Table of contents
A brief introduction to the sequence table:
The difference between the symbols "" and <> in the header file:
Sequence table function description:
Function declaration in header file (Contiguous.h):
The specific implementation of the functions in the source file (Contiguous.cpp):
Initialization function (Init_Sqlist):
Determine whether the sequence table is an empty function (IsEmpty):
Function to determine whether the sequence table is full (IsFull):
Head insertion function (Insert_head):
Tail insertion function (Insert_tail):
Insert function by position (Insert_pos):
Head delete function (Delete_head):
Tail delete function (Delete_tail):
Delete function by position (Delete_pos):
Delete function by value (Delete_val):
Clear sequence table function (Clear):
Destroy sequence table function (Destroy):
Print sequence table function (Show):
Test the implemented functions in the test file (Test.cpp):
Define a head sequence table in the Test file and initialize it:
Fill the sequence table with 100 elements after initialization:
Test header insertion function and expansion function (Insert_gead):
Test tail insertion function (Insert_tail):
Test the interpolation function by position (Insert_pos):
Test head delete function (Delete_Head):
Test the tail delete function (Delete_tail):
Test the delete function by position (Delete_pos):
Test the delete function by value (Delete_val):
Test the search function (Search):
Test the clear function (Clear):
Test the destruction function (Destroy):
introduction:
In the first article of the previous data structure, the basic concepts in the data structure and the related concepts of time complexity were introduced. I have a basic understanding of the data structure. A few days ago, I systematically learned the sequence table. The table was manually typed from scratch, and I also carefully wrote the comments of almost every function and statement in the sequence table in the code. This article learns and summarizes the knowledge of the sequence table.
Data structure learning directory:
Data Structure Series Learning (1) - An Introduction to Data Structure
study:
A brief introduction to the sequence table:
The most convenient and simple way to store a linear table (number table with linear structure) inside the computer is to store the entire linear table with a group of continuous address memory units. This storage structure is called sequential storage structure. The linear table under this storage structure is called a sequential table.
A sequence table includes these characteristics:
There is a unique table name to identify the sequential table;
The memory unit is stored continuously, that is to say, a sequential table must occupy a continuous memory space;
The data is stored in order, and there is a sequence relationship between elements;
Defining a sequence table is to open up a continuous storage space in the memory. At the same time, the sequence table we define should also realize the four functions of adding, deleting, checking and modifying.
Relationships between files:
In the programming process, the order of file compilation is generally from top to bottom. If the function we write is before the main function, we can call it directly in the main function, but if we write the function after the main function, when When we continue to call the function in the main function, the program will report an error. Here we give a simple example.
For example, I define an Add function here, but I write it after the main function:

The program error shows that the undefined keyword Add is used. If we want to eliminate this error at this time, the method is to declare the function before the main function and add the statement:
int Add(int a,int b);Note that there must be a semicolon after it!
In the file, the function declaration is also required, and the function declaration and the realization of the function function are respectively completed in different files. Two file forms are introduced here, namely: files with .h and .cpp suffixes:
The form of the .h file is called a header file. When we implement a program with more complex functions, we can write all the function declarations in the .h file, and design the structure, constant variables and macros in the file. constant definition;
Then we implement the specific functions in the cpp file, and refer to the h file in the form of a header file at the beginning, so that a combination is called an engineering project in the compiler. For example, we The sequence table that will be realized next.
The difference between the symbols "" and <> in the header file:
Note that here we must distinguish the difference between "" and <> when referencing header files.
But if we write directly like this: #include<Contiguous_List.h>, an error will be reported. The reason is that when using the <> symbol, the compiler will directly search for the header file in the system variable path, such as the front of the program we usually write There is #include<stdio.h> the standard input and output header file, and the Contiguous_List.h file is our custom header file, which is not included in the system variable. At this time, we need to use the "" symbol to include the file name go in:
#include"Contiguous.h"In this way, the writing program will not report an error, but we can actually use the "" symbol when citing the header file of C itself, which involves a sequence issue:
The <> symbol is only used to find header files directly in the system variable path;
The "" symbol can be used to search both user-defined header files and header files in the system variable path, but in the search order, the user project path is searched first, and then the system variable path is searched.
So when we add #include "stdio.h" after referencing the user-defined header file above, no error will be reported.
