeping all the metadata in main memory, and we do this by dramatically reducing the metadata for each image that is needed to find the image on disk.
- High availability. In large systems, failures occur every day. Our users rely on their images to be available and should not encounter errors despite the inevitable server crashes and hard drive failures. It could happen that an entire data center loses power or a cross-country link is severed. Hystack replicated each image in geographically different locations. If we lose a machine, we bring in another to take its place, replicating data where necessary for redundancy.
- High cost performance. Hystack provides better performance and lower cost than our previous NFS-based approach. We quantify cost savings in two dimensions: Hystack cost per TB of available storage and normalized HayStack read rate per TB of available storage. In HayStack, the cost per usable TB is 28% lower than the same TB on the appliance, and 4 times more reads are processed per second.
- very simple. In a production environment, we cannot overstate the power of a design that is easy to implement and maintain. Since Haystack is a new system, lacking years of production-grade testing, we took special care to keep it simple. This simplicity allows us to build and deploy a working system in months rather than years.
This work describes our experience from conception to implementation of a production-quality system serving billions of images per day. Our three main contributions are:
- HayStack, an object storage system optimized for efficient storage and retrieval of billions of images.
- Lessons learned in building and scaling cheap, reliable, and usable image storage systems.
- Describes a request to Facebook's photo sharing application.
We organize the remainder of this paper as follows. Section 2 provides background and highlights challenges in our previous architecture. We describe the design and implementation of HayStack in Section 3. Section 4 describes our image read and write workload and demonstrates that HayStack meets our design goals. We compare with related work in Section 5 and conclude the paper in Section 6.
2. Background and Design Concept
In this section, we describe the pre-existing architecture of HayStack and highlight the main lessons we learned. Due to space constraints, our discussion of this design omits several details of production-grade deployment.
2.1 Background
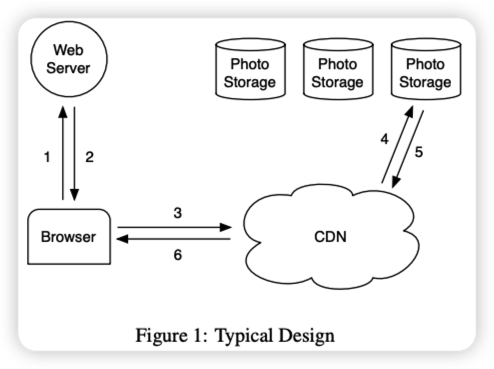
We begin with a brief overview of a typical design of how web servers, content delivery networks (CDNs), and storage systems interact to serve images on popular websites. Figure 1 depicts the steps from when a user visits a page containing an image to when that image is downloaded from its location on disk. When accessing a page, the user's browser first sends an HTTP request to the web server, which is responsible for generating the markup for the browser to render. For each image, the web server constructs a URL that points the browser to where to download the data. For popular sites, this URL usually points to a CDN. If the CDN has the image cached, the CDN immediately responds with the data. Otherwise, the CDN checks the URL, which embeds enough information to retrieve the image from the website's storage system. The CDN then updates its cached data and sends the image to the user's browser.
2.2 NFS-based Design
In our first design, we implemented an image storage system using an NFS-based approach. While the rest of this subsection provides more details about this design, the main lesson we learned is that CDNs by themselves do not provide a practical solution for serving images on social networking sites. CDNs do effectively serve the most popular images - avatars and recently uploaded images - but social networking sites like Facebook also generate a flood of requests for less popular (often older) content, which we call for the long tail. Requests from the long tail make up a large portion of our traffic, and nearly all of these requests go to hosts that support image storage, as these requests are often missing in CDNs. While it would be convenient to cache all the images for this long tail, it is not cost-effective as it would require a very large cache space.
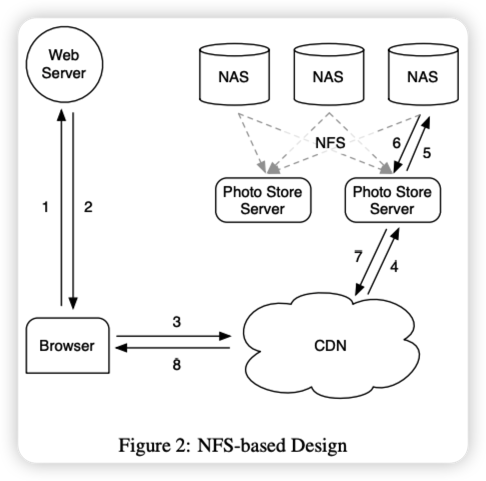
Our NFS-based design stores each image in its own file on a set of commercial NAS devices. A group of machines, image storage servers, and then mount all the volumes exported by these NAS devices through NFS. Figure 2 illustrates the architecture and shows the image storage server handling HTTP requests for images. The image storage server extracts the volume and full path of the file from the URL of the image, reads the data through NFS, and returns the result to the CDN.
Initially, we were storing thousands of files per directory on an NFS volume, which resulted in an excessive number of disk operations required to read a single image. Due to the way NAS devices manage directory metadata, it is extremely inefficient to have thousands of files in a directory whose block map is too large for the device to cache efficiently. Therefore, it is not uncommon to require more than 10 disk operations to retrieve a single image. After reducing directory sizes to hundreds of images per directory, the resulting system still typically requires 3 disk operations to fetch images: one to read the directory metadata from disk, a second to read the inode, and a third to Read the contents of the file.
To further reduce disk operations, we have the Photo Store server explicitly cache the file handles returned by the NAS device.
- When reading a file for the first time, the picture storage server usually opens the file, but also caches the mapping of the file name to the file handle in Memcache.
- When a file whose file handle is cached is requested, the image storage server directly opens the file using a custom open by file handle system call that we added to the kernel.
- Unfortunately, one could argue that storing all file handles in Memcache might be a viable solution. However, this only solves part of the problem, as it relies on the NAS device to keep all its inodes in main memory, an expensive requirement for traditional file systems. The main lesson we've learned from our NAS approach is that focusing only on caching—whether it's the NAS device's cache or an external cache like Memcache—has limited impact on reducing disk operations. The storage system ends up handling the long tail of requests for less popular images, which are not available in the CDN and thus likely to be missed in our cache. This kind of file handle caching provides only a small improvement because less popular pictures are less likely to be cached in the first place.
2.3 Discussion
It's difficult to provide precise guidelines for when or when not to build a custom storage system. However, we believe it still helps the community gain insight into why we decided to build HayStack.
