Unity Android's simple sorting of word segmentation processing (including word attribute processing) using HanLP
Table of contents
Appendix: In HanLP, the nature field of the Term object indicates the part of speech
1. Brief introduction
The technologies that will be used in Unity Android development are simply sorted out, which is convenient for you to view in the future, and it would be better if it can help everyone.
This section introduces that in the development of Unity, the method of encapsulating the word segmentation function of HanLP from Android and calling it in Unity is organized and encapsulated to be called by Unity. The method is not unique, and corrections are welcome.
On the Android platform, in addition to HanLP, there are other algorithms and tools that can be used for Chinese word segmentation. The following are some common Chinese word segmentation algorithms, and some advantages of HanLP in word segmentation:
Common Chinese word segmentation algorithms and tools:
ansj_seg: ansj_seg is a Chinese word segmentation tool based on CRF and HMM model, suitable for Java platform. It supports fine-grained and coarse-grained word segmentation, and has certain custom dictionary and part-of-speech tagging functions.
jieba: jieba is a Chinese word segmentation library widely used in Python, but also has its Java version. It uses a word segmentation method based on a prefix dictionary, and performs well in terms of speed and effect.
lucene-analyzers-smartcn: This is a Chinese tokenizer in the Apache Lucene project, using a rule-based word segmentation algorithm. It is widely used in Lucene search engine.
ictclas4j: ictclas4j is a Chinese word segmentation tool developed by the Institute of Computing Technology, Chinese Academy of Sciences, based on the HMM model. It supports custom dictionaries and part-of-speech tagging.
Advantages of HanLP word segmentation:
Multi-domain applicability: HanLP is designed as a multi-domain Chinese natural language processing toolkit, which not only includes word segmentation, but also supports various tasks such as part-of-speech tagging, named entity recognition, and dependency syntax analysis.
Performance and effect: HanLP has been trained and optimized on multiple standard datasets, and has good word segmentation effect and performance.
Flexible dictionary support: HanLP supports custom dictionaries, and you can add vocabulary in professional fields as needed to improve word segmentation.
Open Source: HanLP is open source, you can use, modify and distribute it freely, which facilitates customization and integration into your projects.
Multilingual support: HanLP not only supports Chinese, but also supports other languages, such as English, Japanese, etc., which facilitates cross-language processing.
Active community: HanLP has an active community and maintenance team that helps with problem solving and support.
In a word, HanLP is a feature-rich and high-performance Chinese natural language processing tool, which is suitable for various application scenarios, especially in multi-domain text processing tasks. However, the final choice depends on your specific needs and project context.
HanLP Official Website: HanLP | Online Demo
2. Implementation principle
1. On the Android side, use StandardTokenizer.segment(text) to pass in the Text content for word segmentation, use Term.word; to get the word segmentation content, and Term.nature.toString() to get the attributes of the word segmentation
