1. Getting to know ES for the first time
(1) Concept:
ES is an open source search engine, combined with data visualization [Kibana], data capture [Logstash, Beats] and integrated into ELK (Elastic Stack), ELK is widely used in log data analysis and real-time monitoring and other fields, ES is the core component .
(2) Function: efficient query search content.
(3) Development history:
1. The underlying implementation is Lucene , a Java language search engine class library, one of Apache's top products, developed by DoungCutting in 1999, official address: https://lucene.apache.org/
Lucene's advantage: easy to expand (Secondary development possible), high performance (based on inverted index)
Disadvantages of Lucene: only limited to Java development, steep learning curve, does not support horizontal expansion
2. In 2004, Shay Banon developed Compass based on Lucene
3. In 2010, Shay Banon rewrote Compass and renamed it to Elasticsearch
official address: https://www.elastic.co/cn/
Advantages of ES:
- Support distributed, support horizontal expansion
- Provide a RESTful interface that can be called by any language
(4) Advantages of ES over other search engines
Ranked according to the frequency of use of search engine technology, the top three are
- ES: open source distributed search engine (commonly used)
- Splunk: Commercial Projects
- Solr: Apache's open source resource engine (commonly used)
(5) Forward index and inverted index
1. Forward index
Traditional databases (such as MySQL) use forward index.
- Match content to query item by item
- If it does not match, discard it, if it matches, put it into the result set
2. Inverted index
ES uses inverted index.
- Document (document): each piece of data is a document
- Term: the words that the document is divided into semantically
The inverted index first separates the fields of the index application into terms and stores them in the term-id key-value pair table. If the terms are the same, only the id of the current data row is recorded in the id of the index table field.
The matching data order of the inverted index:
- Word segmentation of search content
- The obtained entry goes to the entry list to query the id
- Query documents by document id
- Data is stored in the result set
(6) Concept comparison between ES and MySQL
- ES is for document storage, which can be a piece of commodity data or an order information in the database.
- Document data will be serialized into json format and stored in elasticsearch.
1. ES document
{
"id": 1,
“title”: "小米手机",
"price": 2499
}
{
"id": 2,
“title”: "华为手机",
"price": 4699
}
{
"id": 3,
“title”: "华为小米充电器",
"price": 49
}
{
"id": 4,
“title”: "小米手环",
"price": 299
}
2. ES index
Index (Index) is a collection of documents of the same type (you can know whether the types are the same by looking at the document structure).
3. Concept comparison between MySQL and ES
- Table: Index —— index, which is a collection of documents, similar to the table of the library (Table)
- Row: Document —— document, which is a data row, similar to a row (Row) in a database, and the document is in JSON format
- Column: Field —— Field, which is an attribute in a JSON document, similar to a column in a database (Column)
- Schema: Mapping - Mappings are document constraints in an index, such as field type constraints. Similar to the table structure of the database (Schema)
- SQL: DSL —— DSL is a JSON-style request statement provided by ES, which is used to do ES and realize CRUD
4. Architecture
MySQL architecture: Good at transaction type operations to ensure data security and consistency. (mainly write operations)
ES architecture: good at searching, analyzing, and computing massive amounts of data. (mainly read operations)
(7) Install ES and kibana
Why install kibana? Because kibana can assist us in operating ES.
1. Deploy a single ES
(1) Create a network
Because we also need to deploy the kibana container, we need to interconnect the es and kibana containers and create a network.
