按时间顺序,综述近5年的融合算法。重点分析了最近两年的work,欢迎留言探讨
Article directory
- foreword
- 1.SSR-Laplacian Image Fusion(2017)
- 2、FusionGAN(2019)
- 3、MBNet(2020)
- 4、DIDFuse(2020)
- 5、DDcGAN(2020)
- 6、GAN(2020)
- 7、NestFuse(2020)
- 8、AUFusion(2021)
- 9、AttentionFGAN
- 10、GANMcC
- 11、
- 12、
- 13、
- 14、PIAFusion(2022)
- 15、SeAFusion(2022)
- 16、SwinFusion(2022)
- 17、DIVFusion(2023)
- 18、CDDFuse(CVPR2023)
- 19、
- Summarize
foreword
提示:以下是本篇文章正文内容,下面案例可供参考
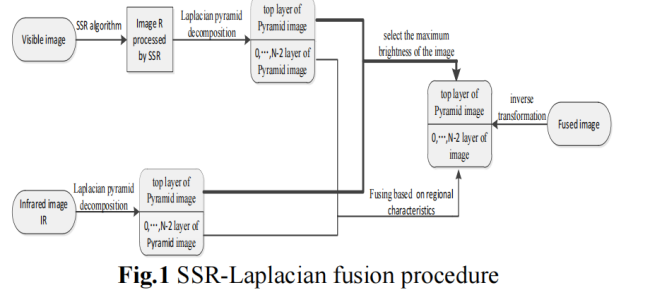
1.SSR-Laplacian Image Fusion(2017)
论文:R. Wu, D. Yu, J. Liu, H. Wu, W. Chen and Q. Gu, “An improved fusion method for infrared and low-light level visible image,” 2017 14th International Computer Conference on Wavelet Active Media Technology and Information Processing (ICCWAMTIP), 2017, pp. 147-151.
This paper presents a method for fusing low-light visible and infrared images. This article mainly adds the image preprocessing steps, and the subsequent process is the combination and extension of some traditional processing methods. SSR (Single Scale Retinex) algorithm, an algorithm developed based on Retinex's human eye physiological characteristics, is used to improve the contrast of visible light images.

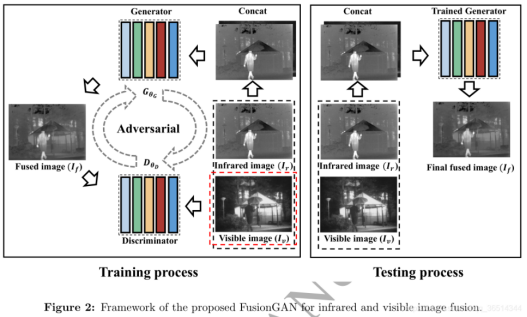
2、FusionGAN(2019)
Paper: Jiayi Ma, Wei Yu, Pengwei Liang, Chang Li, and Junjun Jiang. FusionGAN: A generative adversarial network for infrared and visible image fusion. Information Fusion 48, C (Aug 2019), 11–26, 2019.
This paper proposes FusionGAN, which applies GAN to the task of image fusion. The infrared image Ir and the visible light image Iv are connected by channels and input to the generator, and the output is the fusion image If. Considering that the texture details in the visible image are not fully extracted, the fused image If and the visible image Iv are input into the discriminator, so that If has more texture details. The generator aims to produce fused images with significant infrared intensities and additional visible gradients, and the discriminator aims to force the fused images to possess more details of visible images.
Loss function
generator:
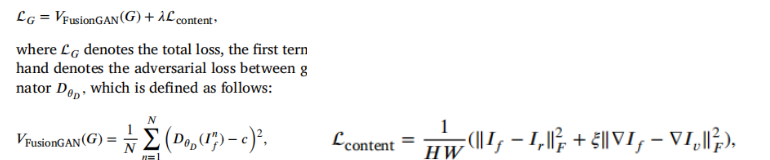
Discriminator:
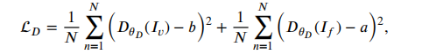
3、MBNet(2020)
Zhou, Kailai et al. “Improving Multispectral Pedestrian Detection by Addressing Modality Imbalance Problems.” European Conference on Computer Vision (2020).
