[Must-see] Original statement: Please indicate the author & source of the article when reprinting: Are you all using Stream?
Hello, I am Xiao Suoqi, this time I will explain the key points of the new features of JDK 8! Stream flow, when you learn the framework later, you will find a lot of Stream flow, if you don’t understand, trust Sochi, you will definitely come back again (Sochi also learns the framework..)
Although the content is very dry, the code is rather boring. If you don’t want to read it now, you can bookmark it for future reference~
Stream API
Why use the Stream API
-
Stream stream is a new API introduced in Java 8! Importance is important. It is mainly a tool for processing collection data. Stream stream can be used to filter, sort, map, reduce and other operations on collections. These operations can be completed through chain calls, making the code more concise and easy to read. Stream also supports parallel processing, which can help us process large amounts of data faster.
-
The power of Stream is that it provides a wealth of intermediate operations, which greatly simplifies the computational complexity of source data compared to containers such as collections or arrays.
In actual development, most data sources in the project come from MySQL, Oracle, etc. But now there are more data sources, such as MongDB, Radis, etc., and these NoSQL data need to be processed at the Java level.
Non-relational database (NOSQL): MongDB, Radis, using non-traditional table structures, such as documents, key-value pairs, graphics, etc., these structures do not need to use SQL statements for query and operation
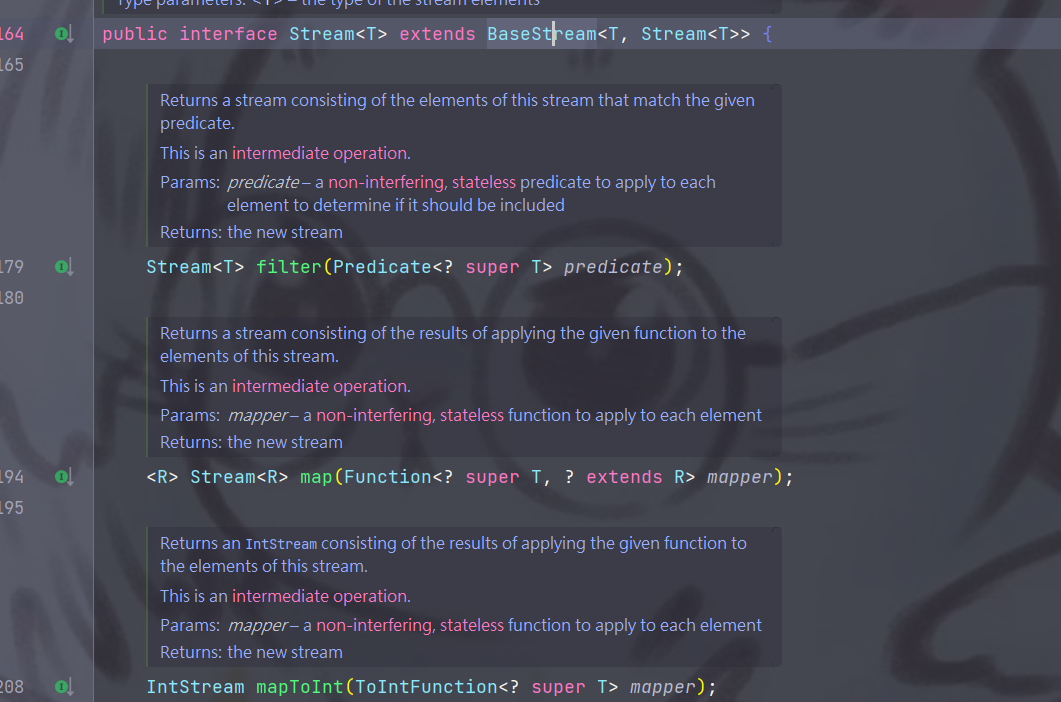
image-20230717001419217
example
Scale client sends request -> Java background (write SQL statement) -> DB query, the result is returned to Java background -> client display
For non-relational databases, we can use StreamAPI to filter at the memory level
At the memory level, non-relational databases usually use a key-value storage method, which can directly store data in memory, which can greatly improve the speed of data reading and writing. Additionally, non-relational databases typically employ a distributed architecture for high availability and scalability
Data filtering using a relational database may be slower than using a non-relational database, because relational databases require operations such as table structure conversion and query optimization. However, relational databases also have their advantages, such as support for transactions, data consistency, and more. Therefore, when choosing a database, you need to choose according to specific application scenarios and requirements.