Faced with a bottleneck in our NFS-based design, we explored the usefulness of building a GFS-like system. Since we store most of our user data in a MySQL database, the main use case for files in the system is a directory for engineers to use for development work, log data, and pictures. NAS devices offer very good price/performance for development work and log data. In addition, we use Hadoop to process extremely large log data. Processing image requests in the long tail is a problem that neither MySQL, NAS devices nor Hadoop can solve well.
One could describe the dilemma we face because existing storage systems lack the correct ratio of RAM to disk. However, there is no correct ratio. The system only needs enough main memory so that all file system metadata can be cached at once. In our NAS-based approach, one image corresponds to one file, and each file requires at least one inode, which is hundreds of bytes large. Having enough main memory in this approach is not cost-effective. In order to achieve better cost performance, we decided to build a custom storage system to reduce the amount of file system metadata per image, so that having enough main memory is more cost-effective than buying more NAS devices.
3. Design and implementation
Facebook uses a CDN to serve popular images and HayStack to efficiently respond to long-tail image requests. When a website encounters an I/O bottleneck serving static content, the traditional solution is to use a CDN. The CDN takes up enough of the load so that the storage system can handle the rest of the tail. At Facebook, the CDN had to cache an unreasonably large amount of static content to keep traditional (and cheap) storage methods from being I/O bound.
Recognizing that CDNs will not fully solve our problems in the near future, we designed HayStack to solve a critical bottleneck in our NFS-based approach: disk operations. We acknowledge that requests for less popular images may require disk operations, but our goal is to limit the number of such operations to only those required to read the actual image data. Hystack achieves this by significantly reducing the memory used for filesystem metadata, making it feasible to keep all of this metadata in main memory.
Recall that storing one image per file generates more filesystem metadata than can be reasonably cached. Hystack takes a simple approach: it stores multiple images in one file, thus maintaining very large files. We show that this straightforward approach works very well. Additionally, we believe its simplicity is its strength, allowing for quick implementation and deployment. We now discuss how this core technology and its surrounding architectural components provide a reliable and available storage system. In the description of HayStack below, we distinguish between two kinds of metadata. Application metadata describes the information needed to construct URLs that browsers can use to retrieve images. File system metadata identifies the data a host needs to retrieve an image residing on that host's disk
3.1 Overview
The Haystack structure consists of three core components: Store, Directory, and Cache.
- Store encapsulates the permanent storage system of images and is the only component that manages the metadata of the image file system.
- We organize storage capacity by physical volume. For example, we can organize the server's 10TB capacity into 100 physical volumes, and each physical volume provides 100 GB of storage. We further group physical volumes on different machines into logical volumes. When HayStack stores a picture on a logical volume, that picture is written to all corresponding physical volumes. This redundancy allows us to reduce data loss due to hard drive failures, disk controller errors, etc.
- Directory maintains logical-to-physical mappings and other application metadata such as which logical volume each image resides on and which logical volume has free space.
- The Cache acts as our internal CDN, which protects storage from requests for the most popular images and provides isolation in the event that an upstream CDN node fails and content needs to be re-fetched.
Figure 3 illustrates how the Store, Directory, and Cache components fit into the canonical interaction between the user's browser, web server, CDN, and storage system. In the Haystack architecture, browsers can be directed to a CDN or cache. Note that although a cache is essentially a CDN, to avoid confusion we use 'CDN' to refer to an external system and 'Cache' to refer to an internal system that caches images. Having an internal caching infrastructure allows us to reduce our reliance on external CDNs. When a user visits a page, the Web server uses the Directory to construct a URL for each picture. The URL contains multiple pieces of information, each corresponding to a series of steps from the user's browser contacting the CDN (or cache) to finally retrieving the image from the machine in the store. A typical URL to point your browser to the CDN ishttp://(CDN)/(Cache)/(Machine id)/(Logical volume, Photo)
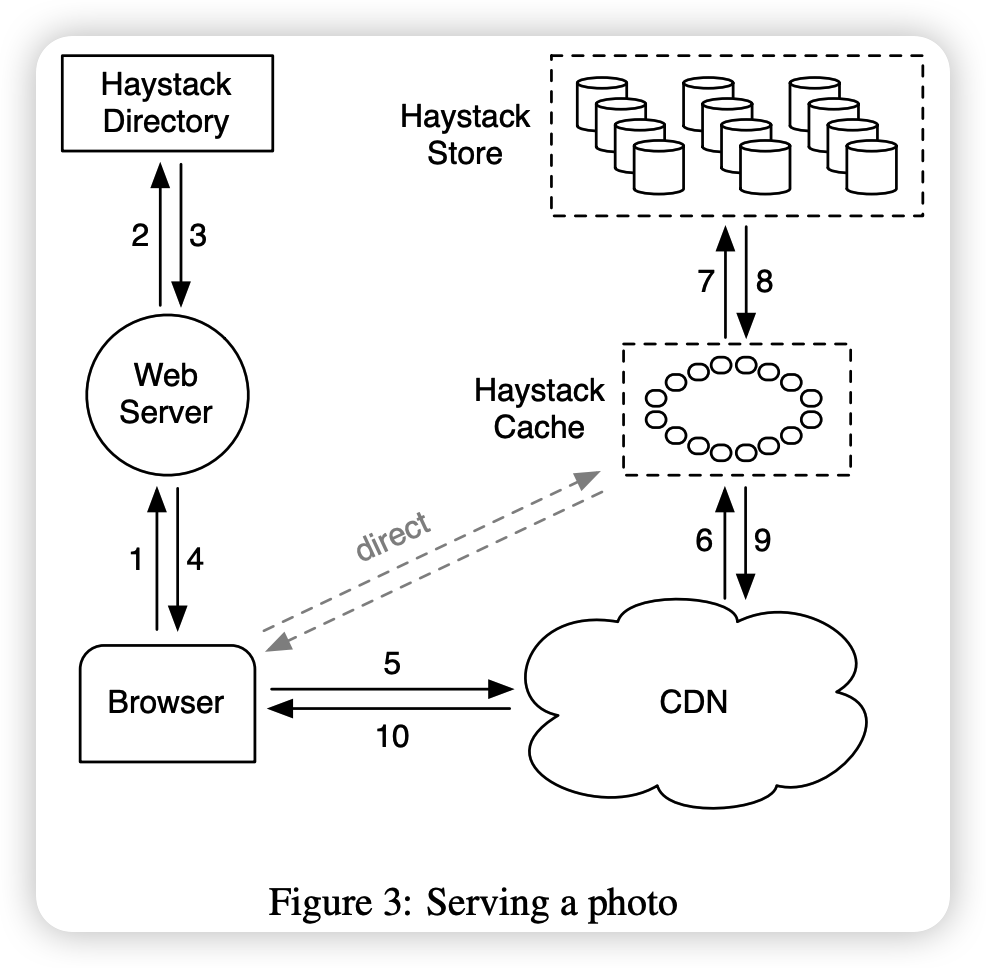
The first part of the URL specifies which CDN to request the image from. A CDN can look up images internally using only the last part of the URL: logical volume and image ID. If the CDN can't find the image, it strips the CDN address from the URL and contacts the cache. The cache performs a similar lookup to find the image, and if there is a miss, it strips the cache address from the URL and requests the image from the specified Store machine. Image requests that go directly to the cache have a similar workflow, except that the URL lacks CDN-specific information.
