You only have to look once: unified real-time object detection
Joseph Redmon∗, Santosh Divvala∗†, Ross Girshick¶, Ali Farhadi∗†
University of Washington∗, Allen Institute for AI†, Facebook AI Research
Summary
We introduce a new object detection method: YOLO. Previous work on object detection repurposes classifiers to perform detection. Instead, we treat object detection as a regression problem with spatially separated bounding boxes and associated class probabilities. In one evaluation, a single neural network predicts bounding boxes and class probabilities directly from the full image. Since the entire detection channel is a single network, it is straightforward to perform end-to-end optimization on detection performance.
Our unified architecture is very fast. Our base YOLO model processes images in real time at 45 frames per second. A smaller version of this network: Fast YOLO, processes 155 frames per second, which is amazingly fast, while still achieving twice the mAP of other real-time detectors (mAP, where it stands for P (Precision) accuracy rate. AP (Average Precision) single Class label average (the average of the maximum precision in each recall rate), the precision rate, mAP (Mean Average Precision) the average precision rate of all class labels). Compared with the most advanced detection system, YOLO will produce more positioning errors, but it is unlikely to predict false positive in the background (false positive is referred to as FP, which is judged as a positive sample, but in fact it is a negative sample). Finally, YOLO is a common method for learning object detection. When generalizing from natural images to other domains such as artwork, it outperforms other detection methods including DPM and R-CNN.
1. Introduction
Humans glance at an image and instantly know what the objects in the image are, where they are, and how they interact. The human visual system is fast and accurate, allowing us to perform complex tasks, such as driving, with little to no awareness. Fast, accurate object detection algorithms will enable computers to drive cars without specialized sensors, enable assistive devices to communicate real-time scene information to users, and open the door to general-purpose, responsive robotic systems.
Current detection systems repurpose classifiers to perform detection. To detect an object, these systems classify the object and evaluate it at different locations and scales in the test image. Systems like Deformable Part Models (DPM) use a sliding window approach where the classifier is run at evenly spaced locations across the image [10].
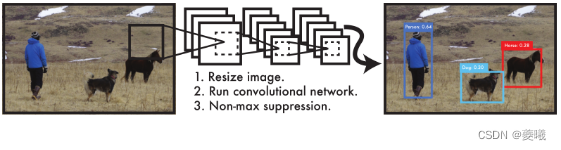
Figure 1: YOLO detection system. Processing images with YOLO is simple and straightforward. Our system (1) resizes the input image to 448×448, (2) runs a single convolutional network on the image, and (3) thresholds the resulting detection based on the confidence of the model.
Some recent approaches such as R-CNN use a region proposal approach that first generates a range of possible bounding boxes and then runs a classifier on these bounding boxes. After classification, duplicate detections are eliminated by post-processing fine bounding boxes, and the boxes are re-scored against other objects in the scene [13]. These complex pipelines are slow and hard to optimize since each part must be trained individually.
We reformulate object detection as a single regression problem, going directly from image pixels to bounding box coordinates and class probabilities. With our system, you can predict the location of an object by looking at the (YOLO) image only once.
YOLO is very simple: see Figure 1. A single convolutional network simultaneously predicts multiple bounding boxes and class probabilities for those boxes. YOLO trains on full images and directly optimizes detection performance. This unified model has several advantages over traditional object detection methods.
First, YOLO is very fast. Since we treat detection as a regression problem, complex channels are not required. We simply run the neural network on new images at test time to predict detections. Our base network runs at 45 frames per second without batching on a Titan X GPU, while the fast version runs at over 150 fps. This means we can process streaming video in real time with less than 25 milliseconds of latency. Furthermore, YOLO achieves more than twice the average accuracy of other real-time systems. See our project webpage for a live demonstration of our system running on a webcam: http://pjreddie.com/yolo/.
Second, YOLO will perform global reasoning on the image when making predictions. Unlike sliding window and proposal-based techniques, YOLO sees the entire image during training and testing, so it implicitly encodes contextual information about classes and their appearance. Fast R-CNN, a top detection method [14], mistook background patches in images for objects because it could not see the larger background. Compared with Fsast R-CNN, YOLO has less than half the background misidentification.
Third, YOLO learns generalizable representations of objects. When it is trained on natural images and tested on artwork, YOLO outperforms top detection methods like DPM and R-CNN by a wide margin. Since YOLO is highly generalizable, it is less likely to crash when applied to new domains or unexpected inputs.
YOLO still lags behind state-of-the-art detection systems in accuracy. While it can quickly identify objects in images, it struggles to pinpoint certain objects, especially small ones. We further investigate these weights in our experiments.
All our training and testing code is open source. Various pretrained models are also available for download.
