Introduction: Alibaba Cloud's full-link data lake development and governance solution capabilities continue to be upgraded, and version 2.0 is released. The solution includes open source big data platform E-MapReduce (EMR), one-stop big data data development and management platform DataWorks, data lake construction DLF, object storage OSS and other core products. Supports three forms of EMR new data lake DataLake cluster (on ECS), custom cluster (on ECS), and Spark cluster (on ACK), and connects with Alibaba Cloud's one-stop big data development and management platform DataWorks, which has accumulated more than ten years of Alibaba. Data construction methodology, completes the full-link data lake development and governance capabilities for customers from lake entry, modeling, development, scheduling, governance, security, etc., to help customers improve data application efficiency.
Alibaba Cloud's full-link data lake development and governance solution capability has been continuously upgraded, and version 2.0 has been released. The solution includes open source big data platform E-MapReduce (EMR), one-stop big data data development and management platform DataWorks, data lake construction DLF, object storage OSS and other core products.
The solution supports three forms of EMR's new data lake DataLake cluster (on ECS), custom cluster (on ECS), and Spark cluster (on ACK). With many years of big data construction methodology, it has completed the full-link data lake development and governance capabilities for customers from lake entry, modeling, development, scheduling, governance, and security, helping customers improve data application efficiency.
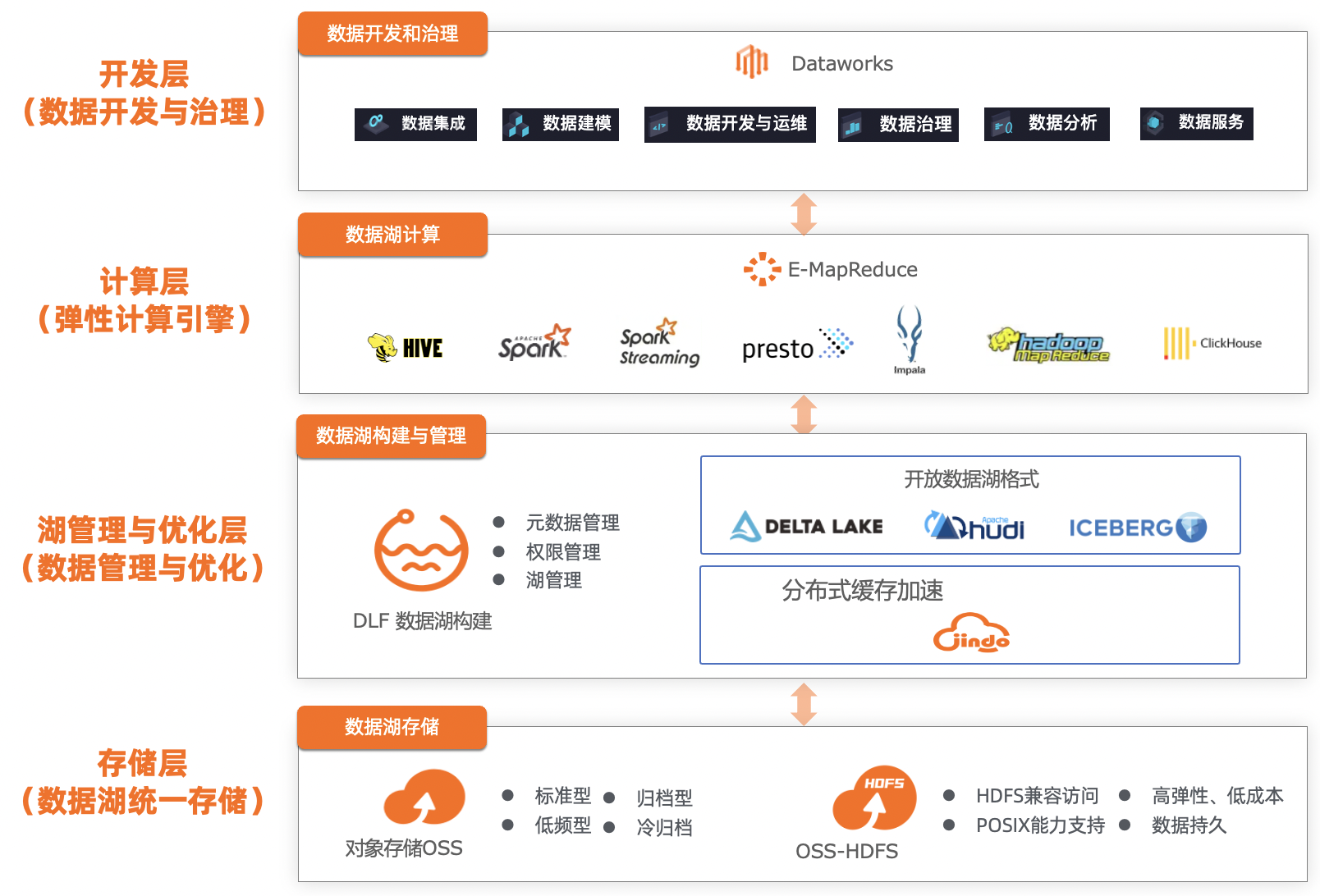
Key capability upgrades
Enhancing Data Lake Capabilities
DataWorks data integration supports real-time data transfer from MySQL to the lake OSS (HUDI), Kafka real-time data transfer to the lake OSS (HUDI), and cycle synchronization capabilities from MySQL to Hive.