-
Stream is mainly a tool for processing collection data. Stream stream can be used to filter, sort, map, reduce and other operations on collections
Stream API vs collection framework
-
The Stream API focuses on the calculation of multiple data (sorting, searching, filtering, mapping, traversal, etc.), which is CPU-oriented.
-
Storage of data of collection concern, memory-oriented.
-
Stream API is to collections, similar to SQL to data table queries.
Instructions for use
①Stream itself does not store elements.
②Stream will not change the source object. Instead, they return a new Stream holding the result.
③Stream operation is delayed execution. This means they wait until the result is needed to execute it. That is, once the terminating operation is executed, the chain of intermediate operations is executed and results are produced.
④ Once the Stream has executed the termination operation, it can no longer call other intermediate operations or termination operations.
Stream execution process
Step 1: Instantiation of Stream
-
A data source, such as a collection, an array, gets a stream
Step 2: A series of intermediate operations
-
Each processing will return a new Stream holding the result, that is, the method return value of the intermediate operation is still an object of type Stream. Therefore the intermediate operation
It can be an operation chain, which can perform secondary processing on the data of the data source, but it will not be actually executed until the operation is terminated.
Step 3: Execute the termination operation (terminal operation)
The return value type of the method of terminating the operation is no longer Stream, so once the terminating operation is executed, the entire Stream operation is ended. Once the terminating operation is executed, the intermediate operation is executed
The operation chain finally produces the result and ends the Stream.
expand
stream method
In Java 8, a new stream() method is added to collection classes (such as List, Set, etc.), which can return a Stream object. Stream is a new API in Java 8 for operating
For collection data, you can implement functional programming to process collection data.
Default method of List
forEach method
forEach() is a new method in Java 8. It is part of the Stream API and can perform specified operations on each element in the collection. The forEach() method accepts a Lambda expression or method reference as a parameter, and the Lambda expression defines the operation to be performed on each element.