Sequence table function description:
We should first be clear about the functions that a complete sequence table should have:
Operation function (fuction):
Initialization function (Init_Sqlist)
Clear function (Clear)
Destroy function (Destroy)
Expansion function (Inc)
Print function (Show)
Insert function (Insert):
Head insertion function (Insert_head)
Tail insert function (Insert_tail)
Insert function at specified position (Insert_pos)
Delete function (Delete):
Head delete function (Delete_head)
Tail delete function (Delete_tail)
Delete function at specified position (Delete_pos)
Specify value delete function (Delete_val)
Judgment function (Is):
Function to judge whether the sequence table is full (Is_Empty)
Function to determine whether the sequence table is empty (Is_Full)
Function declaration in header file (Contiguous.h):
Before designing the structure, we must first define the initial length of the sequence table:
#define LIST_INIT_SIZE 100//顺序表的初始长度First, we have to define a pointer variable conforming to the element type of the sequence table to store the base address of the storage space of the sequence table;
The current length of the sequence table;
The current total capacity of the sequence table;
We use Elemtype to redefine the parameters of type int, use length to represent the current length of the sequence table, and listsize to represent the current total capacity of the sequence table, the structure can be represented as follows:
typedef int Elem_type;//对int类型起一个别名
typedef struct Sqlist
{
Elem_type * elem;//存储空间基址(用来接收malloc返回在堆上申请的连续空间块开辟)
int length;//当前有效长度
int listsize;//当前总空间大小
}Sqlist,*PSqlist;//结构体末尾的重命名相当于后面这两个语句:
//typedef struct Sqlist Sqlist;
//typedef struct Sqlist* PSqlist;All function declarations in the header file:
void Init_Sqlist(struct Sqlist* sq);//初始化
bool Insert_head(struct Sqlist* sq,Elem_type val);//头插(插入需要判满,自然,删除也需要判空)
bool Insert_tail(struct Sqlist* sq,Elem_type val);//尾插
bool Insert_pos(struct Sqlist* sq,int pos,Elem_type val);//按位置插
bool Delete_head(struct Sqlist* sq);//头删
bool Delete_tail(struct Sqlist* sq);//尾删
bool Delete_pos(struct Sqlist* sq,int pos);//按位置删
bool Delete_val(struct Sqlist* sq,Elem_type val);//按值删(找这个值在顺序表中第一次出现的位置,然后删除它)
bool Is_Empty(struct Sqlist* sq);//判空
bool Is_Full(struct Sqlist* sq);//判满
void Inc(struct Sqlist* sq);//扩容函数
int Search(struct Sqlist* sq,Elem_type val);//查找(找这个值在顺序表中第一次出现的位置)
void Clear(struct Sqlist* sq);//清空(将数据晴空,认为没有有效值)
void Destroy(struct Sqlist* sq);//销毁(将数据存储空间都释放掉)
void Show(struct Sqlist* sq);//打印The specific implementation of the functions in the source file (Contiguous.cpp):
Initialization function (Init_Sqlist):
(1) Allocate a predefined size storage area LIST_INIT_SIZE for the linear table as required, which is the maximum capacity of the sequential table. If the storage allocation fails, an error message will be given.
(2) Set the initial length of the linear table to 0
(3) Set the current storage capacity of the linear table to the maximum capacity of the sequential table
code:
void Init_Sqlist(struct Sqlist* sq)//初始化
{
sq->elem = (Elem_type*)malloc(LIST_INIT_SIZE * sizeof(int));
assert(sq->elem != NULL);//安全性判断
sq->length = 0;//将顺序表初始长度设为0
sq->listsize = LIST_INIT_SIZE;//将顺序表初始总容量设置为前面的宏定义
}Determine whether the sequence table is an empty function (IsEmpty):
This function is easy to understand. When the length of the sequence table is 0, the sequence table is naturally an empty sequence table.
code:
bool Is_Empty(struct Sqlist* sq)//判空
{
//1 安全性处理
assert(sq != NULL);
//2 顺序表的长度为0时,判断顺序表为空
return sq->length == 0;
}Function to determine whether the sequence table is full (IsFull):
Similarly, when the length of the sequence table is equal to the total capacity of the sequence table, the sequence table is in a full state.
code:
bool Is_Full(struct Sqlist* sq)//判满
{
//1 安全性处理
assert(sq != NULL);
//2 当顺序表的长度等于顺序表的总容量时判为满
return sq->length == sq->listsize;
}Find function (Search):
This function is actually a sequential search in a broad sense. It traverses backwards from the first element in the sequence table, returns the subscript of the element if it is found, and returns -1 directly if it cannot find it.
code:
int Search(struct Sqlist* sq,Elem_type val)//查找(找这个值在顺序表中第一次出现的位置)
{
//1 安全性处理
assert(sq != NULL);
//2 顺序查找,找到了返回下标,找不到了直接返回-1
for(int i = 0;i < sq->length;i++){
if(val == sq->elem[i]){
return i;
}
}
return -1;
}Expansion function (Inc):
The expansion function needs to use the realloc function in the <malloc.h> header file. When the sequence table is full and we need to add elements to the sequence table, we need to perform the expansion operation and name a sq->elem to store The new memory base address of the space after the expansion of the realloc function, the default expansion is 2 times, and the storage capacity of the sequence table * 2.