Choose to enter data integration in the DataWorks console
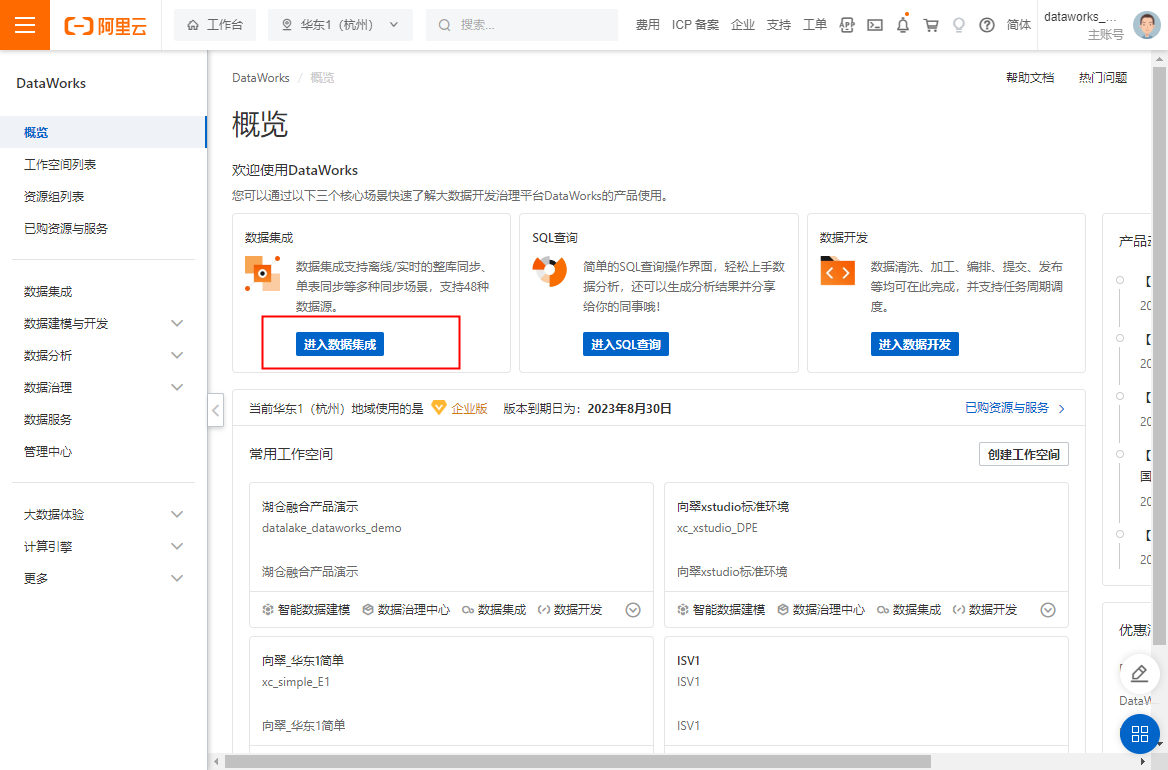
Click "Create My Data Synchronization" directly on the page

Select the type of source and destination to see the corresponding ability to enter the lake
MySQL entire database real-time into the lake OSS (Hudi)
Support automatic registration of metadata to Alibaba Cloud DLF, which is convenient for users to manage lakes;
Supports synchronization at the MySQL instance level, that is, the source MySQL can select multiple libraries at the same time;
Supports selecting source MySQL libraries and tables according to regular expressions;
Supports automatic database and table addition, that is, after adding a database or table on the MySQL side, it can be automatically synchronized to OSS without manual intervention and operation.