2. Unified detection
We unify various parts of object detection into a single neural network. Our network uses features from the entire image to predict each bounding box. It also predicts all bounding boxes for all classes of an image simultaneously. This means that our network makes global inferences about the entire image and all objects in the image. The YOLO design enables end-to-end training and real-time speed while maintaining high average accuracy.
Our image input system is divided into an S×S grid. If the center of an object falls into a grid cell, that grid cell is responsible for detecting the object.
Each grid cell predicts B bounding boxes and confidence scores for these boxes. These confidence scores reflect how confident the model is that the bounding box contains the object, and how accurate it thinks the bounding box predictions are. We formally define the confidence level: . If no object exists in that cell, the confidence score should be zero. Otherwise, we want the confidence score to be equal to the intersection-over-union (IOU) between the predicted box and the ground truth.
Each bounding box consists of 5 predictions: x, y, w, h and confidence. The (x,y) coordinates indicate the center of the cuboid relative to the grid cell boundaries. Width and height are predicted relative to the entire image. Finally, the confidence prediction represents the IOU between the predicted box and any ground truth box.
Each grid cell also predicts the C conditional class probability Pr ( Classi | Object ). These probabilities are conditioned on the grid cell containing the object. We only predict a set of class probabilities for each grid cell, regardless of the number of B bounding boxes. At test time, we multiply the conditional class probability relation and the individual box confidence predictions.
This gives us a class-specific confidence score for each bounding box. These scores encode the probability that the class appears in the box and how well the predicted box matches the object.
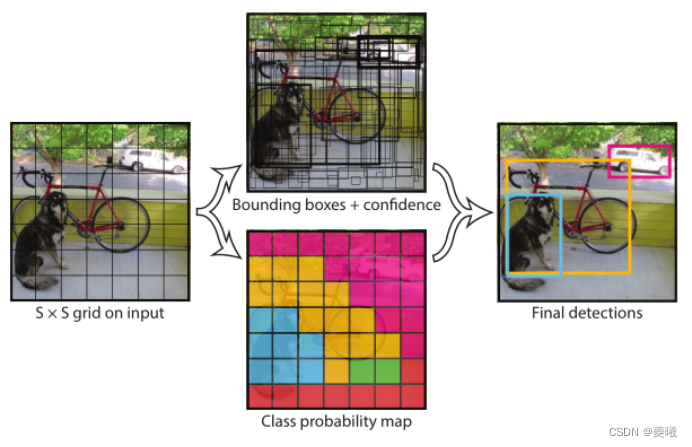
Figure 2: Model. Our system models detection as a regression problem. It divides the image into S×S grids and predicts bounding boxes, confidences for these boxes, and class probabilities for each grid cell. These predictions are encoded as S×S×(B*5+C) tensors.
To evaluate YOLO on PASCAL VOC, we use S=7, B=2. PASCAL VOC has 20 token classes, so C=20. Our final predictions are 7×7×30 tensors.
2.1 Network Design
We implement the model as a convolutional neural network and evaluate it on the PASCAL VOC detection dataset [9]. The network's initial convolutional layers extract features from images, while fully connected layers predict output probabilities and coordinates.
Our network architecture is inspired by the GoogLeNet model for image classification [34]. Our network has 24 convolutional layers followed by two fully connected layers. Different from the inception module used by GoogLeNet, we only use a 1×1 reduction layer followed by a 3×3 co-evolution layer, similar to Lin et al. [22]. The complete network is shown in Figure 3.
We also trained a fast version of YOLO designed to push the boundaries of fast object detection. The neural network used by Fast YOLO has fewer convolutional layers (9 instead of 24) and fewer filters. Except for the size of the network, all training and testing parameters are the same between YOLO and Fast YOLO.
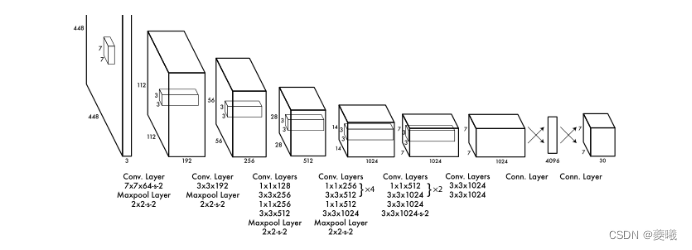
Figure 3: Architecture. Our detection network consists of 24 convolutional layers and 2 fully connected layers. Alternating 1×1 convolutional layers reduce the feature space of previous layers. We pre-train the convolutional layers on the ImageNet classification task at half the resolution (224×224 input images), and then double the detection resolution.
The final output of our network is a 7×7×30 tensor of predictions.