code:
void Inc(struct Sqlist* sq)//扩容函数
{
//1 安全性处理
assert(sq != NULL);
//2 使用sq->elem保存realloc函数扩容后的新内存基址
sq->elem = (Elem_type*)realloc(sq->elem,(sq->listsize*sizeof(int))* 2);
//3 安全性处理
assert(sq->elem != NULL);
//4 sq->length并不需要改变,需要改变的是顺序表总的长度
sq->listsize *= 2;
}Head insertion function (Insert_head):
When we execute the head insertion function, the first thing to be clear is that there will be two situations (Opt represents two situations):
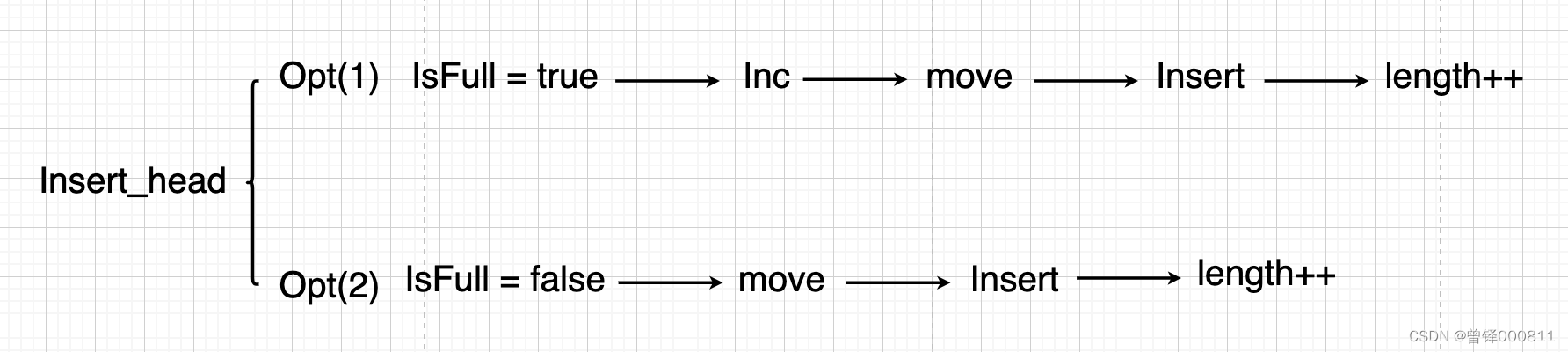
First of all, we need to perform the full operation. If the sequence table is full, we need to perform the expansion operation. After the expansion operation is completed, all elements will be migrated by one unit (note that starting from the last element, if starting from the first start with one element, then the storage order and address will be destroyed), and then perform the head insertion operation; if the sequence table is not full, we directly migrate all elements backward by one unit, and then perform the insertion operation.
code:
bool Insert_head(struct Sqlist* sq,Elem_type val)//头插
{
//1安全性处理
assert(sq != NULL);
//2判满操作
if(Is_Full(sq)){
Inc(sq);
}
//3向后挪动元素(从尾部向前进行移动)
for(int i = sq->length - 1;i >= 0;i--){
sq->elem[i + 1] = sq->elem[i];
}
//4插入值
sq->elem[0] = val;
//5length+1
sq->length++;
return true;
}Tail insertion function (Insert_tail):
Different from the head insertion function, the execution of the tail insertion function does not require the migration of elements, it only needs to insert directly behind the sequence table, so the time complexity of this function is O(1), as follows flow chart:
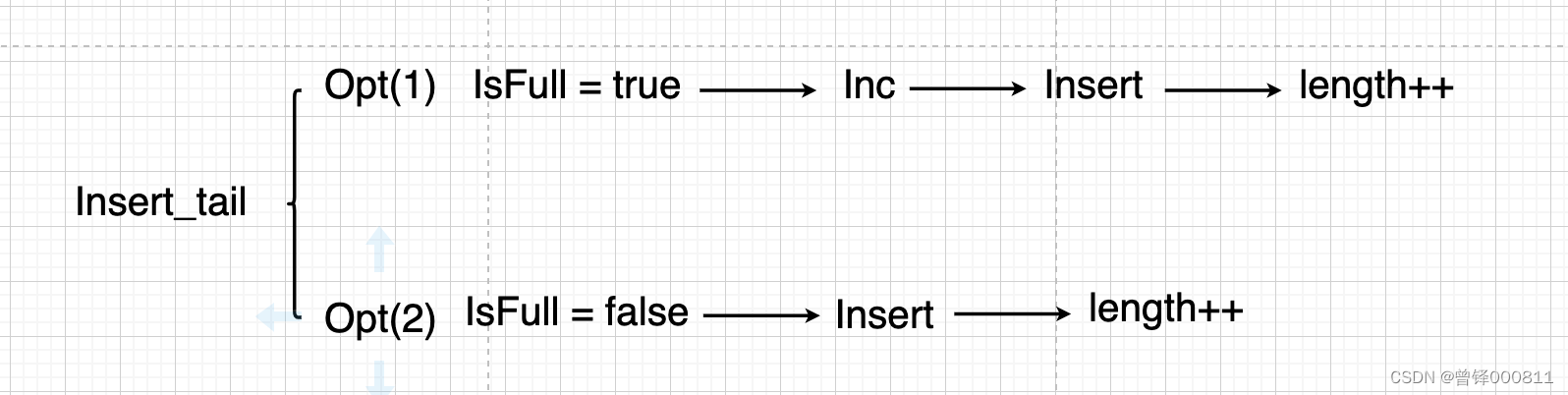
Same as the head insertion function, it needs to be judged to be full. If the judgment is full, execute the expansion function, and then perform the tail insertion operation after the expansion function; if the judgment is false, directly perform the insertion operation.