Kafka into the lake OSS (Hudi) in real time
Support Kafka json data increments to enter the lake in real time, with second-level delay
Supports data processing in synchronous links, including data filtering, desensitization, string replacement, field-level assignment, etc.
Support dynamically adding fields according to kafka json data schema changes
Support docking with Alibaba Cloud DLF, automatic registration of metadata entering the lake, real-time query and management
Support custom OSS lake storage path
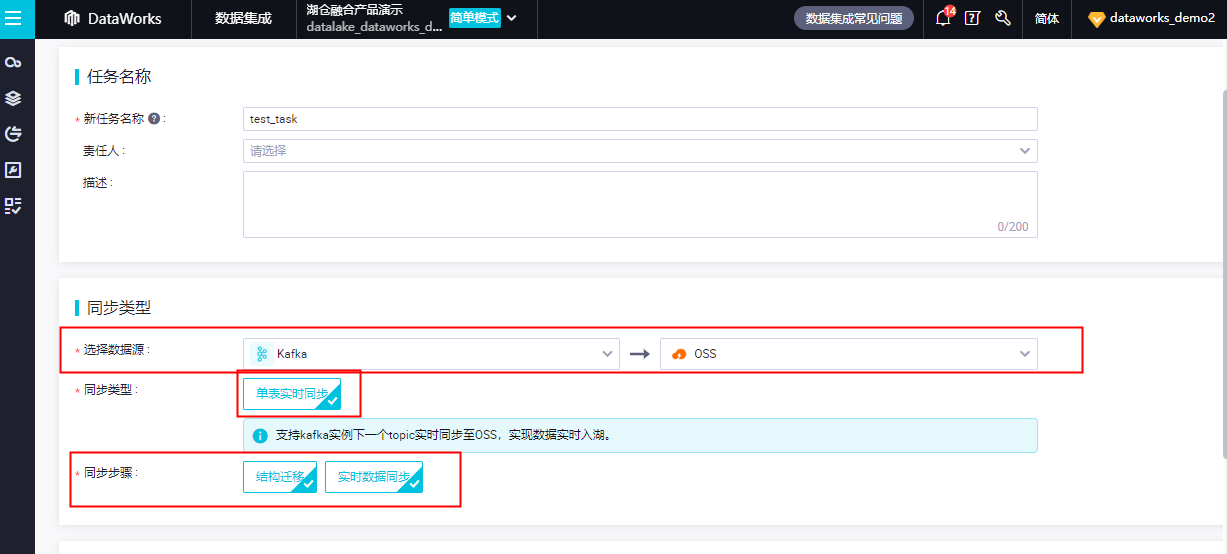
Synchronize the entire MySQL database offline to Hive
The entire instance level of MySQL is synchronized offline to Hive, which supports the configuration of periodic scheduling. You can also rely on this synchronization scheduling node as the upstream in DataStudio, and supports historical full synchronization and offline incremental synchronization.

Enhance job development and scheduling capabilities
Support spark on ACK cluster scheduling
DataWorks supports scheduling spark-submit and spark-sql type jobs to EMR Spark clusters (on ACK). Users can use the elasticity of ACK to adjust cluster resources as needed, realize mixed deployment with applications, and use the same set of operation and maintenance solutions at the same time. Maximize the use of resources. For Spark tasks originally running in the new version of the DataLake cluster and custom clusters, one-click migration to the ACK cluster is supported without modifying the code.
Development capability upgrade
Support each module in the space to set the yarn queue
As more and more customers begin to use data lakes to process and analyze data, it has become a common demand for computing resources to prioritize output of important ETL tasks. DataWorks supports yarn queues for setting tasks for different modules, including data analysis, data development, operation and maintenance, etc., to ensure the isolation requirements of computing resources in different scenarios.
Support workspace level Spark Conf settings
Many users find it tedious to set up conf for each spark job. Clusters are often shared by multiple departments, and setting default at the cluster level will affect other users. While DataWorks supports setting conf for a single task, it also provides the ability to set spark conf at the workspace level, which applies to all spark tasks under the space.