2. Expose the functional interface encapsulated on the Android side to Unity calls
/**
* 开始分词
* @param wordsContent
* @return 返回分词结果,和此属性
*/
public String segmentWork(String wordsContent)3. Obtain the object interface of the Android side on the Unity side, and simply process the information to make it more suitable for use on the Unity side
MAndroidJavaObject.Call<string>("segmentWork", wordsContent)3. Matters needing attention
1. Chinese words will have a more accurate corresponding attribute, but English words may not
2. Generally, the interaction between Android and Unity can only transfer the basic data types, and the advanced objects of the list object may not be transferred. Here, the data of the list object is assembled into a string and passed to Unity. Unity parses the corresponding information based on the string
4. Effect preview
(Here, the part of speech only makes a simple correspondence, if you need more correspondence, please refer to the appendix part of speech information)

5. Implementation steps
HanLP package (hanlp-portable-1.7.5.jar) can be downloaded directly in Android Studio here
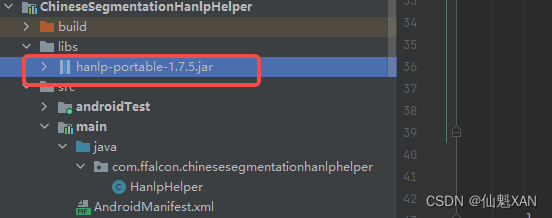
1. Open Android Studio, create a module project, and add the hanlp-portable-1.7.5.jar package
Note: Remember to add as a library
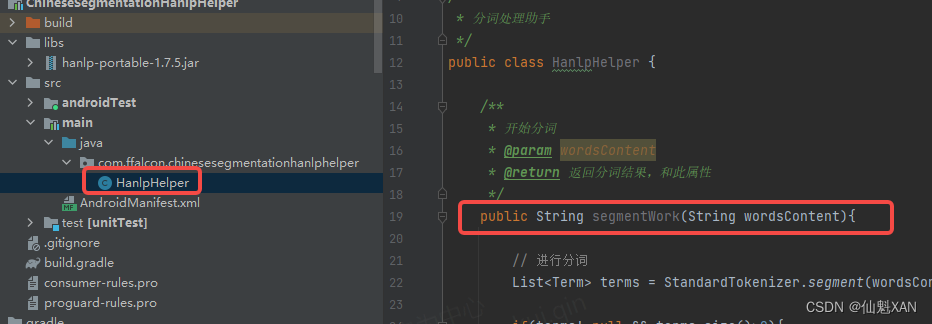
2. Create a script and add word segmentation function
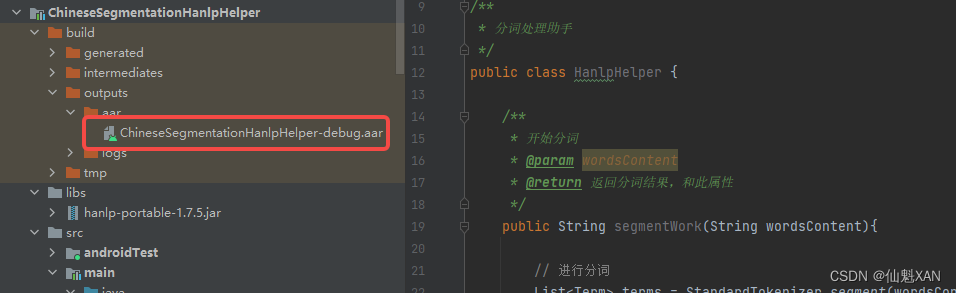
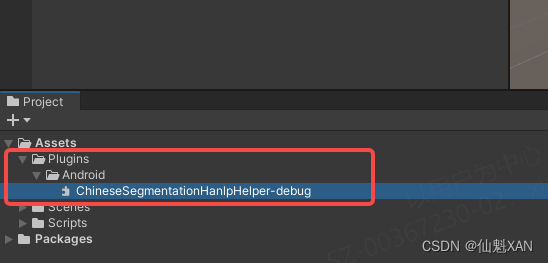
3. Create a Unity project and add the compiled aar to Unity
4. Create a script in Unity, call the interface encapsulated in Android, and write a script to test the function

5. Add the test script to the scene
6. Package, install and run on the machine, the effect is as above
6. Key code
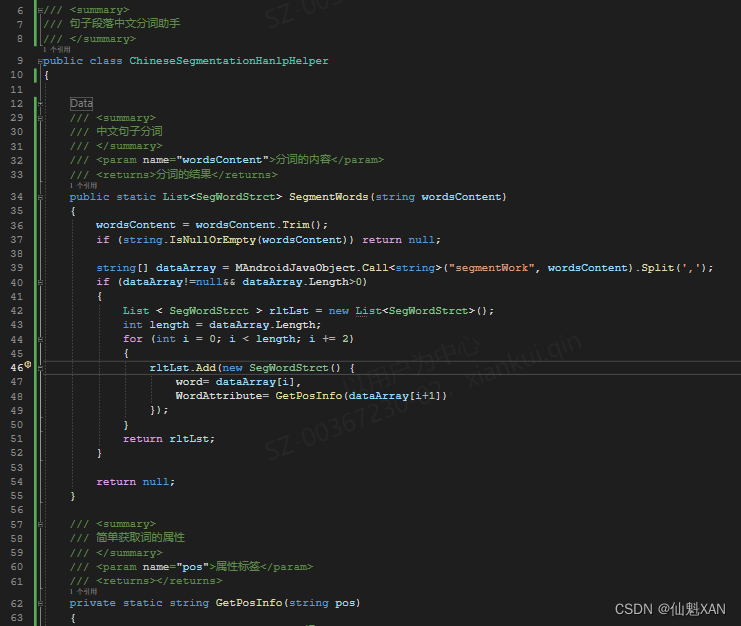
1、TestChineseSegmentationHanlpHelper.cs
using System.Collections.Generic;
using UnityEngine;
public class TestChineseSegmentationHanlpHelper : MonoBehaviour
{
// Start is called before the first frame update
void Start()
{
List<SegWordStrct> segWordStrcts = ChineseSegmentationHanlpHelper.SegmentWords("今天深圳的天气如何");
foreach (var word in segWordStrcts)
{
Debug.Log($"{word.word},{word.WordAttribute}");
}
}
}2、ChineseSegmentationHanlpHelper.cs
using System.Collections.Generic;
using UnityEngine;
/// <summary>
/// 句子段落中文分词助手
/// </summary>
public class ChineseSegmentationHanlpHelper
{
#region Data
static AndroidJavaObject _mAndroidJavaObject;
protected static AndroidJavaObject MAndroidJavaObject
{
get
{
if (_mAndroidJavaObject == null)
{
_mAndroidJavaObject = new AndroidJavaObject("com.ffalcon.chinesesegmentationhanlphelper.HanlpHelper");
}
return _mAndroidJavaObject;
}
}
#endregion
/// <summary>
/// 中文句子分词
/// </summary>
/// <param name="wordsContent">分词的内容</param>
/// <returns>分词的结果</returns>
public static List<SegWordStrct> SegmentWords(string wordsContent)
{
wordsContent = wordsContent.Trim();
if (string.IsNullOrEmpty(wordsContent)) return null;
string[] dataArray = MAndroidJavaObject.Call<string>("segmentWork", wordsContent).Split(',');
if (dataArray!=null&& dataArray.Length>0)
{
List < SegWordStrct > rltLst = new List<SegWordStrct>();
int length = dataArray.Length;
for (int i = 0; i < length; i += 2)
{
rltLst.Add(new SegWordStrct() {
word= dataArray[i],
WordAttribute= GetPosInfo(dataArray[i+1])
});
}
return rltLst;
}
return null;
}
/// <summary>
/// 简单获取词的属性
/// </summary>
/// <param name="pos">属性标签</param>
/// <returns></returns>
private static string GetPosInfo(string pos)
