Table of contents
Complete code (CamvidDataset function)
Dataset introduction
The Camvid driving scene dataset is used, which contains 701 driving scene semantic segmentation images, which are divided into training set, verification set, and test set, with 367, 101, and 233 images respectively.
The dataset directory is as follows:
Dataset download link
Link: https://pan.baidu.com/s/1HLviQ3AUU7jinWX0YCMWtA?pwd=aaaa
Extraction code: aaaa
Dataset function - read data
Data reading steps
1. What data to read: index output by sampler
2. Where to read data: root_dir (path) in Dataset
3. How to read data: the __getitem__(self,index) function in Dataset reads data according to the index index (you need to write the key function yourself)
label introduction
Intercept some labels in train_labels
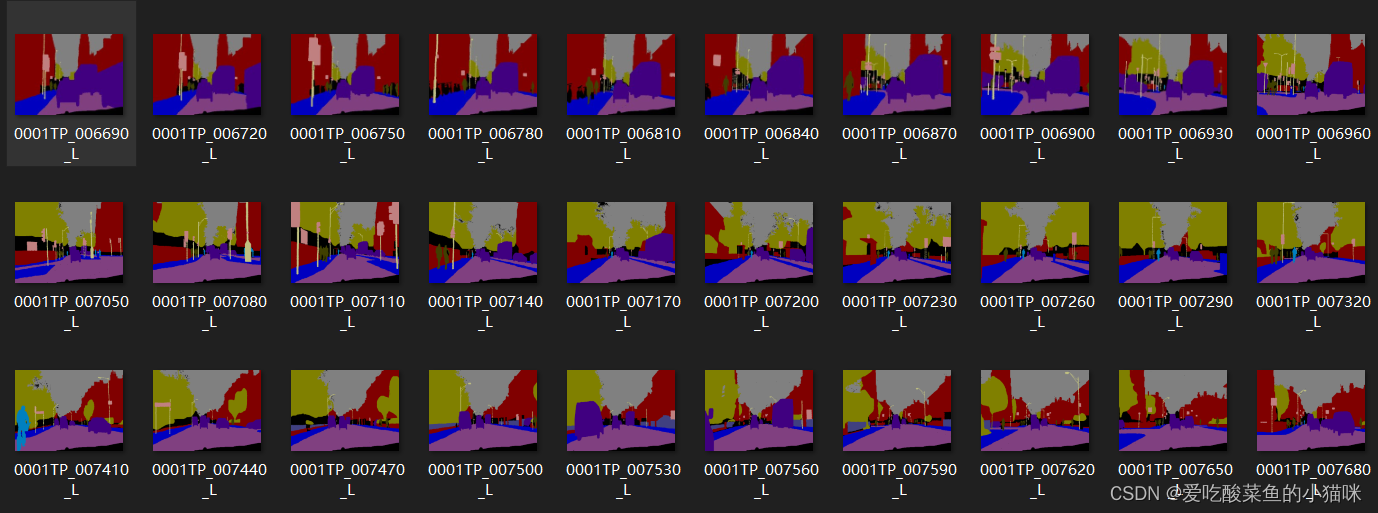
It can be seen that: different from the label in image classification, it is a specific label 0 1 2 ... 11 (the whole picture represents a category ); the label in image segmentation is a color RGB three-channel picture, and different colors represent different Category ( the whole image is divided into different categories pixel by pixel ), and the correspondence table between colors and categories is shown in class_dict.csv. (A total of 12 categories)
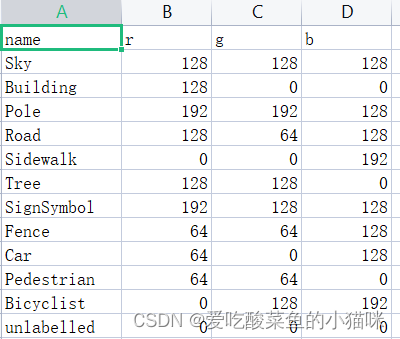
Label encoding method
Read the class_dict.csv file and generate a colormap:
colormap=[[128, 128, 128],[128, 0, 0],[192, 192, 128],[128, 64, 128],[0, 0, 192],[128, 128, 0][192, 128, 128],[64, 64, 128],[64, 0, 128],[64, 64, 0],[0, 128, 192],[0, 0, 0]]
(A total of 12 categories, use the subscript colormap.index(a) of the elements in the list to indicate the category of element a)
Read any label, change its shape from (h,w,3)->(h,w), each element in (h,w) represents the category of the current pixel
import numpy as np
from PIL import Image
colormap=[[128, 128, 128],[128, 0, 0], [192, 192, 128],[128, 64, 128],[0, 0, 192],[128, 128, 0],[192, 128, 128],[64, 64, 128],[64, 0, 128],[64, 64, 0],[0, 128, 192],[0, 0, 0]]
label_path=r'D:\图像分割\camvid_from_paper\train_labels\0001TP_006690_L.png'
label=Image.open(label_path)
label = np.array(label) # 此时label.shape=(h,w,3)
h, w, _ = label.shape
label = label.tolist() # 将label转化为list,三维列表
# 遍历label中的每一个元素,为RGB三通道颜色,例如[128,0,0]
for i in range(h):
for j in range(w):
label[i][j] = colormap.index(label[i][j]) # colormap中元素的下标0-11作为类别0-11
label = np.array(label,dtype='int64').reshape((h, w)) # reshape为(h,w)
print(label)This code is defined in the complete code LabelProcessor.cm2label function
Complete code (CamvidDataset function)
from PIL import Image
from torch.utils.data import Dataset,DataLoader
import pandas as pd
import numpy as np