docker network create es-net

(2) Load the image
docker pull elasticsearch:7.12.1
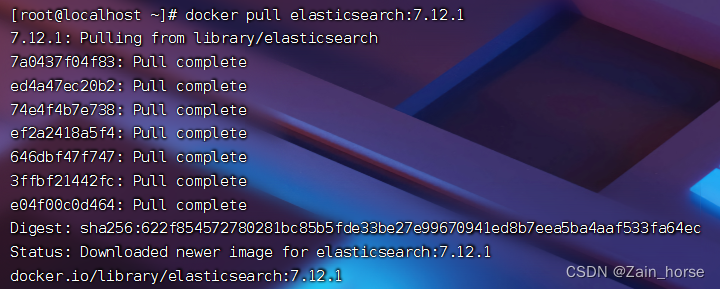
(3) run ES
Run the docker command to deploy single point es:
# -e "cluster.name=es-docker-cluster:设置集群名称
# -e "ES_JAVA_OPTS=-Xms512m -Xmx512m": 设置堆内存大小
# -e "discovery.type=single-node": 配置部署类型为单点
# -v es-data:/usr/share/elasticsearch/data: ES数据挂载点
# -v es-plugins:/usr/share/elasticsearch/plugins: ES插件挂载点
# --network es-net: 容器加载到网络
# -p 9200:9200: 暴露的HTTP访问接口
# -p 9300:9300: 暴露容器访问端口
docker run --name es \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v es-data:/usr/share/elasticsearch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
--privileged \
--network es-net \
-p 9200:9200 \
-p 9300:9300 \
-d elasticsearch:7.12.1
Access port 9200

2, department kibana
docker pull kibana:7.12.1
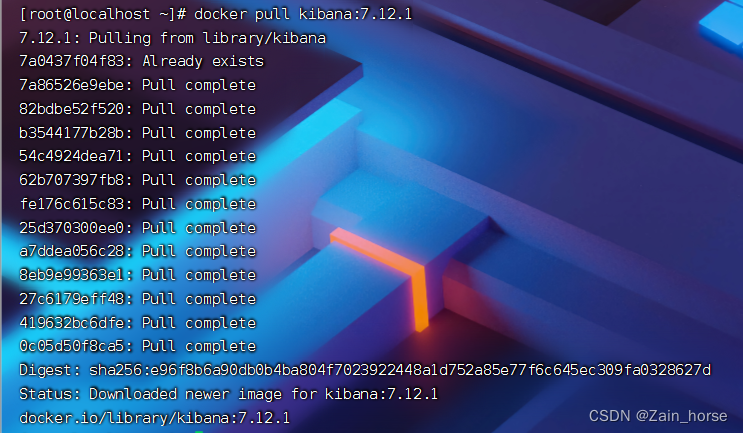
# --network=es-net: 加入到ES的网络中
# -e ELASTICSEARCH_HOSTS=http://es:9200: 配置ES主机地址,因为在同一个网络中,所以可以直接用容器名访问ES
# -p 5601:5601: 端口映射配置
docker run --name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=es-net \
-p 5601:5601 \
-d kibana:7.12.1

Access the Kibana console
DSL request desk
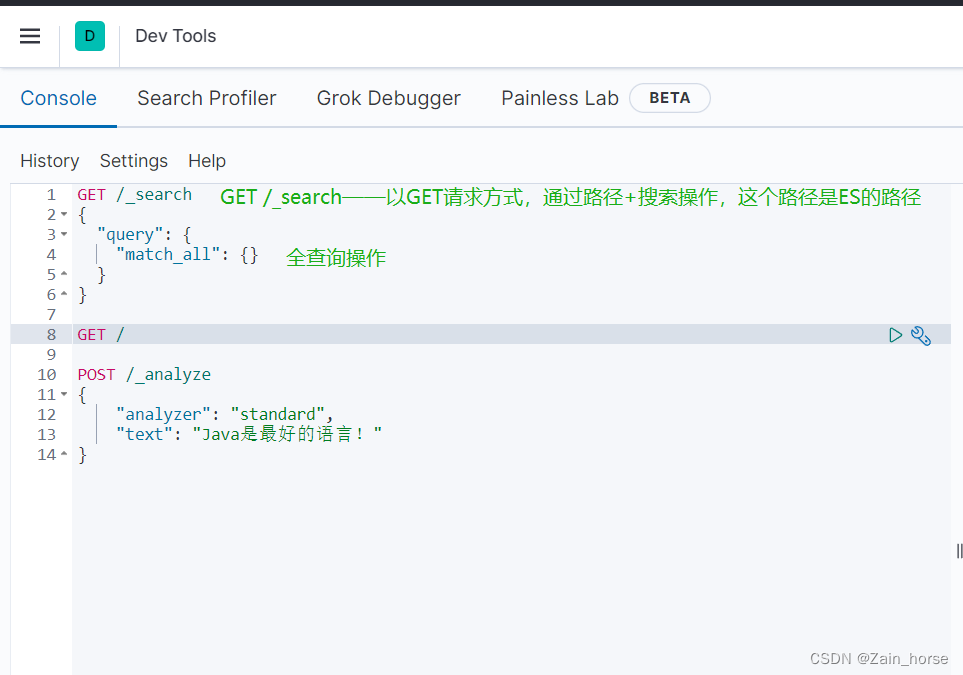
(8) Tokenizer
ES needs to segment the document when creating an inverted index; when searching, it needs to segment the content entered by the user, but the default word segmentation rules are not good for Chinese processing.