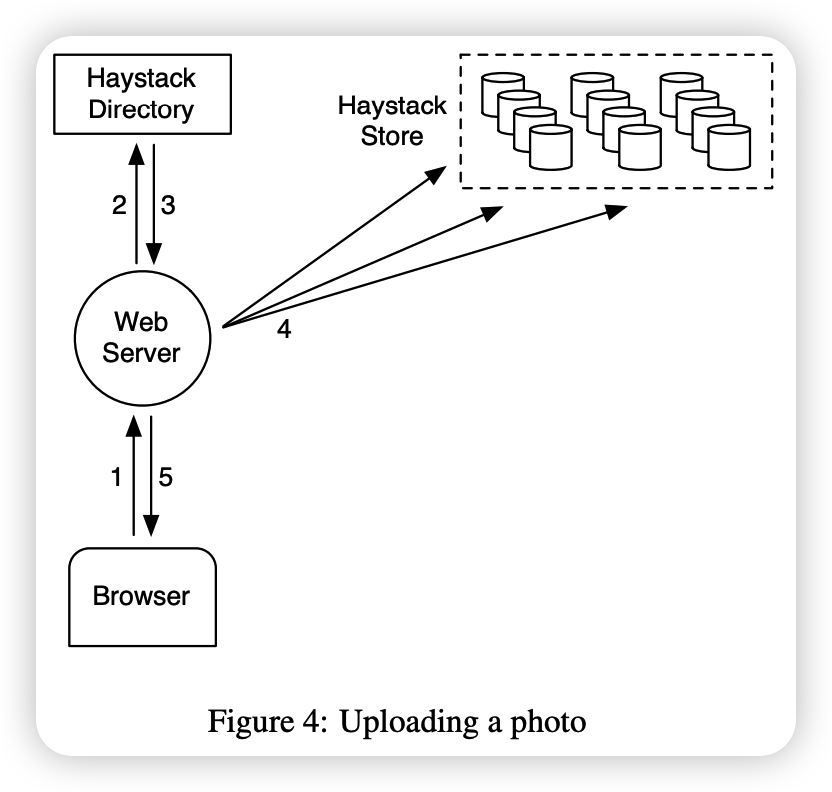
Figure 4 shows the upload path in HayStack. When a user uploads a photo, she first sends the data to a web server. Next, the server requests write-enabled logical volumes from Directory. Finally, the web server assigns a unique ID to the photo and uploads it to each physical volume mapped to the assigned logical volume
3.2 Haystack Directory
The Directory has four main functions.
- First, it provides a mapping from logical volumes to physical volumes. The web server uses this map when uploading photos and building image URLs for page requests.
- Second, the directory load balances write operations across logical volumes and read operations across physical volumes.
- Third, the directory determines whether photo requests should be handled by the CDN or by the cache. This feature allows us to adjust our reliance on CDN.
- Fourth, the catalog identifies those logical volumes that are read-only for operational reasons or because the volumes have reached their storage capacity. For operational convenience, we mark volumes as read-only at machine granularity.
When we increase the capacity of the store by adding new machines, those machines are write-enabled; only write-enabled machines will receive uploads. Over time, the available capacity on these machines decreases. When a machine exhausts its capacity, we mark it read-only. In the next subsection, we discuss how this distinction subtly affects caching and storage.
A directory is a relatively simple component that stores its information in a replicated database that leverages Memcache to reduce latency for PHP interface access. If data is lost on a storage machine, we delete the corresponding entry in the map and replace it with a new storage machine when it comes online.
3.3 Haystack Cache
Cache receives HTTP requests for photos from CDNs and directly from the user's browser. We organize the cache as a distributed hash table and use the ID of the photo as a key to locate the cached data. If the cache cannot respond to the request immediately, the cache fetches the image from the Store machine identified in the URL and replies to the CDN or the user's browser as needed.
We now focus on an important behavioral aspect of caching. It only caches photos when two conditions are met: (A) the request comes directly from the user, not a CDN; and (B) the photo is fetched from a writable storage machine.
- The rationale for the first case is that our experience with NFS-based designs has shown that post-CDN caching is ineffective because requests that miss in the CDN are less likely to hit our internal cache.
- The second reason is indirect. We use caching to protect write-capable storage machines from reads because of two interesting properties: photos are most frequently accessed shortly after upload, and our workload's filesystem is typically more performant when performing reads or writes Good, but not both at the same time (Section 4.1). Therefore, without caching, write-enabled storage machines will see the most reads. Given this nature, one optimization we plan to implement is to proactively push recently uploaded photos into the cache, as we expect these photos to be frequently read soon.
3.4 Haystack Store
The storage machine's interface is intentionally basic. A read makes a very specific and well-contained request for a photo with a given ID, a specific logical volume, and a photo from a specific physical storage machine. If a photo is found, the machine returns it. Otherwise, the machine will return an error.
Each storage machine manages multiple physical volumes. Each volume contains millions of photographs. Specifically, readers can think of the physical volume as a very large file (100 GB), saved as /hay/haystack<逻辑卷id>. Using only the ID of the corresponding logical volume and the file offset where the photo resides, the storage machine can quickly access the photo. This knowledge is the basis of HayStack's design: to retrieve the filename, offset, and size of a particular photo without requiring disk operations. The storage machine keeps open file descriptors for each physical volume it manages and maps photo IDs to file system metadata (i.e., file, offset, and size in bytes) in memory, which Data is critical to retrieving photos.