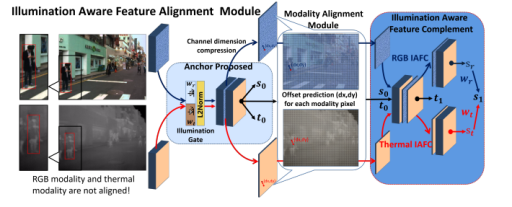
The modality imbalance problem is mainly divided into two aspects: illumination modality imbalance (light variation) and feature modality imbalance (misregistration of infrared and visible features, and inappropriate fusion methods). This paper designs a Differential Modality Aware Fusion (DMAF, Differential Modality Aware Fusion) module to make the two modalities complement each other. The Illumination Aware Feature Alignment Module (IAFA, Illumination Aware Feature Alignment Module) selects complementary features based on lighting conditions and adaptively aligns two modality features.
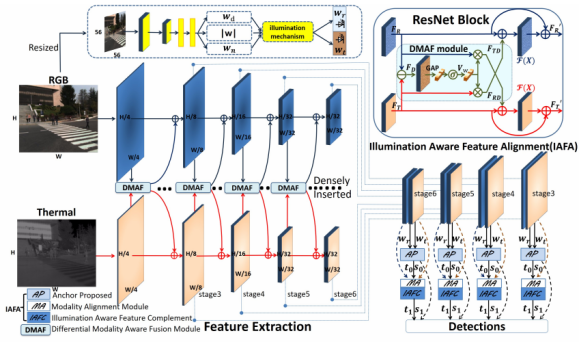
Each modality in the DMAF module contains a common part and a difference part.
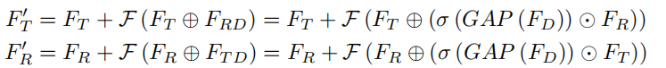
First directly subtract the two modal features to obtain the difference features, then perform global average pooling on the difference features, then perform tanh activation, and then perform channel-level weighting on the original features, and add the weighted features to another modal feature .
The IAFA module uses a small network that can predict lighting conditions from visible light images, and its loss is defined as follows:
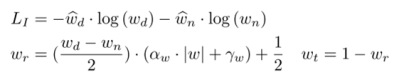
Since the infrared and visible light cameras are not all captured at the same time, this can lead to misalignment of the features. Therefore, a Modality Alignment (MA, Modality Alignment) module is proposed to predict a feature offset (dx, dy) for each pixel (x, y) of each modality, since the feature offset is a floating point number , so bilinear interpolation is used to fit (x+dx, y+dy) with the values of neighboring points.
The IAFA module first stitches the reweighted RGB and infrared features, and generates an approximate anchor position in the anchor proposed stage. The regression offset t0 predicted in the IAFC stage is used to generate deformable anchors as the basic reference for position prediction. Then the deformable anchors and confidence score s0 are further fine-tuned through the IAFC stage. Confidence scores for RGB and IR feature map predictions are further reweighted by illumination values. The final confidence score and regression offset value are as follows:
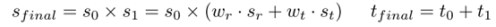
The classification loss function uses focal loss to solve the problem of sample imbalance.
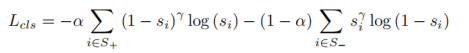
4、DIDFuse(2020)
Zixiang Zhao, Shuang Xu, Chunxia Zhang, Junmin Liu, Jiangshe Zhang and Pengfei Li, DIDFuse: Deep Image Decomposition for Infrared and Visible Image Fusion. IJCAI 2020: 970-976.
