Recap - Focus on reptiles:
Crawl the specified page content in the page; the processing after obtaining the corresponding data information is called data analysis
Coding process:
— specified url
— make a request
— get response data
- data analysis
— persistent storage
Data analysis classification:
— regular
— bs4
— xpath (stronger versatility)
Overview of data analysis principles:
—The parsed partial text will be stored between the tags or in the attributes corresponding to the tags.
— 1. Carry out the positioning of the specified label
— 2. Extract (parse) the data value stored in the label or the attribute corresponding to the label
1. Data Analysis - Regular
1.1 findall: Match all regular content in the string
re.findall(pattern,string,flags=0)
# 用于返回包含所有匹配项的列表。返回string中所有与pattern相匹配的全部字串,返回形式为数组。
import re
# findall:匹配字符串中所有的符合正则的内容
lst = re.findall("m", "mai le fo len,mai ni mei!") #需要寻找的数,字符串
print(lst) # ['m', 'm', 'm']
#r是指被r前缀的字符串不进行转义
lst1 = re.findall(r"\d+", "5点之前,你要给我5000万")#也可以是需要的正则,字符串
print(lst1) # ['5', '5000']
#考虑到findall返回到列表效率不高
#finditer: 匹配字符串中所有到内容[返回到是迭代器],从迭代器中拿到内容需要.group()
it=re.finditer(r"\d+", "5点之前,你要给我5000万")
for i in it:
print(i.group())
'''
返回结果:
5
5000
'''1.2 search
import re
#search,找到一个结果就返回,返回的结果是match对象,拿数据需要.group()
s = re.search(r"\d+","我的电话号是:10086,我女朋友的电话是:10010")
print(s.group()) #100861.3 match
# match是从头开始匹配
s = re.match(r"\d+","我的电话号是:10086,我女朋友的电话是:10010") #当开头不是数字就会报错
s1 = re.match(r"\d+","10086,我女朋友的电话是:10010")
print(s1.group()) #10086
print(s.group()) #报错1.4 Preload regular expressions (write regular expressions in advance to facilitate future calls and improve efficiency)
import re
obj = re.compile(r"\d+")#存储正则表达式
ret=obj.finditer("我的电话号是:10086,我女朋友的电话是:10010")
for it in ret:
print(it.group())1.4.1 Case: Extract specified characters
import re
s="""
<div class='jay'><span id='1'>郭麒麟</span></div>
<div class='jj'><span id='2'>宋铁</span></div>
<div class='jolin'><span id='3'>大聪明</span></div>
<div class='sylar'><span id='4'>范思辙</span></div>
<div class='tory'><span id='5'>胡说八道</span></div>
"""
#提前编写正则表达式
# (?P<自定义组名>.*?) -》用于自定义的组名提取数据,P要大写
#后面的re.S是为了换行
obj = re.compile(r"<div class='.*?'><span id='.*?'>(?P<wahaha>.*?)</span></div>",re.S)
result = obj.finditer(s)
for i in result:
print(i.group("wahaha"))【operation result】
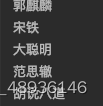
The id value is required, and a group name can also be created for the id
import re
s="""
<div class='jay'><span id='1'>郭麒麟</span></div>
<div class='jj'><span id='2'>宋铁</span></div>
<div class='jolin'><span id='3'>大聪明</span></div>
<div class='sylar'><span id='4'>范思辙</span></div>
<div class='tory'><span id='5'>胡说八道</span></div>
"""
obj = re.compile(r"<div class='.*?'><span id='(?P<id>.*?)'>(?P<wahaha>.*?)</span></div>")
result = obj.finditer(s)
for i in result:
print(i.group("id"))
print(i.group("wahaha"))
 https://www.runoob.com/python/python-reg-expressions.html#flags
https://www.runoob.com/python/python-reg-expressions.html#flags