We now describe the layout of each physical volume and how the memory map is derived from that volume. The storage machine represents the physical volume as a large file consisting of a superblock and a series of needles. Each pin represents a photo stored in Haystack. Figure 5 illustrates the volume file and format for each needle. Table 1 describes the fields in each needle
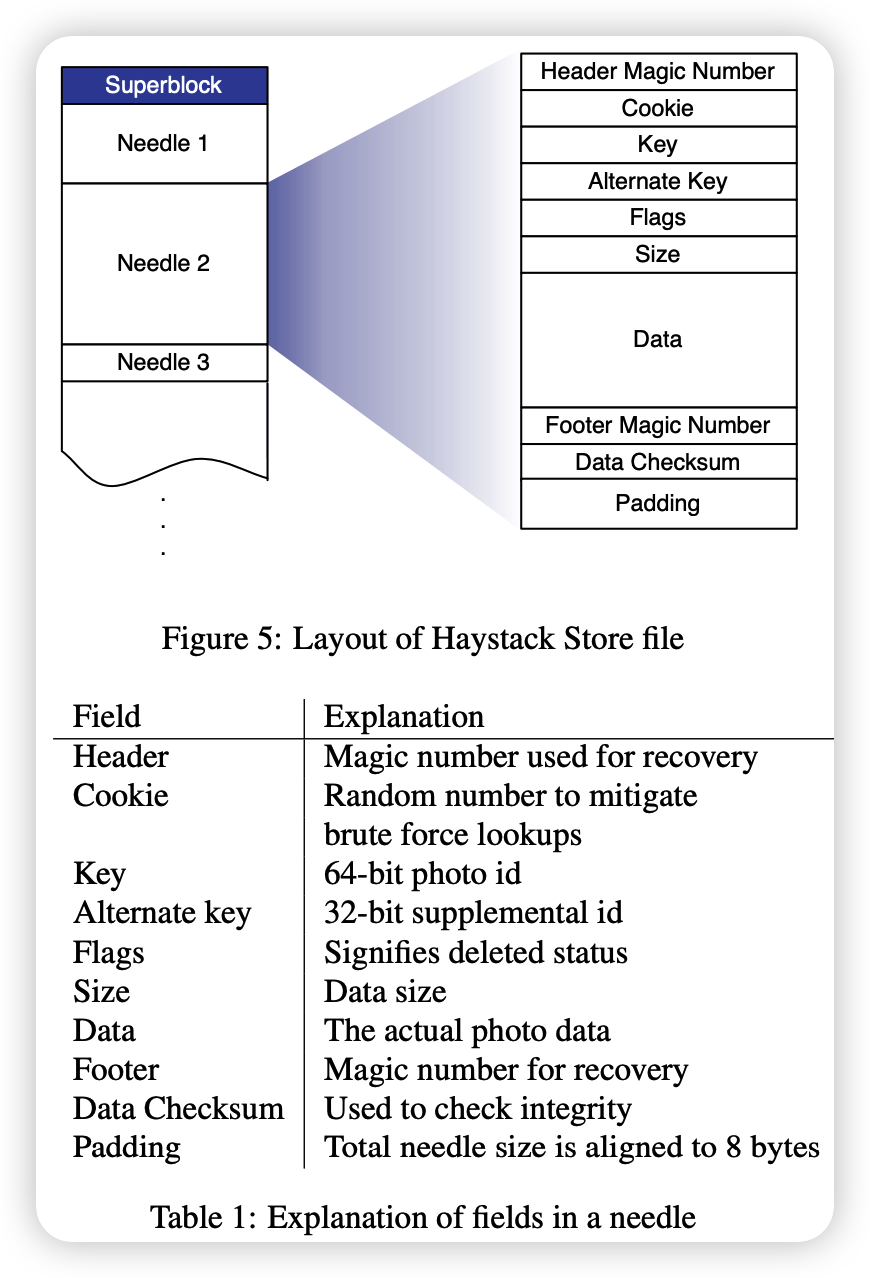
For fast needle retrieval, each storage machine maintains an in-memory data structure for each of its volumes. The data structure maps (key, Alternate Key) 2 pairs to the corresponding pin flags, and the size is 2. For historical reasons, the photo's id corresponds to the Key, while its type is used for the Alternate Key. During upload, the web server scales each photo to four different sizes (or types) and stores them as different pins, but with the same key. The important difference between these bytes and the volume offset. After a crash, the storage machine can rebuild this mapping directly from the volume file before processing the request. We will now describe how the Store machine maintains its volume and memory map while responding to read, write, and delete requests (the only operations supported by the Store).
3.4.1 Photo Read
When the caching machine requests a photo, it provides the storage machine with a logical volume ID, key, backup key, and cookie. A cookie is a number embedded in the URL of a photo. When uploading a photo, the value of the cookie is randomly assigned by the directory and stored in the directory. This cookie effectively eliminates attacks aimed at guessing valid URLs for photos.
When a store machine receives a request for a photo from a cache machine, the store machine looks up the relevant metadata in its memory map. If the photo has not been deleted, the storage machine will look up the appropriate offset in the volume file, read the entire pointer from disk (whose size can be calculated ahead of time), and verify cookie and data integrity. If these checks pass, the storage machine returns the photo to the cache machine
3.4.2 Photo Write
When uploading photos to HayStack, the web server provides logical volume ID, key, backup key, cookie and data to the storage machine. Each machine synchronously appends the needle image to its physical volume file, updating the in-memory mapping as needed.
While simple, this append-only limitation can complicate some photo editing operations, such as rotation. Since HayStack does not allow overriding pins, photos can only be modified by adding an updated pin with the same key and an alternate key. If the new pointer is written to a different logical volume than the original pointer, the directory will have its application metadata updated and future requests will never fetch the older version. If a new pointer is written to the same logical volume, the storage machine will attach the new pointer to the same corresponding physical volume. Haystack distinguishes such repeated needles based on their offset. That is, the latest version of the needle within the physical volume is the one with the highest offset.
3.4.3 Photo Delete
Deleting photos is easy. The storage machine sets the delete flag synchronously in the memory map and in the volume file. A request to get a deleted photo first checks for a flag in memory, and returns an error if the flag is enabled. Note that the space occupied by deleted needles is temporarily lost. We then discussed how to reclaim deleted needle space by shrinking volume files.
3.4.4 The Index File
Storage machines use an important optimization on restart - index files. While it is theoretically possible for a machine to rebuild its in-memory mapping by reading all of its physical volumes, doing so is time-consuming because all data volumes (TB) must be read from disk. Index files allow storage machines to build their memory maps quickly, reducing restart times.
Storage machines maintain an index file for each of their volumes. An index file is a checkpoint of an in-memory data structure used to efficiently locate needles on disk. The layout of an index file is similar to that of a volume file, consisting of a superblock followed by a series of index records corresponding to each pointer in the superblock. These records must appear in the same order as the corresponding needles appear in the volume file. Figure 6 illustrates the layout of the index file, and Table 2 illustrates the different fields in each record.

Starting over with an index is a little more complicated than just reading the index and initializing the in-memory mapping. This complication arises because index files are updated asynchronously, which means that index files may represent stale checkpoints. When we write a new photo, the store machine "synchronously" appends a pointer to the end of the volume file and "asynchronously" appends a record to the index file. When we delete a photo, the Store machine will set the flag in the photo's pointer synchronously without updating the index file. These design decisions enable write and delete operations to return faster because they avoid additional synchronous disk writes. They also created two side effects that we had to address: needles could exist without corresponding index records, and index records would not reflect deleted photos.