code:
bool Insert_tail(struct Sqlist* sq,Elem_type val)//尾插
{
//尾插并不需要挪动元素,如果满了就扩容,再在尾部进行添加,如果没满直接在后面插就行
//1安全性处理
assert(sq != NULL);
//判满操作
if(Is_Full(sq)){
Inc(sq);
}
sq->elem[sq->length] = val;
//length+1
sq->length++;
return true;
}Insert function by position (Insert_pos):
When executing the insert function by position, two situations will also occur, corresponding to the header insert function. If the sequence table is full, the capacity expansion operation will be performed. After the capacity expansion is completed, the elements will be uniformly migrated backward by one unit from the specified position (subscript), and then Then insert the element at the specified position (subscript); if the sequence table is not full, perform the migration operation directly and insert the element at the specified position. The following is the flow chart:

code:
bool Insert_pos(struct Sqlist* sq,int pos,Elem_type val)//按位置插
{
//默认当pos == 0时为头插,所以当pos == length的时候也就是尾插了
//1安全性处理
assert(sq != NULL);
//2判满
if(Is_Full(sq)){
Inc(sq);
}
//3移动元素位置
for(int i = sq->length;i >= pos;i--){
sq->elem[i + 1] = sq->elem[i];
}
//4将值放进去
sq->elem[pos] = val;
//5length+1
sq->length++;
return true;
}Head delete function (Delete_head):
Insertion needs to be judged full, and deletion needs to be judged empty. If a sequence table itself is empty, then naturally there will be no delete operation. Therefore, the head deletion function will also generate two cases, namely, the case where the sequence table is empty and the case that the sequence table is not empty. The following is the flow chart:
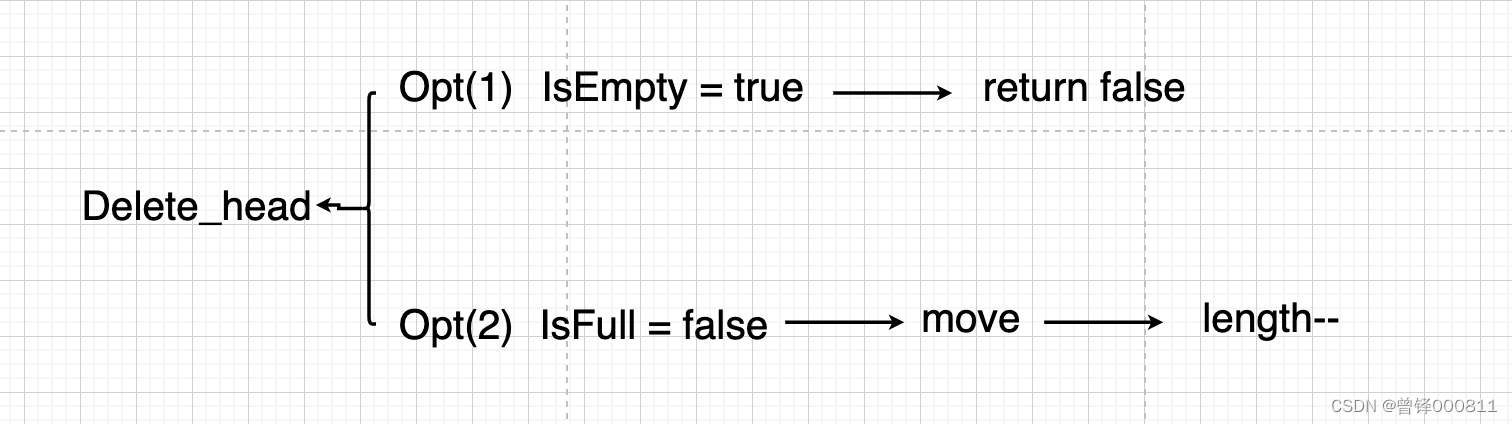
code:
bool Delete_head(struct Sqlist* sq)//头删
{
//1安全性处理
assert(sq != NULL);
//2判空
if(Is_Empty(sq)){
return false;
}
//3移动元素位置
for(int i = 0;i < sq->length - 1;i++){
sq->elem[i - 1] = sq->elem[i];
}
//4length-1
sq->length--;
return true;
}Tail delete function (Delete_tail):
Unlike head deletion, the tail deletion function does not need to be moved, so the time complexity is O(1), but it also needs to be judged empty. The following is the flow chart:
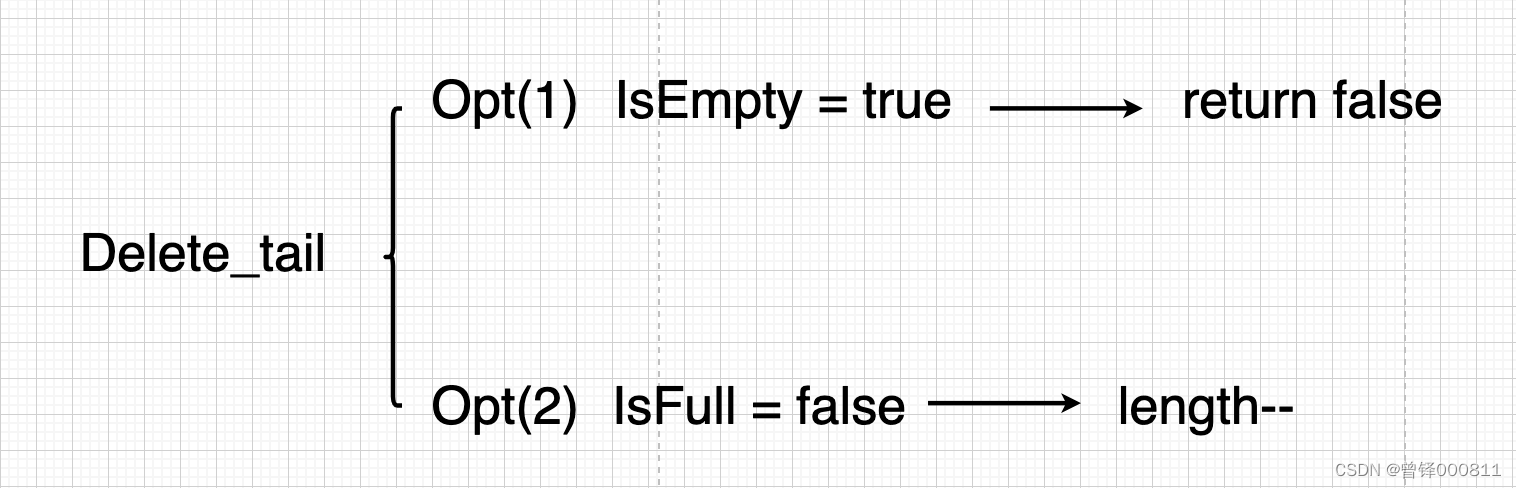
code:
bool Delete_tail(struct Sqlist* sq)//尾删
{
//1 安全性判断
assert(sq != NULL);
//2 判空
if(Is_Empty(sq)){
return false;
}
//3 length - 1
sq->length--;
return true;
}Delete function by position (Delete_pos):
First perform the null judgment operation. If it is empty, return false directly. If it is not empty, the value behind the element to be deleted will be moved forward by one unit, and the length will be reduced by 1. The following is the flow chart:
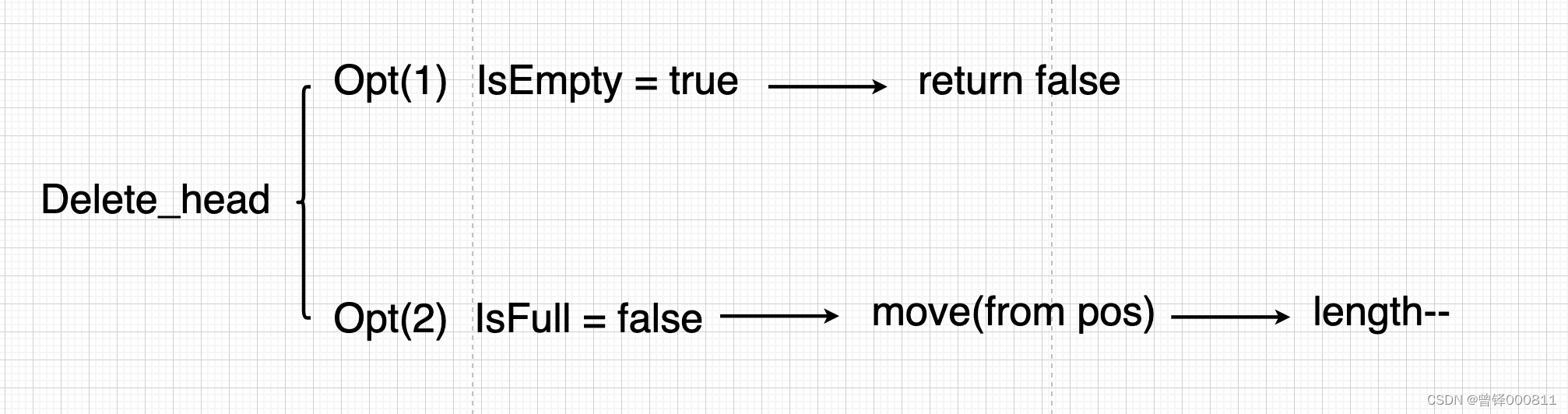
It should be noted here that when the pos value is 0, the head deletion operation is actually performed, so we need to add a judgment condition that pos >= 0, which is similar to the insertion operation by position, and is executed when pos == 0 It is also a plug-in operation.
code:
bool Delete_pos(struct Sqlist* sq,int pos)//按位置删
{
//1 安全性处理
assert(sq != NULL);
//2 将待删除节点后面的节点统一向前移一位,假设pos = 0时为头删判断pos的合法性
assert(pos >= 0 && pos < sq->length);
//3 判空
if(Is_Empty(sq)){
return false;
}
//4 假设让i指向被覆盖者的一方
for(int i = pos;i < sq->length - 1;i++){
sq->elem[i] = sq->elem[i + 1];
}
//假设让i指向覆盖者的一方
// for(int i = pos + 1;i < sq->length;i++){
// sq->elem[i - 1] = sq->elem[i];
// }
//5 length - 1
sq->length--;
return true;
}Delete function by value (Delete_val):
The delete function by value is based on the premise that the sequence table is not empty, so there is no need to perform null judgment. We first define a temporary variable temp to save the subscript of the element found in the sequence table, and then directly call the delete function by position (Delete_pos) here, the following is the flow chart:

code:
bool Delete_val(struct Sqlist* sq,Elem_type val)//按值删(找这个值在顺序表中第一次出现的位置,然后删除它)
{
//1 安全性处理
assert(sq != NULL);
//2 定义临时变量保存要删除元素的下标(先查找)
int temp = Search(sq,val);
//如果找到了,temp保存这个值的下标,如果没找到temp返回-1
if(temp == -1){
return false;
}
//3 如果代码执行到了这一行
return Delete_pos(sq,temp);
}Clear sequence table function (Clear):
Clearing the sequence table means directly assigning the length of the sequence table to zero.