2.2 Training
We pre-train convolutional layers on the ImageNet 1000-class competition dataset [30]. For pre-training, we use the first 20 convolutional layers in Figure 3, followed by average pooling and fully connected layers. We trained the network for about a week and achieved 88% single crop top-5 accuracy on the ImageNet 2012 validation set, comparable to the GoogLeNet model in Caffe Model Zoo [24]. We use Darknet for all training and inference [26].
Then, we apply the model to detection. Ren et al. demonstrated that adding convolutional and concatenated layers to a pretrained network improves performance [29]. Following their example, we add four convolutional layers and two fully connected layers with randomly initialized weights. Detection usually requires fine-grained visual information, so we increase the input resolution of the network from 224×224 to 448×448.
The last layer predicts class probabilities and bounding box coordinates. We normalize the width and height of the bounding box to be between 0 and 1 by the width and height of the image. We parameterize the bounding box X and Y coordinates as offsets from specific grid cell positions, so their bounds are also between 0 and 1.
We use a linear activation function for the last layer and all other layers use the following leak-corrected linear activations:
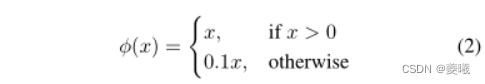
We optimize the sum of squared errors of the model output. We use the sum of squared errors because it's easy to optimize, but it doesn't quite fit our goal of maximizing average precision. It weights the localization error equally with the possibly suboptimal classification error. Also, in each image, many grid cells do not contain any objects. This pushes the "confidence" scores of these cells towards zero, often exceeding the gradient of cells containing objects. This can lead to model instability causing training to drift early.
To address this, we increase the loss for bounding box coordinate prediction and decrease the loss for confidence prediction for boxes that do not contain objects. We do this using two parameters λcoord and λnoobj. We set λcoord=5 and λnoobj=.5.
The sum of squared errors also weights the errors equally in the large and small boxes. Our error metric should reflect that small deviations in large boxes are more important than small deviations in small boxes. To partially address this issue, we predict the square root of the bounding box width and height instead of predicting the width and height directly.
YOLO predicts multiple bounding boxes per grid cell. When training, we only want one bounding box predictor to be responsible for each object. We designate a predictor to be "responsible" to predict an object based on which the prediction has the highest current ground-truth IOU. This leads to specialization among bounding box predictors. Each predictor is better at predicting specific dimensions, aspect ratios, or object categories, improving overall recall.
During training, we optimize the following parts of the loss function:
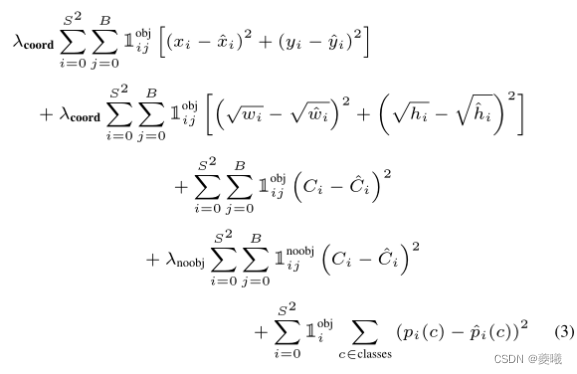
where denotes whether the object is present in cell grid i, denoting that the jth bounding box predictor in grid i is "responsible" for that prediction.
Note that the loss function only penalizes misclassification if there is an object in the grid cell (hence the conditional class probabilities discussed earlier). It also only penalizes bounding box coordinate errors if the predictor is "responsible" for the ground-truth box (i.e., has the highest IOU of any predictor in that grid cell).
We trained the network for approximately 135 epochs on the PASCAL VOC 2007 and 2012 training and validation datasets. When testing in 2012, we also included the VOC 2007 test data for training. Throughout training, we use a batch size of 64, a momentum of 0.9, and a decay of 0.0005.
Our learning rate schedule is as follows: In the first epochs, we slowly increase the learning rate from 10−3 to 10−2. If we start learning with a high learning rate, our model tends to deviate from unstable gradients. We continue to train for 75 epochs with a learning rate of 10−2, then for 30 epochs with a learning rate of 10−30, and finally for 30 epochs with a learning rate of 10−30.
To avoid overfitting, we use dropout and extensive data augmentation. The dropout layer rate is 0.5 after the first connected layer, preventing mutual adaptation between layers [18]. For data augmentation, we introduce 20% of the original image size for random scaling and translation. We also randomly adjusted the exposure and saturation of the image to 1.5 in HSV color space.
2.3 Reasoning
Just like in training, predicting detections on test images requires only one network evaluation. On PASCAL VOC, the network predicts 98 bounding boxes per image, each with a class probability. Unlike classifier-based methods, YOLO is very fast at test time because it requires only one network evaluation.