This model effectively utilizes prior information, that is, base information represents large-scale background information, and detail information is information with obvious mutual differences, that is, the infrared and visible base information are as close as possible, and the detail information of the two is as different as possible. larger. After training, the model obtains the trained encoder and decoder, and then enters the testing phase. In the test process, add a fusion layer, that is, a fusion layer, to realize the fusion of sum and fusion, and then splicing it, and input it into the decoder to realize image reconstruction. There are three strategies for the selection of the fusion strategy: direct addition, given weight addition and L1-norm (the L1 norm of the feature map is regarded as its activity measurement, and then the L1-norm of different feature maps is calculated to give set different fusion weights).
loss function
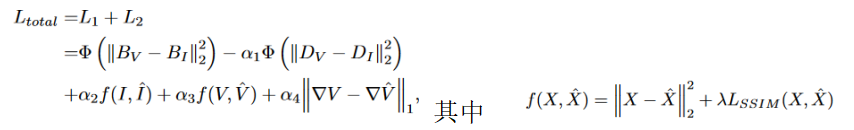
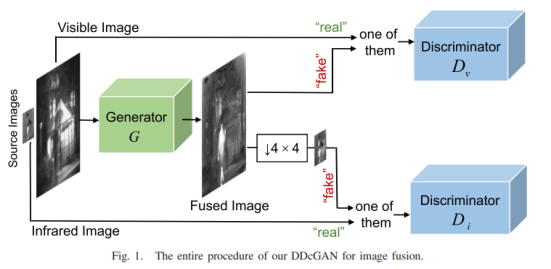
5、DDcGAN(2020)
J. Ma, H. Xu, J. Jiang, X. Mei and X. -P. Zhang, “DDcGAN: A Dual-Discriminator Conditional Generative Adversarial Network for Multi-Resolution Image Fusion,” in IEEE Transactions on Image Processing, vol. 29, pp. 4980-4995, 2020.
In this paper, a dual discriminator is designed on the basis of FusionGAN. In order to fuse images of different resolutions, the authors assume that the resolution of the visible image is 4×4 times that of the infrared image, the discriminator Dv aims to distinguish the generated image from the visible image, and the discriminator Di aims to distinguish the original A fused image of a low-resolution infrared image and downsampling (average pooling) . To maintain a balance between generator and discriminator, the input layer of each discriminator is a single channel containing sample data instead of two channels containing both sample data and the corresponding source image as condition information.
6、GAN(2020)
J. Ma et al.,“Infrared and visible image fusion via detail preserving adversarial learning,” Information Fusion, vol. 54, pp. 85–98, Feb. 2020.
The model in this paper is used to improve the detail loss problem caused by the previous GAN model, and a protection mechanism for edges is added. The generator of the model generates a fusion image, and then the fusion result is sent to the discriminator together with the visible light source image to judge whether the fusion result comes from the visible light image.
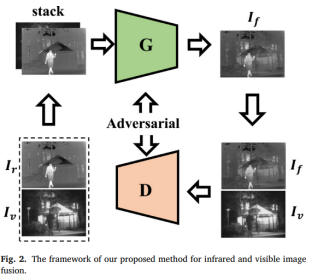
Loss function:
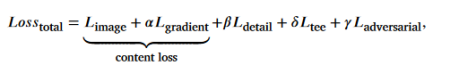

7、NestFuse(2020)
H. Li, X. -J. Wu and T. Durrani, “NestFuse: An Infrared and Visible Image Fusion Architecture Based on Nest Connection and Spatial/Channel Attention Models,” in IEEE Transactions on Instrumentation and Measurement, vol. 69, no. 12, pp. 9645-9656, Dec. 2020.
This article is an infrared-visible fusion model based on nest connection and spatial/channel attention, which can retain important information in multiple scales. The model is divided into three parts: encoder, fusion strategy and decoder. In the fusion strategy, a spatial attention model and a channel attention model are used to describe the importance of deep features at each spatial location and channel, respectively. First, the input image is sent to the encoder to extract multi-scale features, and the fusion strategy fuses these features at each scale , and finally the image is reconstructed through the decoder based on nest connection.