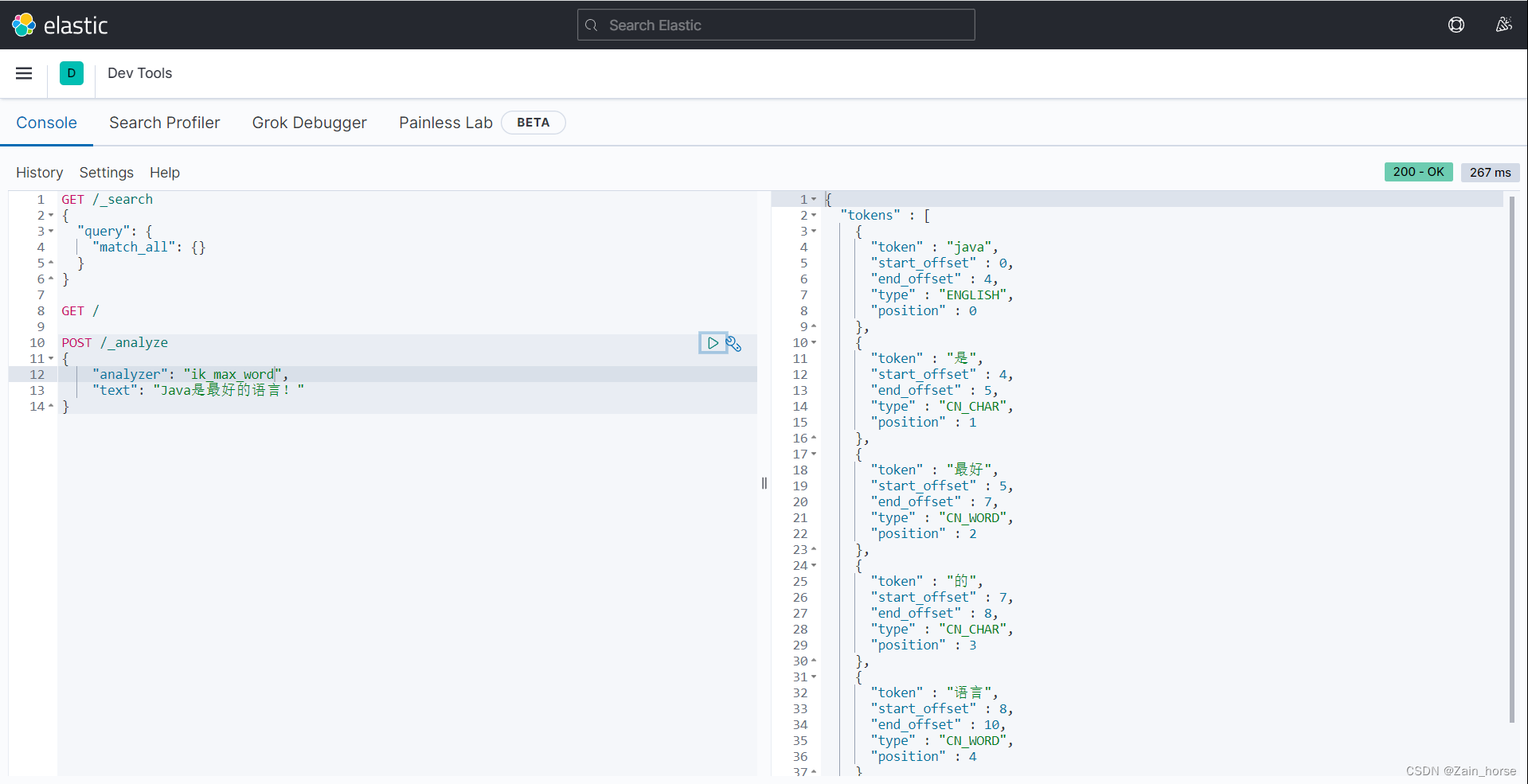
We use the Kibana console to do a Chinese test:
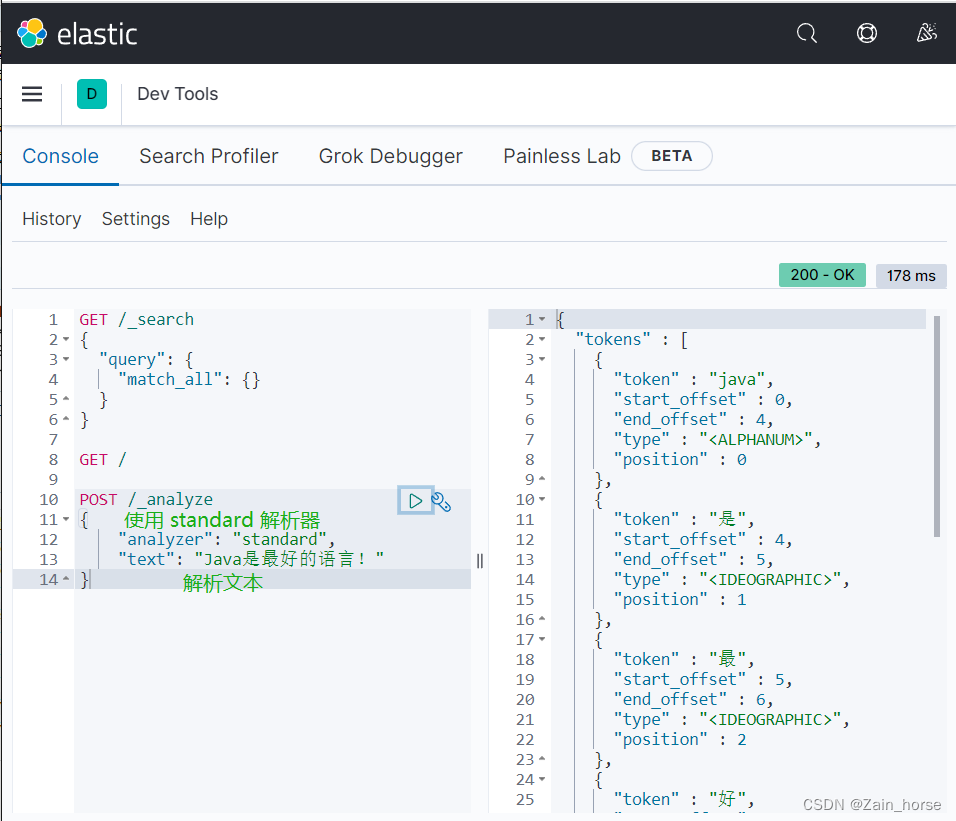
Chinese word breaker IK
Official website: https://github.com/medcl/elasticsearch-analysis-ik
1. Deploy the IK tokenizer
Online installations may experience connection denials
#进入ES容器
docker exec -it es /bin/bash
#下载 IK分词器
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip
#退出
exit
#重启容器
docker restart elasticsearch
Install ik offline
1. Download ik.7.12.1, zip
2. After decompression, transfer to elasticsearch-plugins data volume
3. Restart docker
docker restart es
4. Check that the IK tokenizer is loaded successfully
docker logs -f es
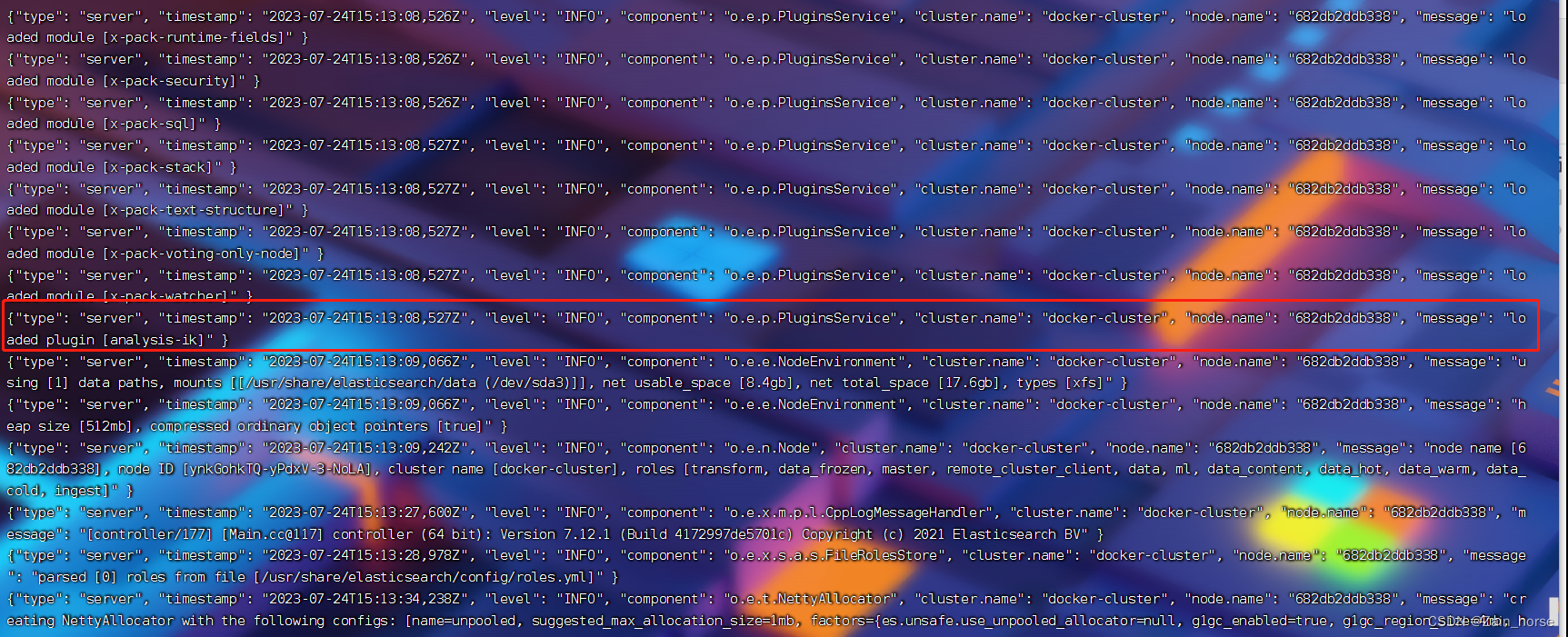
5. Test
-
ik_smart: coarse-grained distinction, only split once for analysis.