The grid design enhances spatial diversity in bounding box prediction. Typically, it is clear which grid cell an object belongs to, and the network only predicts one box per object. However, some large objects or objects near multiple cell boundaries can be well localized by multiple cells. Non-maximum suppression can be used to fix these multiple detections. While not as critical to performance as R-CNN or DPM, non-maximum suppression increases mAP by 23%.
2.4 Limitations of YOLO
YOLO imposes strong spatial constraints on bounding box predictions, since each grid cell can only predict two boxes and only have one class. This spatial limitation limits the number of nearby objects our model can predict. Our model struggles with small objects that appear in groups, such as flocks of birds.
Since our model learns to predict bounding boxes from data, it is difficult to generalize to objects with new or unusual aspect ratios or configurations. Our model also uses relatively coarse features to predict bounding boxes because our architecture has multiple downsampling layers from the input image.
Finally, when we train a loss function that approximates detection performance, our loss function handles errors in the same way for small bounding boxes as it does for large ones. Small errors in large boxes are usually benign, but small errors in small boxes have a much greater impact on IOU. Our main source of error is wrong positioning.
3. Comparison with other detection systems
Object detection is a central problem in computer vision. The detection pipeline generally starts by extracting a set of robust features (Haar[25], SIFT[23], HOG[4], convolutional features[6]) from the input image. Then, classifiers [36, 21, 13, 10] or localizers [1, 32] are used to identify objects in the feature space. These classifiers or localizers either operate in a sliding-window fashion over the entire image epoch, or over some subset of regions of the image [35, 15, 39]. We compare the YOLO detection system with several top detection frameworks, highlighting key similarities and differences.
Deformable part models. Deformable part models (DPM) use a sliding window approach for object detection [10]. DPM uses disjoint channels to extract static features, classify regions, predict bounding boxes for high-scoring regions, etc. Our system replaces all these different parts with a single convolutional neural network. The network simultaneously performs feature extraction, bounding box prediction, non-maximum suppression, and contextual reasoning. Instead of static features, the network trains features online and optimizes them for the detection task. Our unified architecture results in faster and more accurate models compared to DPM.
R-CNN. R-CNN and its variants use region proposals instead of sliding windows to find object images. Selective Search [35] generates potential bounding boxes, convolutional network extracts features, support vector machine (SVM) predicts box scoring, linear model adjusts bounding boxes, and non-maximum suppression eliminates duplicate detection. Each stage of this complex pipeline must be fine-tuned independently, and as a result the system detection speed is very slow, requiring more than 40 seconds per image at test time [14].
YOLO shares some similarities with R-CNN. Each grid cell proposes potential bounding boxes and uses convolutional features to score these boxes. However, our system imposes spatial constraints on the grid cell scheme, which helps reduce multiple detections of the same object. Our system also proposes far fewer bounding boxes, only 98 per image, compared to about 2000 for Selective Search. Finally, our system combines these individual components into a single, jointly optimized model.
Other quick detectors. Fast R-CNN and Faster R-CNN focus on speeding up the detection speed of the R-CNN framework by sharing computation and using neural network proposals instead of selective search [14][28]. Although they have improved in speed and accuracy compared to R-CNN, their real-time performance is still not satisfactory.
Much research work has focused on accelerating DPM channels [31][38][5]. They speed up HOG calculations, use cascades, and push the calculations to the GPU. However, only 30Hz DPM [31] can run in real time.
Instead of trying to optimize individual components of a large detection pipeline, YOLO discards the pipeline entirely and is designed to be fast. Single-class detectors such as faces or people can be highly optimized because the variation they have to deal with is much smaller [37]. YOLO is a general-purpose detector that can detect multiple objects simultaneously.
Deep MultiBox. Unlike R-CNN, Szegedy et al. train a convolutional neural network to predict regions of interest (RoI) [8] instead of using selective search. MultiBox can also perform single-object detection by replacing confidence predictions with single-class predictions. However, MultiBox cannot perform general object detection and is still only a part of a larger detection pipeline, requiring further image patch classification. Both YOLO and MultiBox use convolutional networks to predict bounding boxes in images, but YOLO is a complete detection system.
Overfitting (OverFeat). Sermanet et al. train a convolutional neural network for localization and tune this localizer for detection [32]. Overfitting effectively performs sliding window detection, but it is still a disjoint system. Overfitting optimizes localization, not detection performance. Like DPM, locators only look at local information when making predictions. OverFeat cannot reason about the global context and thus requires extensive post-processing to produce consistent detections.