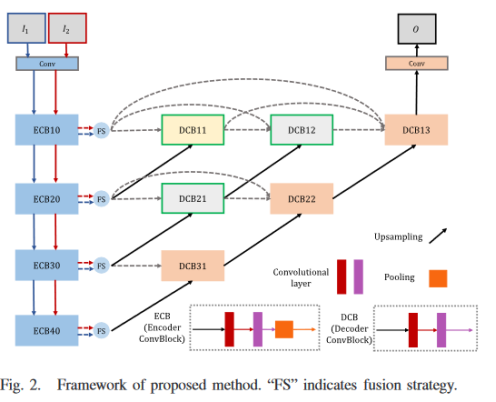
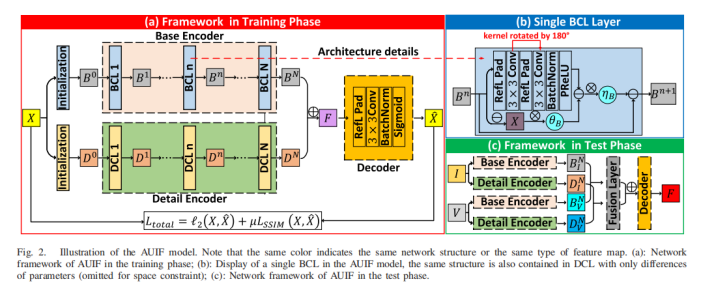
8、AUFusion(2021)
Zixiang Zhao, Shuang Xu, Jiangshe Zhang, Chengyang Liang, Chunxia Zhang and Junmin Liu, “Efficient and Model-Based Infrared and Visible Image Fusion via Algorithm Unrolling,” in IEEE Transactions on Circuits and Systems for Video Technology,2021.
In this paper, the network is constructed by means of algorithm expansion, which increases the interpretability of the network. First, an autoencoder is pre-trained for feature extraction and image reconstruction. Then some hand-designed fusion strategies (pixel-based weighted average) are used to integrate the depth features extracted from different source images to achieve image fusion. During training, infrared and visible light are alternately input to the network; during testing, infrared and visible are input in pairs. The features B 0 and D 0 in the network are obtained by blur and Laplacian filters respectively.
BCL and DCL module design, X represents the input image, B and D represent the base feature and detail feature respectively, and
g B j represents high-pass filtering, and g D j represents low-pass filtering.
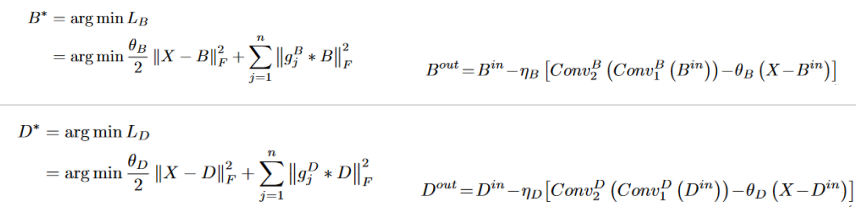
Loss function:
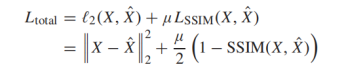
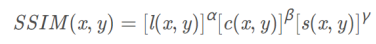
SSIM measures the similarity of two images, and this loss makes the reconstructed image close to the source image in terms of brightness, structure, and contrast.
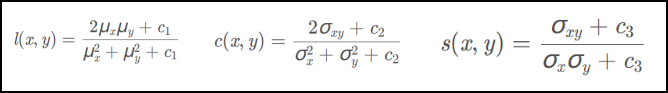
9、AttentionFGAN
J. Li, H. Huo, C. Li, R. Wang and Q. Feng, “AttentionFGAN: Infrared and Visible Image Fusion Using Attention-Based Generative Adversarial Networks,” in IEEE Transactions on Multimedia, vol. 23, pp. 1383-1396, 2021.