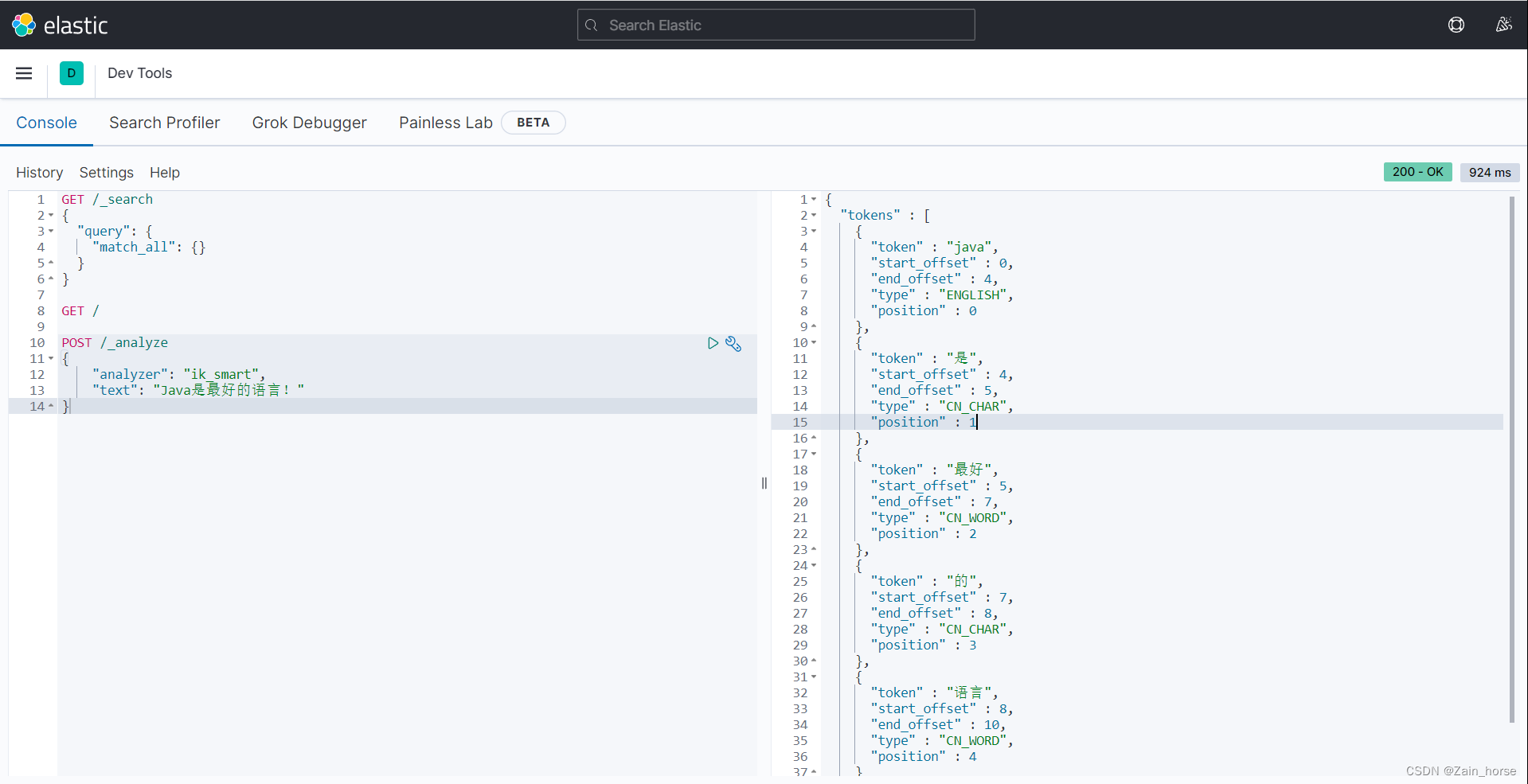
-
ik_max_word: The most fine-grained split, the largest possible separation of more words
(9) Extended entries and disabled entries of the IK tokenizer
The bottom layer of the IK tokenizer is matched based on the dictionary. If the dictionary is matched, it will be split directly, and if it is not matched, it will not be split.
So we need to expand the IK word segmentation .
1. Modify the /config/IKAnalyzer.cfg.xml file of the IK tokenizer
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">stopword.dic</entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
2. Create ext.dic and stopword.dic
These two files are just text files, separated by carriage returns, one word per line.