code:
void Clear(struct Sqlist* sq)//清空(将数据晴空,认为没有有效值)
{
//1 安全性处理
assert(sq != NULL);
//2 将顺序表的长度直接赋值为0
sq->length = 0;
}Destroy sequence table function (Destroy):
The meaning of destroying the sequence table is to directly release the memory space (whether it is expanded or not) that was applied for by using malloc in the initialization function, and the sequence table naturally does not exist.
code:
void Destroy(struct Sqlist* sq)//销毁(将数据存储空间都释放掉)
{
//1 安全性处理
assert(sq != NULL);
//2 释放掉申请开辟的空间
free(sq->elem);
//3 将顺序表的长度和总容量全部置为0
sq->length = 0;
sq->listsize = 0;
}Print sequence table function (Show):
This function is relatively simple, in fact, it traverses and then outputs.
code:
void Show(struct Sqlist* sq)//打印
{
//1 安全性处理
assert(sq != NULL);
//2 打印操作
for(int i = 0;i < sq->length;i++){
printf("%3d",sq->elem[i]);
}
printf("\n");
}Test the implemented functions in the test file (Test.cpp):
Define a head sequence table in the Test file and initialize it:
struct Sqlist head;
Init_Sqlist(&head);Fill the sequence table with 100 elements after initialization:
for(int i = 0;i < 100;i++){
Insert_pos(&head,i,i + 1);
}Test header insertion function and expansion function (Insert_gead):
Insert element 100 at the head of the sequence table and print the length of the sequence table and the length of the storage space. When the sequence table is full, first expand the capacity and then insert:
Show(&head);
printf("\nlength = %d",head.length);