MultiGrasp. Our work is similar in design to the grasp detection work of Redmon et al. [27]. Our mesh bounding box prediction method is based on the MultiGrasp system for regression grasping. However, grasp detection is much simpler than object detection. MultiGrass only needs to predict one graspable region for an image containing one object. It does not need to estimate the size, position or boundary of the object, nor does it need to predict the category of the object, it only needs to find a suitable area for grasping. YOLO predicts bounding boxes and class probabilities for multiple objects of multiple classes in an image.
4. Experiment
First, we compare YOLO to other real-time detection systems on PASCAL VOC 2007. To understand the differences between YOLO and R-CNN variants, we study the errors of YOLO and Fast R-CNN on VOC 2007, one of the highest performing versions of R-CNN [14]. Based on different error patterns, we show that YOLO can be used to restore Fast R-CNN detections and reduce errors from background false positives, leading to significant performance improvements. We also present results on VOC 2012 and compare mAP with current state-of-the-art methods. Finally, we show that YOLO generalizes to new domains better than other detectors on two artwork datasets.
4.1 Real-time comparison with other systems
Much research work in object detection has focused on fast implementation of standard detection pipelines. [5][38][31][14][17][28] However, only Sadeghi et al. actually produced a detection system that runs in real time (30 frames per second or better) [31]. We compared YOLO to their implementation of DPM on a GPU, running at 30Hz or 100Hz. While other efforts have not reached real-time milestones, we also compare their relative mAP and speed to examine the accuracy-performance trade-off available in object detection systems.
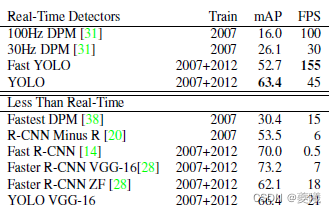
Table 1: Real-time systems on PASCAL VOC 2007. The performance and speed of fast detectors are compared. Fast YOLO is the fastest detector on record for PASCAL VOC detection and is still twice as fast as other real-time detectors. YOLO is 10mAP larger than the Fast version, but the speed is still much higher than real-time.
Fast YOLO is the fastest object detection method on PASCAL; to the best of our knowledge, it is the fastest object detector in existence. 52.7% mAP, which is more than double the accuracy of previous real-time detection work. YOLO pushes mAP to 63.4%, while still maintaining real-time performance.
We also train YOLO using VGG-16. This model is more accurate, but also much slower than YOLO. It is useful compared to other detection systems that rely on VGG-16, but since it is slower than real-time systems, the remainder of this paper will focus on our faster model.
Fastest DPM effectively speeds up DPM without sacrificing too much mAP, but it still misses 2x real-time performance [38]. Compared with neural network methods, the detection accuracy of DPM is relatively low, which also limits its application.
R-CNN minus R replaces selective search with a static bounding box scheme [20].
Although it is faster than R-CNN, it still lacks real-time performance and its accuracy suffers greatly due to lack of good region proposals.
Fast R-CNN speeds up the classification stage of R-CNN, but it still relies on selective search and takes about 2 seconds per image to generate bounding box candidates. So it has a high mAP, but at 0.5fps it's far from real-time.
The recent Faster R-CNN replaces selective search with a neural network and proposes bounding boxes, similar to that of Szegedy et al. [8]. Their most accurate model achieved 7 fps in our tests, while smaller, accurate The lower model hit 18 fps. The VGG-16 version of Faster R-CNN is 10 mAP higher than YOLO, but also 6 times slower. ZeilerFergus' Faster R-CNN is only 2 fps. 5x slower than YOLO, but also less accurate.
4.2 VOC 2007 error analysis
To further investigate the differences between YOLO and state-of-the-art detectors, we looked at a detailed breakdown of the 2007 VOC test results. We compared YOLO with Fast RCNN because Fast R-CNN is one of the highest performing detectors on PASCAL and its detection data is publicly available.
We use the method and tools of Hoiem et al. [19], where at test time for each class we look at the top N predictions for that class. Each prediction is either correct or classified according to the type of error:
- Correct: correct category and IOU > .5
- Localization: correct category, .1<IOU<.5
- Similar: Classification similar, IOU > .1
- Other: Wrong category, IOU>.1
- Background: IOU < .1 for any object
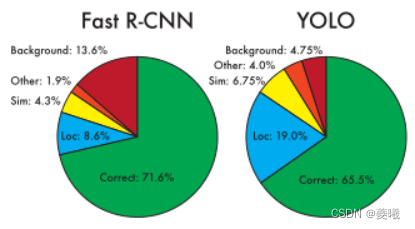
Figure 4: Error Analysis: Fast R-CNN vs. YOLO These graphs show the percentage of localization and background errors in the top N detections for different classes (N = # objects in that class) .
Figure 4 shows the breakdown of each error type averaged across all 20 classes.