{
// 这里你可以根据需要添加更多的判断逻辑来确定词性属性
if (pos.Equals("n"))
{
return WordAttributeStrDefine.Noun;
}
else if (pos.Equals("v"))
{
return WordAttributeStrDefine.Verb;
}
else if (pos.Equals("ns"))
{
return WordAttributeStrDefine.PlaceName;
}
else if (pos.Equals("t"))
{
return WordAttributeStrDefine.Time;
}
else
{
return WordAttributeStrDefine.Other;
}
}
}
/// <summary>
/// 数据分词结构
/// </summary>
public struct SegWordStrct
{
public string word;
public string WordAttribute;
}
/// <summary>
/// 此属性文字定义
/// 较多,这里只定义了部分
/// </summary>
public class WordAttributeStrDefine {
public const string Noun ="名词";
public const string Verb ="动词";
public const string PlaceName ="地名";
public const string Time ="时间";
public const string Other ="其他";
}
3、HanlpHelper.java
package com.xxxx.chinesesegmentationhanlphelper;
import com.hankcs.hanlp.seg.common.Term;
import com.hankcs.hanlp.tokenizer.StandardTokenizer;
import java.util.ArrayList;
import java.util.List;
/**
* 分词处理助手
*/
public class HanlpHelper {
/**
* 开始分词
* @param wordsContent
* @return 返回分词结果,和此属性
*/
public String segmentWork(String wordsContent){
// 进行分词
List<Term> terms = StandardTokenizer.segment(wordsContent);
if(terms!=null && terms.size()>0){
List<String> rltWordAttr = new ArrayList<>();
// 遍历分词结果,判断词性并打印
for (Term term : terms) {
String word = term.word;
String pos = term.nature.toString();
String posInfo = getPosInfo(pos); // 判断词性属性
System.out.println("Word: " + word + ", POS: " + pos + ", Attribute: " + posInfo);
rltWordAttr.add(word);
rltWordAttr.add(pos);
}
String[] dataArray = rltWordAttr.toArray(new String[0]);
return String.join(",", dataArray);
}
return null;
}
/**
* 判断词性属性
* @param pos
* @return
*/
public String getPosInfo(String pos) {
// 这里你可以根据需要添加更多的判断逻辑来确定词性属性
if (pos.equals("n")) {
return "名词";
} else if (pos.equals("v")) {
return "动词";
} else if (pos.equals("ns")) {
return "地名";
}else if (pos.equals("t")) {
return "时间";
}
else {
return "其他";
}
}
}
Addendum: In HanLP, Termthe object's naturefield represents the part of speech
In HanLP, the nature field of the Term object represents the Part of Speech (POS). HanLP uses a standard Chinese part-of-speech tagging system, and each part of speech has a unique identifier. Here are some common Chinese part-of-speech tags and their meanings:
Nouns:
n: common nouns
nr: personal
names ns: place names
nt: institution names
nz: other proper names
nl: noun idioms
ng: noun morphemesTime class:
t: time wordVerb categories:
v: verb
vd: adverb
vn: noun verb
vshi: verb "is"
vyou: verb "has"Adjective class:
a: adjective
ad: adverbAdverb class:
d: adverbPronoun class:
r: pronoun
rr: personal pronoun
rz: demonstrative pronoun
rzt: time demonstrative pronounConjunctions:
c: ConjunctionsParticle class:
u: particleNumeral class:
m: NumeralQuantifier class:
q: quantifierModal particle class:
y: Modal particleInterjection class:
e: interjectionOnomatopoeic part of speech:
o: onomatopoeiaPosition part of speech:
f: position wordState part of speech:
z: state wordPreposition class:
p: prepositionPrefix class:
h:prefixSuffix class:
k:suffixPunctuation class:
w: punctuationPlease note that the above are just some common part-of-speech tags and their meanings, and the actual situation may be more complicated. You can investigate HanLP documentation for more details on part-of-speech tagging as needed. Based on these part-of-speech tags, you can write code to judge the attributes of words (such as verbs, nouns, place names, etc.) and perform corresponding processing.