Table of contents
2.1.mapping mapping properties
2.2. CRUD of the index library
2.2.1. Create index library and mapping
2.2.3. Modify the index library
2.2.4. Delete the index library
2. Index library operation
The index library is similar to the database table, and the mapping mapping is similar to the table structure.
If we want to store data in es, we must first create "library" and "table".
2.1.mapping mapping properties
Mapping is a constraint on documents in the index library. Common mapping attributes include:
-
type: field data type, common simple types are:
-
String: text (text that can be segmented), keyword (exact value, such as: brand, country, ip address)
-
Value: long, integer, short, byte, double, float,
-
Boolean: boolean
-
date: date
-
Object: object
-
-
index: Whether to create an index, the default is true
-
analyzer: which tokenizer to use
-
properties: subfields of this field
For example the following json document:
{
"age": 21,
"weight": 52.1,
"isMarried": false,
"info": "黑马程序员Java讲师",
"email": "[email protected]",
"score": [99.1, 99.5, 98.9],
"name": {
"firstName": "云",
"lastName": "赵"
}
}Corresponding to each field mapping (mapping):
-
age: The type is integer; participate in the search, so the index needs to be true; no tokenizer is required
-
weight: The type is float; participate in the search, so the index needs to be true; no tokenizer is required
-
isMarried: The type is boolean; participate in the search, so the index needs to be true; no tokenizer is required
-
info: The type is a string, word segmentation is required, so it is text; to participate in the search, so the index needs to be true; the word segmenter can use ik_smart
-
email: The type is a string, but word segmentation is not required, so it is a keyword; it does not participate in the search, so the index needs to be false; no word segmentation is required
-
score: Although it is an array, we only look at the type of the element, which is float; participate in the search, so the index needs to be true; no tokenizer is required
-
name: The type is object, and multiple sub-attributes need to be defined
-
name.firstName; the type is a string, but word segmentation is not required, so it is a keyword; it participates in the search, so the index needs to be true; no word segmentation is required
-
name.lastName; the type is a string, but word segmentation is not required, so it is a keyword; it participates in the search, so the index needs to be true; no word segmentation is required
-
2.2. CRUD of the index library
Here we uniformly use Kibana to write DSL to demonstrate.
2.2.1. Create index library and mapping
Basic syntax:
-
Request method: PUT
-
Request path: /index library name, which can be customized
-
Request parameter: mapping mapping
Format:
PUT /indexbasename
{
"mappings": {
"properties": {
"field name": {
"type": "text",
"analyzer": "ik_smart"
},
"Field name 2":{
"type": "keyword",
"index": "false"
},
"Field name 3":{
"properties": {
"subfield": {
"type": "keyword"
}
}
},
// ...slightly
}
}
}
Example:
PUT /at home
{
"mappings": {
"properties": {
"info":{
"type": "text",
"analyzer": "ik_smart"
},
"email":{
"type": "keyword",
"index": "false"
},
"name":{
"properties": {
"firstName": {
"type": "keyword"
}
}
},
// ... slightly
}
}
}
2.2.2. Query index library
Basic syntax :
-
Request method: GET
-
Request path: /index library name
-
Request parameters: none
Format :
GET /indexbasename
Example :

2.2.3. Modify the index library
Although the structure of the inverted index is not complicated, once the data structure changes (for example, the tokenizer is changed), the inverted index needs to be recreated, which is a disaster. Therefore, once the index library is created, the mapping cannot be modified .
Although the existing fields in the mapping cannot be modified, it is allowed to add new fields to the mapping because it will not affect the inverted index.
Grammar description :
PUT /index library name/_mapping
{
"properties": {
"New field name": {
"type": "integer"
}
}
}
Example :

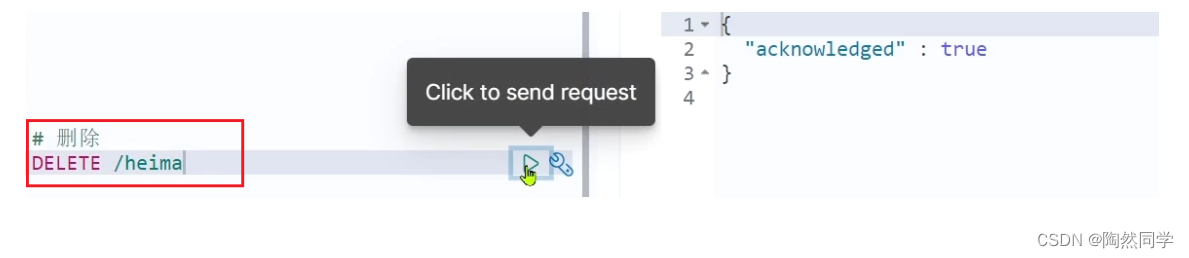
2.2.4. Delete the index library
grammar:
-
Request method: DELETE
-
Request path: /index library name
-
Request parameters: none
Format:
DELETE /index library name
Test in kibana:
2.2.5. Summary
What are the index library operations?
-
Create an index library: PUT /index library name
-
Query index library: GET / index library name
-
Delete the index library: DELETE /index library name
-
Add field: PUT /index library name/_mapping