YOLO locates the target as correctly as possible. Localization errors account for a larger proportion of YOLO's errors than all other sources combined. Fast R-CNN has much fewer localization errors, but much more background errors. 13.6% of the top detections are misidentifications that do not contain any objects. Fast R-CNN is almost 3 times more likely to predict background detection than YOLO.
4.3 Combine Fast R-CNN and YOLO
YOLO makes much fewer background errors than Fast R-CNN. By using YOLO to eliminate the background detection of Fast R-CNN, we get a significant performance boost. For each bounding box predicted by R-CNN, we check whether YOLO predicted a similar box. If so, we improve the prediction based on the probability predicted by YOLO and the overlap between the two boxes.
On the VOC 2007 test set, the mAP of the best Fast R-CNN model is 71.8%. When combined with YOLO, its mAP increased by 3.2% to 75.0%. We also tried combining the top Fast R-CNN model with several other versions of Fast R-CNN. These combinations produced small increases in mAP between .3 and .6%, as detailed in Table 2.
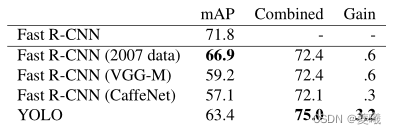
Table 2: VOC model combination tests in 2007. We study the effect of combining various models with the best version of Fast R-CNN. Other versions of Fast R-CNN provide only a small benefit, while YOLO provides a significant performance boost.
The improvement brought by YOLO is not just a by-product of model integration, because there is little benefit in combining different versions of Fast R-CNN. On the contrary, it is precisely because YOLO makes all kinds of mistakes at test time that it improves the performance of Fast R-CNN so effectively.
Unfortunately, this combination doesn't benefit from the speed of YOLO because we run each model separately and then combine the results. However, since YOLO is so fast, it does not add any significant computation time compared to Fast R-CNN.
4.4 VOC 2012 Results
In the VOC test in 2012, YOLO achieved a mAP of 57.9%. This is lower than the current state of the art and closer to the original R-CNN using VGG-16, see Table 3. Compared to the closest competitor, our system struggles with small objects. On categories like bottle, sheep and TV/monitor, YOLO scores 8-10% lower than R-CNN or Feature Edit. However, on other categories, such as cat and train YOLO, the performance is higher.
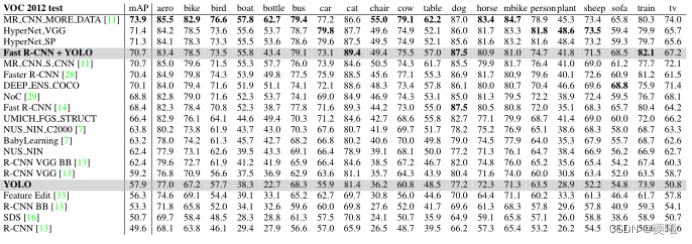
Table 3: PASCALVOC 2012 leaderboard. YOLO was compared to the fullcomp4 (external data allowed) public leaderboard as of November 6, 2015. The average precision of various detection methods and the average precision per class are shown. YOLO is the only real-time detector. Fast R-CNN YOLO is the fourth highest scoring method with a score of 2.3% over Faster R-CNN.
4.5 Brief: People Detection in Artwork
Academic datasets for object detection draw training and test data from the same distribution. In real applications, it is difficult to predict all possible use cases, and the test data may be different from what the system has seen before [3]. We compare YOLO to other detection systems on the Picasso dataset [12] and the People Art dataset [3], which are used to test person detection on artwork.
Figure 5 shows the comparative performance between YOLO and other detection methods. As a reference, we present the VOC 2007 detection AP onPerson, where all models are trained only on VOC 2007 data. For Picasso, models were trained on VOC 2012, while for character art, models were trained on VOC 2010.
R-CNN has a high AP on VOC in 2007. However, when R-CNN is applied to artwork, it drops significantly. R-CNN uses a selective search bounding box scheme that is tuned for natural images. The classifier step in R-CNN only sees small regions and requires good proposals.
DPM maintains its AP well when applied to artwork. Previous work theorized that DPM performs well because it has a strong spatial model of the shape and layout of objects. Although the performance of DPM is not as good as that of R-CNN, it starts from a lower AP.
YOLO has very good performance on VOC 2007, and its AP degrades less than other methods when used for artwork. Like DPM, YOLO models the size and shape of objects, the relationships between objects, and where objects typically appear. Artwork and natural images are very different at the pixel level, but they are similar in terms of object size and shape, so YOLO can still predict good bounding boxes and detections.