We refer to needles that do not have corresponding index records as orphans. During a restart, the storage machine checks each orphan in order, creates a matching index record, and appends the record to the index file. Note that we can "quickly identify" orphans because the last record in the index file corresponds to the last non-orphan pointer in the volume file. To complete the restart, the store machine now only uses the index file to initialize its memory map.
Since index records do not reflect deleted photos, storage machines can retrieve photos that have actually been deleted. To get around this, after the Store machine has read the entire stitch of a photo, the machine can check for a flag of deletion. If the pointer is marked as deleted, the storage machine updates its in-memory map accordingly and notifies the cache that the object was not found.
3.4.5 Filesystem
We describe HayStack as object storage using a common Unix-like filesystem, but some filesystems are better suited for HayStack than others. In particular, the storage machine should use a file system that does not require much memory to be able to quickly perform random seeks in large files. Currently, every storage machine uses XFS, which is a zone-based file system. For HayStack, XFS has two main advantages.
- First, the blockmaps of several contiguous large files can be small enough to be stored in main memory.
- Second, XFS provides efficient file preallocation, reducing fragmentation and controlling the size of block maps.
Using XFS, HayStack can eliminate disk operations to retrieve file system metadata when reading photos. However, this benefit does not mean that HayStack can guarantee that every read of a photo will result in a disk operation. There are special cases where the file system requires multiple disk operations when photo data spans extents or RAID boundaries. Haystack pre-allocates 1 GB extents and uses a RAID stripe size of 256 KB, so in practice we rarely encounter this.
3.5 Recovery from failures
Like many other large systems running on commodity hardware, HayStack needs to tolerate failures of all kinds: faulty hard drives, misbehaving RAID controllers, damaged motherboards, etc. We use two simple techniques to tolerate faults - one for detection and one for repair.
To proactively discover problematic shop machines, we maintain a background task called Pitchfork that periodically checks the health of each shop machine. Pitchfork remotely tests the connection to each storage computer, checks the availability of each volume file, and attempts to read data from the storage computer. If Shochfork determines that a storage machine consistently fails these health checks, it automatically marks all logical volumes residing on that storage machine as read-only. We manually resolve the root cause of the check failure offline.
Once diagnosed, we may be able to fix the problem very quickly. Sometimes this situation requires a more onerous bulk sync operation, where we reset the storage computer's data with the volume files provided by the replica. Bulk syncs happen infrequently (only a few times per month) and are simple, albeit slow to perform. The main bottleneck is that the amount of data to be batch synced is typically orders of magnitude higher than the speed of the NICs on each Store computer, resulting in average restore times of many hours. We are actively exploring techniques to address this limitation.
3.6 Optimizations
We now discuss several optimizations that are important to the success of HayStack.
3.6.1 Compaction
Compaction is an online operation that reclaims the space used by deleted and duplicated needles (those with the same key and alternate keys). The storage machine does this by copying the needles into a new file while skipping any duplicated or deleted entries to compress the volume file. During the compaction process, the delete operation deletes both files. Once this process reaches the end of the file, it prevents any further modification of the volume and automatically swaps the file and the in-memory structure
We use compression to free up space from deleted photos. The pattern of deletion was similar to photo viewing: younger photos were more likely to be deleted. Over the course of a year, about 25 percent of photos were deleted.
3.6.2 Saving more memory
As mentioned above, the storage machine maintains an in-memory data structure that includes flags, but our current system only uses the flags field to mark a needle as deleted. We remove the need for the in-memory representation of the flag by setting the deleted photo's offset to 0. Also, the storage machine does not keep track of the cookie value in main memory, but instead checks the provided cookie after reading the pointer from disk. With these two technologies, the storage machine's main memory footprint has been reduced by 20%.
Currently, HayStack uses an average of 10 bytes of memory per photo. Recall that we scaled each uploaded image to four photos, all with the same key (64 bits), different alternate keys (32 bits), and thus different data sizes (16 bits). In addition to these 32 bytes, HayStack consumes about 2 bytes of overhead on each image due to the hash table, bringing the total overhead of four scaled photos of the same image to 40 bytes. For comparison, assume that the XFS inode t structure in Linux is 536 bytes.
3.6.3 Batch upload
Since disks are generally better at doing large sequential writes than small random writes, we batch uploads together whenever possible. Fortunately, many users upload entire albums to Facebook, rather than individual photos, which obviously presents an opportunity to batch together photos in an album. We quantify the improvement of aggregating writes together in Section 4.
4. Evaluation
We divide our evaluation into four parts. First, we describe the photo requests seen by Facebook. In the second and third parts, we show the effectiveness of catalog and cache respectively. Finally, we analyze How the store behaves with synthetic and production workloads.
4.1 Characterizing photo requests
Photos are one of the main things users share on Facebook. Users upload millions of photos every day, and more recent uploads tend to be more popular than older ones. Figure 7 illustrates the popularity of each photo as a function of photo age. To understand the shape of the graph, it's useful to discuss what drives Facebook's photo requests
4.1.1 Features that drive photo requests
98% of photo requests on Facebook come from two features: newsfeed and photo gallery. The News Feed feature shows users the latest content shared by their friends. The photo album feature allows the user to browse photos of her friends. She can view recently uploaded photos and browse all personal albums. 98% of Facebook's photo requests come from two features: the news feed and the photo gallery. The newsfeed feature shows users the latest content shared by their friends. The photo album feature allows the user to browse photos of her friends. She can view recently uploaded photos and also browse all personal photo albums.