In this paper, the multi-scale attention mechanism is added to GAN for infrared-visible light image fusion. The multi-scale attention mechanism aims to capture comprehensive spatial information, helping the generator to focus on the foreground target information of infrared images and the background detail information of visible light images, while constraining the discriminator to pay more attention to the attention area rather than the entire input image. In the generator part, two multi-scale attention modules first obtain the attention maps of infrared and visible light images respectively, and then send the two attention maps and source images into the fusion network after splicing in the channel dimension. The two discriminators are used to distinguish the fusion image from the infrared/visible light image respectively. The structure is exactly the same, but the parameters are not shared.
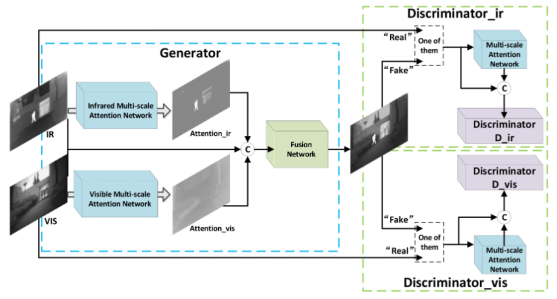
loss function
Builder:
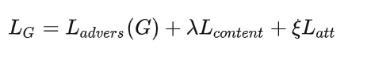
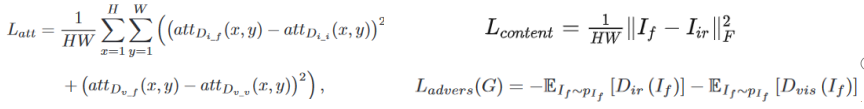
Discriminator: The first two items represent the Wasserstein distance estimate, and the last item is the gradient penalty for network regularization
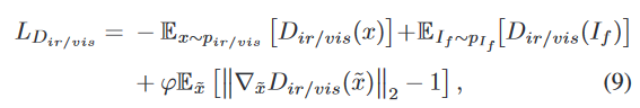
10、GANMcC
J. Ma, H. Zhang, Z. Shao, P. Liang and H. Xu, “GANMcC: A Generative Adversarial Network With Multiclassification Constraints for Infrared and Visible Image Fusion,” in IEEE Transactions on Instrumentation and Measurement, vol. 70, pp. 1-14, 2021.
The detail information of infrared images is not necessarily worse than that of visible light, and the contrast of RGB images may also be better than that of infrared images. The fused image has both significant contrast and rich texture details. The key is to ensure that the contrast and gradient information of the source image are balanced, essentially estimating the distribution of two different domains at the same time. GAN can better estimate the probability distribution of the target in an unsupervised situation, and multi-category GAN can further fit multiple distribution features at the same time to solve this unbalanced information fusion. When the visible image is overexposed, the corresponding information of the infrared image can compensate, which enables our method to remove highlights while maintaining significant contrast.
Network Architecture
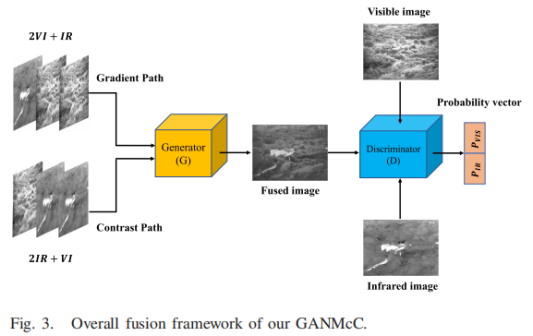
For the generator, the input is also a mixture input of the two modalities, and the fused image is obtained by the generator. For the discriminator, the input image (infrared/visible light/fusion image is optional) is classified to obtain the category of the input image, and the output is a vector containing two probability values. For the fused image, under the multi-classification constraint, the generator expects both probabilities to be high , that is, the discriminator thinks it is both an infrared image and a visible image, and the discriminator expects these two probabilities to be small at the same time, that is, the discriminator judges the fusion The image is neither infrared nor visible. During this process, both probabilities are constrained to ensure that the fused image has the same degree of true/false in both classes. After continuous adversarial learning, the generator can simultaneously fit the probability distribution of infrared images and visible images , resulting in results with significant contrast and rich texture details.
loss function
Generator: Determine the degree of retention of each type of information by adjusting the size of the weight β, and d is set to 1.