The following uses Lambda and method reference output respectively, the result is the same
List<String> list2 = Arrays.asList("apple", "banana", "orange");
System.out.println("方法引用");
list2.forEach(System.out::println);
System.out.println("Lambda表达式");
list2.forEach(s-> System.out.println(s));
-
The Arrays.asList() method can conveniently convert an array into a List collection
code demo
Employee table Employee
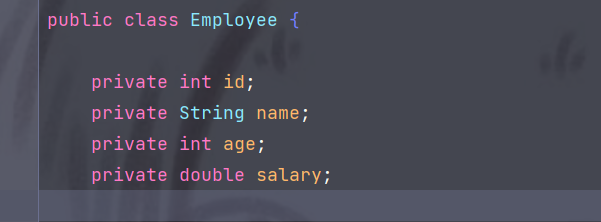
image-20230716222356654
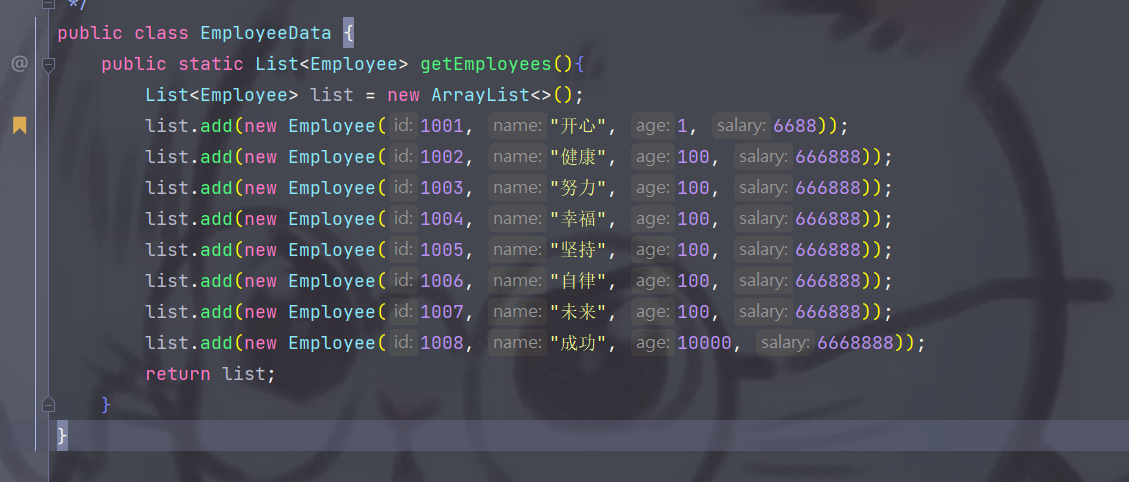
image-20230726011231112
All the methods of Stream have been intercepted for everyone, see the picture below
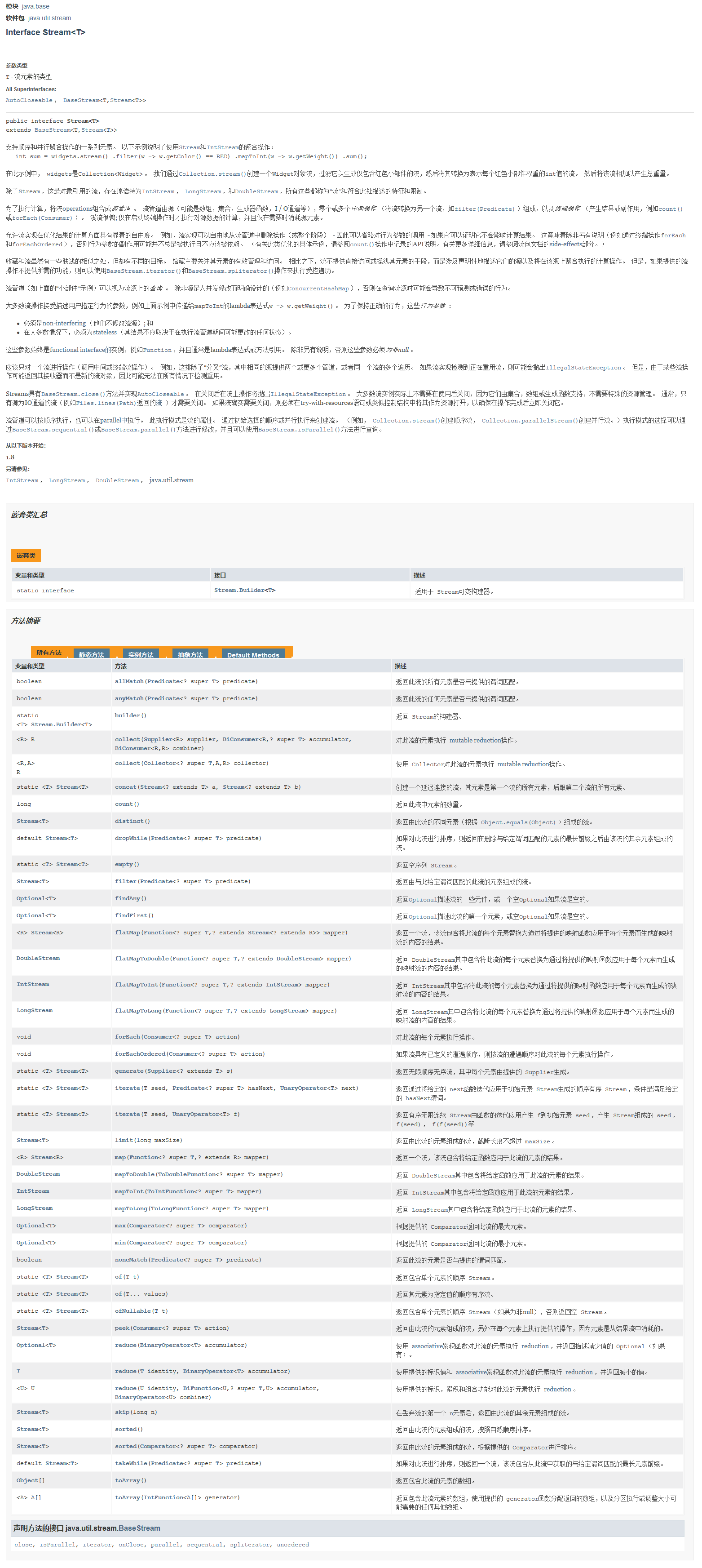
image-20230726004337375
StreamAPITest
public class StreamAPITest {
/**
* 创建 Stream方式一:通过集合
*/
@Test
public void test1(){
List<Employee> list = EmployeeData.getEmployees();
// default Stream<E> stream() : 返回一个顺序流
Stream<Employee> stream = list.stream();
// default Stream<E> parallelStream() : 返回一个并行流
Stream<Employee> stream1 = list.parallelStream();
System.out.println(stream);
System.out.println(stream1);
}
/**
* 创建 Stream方式二:通过数组
*/
@Test
public void test2(){
//调用Arrays类的static <T> Stream<T> stream(T[] array): 返回一个流
Integer[] arr = new Integer[]{1,2,3,4,5};
// 先得到Stream的示例
Stream<Integer> stream = Arrays.stream(arr);
int[] arr1 = new int[]{1,2,3,4,5};
IntStream stream1 = Arrays.stream(arr1);
}
/**
* 创建 Stream方式三:通过Stream的of()
*/
@Test
public void test3(){
Stream<String> stream = Stream.of("AA", "BB", "CC", "SS", "DD");
}
}
StreamAPITest1
public class StreamAPITest01 {
//1-筛选与切片
@Test
public void test1() {
// filter(Predicate p)——接收 Lambda,从流中排除某些元素。
//练习:查询员工表中薪资大于7000的员工信息
List<Employee> list = EmployeeData.getEmployees();
Stream<Employee> stream = list.stream();
// forEach遍历是终止操作
stream.filter(emp -> emp.getSalary() > 7000).forEach(System.out::println);
System.out.println();
// limit(n)——截断流,使其元素不超过给定数量。
//这里报错,因为stream已经执行了终止操作,就不可以再调用其它的中间操作或终止操作了。要重新调用
// stream.limit(2).forEach(System.out::println);
list.stream().filter(emp -> emp.getSalary() > 7000).limit(2).forEach(System.out::println);
System.out.println();
// skip(n) —— 跳过元素,返回一个扔掉了前 n 个元素的流。若流中元素不足 n 个,则返回一个空流。与 limit(n) 互补
list.stream().skip(5).forEach(System.out::println);
System.out.println();
// distinct()——筛选,通过流所生成元素的 hashCode() 和 equals() 去除重复元素
list.add(new Employee(1009, "马斯克", 40, 12500.32));
list.add(new Employee(1009, "马斯克", 40, 12500.32));
list.add(new Employee(1009, "马斯克", 40, 12500.32));