import torchvision.transforms as transforms
import os
import torch
class LabelProcessor:
cls_num = 12
def __init__(self,file_path):
"""
self.colormap 颜色表 [[128,128,128],[128,0,0],[],...,[]] ['r','g','b']
self.names 类别名
"""
self.colormap,self.names=self.read_color_map(file_path)
def read_color_map(self,file_path):
# 读取csv文件
pd_read_color=pd.read_csv(file_path)
colormap=[]
names=[]
for i in range(len(pd_read_color)):
temp=pd_read_color.iloc[i] # DataFrame格式的按行切片
color=[temp['r'],temp['g'],temp['b']]
colormap.append(color)
names.append(temp['name'])
return colormap,names
def cm2label(self,label):
"""将RGB三通道label (h,w,3)转化为 (h,w)大小,每一个值为当前像素点的类别"""
label = np.array(label)
h, w, _ = label.shape
label = label.tolist()
for i in range(h):
for j in range(w):
label[i][j] = self.colormap.index(label[i][j])
label = np.array(label,dtype='int64').reshape((h, w))
return label
class CamvidDataset(Dataset):
def __init__(self,img_dir,label_dir,file_path):
"""
:param img_dir: 图片路径
:param label_dir: 图片对应的label路径
:param file_path: csv文件(colormap)路径
"""
self.img_dir=img_dir
self.label_dir=label_dir
self.imgs=self.read_file(self.img_dir)
self.labels=self.read_file(self.label_dir)
self.label_processor=LabelProcessor(file_path)
# 类别总数与以及类别名
self.cls_num=self.label_processor.cls_num
self.names=self.label_processor.names
def __getitem__(self, index):
"""根据index下标索引对应的img以及label"""
img=self.imgs[index]
label=self.labels[index]
img=Image.open(img)
label=Image.open(label)
img,label=self.img_transform(img,label)
return img,label
def __len__(self):
if len(self.imgs)==0:
raise Exception('Please check your img_dir'.format(self.img_dir))
return len(self.imgs)
def read_file(self,path):
"""生成每个图片路径名的列表,用于getitem中索引"""
file_path=os.listdir(path)
file_path_list=[os.path.join(path,img_name) for img_name in file_path]
file_path_list.sort()
return file_path_list
def img_transform(self,img,label):
"""对图片做transform"""
transform_img=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
])
img=transform_img(img)
label = self.label_processor.cm2label(label)
label=torch.from_numpy(label) # numpy转化为tensor
return img,label
if __name__=='__main__':
# 路径
root_dir='D:\图像分割\camvid_from_paper'
img_path = os.path.join(root_dir,'train')
label_path = os.path.join(root_dir,'train_labels')
file_path = os.path.join(root_dir,'class_dict.csv')
train_data=CamvidDataset(img_path,label_path,file_path)
train_loader=DataLoader(train_data,batch_size=8,shuffle=True,num_workers=0)
for i,data in enumerate(train_loader):
img_data,label_data=data
print(img_data.shape,type(img_data))
print(label_data.shape,type(label_data))
Output result:
torch.Size([8, 3, 360, 480]) <class 'torch.Tensor'>
torch.Size([8, 360, 480]) <class 'torch.Tensor'>
(each element in label_data is a number between 0-11)