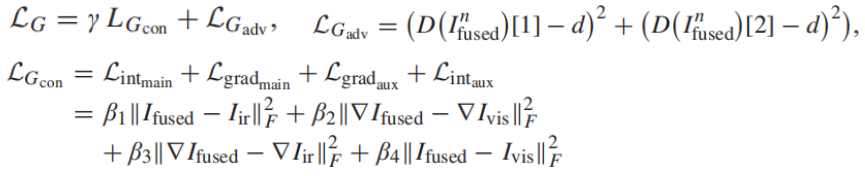
Discriminator: c is set to 0.
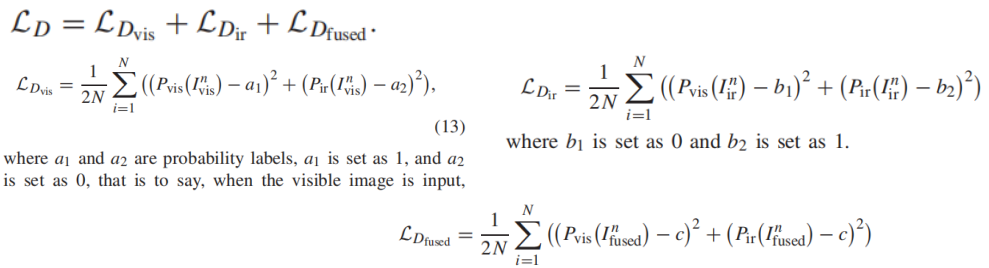
11、
12、
13、
14、PIAFusion(2022)
Linfeng Tang, Jiteng Yuan, Hao Zhang, Xingyu Jiang, and Jiayi Ma. “PIAFusion: A progressive infrared and visible image fusion network based on illumination aware”, Information Fusion, 83-84, pp. 79-92, 2022
Considering the problem of unbalanced lighting and insufficient features of fused images, this paper proposes a progressive image fusion network (PIAFusion) based on illumination perception, which adaptively maintains the intensity distribution of salient objects and preserves the texture information in the background . Specifically, this paper designs an illumination-aware sub-network to estimate the illumination distribution and calculate the illumination probability. In addition, the illumination probability is used to construct the illumination perception loss to guide the training of the fusion network, and the cross-modal differential perception fusion module is used to fuse the common information and complementary information of infrared and visible features. In addition, this paper released a large benchmark dataset (MSRS, Multi-Spectral Road Scenarios) for infrared and visible image fusion.
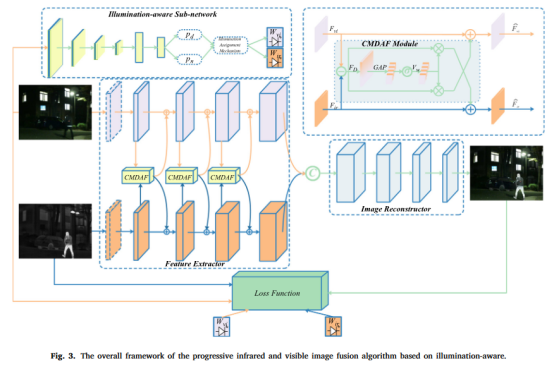
The light perception sub-network uses the cross-entropy loss function, and the backbone network loss function is
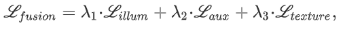
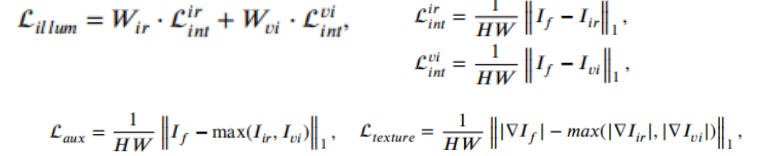
15、SeAFusion(2022)
Tang, Linfeng, Jiteng Yuan, and Jiayi Ma. “Image fusion in the loop of high-level vision tasks: A semantic-aware real-time infrared and visible image fusion network.” Information Fusion 82 (2022): 28-42.