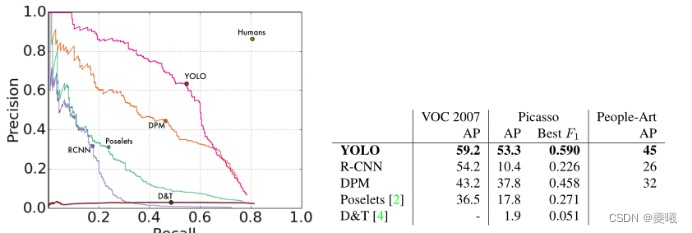
(a) Precision-recall curve for Picasso dataset
(b) Quantitative results for VOC 2007, Picasso and Character Art datasets. The Picasso dataset is evaluated based on AP and Best F1 scores.
5. Real-time detection in the field
YOLO is a fast and accurate object detector ideal for computer vision applications. We connect YOLO to a webcam and verify that it maintains real-time performance, including the time to acquire images from the camera and display detection results.

Figure 6: Qualitative results. YOLO operates on samples of artwork and natural images from the web. While it does think a person is an airplane, it's mostly accurate.
The resulting system is interactive and engaging. While YOLO processes images alone, when connected to a webcam it functions like a tracking system, detecting objects as they move and change in appearance. A demo and source code of the system is available on our project website: http://pjreddie.com/yolo/.
6 Conclusion
We introduce YOLO, a unified model for object detection. Our model is simple in construction and can be trained directly on full images. Unlike classifier-based methods, YOLO is trained based on a loss function that directly corresponds to detection performance, and the entire model is trained synchronously.
Fast YOLO is the fastest general-purpose object detector in the literature, and YOLO promotes the development of real-time object detection technology. YOLO also generalizes well to new domains, making it ideal for applications that rely on fast, robust object detection.
Acknowledgments: This work was supported in part by ONR N00014-13-1-0720, NSF IIS-1338054, and an Allen Distinguished Investigator Award.
references
[1]M. B. Blaschko and C. H. Lampert. Learning to localize ob-jects with structured output regression. InComputer Vision–ECCV 2008, pages 2–15. Springer, 2008.4
[2]L. Bourdev and J. Malik. Poselets: Body part detectorstrained using 3d human pose annotations. InInternationalConference on Computer Vision (ICCV), 2009.8
[3]H. Cai, Q. Wu, T. Corradi, and P . Hall. The cross-depiction problem: Computer vision algorithms for recognising objects in artwork and in photographs.arXiv preprint arXiv:1505.00110, 2015.7
[4]N. Dalal and B. Triggs. Histograms of oriented gradients for human detection. InComputer Vision and Pattern Recognition, 2005. CVPR 2005. IEEE Computer Society Conference on, volume 1, pages 886–893. IEEE, 2005.4,8
[5]T. Dean, M. Ruzon, M. Segal, J. Shlens, S. Vijaya narasimhan, J. Yagnik, et al. Fast, accurate detection of 100,000 object classes on a single machine. In Computer Vision and Pattern Recognition (CVPR), 2013 IEEE Conference on, pages 1814–1821. IEEE, 2013.5
[6]J. Donahue, Y . Jia, O. Vinyals, J. Hoffman, N. Zhang, E. T zeng, and T. Darrell. Decaf: A deep convolutional activation feature for generic visual recognition.arXiv preprint arXiv:1310.1531, 2013.4
[7]J. Dong, Q. Chen, S. Yan, and A. Y uille. Towards unified object detection and semantic segmentation. InComputer Vision–ECCV 2014, pages 299–314. Springer, 2014.7
[8]D. Erhan, C. Szegedy, A. Toshev, and D. Anguelov. Scalable object detection using deep neural networks. InComputer Vision and Pattern Recognition (CVPR), 2014 IEEE Conference on, pages 2155–2162. IEEE, 2014.5,6
[9]M. Everingham, S. M. A. Eslami, L. V an Gool, C. K. I. Williams, J. Winn, and A. Zisserman. The pascal visual object classes challenge: A retrospective.International Journal of Computer Vision, 111(1):98–136, Jan. 2015.2
[10]P . F. Felzenszwalb, R. B. Girshick, D. McAllester, and D. Ramanan. Object detection with discriminatively trained part based models.IEEE Transactions on Pattern Analysis and Machine Intelligence, 32(9):1627–1645, 2010.1,4
[11]S. Gidaris and N. Komodakis. Object detection via a multiregion & semantic segmentation-aware CNN model.CoRR, abs/1505.01749, 2015.7
[12]S. Ginosar, D. Haas, T. Brown, and J. Malik. Detecting people in cubist art. In Computer Vision-ECCV 2014 Workshops, pages 101–116. Springer, 2014.7