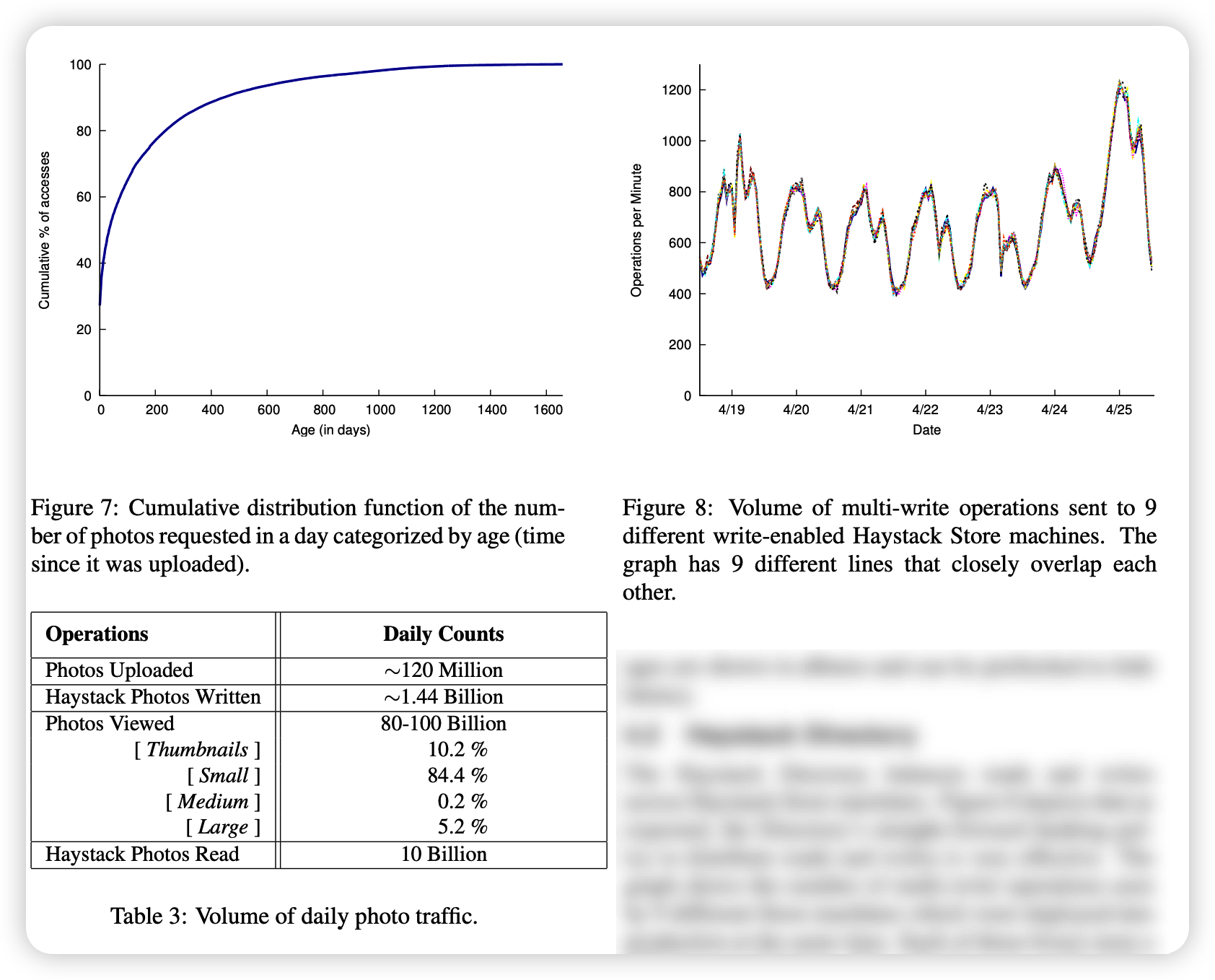
Figure 7 shows a sharp rise in requests for photos from a few days ago. The news feed drives most of the traffic to recent photos, and around two days or so, when many stories no longer show up in the default feed view, traffic drops off sharply. From this figure, two key points are worth noting. First, the rapid decline in popularity shows that CDNs and caching in caches are very effective for hosting popular content. Second, the graph has a long tail, which means that a large number of requests cannot be handled using cached data.
4.1.2 Traffic Volume
Table 3 shows image traffic on Facebook. Since our application scales each image to 4 sizes and saves each size in 3 different locations, 12 times as many HayStack photos are written than uploaded. The table shows that about 10% of all photo requests made by the CDN get a response from HayStack. Observe that most of the photos viewed are smaller images. This feature underscores our desire to minimize metadata overhead, as inefficiencies can quickly add up. Additionally, reading smaller images is generally a more latency-sensitive operation for Facebook, since they appear in the News Feed, while larger images appear in the photo album, which can be prefetched to hide latency.
4.2 Haystack Directory
The haystack directory balances read and write operations across all haystack storage machines. As shown in Figure 8, the straightforward hashing strategy for distributing reads and writes to directories works very well. The graph shows the number of multi-write operations seen by 9 different storage machines that were simultaneously deployed to production. Each of these boxes stores a different set of photos. Since the lines are almost indistinguishable, we conclude that the writing of the Catalog is well balanced. Comparing read traffic between storage machines shows similarly well-balanced behavior.
4.3 Haystack Cache
Figure 9 shows the hit ratio of the HayStack cache. Recall that the cache only stores photos if they are saved on a Store computer that supports write. These photos are relatively new, which explains about 80% of the high hit rate. Since write-enabled storage machines also see the most reads, caching can effectively significantly reduce the rate of read requests for the most affected machines.
4.4 Haystack Store
Recall that HayStack targets the long tail of photo requests and aims to maintain high throughput and low latency despite seemingly random reads. We show performance results for storage machines under synthetic and production workloads.

4.4.1 Experimental setup
We deploy storage machines on commodity storage blades. A typical hardware configuration for a 2U storage blade has 2x hyperthreaded quad-core Intel Xeon CPUs, 48 GB of memory, a hardware RAID controller with 256-512MB of NVRAM, and 12 x 1TB SATA drives.
Each storage blade provides approximately 9TB of capacity configured as RAID-6 partitions managed by a hardware RAID controller. RAID-6 can provide sufficient redundancy and excellent read performance while reducing storage costs. The controller's NVRAM write-back cache mitigates the reduced write performance of RAID-6. Since our experience has shown that caching photos on the storage computer is ineffective, we reserve NVRAM entirely for writing. We also disable disk cache to ensure data consistency in case of crashes or power outages.
4.4.2 Benchmark performance
We evaluate the performance of Store machines using two benchmarks: Randomio and HayStress. Randomio is an open source multithreaded disk I/O program that we use to measure the raw capacity of storage devices. It issues random 64KB reads, uses direct I/O to issue sector-coherent requests, and reports maximum sustainable throughput. We use Randomio to establish a benchmark of read throughput that we can compare with results from other benchmarks.
HayStress is a custom multithreaded program that we use to evaluate the Store machine against various synthetic workloads. It communicates with the storage machine via HTTP (just like a cache) and evaluates the maximum read and write throughput that the storage machine can sustain. HayStress performs random reads on a large set of virtual images to reduce the impact of the machine's buffer cache; that is, nearly all reads require disk operations. In this paper, we evaluate storage machines using seven different HayStress workloads.
Table 4 describes the read and write throughput and associated latencies that the storage machines can sustain under our benchmarks. Workload A performs random reads on a 64KB image on a storage machine with 201 volumes. The results showed that HayStack delivered 85% of the device's raw throughput with only 17% higher latency.