The paper proposes a semantic-aware image fusion framework that utilizes high-level vision tasks to drive image fusion. At the same time, considering the requirement of real-time performance, a lightweight network is designed in terms of network design. And in order to enhance the network's description of fine-grained details, a Gradient Residual Dense Block (GRDB) is designed. Finally, considering that the existing evaluation indicators only use EN, MI, SF and other statistical indicators to measure the quality of image fusion. The authors also propose a task-driven evaluation, which measures the quality of fusion results by their performance on high-level vision tasks.
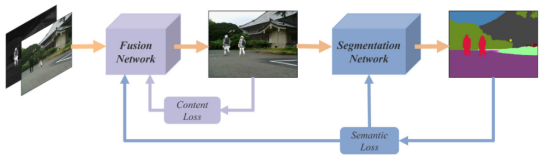
The source image passes through the fusion network to generate a fusion image, and the fusion network image passes through a segmentation network to obtain the segmentation result. The segmentation result and labels construct a semantic loss, and construct a content loss before fusing the image and the source image. The semantic loss is only used to constrain the segmentation network, and the content loss and semantic loss jointly constrain the optimization of the fusion network. In this way, the semantic loss can return the semantic information required for advanced vision tasks (segmentation) back to the fusion network, so that the fusion network can effectively retain the semantic information in the source image.
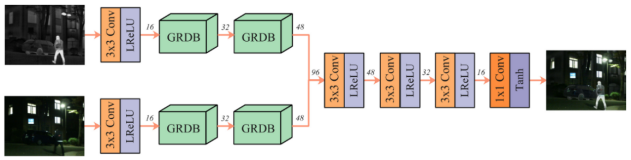
For the fusion network, SeAFusion uses the framework of double-branch feature extraction and Concat fusion to reconstruct the image, while using the features extracted by the gradient operator in GRDB as the residual connection can strengthen the network's extraction of detailed features.
Since there is no groundtruth for image fusion, it is impossible to use the fusion results to pre-train a segmentation model to guide the training of the fusion network. Therefore, the author alternately trains the fusion network and the segmentation network to maintain the balance between image fusion and semantic segmentation. Vision task performance without compromising the performance of the fusion network.
Result comparison:

16、SwinFusion(2022)
J. Ma, L. Tang, F. Fan, J. Huang, X. Mei and Y. Ma, “SwinFusion: Cross-domain Long-range Learning for General Image Fusion via Swin Transformer,” in IEEE/CAA Journal of Automatica Sinica, vol. 9, no. 7, pp. 1200-1217, July 2022.
On the one hand, this paper designs an attention-guided cross-domain module to achieve sufficient integration of complementary information and global interactions. The method consists of a self-attention-based intra-domain fusion unit and a cross-attention-based inter-domain fusion unit , which mine and integrate long dependencies within the same domain and across domains. Through long-range dependency modeling, the network can fully realize domain-specific information extraction and cross-domain complementary information integration, and maintain appropriate apparent strength from a global perspective. A shifted window mechanism is introduced in self-attention and cross-attention, which allows the model to receive images of arbitrary size. On the other hand, both multimodal image fusion and digital photography image fusion are generalized to the design of structure, texture and strength preservation. A unified loss function form is defined to constrain all image fusion problems. The SwinFusion model performs well in both multimodal image fusion and digital photography image fusion tasks.
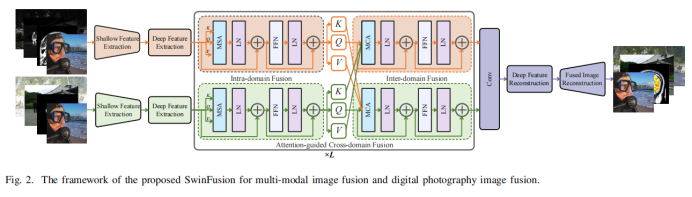

The SwinFusion model can be divided into three parts: feature extraction, attention-guided cross-domain fusion, and reconstruction.