printf("\nlistsize = %d",head.listsize);
printf("\n");
Insert_head(&head,100);
Show(&head);
printf("\nlength = %d",head.length);
printf("\nlistsize = %d",head.listsize);operation result:

As shown in the figure, our initial total capacity is set to 100 units. When we need to add element 100 to the head of the value sequence table, we must first perform the full operation, then double the capacity of the sequence table, and then migrate the elements , and then add 100 to the header of the sequence table, and the running result is correct.
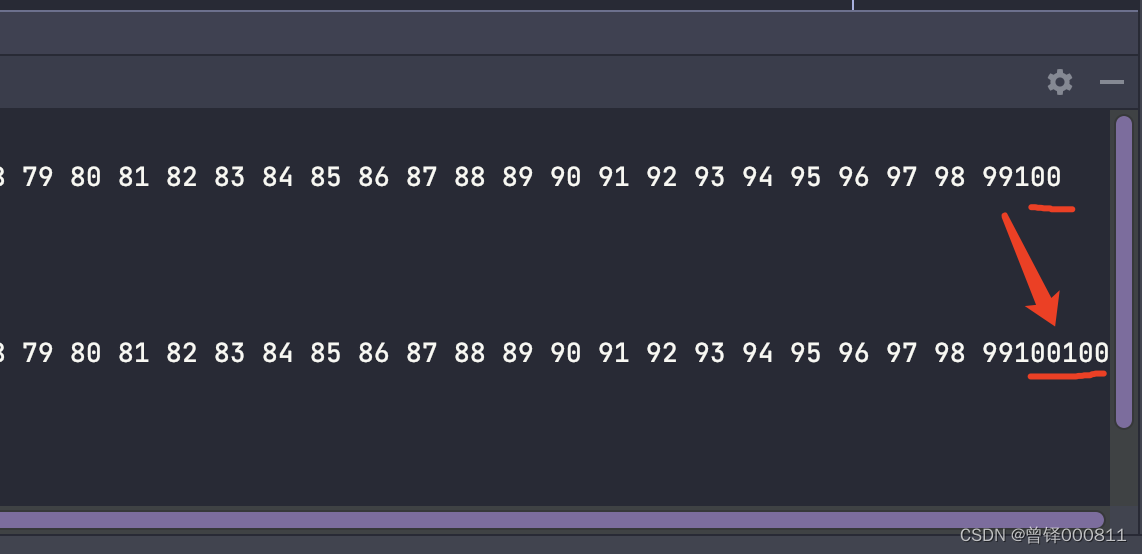
Test tail insertion function (Insert_tail):
Insert element 100 to the end of the sequence table. At this time, because the sequence table is full, the capacity must be expanded first, and then inserted. The listsize variable becomes twice the original value, which is 200:
Insert_tail(&head,100);
Show(&head);
printf("\nlength = %d",head.length);
printf("\nlistsize = %d",head.listsize);operation result:
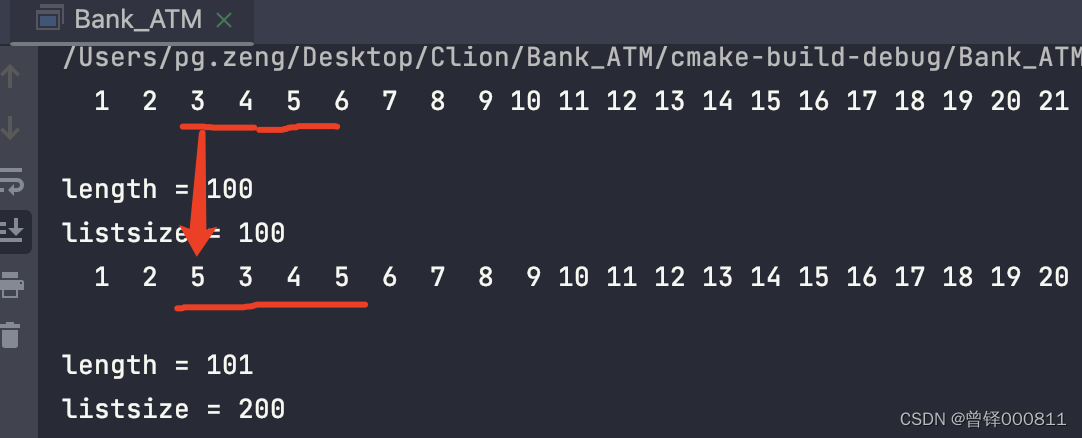
Test the interpolation function by position (Insert_pos):
Specify the 2nd subscript position to insert 5 elements:
Insert_pos(&head,2,5);
Show(&head);
printf("\nlength = %d",head.length);
printf("\nlistsize = %d",head.listsize);operation result:
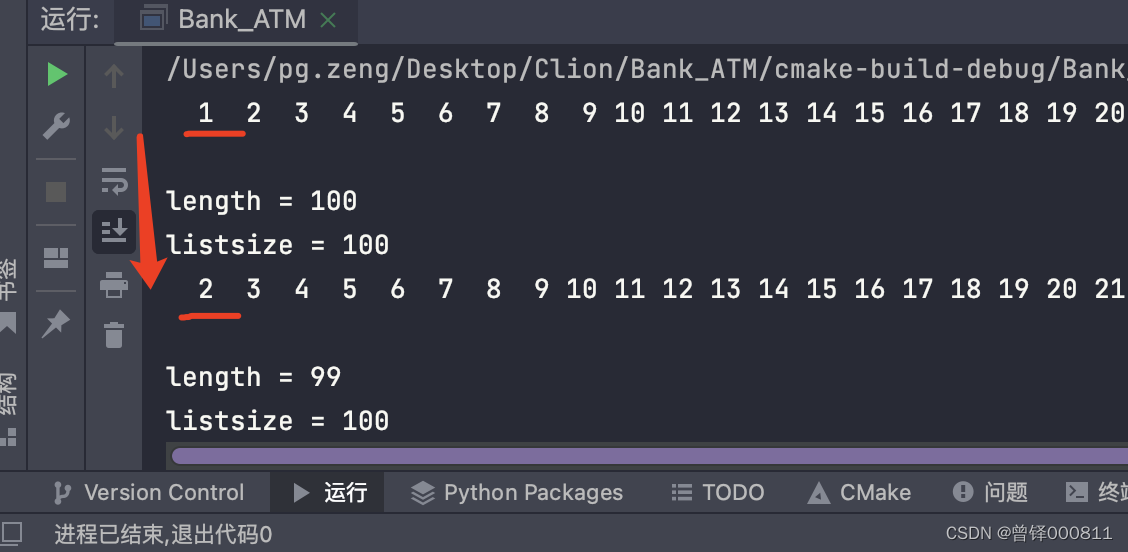
Test head delete function (Delete_Head):
Delete the head element of the sequence table:
Delete_head(&head);
Show(&head);
printf("\nlength = %d",head.length);