These two files must be configured in the config directory, otherwise they cannot be read, and the dictionary of the plug-in author is also in the config directory.
3. Restart docker
docker restart es
2. Operation index library
(1) mapping mapping
Common mapping properties
- type: field data type, common types are
- Strings : text (text that can be segmented), keyword (text that cannot be segmented)
- Value: byte, short, integer, long, float, double
- Boolean: boolean
- date: date
- object: object
- geo_point: A point identified by longitude and latitude, e.g. "32.8138,120.58558"
- geo_shape: A geometric figure composed of multiple points, such as a straight line LINESTRING(-77.06581831,-77.008463181)
- index: Whether to create an index, the default is true
- analyzer: the tokenizer used
- properties: subfields of this field, such as properties in objects
- text: participle text
Regarding the problem of array collection: mapping supports multiple types of a single type.
(2) Create an index library
ES operates index libraries and documents through RESTful requests. The content of the request is represented by a DSL statement.
The DSL syntax for creating an index library and mapping is as follows:
PUT /test
{
"mappings": {
"properties": {
"info": {
"type": "text"
"analyzer": "ik_smart
},
"email": {
"type": "keyword",
"index": "false"
},
"name": {
"type": "object",
"properties": {
"firstName": {
"type": "keyword"
},
"lastName": {
"type": "keyword"
}
}
}
}
}
}
Common success effects
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "test"
}
There is also a little trick here: when we need multi-field search, we can use copy_toattribute copy.