We attribute the overhead of the storage machine to four factors:
- It operates on top of the file system instead of directly accessing the disk;
- The disk read is larger than 64KB, because the entire magnetic needle needs to be read;
- The stored image may not be aligned to the underlying RAID-6 device stripe size, so a small portion of the image is read from multiple disks;
- CPU overhead of the HayStack server (index access, checksum calculation, etc.).
In workload B, we checked the read-only workload again, but changed 70% of the reads so that they request smaller images (8KB instead of 64KB). In practice, we found that most requests were not for the largest size images (as seen in the photo album), but for thumbnails and profile photos.
Workloads C, D, and E show the write throughput of the storage machine. Recall that HayStack can write in batches together. Workloads C, D, and E groups 1, 4, and 16 write a single write many times, respectively. The table shows that amortizing the fixed cost of writes over 4 and 16 images increases throughput by 30% and 78%, respectively. As expected, this also reduces per-image latency.
Finally, let's look at performance when there are both reads and writes. Workload F uses a mix of 98% reads and 2% write-many, while G uses a mix of 96% read and 4% write-many with 16 writes per write-many image. These ratios reflect what is often observed in production. The table shows that the bucket provides high read throughput even in the presence of writes.
4.4.3 Production workload
This section examines the performance of the Store on production machines. As mentioned in Section 3, there are two types of buckets – write-enabled and read-only. Write-enabled hosts serve read and write requests, and read-only hosts serve read requests. Since the two classes have rather different traffic characteristics, we analyze a set of machines in each class. All machines have the same hardware configuration.
On a per-second granularity, there can be large spikes in the amount of photo read and write operations that the Store Box sees. To ensure reasonable latency even with these spikes, we conservatively allocate a large number of write-capable machines so that their average utilization is low.
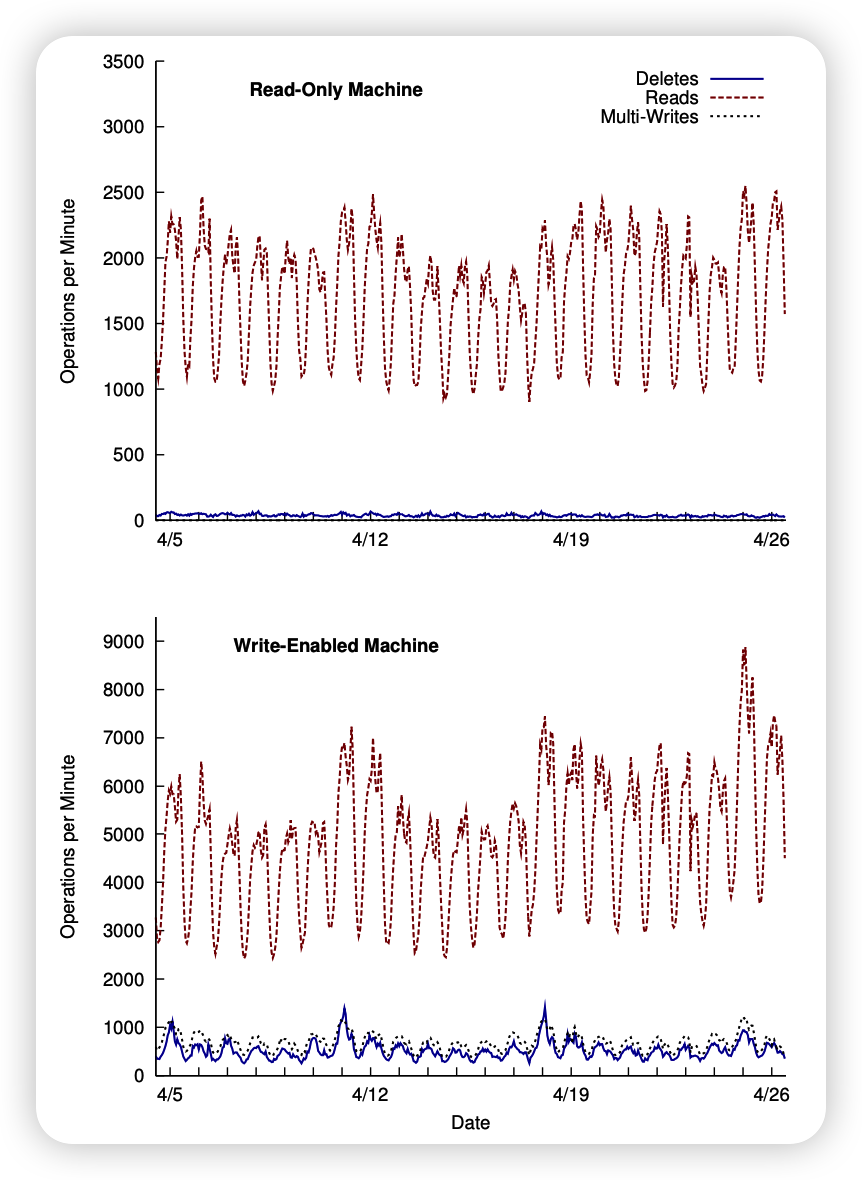
Figure 10 shows the frequency of different types of operations on read-only and write-enabled Store machines. Note that we saw a spike in photo uploads on Sunday and Monday, with a steady decline for the rest of the week before leveling off Thursday through Saturday. Then, a new Sunday came and we hit a new weekly peak. Generally, our footprint grows by 0.2% to 0.5% per day.
As mentioned in Section 3, on production machines, write operations to the store are always multiple writes to amortize the fixed cost of the write operation. Finding groups of images is fairly simple, as 4 different sizes of each photo are stored in HayStack. It's also common for users to upload batches of photos into photo albums. As a combination of these two factors, the average number of images per multiple write is 9.27 for this write-capable machine.
Section 4.1.2 explains that recently uploaded photos have high read and delete rates and will decrease over time. This behavior can also be observed in Figure 10; write-enabled machines see more requests (even though some read traffic is served by the cache).
Another trend worth noting: As more data is written to a box that supports writes, the number of photos also increases, resulting in an increased rate of read requests. Figure 11 shows the latencies of read operations and multiple writes performed on the same two machines as in Figure 10 over the same time period.
The latency of multi-write operations is quite low (between 1 and 2 milliseconds) and stable even if the traffic volume varies greatly. The haystack machine has an NVRAM-backed RAID controller that buffers writes for us. As mentioned in Section 3, NVRAM allows us to write pointers asynchronously, and then issue a single fsync to flush the volume file after the multi-write operation is complete. Multiple write latencies are very smooth and stable.