list.add(new Employee(1009, "马斯克", 40, 12500.32));
list.stream().distinct().forEach(System.out::println);
}
//2-映射
@Test
public void test2() {
//map(Function f)——接收一个函数作为参数,将元素转换成其他形式或提取信息,该函数会被应用到每个元素上,并将其映射成一个新的元素。
//练习:转换为大写
List<String> list = Arrays.asList("aa", "bb", "cc", "dd");
//方式1:
list.stream().map(str -> str.toUpperCase()).forEach(System.out::println);
//方式2:
list.stream().map(String :: toUpperCase).forEach(System.out::println);
//练习:获取员工姓名长度大于3的员工。
List<Employee> employees = EmployeeData.getEmployees();
employees.stream().filter(emp -> emp.getName().length() > 3).forEach(System.out::println);
//练习:获取员工姓名长度大于3的员工的姓名。
//方式1:
employees.stream().filter(emp -> emp.getName().length() > 3).map(emp -> emp.getName()).forEach(System.out::println);
//方式2:
employees.stream().map(emp -> emp.getName()).filter(name -> name.length() > 3).forEach(System.out::println);
//方式3:
employees.stream().map(Employee::getName).filter(name -> name.length() > 3).forEach(System.out::println);
}
//3-排序
@Test
public void test3() {
//sorted()——自然排序
Integer[] arr = new Integer[]{345,3,64,3,46,7,3,34,65,68};
String[] arr1 = new String[]{"GG","DD","MM","SS","JJ"};
Arrays.stream(arr).sorted().forEach(System.out::println);
System.out.println(Arrays.toString(arr));//arr原数组并没有因为升序,做调整。
Arrays.stream(arr1).sorted().forEach(System.out::println);
//因为Employee没有实现Comparable接口,所以报错!使用Collections.sort()或者Arrays.sort()方法对一个对象集合进行排序时,需要使用对象的自然排序规则进行比较。而默认情况下,Java并不知道如何比较一个自定义对象的大小,因此需要我们自己定义比较规则。
// List<Employee> list = EmployeeData.getEmployees();
// list.stream().sorted().forEach(System.out::println);
//sorted(Comparator com)——定制排序
List<Employee> list = EmployeeData.getEmployees();
list.stream().sorted((e1,e2) -> e1.getAge() - e2.getAge()).forEach(System.out::println);
//针对于字符串从大大小排列
Arrays.stream(arr1).sorted((s1, s2) -> -s1.compareTo(s2)).forEach(System.out::println);
// Arrays.stream(arr1).sorted(String :: compareTo).forEach(System.out::println);
}
}
precision practice
public class StreamAPITest2 {
@Test
public void test01(){
// boolean allMatch(Predicate<? super T> predicate);
List<Employee> list = EmployeeData.getEmployees();
//是否所有员工可以匹配到age>100
System.out.println(list.stream().allMatch(employee -> employee.getAge() > 100));
//是否存在一个员工age>99
System.out.println(list.stream().anyMatch(employee -> employee.getAge() > 99));
// findFirst()返回第一个元素,获取到的是第一个Optional,再调用get方法才可以获取第一个员工:
// Employee{id=1001, name='开心', age=100, salary=666888.0}
System.out.println(list.stream().findFirst().get());