17、DIVFusion(2023)
Linfeng Tang, Xinyu Xiang, Hao Zhang, Meiqi Gong, and Jiayi Ma. “DIVFusion: Darkness-free infrared and visible image fusion”, Information Fusion, 91, pp. 477-493, 2023
(1) The innovation of the paper:
the current image fusion methods are designed for infrared and visible light images under normal lighting. In night scenes, existing methods suffer from severe degradation of visible light images, resulting in weak texture details and poor visual perception, which affects subsequent visual applications. Treating image enhancement and image fusion as independent tasks often leads to incompatibility issues, resulting in poor image fusion results. In this paper, low-light image enhancement technology and image fusion technology are combined to reasonably illuminate the dark, promote the aggregation of complementary information, and obtain a fusion image with good visual perception.
(2) Overall architecture:
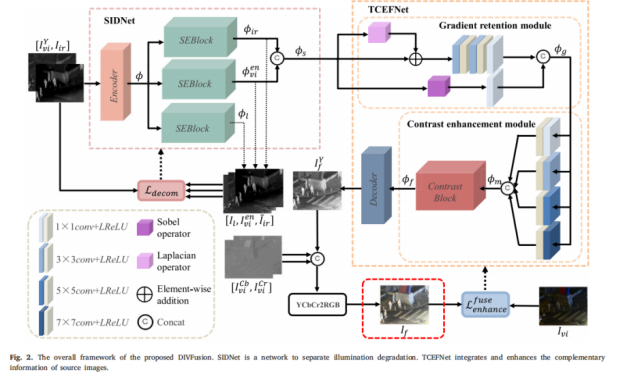
First, a scene illumination decoupling network (SIDNet, scene illumination disentangled network) is designed to remove the illumination degradation in night-time visible light images while retaining the information characteristics of the source image. In order to fuse complementary information and enhance the contrast and texture details of fusion features, a texture-contrast enhancement fusion network (TCEFNet, texture-contrast enhancement fusion network) is designed. The proposed method is able to generate fused images with realistic colors and significant contrast in an end-to-end manner.
(3) The loss function
is mainly divided into two stages of training
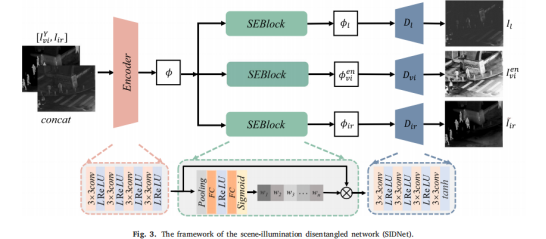
and one stage : SIDNet is used for self-supervised reconstruction of the original image, which consists of an encoder, an attention block, and a decoder. The decoder only forces SIDNet to generate better features during training, so when using the model to fuse images, there is no need to generate reconstructed images. The degenerated lighting features are stripped, and the sum is used as input for the next stage.
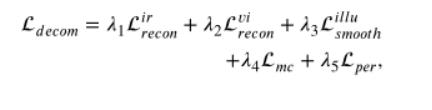
Wherein, L per is to use the image enhanced by histogram equalization as a comparison, so that an enhanced visible light image can be generated.
The second stage: fix SIDNet, train TCEFNet.
In addition to intensity loss and texture loss, color consistency loss is also designed to alleviate color distortion caused by enhancement and fusion.
18、CDDFuse(CVPR2023)
Correlation-Driven Dual-Branch Feature Decomposition for Multi-Modality Image Fusion
Correlation-Driven Dual-Branch Feature Decomposition in Multi-Modal Image Fusion
19、
Summarize
提示:这里对文章进行总结:
For example: the above is what we will talk about today. This article only briefly introduces the use of pandas, and pandas provides a large number of functions and methods that allow us to process data quickly and easily.