[13]R. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. InComputer Vision and Pattern Recognition (CVPR), 2014 IEEE Conference on, pages 580–587. IEEE,2014.1,4,7
[14]R. B. Girshick. Fast R-CNN.CoRR, abs/1504.08083, 2015.2,5,6,7
[15]S. Gould, T. Gao, and D. Koller. Region-based segmentation and object detection. In Advances in neural information processing systems, pages 655–663, 2009.4
[16]B. Hariharan, P . Arbeláez, R. Girshick, and J. Malik. Simultaneous detection and segmentation. InComputer Vision ECCV 2014, pages 297–312. Springer, 2014.7
[17]K. He, X. Zhang, S. Ren, and J. Sun. Spatial pyramid pooling in deep convolutional networks for visual recognition.arXiv preprint arXiv:1406.4729, 2014.5
[18]G. E. Hinton, N. Srivastava, A. Krizhevsky, I. Sutskever, and R. R. Salakhutdinov. Improving neural networks by preventing co-adaptation of feature detectors.arXiv preprint arXiv:1207.0580, 2012.4
[19]D. Hoiem, Y . Chodpathumwan, and Q. Dai. Diagnosing error in object detectors. InComputer Vision–ECCV 2012, pages 340–353. Springer, 2012.6
[20]K. Lenc and A. V edaldi. R-cnn minus r.arXiv preprint arXiv:1506.06981, 2015.5,6
[21]R. Lienhart and J. Maydt. An extended set of haar-like features for rapid object detection. InImage Processing. 2002. Proceedings. 2002 International Conference on, volume 1, pages I–900. IEEE, 2002.4
[22]M. Lin, Q. Chen, and S. Yan. Network in network.CoRR, abs/1312.4400, 2013.2
[23]D. G. Lowe. Object recognition from local scale-invariant features. InComputer vision, 1999. The proceedings of the seventh IEEE international conference on, volume 2, pages 1150–1157. Ieee, 1999.4
[24]D. Mishkin. Models accuracy on imagenet 2012 val.https://github.com/BVLC/caffe/wiki/Models-accuracy-on-ImageNet-2012-val. Accessed: 2015-10-2.3
[25]C. P . Papageorgiou, M. Oren, and T. Poggio. A general framework for object detection. InComputer vision, 1998. sixth international conference on, pages 555–562. IEEE, 1998.4
[26]J. Redmon. Darknet: Open source neural networks in c.http://pjreddie.com/darknet/, 2013–2016.3
[27]J. Redmon and A. Angelova. Real-time grasp detection using convolutional neural networks.CoRR, abs/1412.3128, 2014.5
[28]S. Ren, K. He, R. Girshick, and J. Sun. Faster r-cnn: Towards real-time object detection with region proposal networks.arXiv preprint arXiv:1506.01497, 2015.5,6,7
[29]S. Ren, K. He, R. B. Girshick, X. Zhang, and J. Sun. Object detection networks on convolutional feature maps.CoRR, abs/1504.06066, 2015.3,7
[30]O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, A. C. Berg, and L. Fei-Fei. ImageNet Large Scale Visual Recognition Challenge.International Journal of Computer Vision (IJCV), 2015.3
[31]M. A. Sadeghi and D. Forsyth. 30hz object detection with dpm v5. InComputer Vision–ECCV 2014, pages 65–79. Springer, 2014.5,6
[32]P . Sermanet, D. Eigen, X. Zhang, M. Mathieu, R. Fergus, and Y . LeCun. Overfeat:Integrated recognition, localization and detection using convolutional networks.CoRR, abs/1312.6229, 2013.4,5
[33]Z. Shen and X. Xue. Do more dropouts in pool5 feature maps for better object detection.arXiv preprint arXiv:1409.6911,2014.7
[34]C. Szegedy, W. Liu, Y . Jia, P . Sermanet, S. Reed, D. Anguelov, D. Erhan, V . V anhoucke, and A. Rabinovich. Going deeper with convolutions.CoRR, abs/1409.4842,2014.2
[35]J. R. Uijlings, K. E. van de Sande, T. Gevers, and A. W. Smeulders. Selective search for object recognition.International journal of computer vision, 104(2):154–171, 2013.4
[36]P . Viola and M. Jones. Robust real-time object detection. International Journal of Computer Vision, 4:34–47, 2001.4
[37]P . Viola and M. J. Jones. Robust real-time face detection. International journal of computer vision, 57(2):137–154, 2004.5
[38]J. Yan, Z. Lei, L. Wen, and S. Z. Li. The fastest deformable part model for object detection. InComputer Vision and Pattern Recognition (CVPR), 2014 IEEE Conference on, pages 2497–2504. IEEE, 2014.5,6
[39]C. L. Zitnick and P . Dollár. Edge boxes: Locating object proposals from edges. InComputer Vision–ECCV 2014, pages 391–405. Springer, 2014.4
Original translation: You Only Look Once: Unified, Real-Time Object Detection
<!-- >