}
@Test
public void test02(){
// count 返回流中元素的总个数
// 返回流中工资大于1w的员工的总个数
List<Employee> list = EmployeeData.getEmployees();
System.out.println(list.stream().filter(employee -> employee.getSalary()>10000).count());
// max(Comparator c) 返回流中的最大值
// 打算获取最高工资
//先返回最高(最低min)工资的员工
System.out.println(list.stream().max((e1, e2) -> Double.compare(e1.getSalary(), e2.getSalary())));
//Method-1 获取到员工,在获取自身的工资即可
System.out.println(list.stream().max((e1, e2) -> Double.compare(e1.getSalary(), e2.getSalary())).get().getSalary());
//Method-2 先映射工资在调用最高工资 Double.compare是返回一个int,只要返回int就行()--int compare(T o1, T o2);
System.out.println(list.stream().map(employee -> employee.getSalary()).max((s1, s2) -> Double.compare(s1, s2)).get());
// 改为方法引用
System.out.println(list.stream().map(employee -> employee.getSalary()).max(Double::compare).get());
// forEach 内部迭代
list.stream().forEach(System.out::println);
// 针对集合jdk8 增加一个遍历的方法 -- Iterator迭代器、增强for、一般for、ForEach
list.forEach(System.out::println);
}
@Test
public void test03(){
/**
* 归约操作,可以将流中元素反复结合起来,得到一个值。返回T
*/
//T reduce(T identity, BinaryOperator<T> accumulator);
//BinaryOperator 继承 BiFunction , 其中的方法: R apply(T t, U u);
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
// identity 是一个累计函数的恒等值,可以把它理解为种子,在此基础上进行相加,比如10,x1+x2为55,则共65
System.out.println(list.stream().reduce(0, (x1, x2) -> x1 + x2));
// 改为函数式接口
System.out.println(list.stream().reduce(0, (x1, x2) -> Integer.sum(x1,x2)));
System.out.println(list.stream().reduce(0, Integer::sum));
// 获取所有员工工资总和
List<Employee> list1 = EmployeeData.getEmployees();
// 利用reduce将所有员工工资相加
System.out.println(list1.stream().map(emp -> emp.getSalary()).reduce((salary1, salary2) -> Double.sum(salary1, salary2)));
System.out.println(list1.stream().map(emp -> emp.getSalary()).reduce(Double::sum));
}
@Test
public void test04(){
// collect(Collector c) 将流转换为其它形式,接收一个 Collector接口的实现,用于给Stream中元素做汇总的方法
// 练习1:查找工资大于666888的员工,结果返回为一个List或Set
List<Employee> list = EmployeeData.getEmployees();
List<Employee> list1 = list.stream().filter(emp -> emp.getSalary() > 666888).collect(Collectors.toList());
list1.forEach(System.out::println);
System.out.println("------list2------");
// 练习2:按照员工的年龄进行排序,返回到一个新的List中
List<Employee> list2 = list.stream().sorted((e1, e2) -> e1.getAge() - e2.getAge()).collect(Collectors.toList());
list2.forEach(System.out::println);
}
}
Sochi Quotations
-
The world is as simple yet complex and subtle as human beings control ants, and multi-dimensional control three-dimensional