Support data analysis and download up to 5 million records
Support the administrator to set the maximum download volume, and through the data analysis module, up to 5 million lines of data can be downloaded to the local.
Enhance data governance capabilities
Data Governance Center Capability Upgrade
Support data health score assessment based on data lake architecture
Dataworks Data Governance Center provides proactive data governance capabilities covering pre-event problem detection, mid-event problem interception, and post-event problem discovery. Added Dataworks data development + DLF metadata management users to perform multi-dimensional data health score assessment.

Support the identification of data governance issues based on R&D/storage dimensions
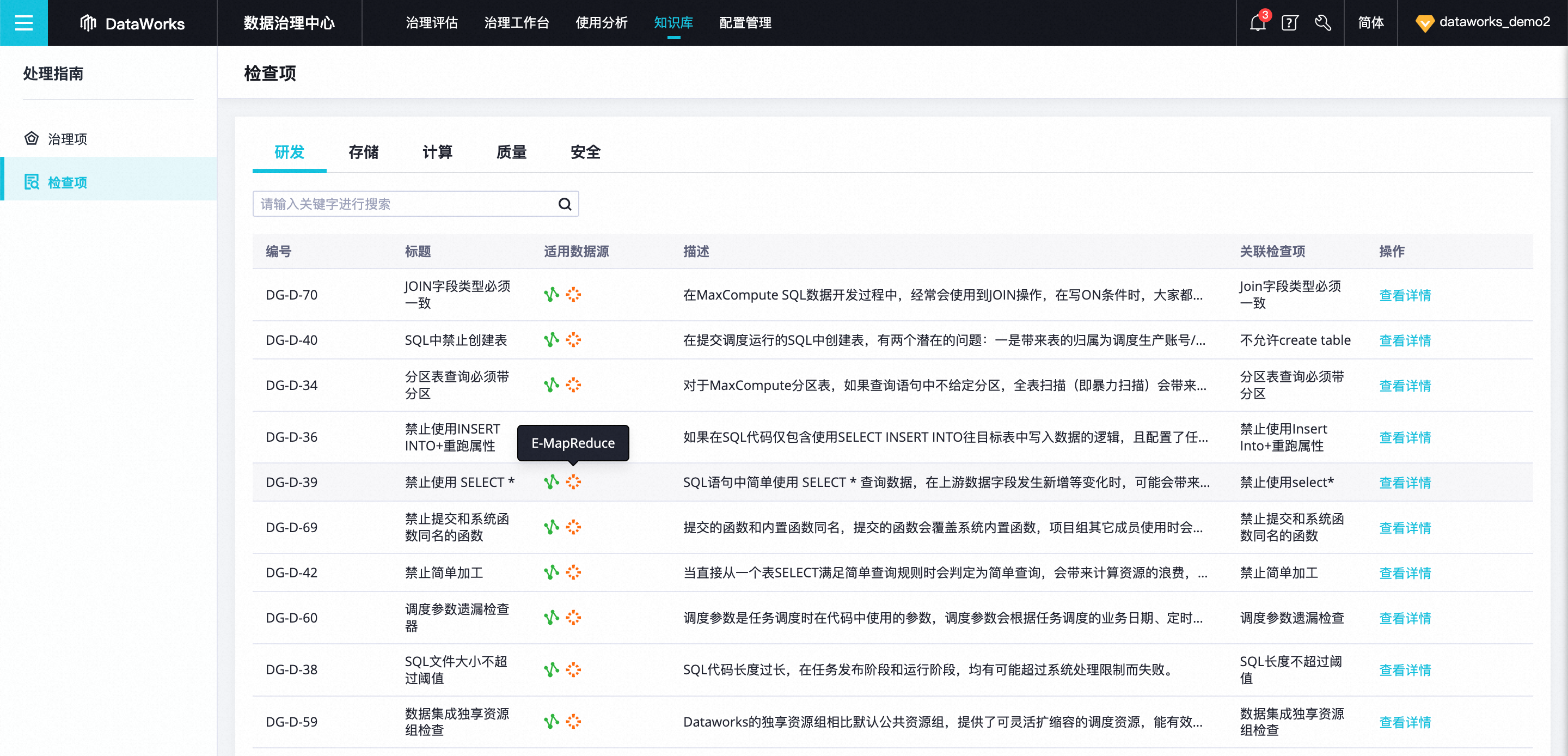
For E-MapReduce users, it can support data standard governance scenarios, with more than ten types of built-in governance items and knowledge bases in the dimensions of R&D, storage, and security. Automatic problem discovery, prompting the person in charge to solve problems in a timely manner.