"all": {
"type": "text",
"analyzer: "ik_max_word"
},
"brand": {
"type": "keyword",
"copy_to": "all"
}
(3) View, delete, and modify the index library
1. View the index library
GET /test
Effect
{
"test" : {
"aliases" : { },
"mappings" : {
"properties" : {
"email" : {
"type" : "keyword",
"index" : false
},
"info" : {
"type" : "text",
"analyzer" : "ik_smart"
},
"name" : {
"properties" : {
"firstName" : {
"type" : "keyword"
},
"lastName" : {
"type" : "keyword"
}
}
}
}
},
"settings" : {
"index" : {
"routing" : {
"allocation" : {
"include" : {
"_tier_preference" : "data_content"
}
}
},
"number_of_shards" : "1",
"provided_name" : "test",
"creation_date" : "1690214456747",
"number_of_replicas" : "1",
"uuid" : "IIdXK-pATYOns4c8BDoaMw",
"version" : {
"created" : "7120199"
}
}
}
}
}
2. Delete the index library
DELETE /test
Effect
删除成功效果
{
"acknowledged" : true
}
再次查询索引库
{
"error" : {
"root_cause" : [
{
"type" : "index_not_found_exception",
"reason" : "no such index [test]",
"resource.type" : "index_or_alias",
"resource.id" : "test",
"index_uuid" : "_na_",
"index" : "test"
}
],
"type" : "index_not_found_exception",
"reason" : "no such index [test]",
"resource.type" : "index_or_alias",
"resource.id" : "test",
"index_uuid" : "_na_",
"index" : "test"
},
"status" : 404
}
3. Modify the index library (only fields can be added)
PUT /test/_mapping
{
"properties": {
"age": {
"type": "integer
}
}
}
Effect
新增成功
{
"acknowledged" : true
}
再次查询/test索引库
{
"test" : {
"aliases" : { },
"mappings" : {
"properties" : {
"age" : {
"type" : "integer"
},
"email" : {
"type" : "keyword",
"index" : false
},
"info" : {
"type" : "text",
"analyzer" : "ik_smart"
},
"name" : {
"properties" : {
"firstName" : {
"type" : "keyword"
},
"lastName" : {
"type" : "keyword"
}
}
}
}
},
"settings" : {
"index" : {
"routing" : {
"allocation" : {
"include" : {
"_tier_preference" : "data_content"
}
}
},
"number_of_shards" : "1",
"provided_name" : "test",
"creation_date" : "1690214957185",
"number_of_replicas" : "1",
"uuid" : "HeoHP6GYS-uovI1DQyxEsg",
"version" : {
"created" : "7120199"
}
}
}
}
}
3. Document Operation
(1) New document
POST /test/_doc/1
{
"info": "Java是最好的语言",
"age": 18,
"email": :"[email protected]",
"name": {
"firstName": "Zengoo",
"lastName": "En"
}
}
Effect
{
"_index" : "test",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
(2) Delete the document
DELETE /test/_doc/1
Effect
删除成功
{
"_index" : "test",
"_type" : "_doc",
"_id" : "1",
"_version" : 2,
"result" : "deleted",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}
再次查询
{
"_index" : "test",
"_type" : "_doc",
"_id" : "1",
"found" : false
}
(3) Modify the document
PUT /test/_doc/1
{
"info": "这是我的ES拆分Demo"
}
Effect
修改成功
{
"_index" : "test",
"_type" : "_doc",
"_id" : "1",
"_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 3,
"_primary_term" : 1
}
再次查询
{
"_index" : "test",
"_type" : "_doc",
"_id" : "1",
"_version" : 2,
"_seq_no" : 3,
"_primary_term" : 1,
"found" : true,
"_source" : {
"info" : "这是我的ES拆分Demo"
}
}
We can see that directly using PUT to modify will directly overwrite the original document.
So we use the second modification method.