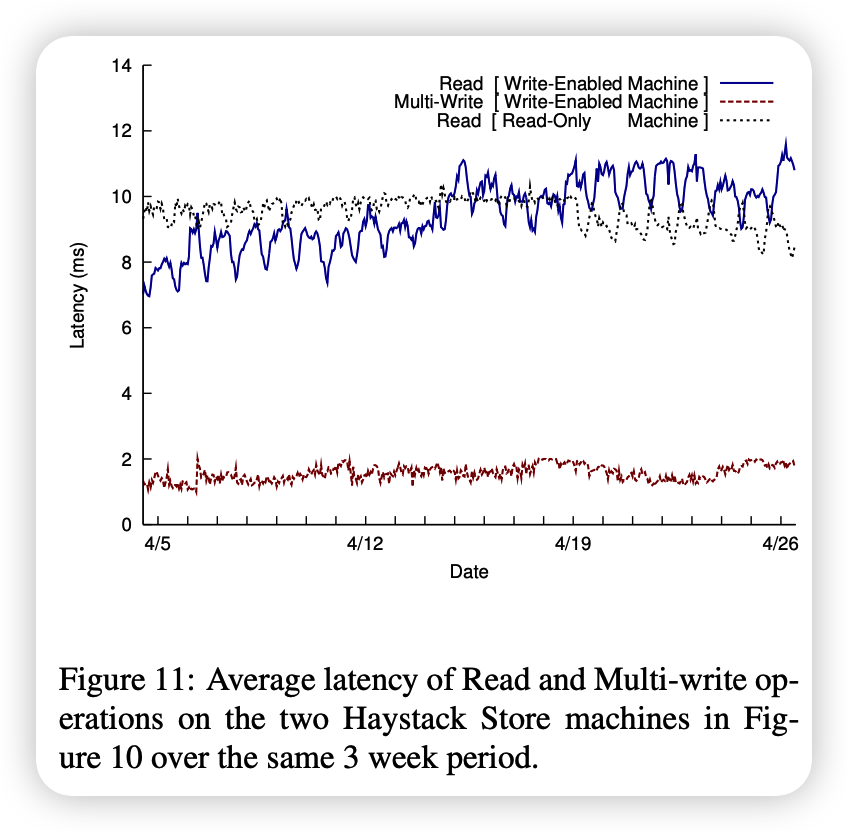
Read latencies on the read-only chassis are also fairly stable, even with highly variable traffic (up to 3x over 3 weeks). For write-enabled computers, read performance is affected by three main factors.
- First, as the number of photos stored on a machine increases, so does the machine's read traffic (compare weekly traffic in Figure 10).
- Second, photos on write-enabled machines are cached in cache, whereas for read-only machines3 they are not cached. This suggests that the buffer cache is more efficient for read-only machines.
- Third, recently written photos are often instantly reread because Facebook highlights recent content. Such reads on a write-enabled box will always hit the buffer cache and improve the buffer cache hit ratio. The shape of the lines in the graph is the result of the combination of these three factors.
Low CPU utilization on storage machines. CPU idle time varies between 92-96%.
五、Related Work
As far as we can tell, HayStack is targeting a new design point focused on the long tail of photo requests seen by a large social networking site.
- File system: HayStack adopts a log-structured file system [23], Rosenblum and Ousterhout designed this file system to optimize write throughput, because most read operations can be obtained from the cache. Although measurement results [3] and simulation results [6] show that log-structured file systems have not yet reached their full potential in local file systems, the core idea is very relevant to HayStack. Photos are attached to physical volume files in the HayStack Store, and the HayStack cache protects write-enabled computers from being overwhelmed by the rate of requests for recently uploaded data. The main differences are: (A) HayStack storage machines write data in such a way that they can efficiently service reads once the data becomes read-only; (B) the rate of read requests for older data increases over time. decrease with the passage of time.
Several works [8, 19, 28] propose how to manage small files and metadata more efficiently. A common thread across these contributions is how to intelligently group related files and metadata together. Hystack avoids these problems because it maintains metadata in main memory, and users frequently upload related photos in bulk.
-
Object-based storage: HayStack's architecture has many similarities to the object storage system proposed by Gibson et al. [10] In Network Attached Secure Disk (NASD). In NASD, which separates logical storage units from physical storage units, HayStack directories and storage are probably most analogous to the concepts of file and storage managers, respectively. In OBFS [25], Wang et al. construct a user-level object-based file system whose size is 1/25 of that of XFS. Although OBFS achieves greater write throughput than XFS, its read throughput (HayStack's main focus) is slightly worse.
-
Managing Metadata: Weil et al. [26, 27] address scaling metadata management in Ceph1 petabyte-scale object storage. Cave further decouples the mapping from logical units to physical units by introducing generating functions instead of explicit mappings. Clients can compute the appropriate metadata instead of looking it up. Implementing this technology in haystacks is still future work. Hendricks et. Al [13] note that traditional metadata prefetching algorithms are inefficient for object storage because related objects identified by unique numbers lack the semantic grouping implicitly imposed by directories. Their solution is to embed inter-object relationships into object IDs. This idea is orthogonal to HayStack because Facebook explicitly stores these semantic relationships as part of the social graph. In SpyGlass [15], Leung et al. proposed a design scheme for fast and scalable search of metadata in large-scale storage systems. Manber and Wu also proposed a method to quickly search the entire file system [17]. Patil et al. [20] use sophisticated algorithms in GIGA+ to manage metadata associated with billions of files per directory. We design a solution that is simpler than many existing works because HayStack need neither provide search functionality nor traditional UNIX file system semantics.
-
Distributed File System: HayStack's logical volume concept is similar to Lee and Thekkath's [14] virtual disk in Petal. The Boxwood project [16] explores the use of advanced data structures as the basis for storage. While attractive for more complex algorithms, abstractions like B-trees may not have much impact on HayStack's deliberately lean interface and semantics. Likewise, Sinfonia's [1] small transaction and PNUTS' [5] database functions provide more functionality and stronger guarantees than HayStack requires. Ghemawat et al. [9] designed the Google File System for workloads consisting mainly of append operations and large sequential reads. BigTable [4] provides a storage system for structured data and provides database-like functionality for many projects at Google. It's unclear whether many of these features make sense in a system optimized for photo storage.
6. Conclusion
This paper describes HayStack, an object storage system designed for Facebook's Photos application. We designed HayStack to serve the long tail requests seen in sharing photos across large social networks. The key insight was to avoid disk operations when accessing metadata. Hystack provides a fault-tolerant and simple solution for photo storage at significantly lower cost and higher throughput than traditional methods using NAS devices. Additionally, HayStack is incrementally scalable, a quality necessary for our users to upload hundreds of millions of photos every week.