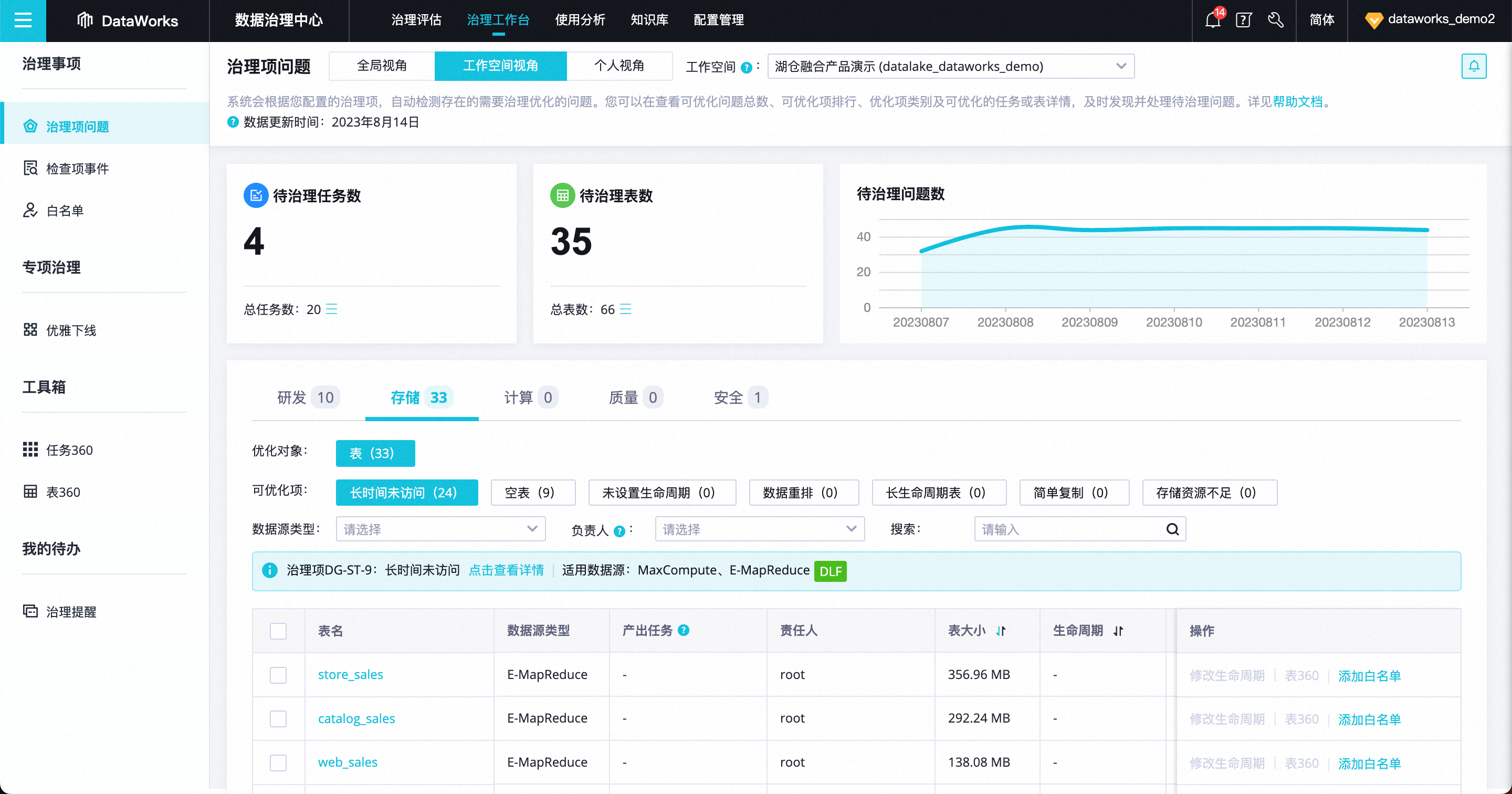
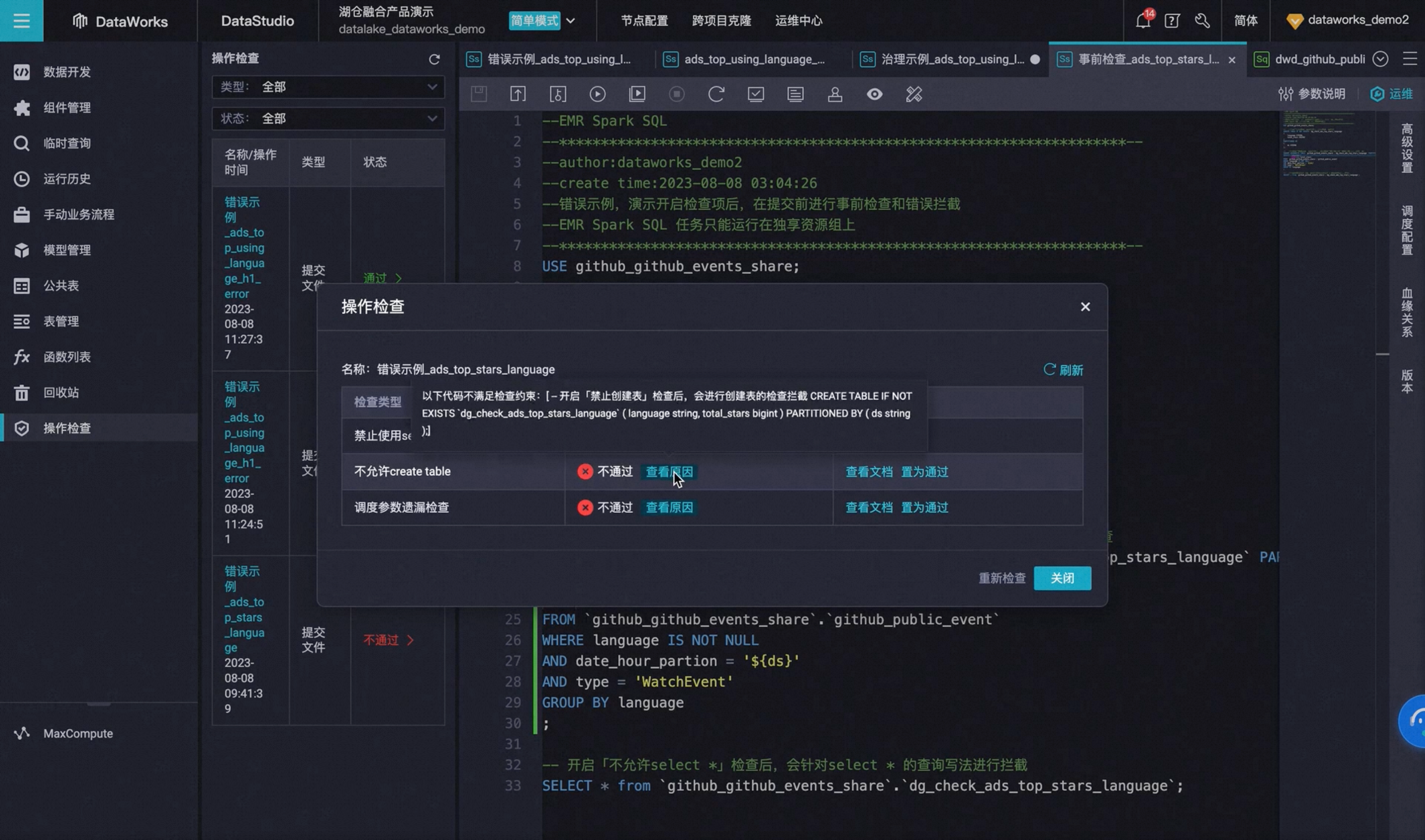
The Data Governance Center supports proactive governance based on EMR Hive/Spark SQL tasks
The Dataworks Data Governance Center has added 10 built-in data inspection items, which can check and automatically intercept data problems for the Hive SQL and Spark SQL tasks on the Dataworks data development side, and for the submission and release links, and prevent problems beforehand.
Join the group by scanning the QR code on Dingding, experience dataworks on emr data lake governance and get the first-month opening discount spree