POST /test/_update/1
{
"doc": {
"info": "这是我的ES拆分Demo"
}
}
Effect
更新成功
{
"_index" : "test",
"_type" : "_doc",
"_id" : "1",
"_version" : 11,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 12,
"_primary_term" : 1
}
查询文档
{
"_index" : "test",
"_type" : "_doc",
"_id" : "1",
"_version" : 11,
"_seq_no" : 12,
"_primary_term" : 1,
"found" : true,
"_source" : {
"info" : "这是我的ES拆分Demo",
"age" : 18,
"email" : "[email protected]",
"name" : {
"firstName" : "Zengoo",
"lastName" : "En"
}
}
}
(4) Query documents
GET /test/_doc/1
Effect
{
"_index" : "test",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"info" : "Java是最好的语言",
"age" : 18,
"email" : "[email protected]",
"name" : {
"firstName" : "Zengoo",
"lastName" : "En"
}
}
}
4. RestClient operates the index library
(1) RestClient
ES officially provides ES clients in different languages. The essence of these clients is to assemble DSL statements and send them to ES through HTTP requests.
Official document: https://www.elastic.co/guide/en/elasticsearch/client/index.html
(2) Install RestClient
Install RestHighLevelClient dependency
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-hight-level-client</artifatId>
</dependency>
Override the default ES version
<properties>
<elasticsearch.version>7.12.1</elasticsearch.version>
</properties>
Initialize RestHighLevelClient
RestHightLevelClient client = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://192.168.92.131:9200")));
(3) RestClient operates the index library
Create an index library
//1、创建Request对象
CreateIndexRequest request = new CreateIndexRequest("test");
//2、请求参数,
//MAPPING_TEMPLATE 是静态常量字符串,描述的是自定义的创建索引库的DSL语句
//XContentType.JSON 是指定DSL语句以JSON格式化
request.source(MAPPING_TEMPLATE, XContentType.JSON);
//3、发起请求
//indices, 返回对象中包含的所有索引库操作方法
//RequestOptions.DEFAULT, 默认请求头
client.indices().create(request, RequestOptions.DEFAULT);
delete index library
CreateIndexRequest request = new CreateIndexRequest("test");
client.indices().delete(request, RequestOptions.DEFAULT);
Query the existence status of the index library
CreateIndexRequest request = new CreateIndexRequest("test");
boolean status = client.indices().exists(request, RequestOptions.DEFAULT);
(4) RestClient operation data document
create document
//根据ID查询数据, hotelService的自定义的方法getById
Hotel hotel = hotelService.getById(1L);
//转换类型,由于数据库类型与DSL类型有差异,所以需要定义一个转换类进行属性转换,即转换类构造器改造实体类。
HotelDoc hotelDoc = new HotelDoc(hotel);
//1、创建Request对象
IndexRequest request = new IndexRequest("test").id(hotel.getId().toString());
//2、准备JSON文档, 通过fastjson快速转换成json格式文本
request.source(JSON.toJSONString(hotelDoc, XContentType.JSON);
//3、发送请求
//index, 就是发送请求的那个索引
client.index(request, RequestOptions.DEFAULT);
query document
//1、创建request对象
GetRequest request = new GetRequest("test").id("1");
//2、发送请求,得到结果
GetResponse response = client.get(request, RequestOptions.DEFAULT);
//3、解析结果
String json = response.getSourceAsString();
System.out.println(JSON.parseObject(json, HotelDoc.class));
delete document
//1、创建request对象
DeleteRequest request = new DeleteRequest("test").id("1");
//2、发送请求,得到结果
client.delete(request, RequestOptions.DEFAULT);
modify document
Method 1: Full modification
Method 2: Partial modification
//1、创建Request对象
UpdateRequest request = new UpdateRequest("test","1");
//2、准备参数,每两个参数为一对
request.doc(
"age": 18,
"name": "Rose"
);
//3、更新文档
client.update(request, RequestOptions.DEFAULT);
Batch import documents
Use ideas
1. Query database data through mybatis
2. Convert entity class data into document type data
3. RestClient uses Bulk batch processing
//1、创建Bulk请求
BulkRequest request = new BulkRequest();
//2、添加批量处理请求
for(Hotel hotel: hotels){
HotelDoc hotelDoc = new HotelDoc(hotel);
request.add(new IndexRequest("hotel").id(hotel.getId().toString()).source(JSON.tJSONString(hotelDoc),XContentType.JSON));
}
//3、发起请求
client.bulk(request, RequestOptions.DEFAULT);