printf("\nlistsize = %d",head.listsize);operation result:
Test the tail delete function (Delete_tail):
Delete the tail element of the sequence table:
Delete_tail(&head);
Show(&head);
printf("\nlength = %d",head.length);
printf("\nlistsize = %d",head.listsize);operation result:

Test the delete function by position (Delete_pos):
I want to delete the element with subscript No. 2 in the sequence table, as shown in the figure:
Delete_pos(&head,2);
Show(&head);
printf("\nlength = %d",head.length);
printf("\nlistsize = %d",head.listsize);operation result:
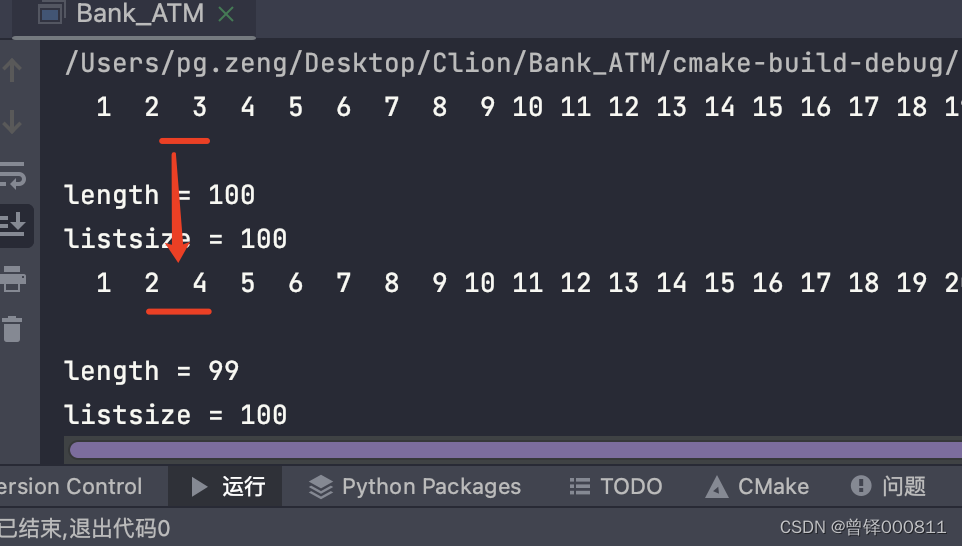
Test the delete function by value (Delete_val):
The value I want to delete is 2. First, check whether 2 exists in the sequence table. If it exists, overwrite the value behind the 2 element forward:
Delete_val(&head,2);
Show(&head);
printf("\nlength = %d",head.length);
printf("\nlistsize = %d",head.listsize);operation result:
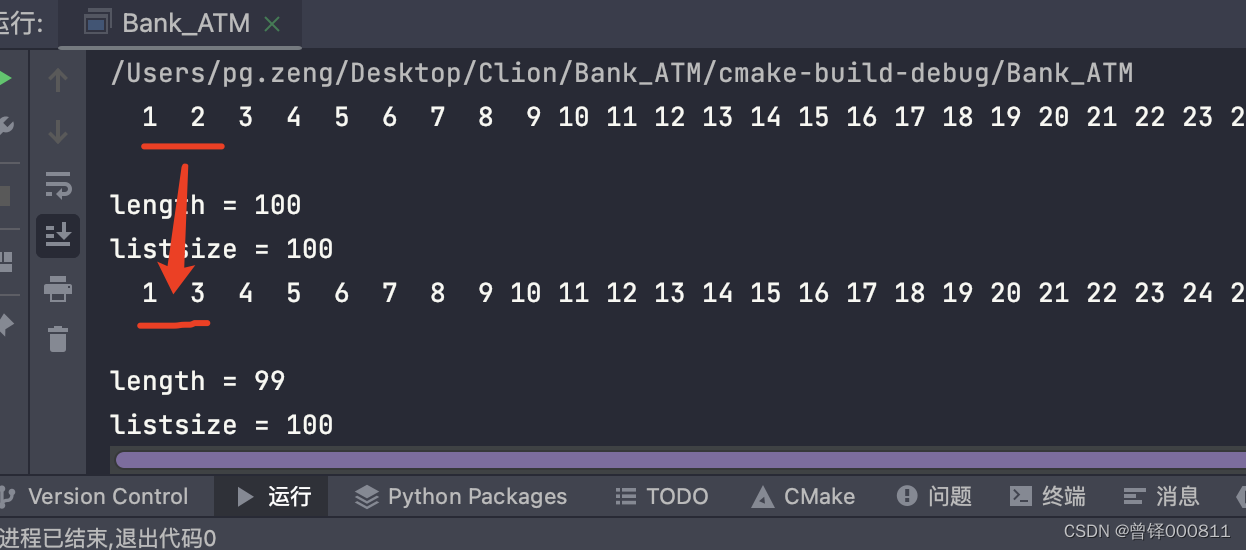
Test the search function (Search):
The value I want to find is 10, and use temp to save the return value of the find function, if the element 10 is found in the sequence table, return the subscript, if not, return -1:
int temp = Search(&head,10);
printf("result = %d\n",temp);operation result:
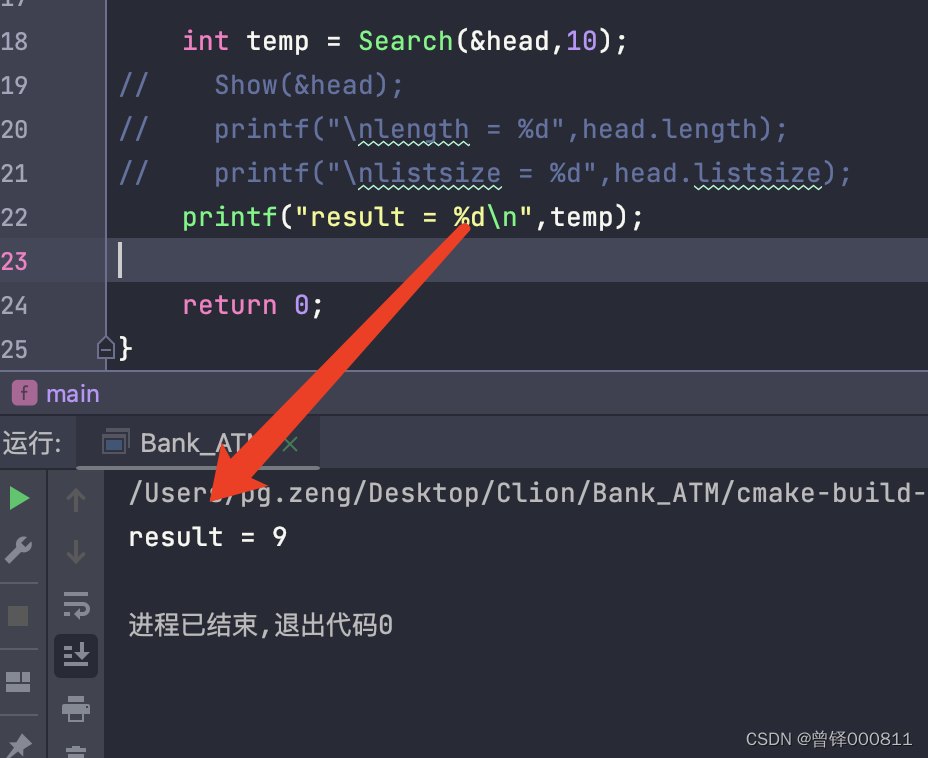
Test the clear function (Clear):
Clear(&head);
Show(&head);
printf("\nlength = %d",head.length);
printf("\nlistsize = %d",head.listsize);operation result:
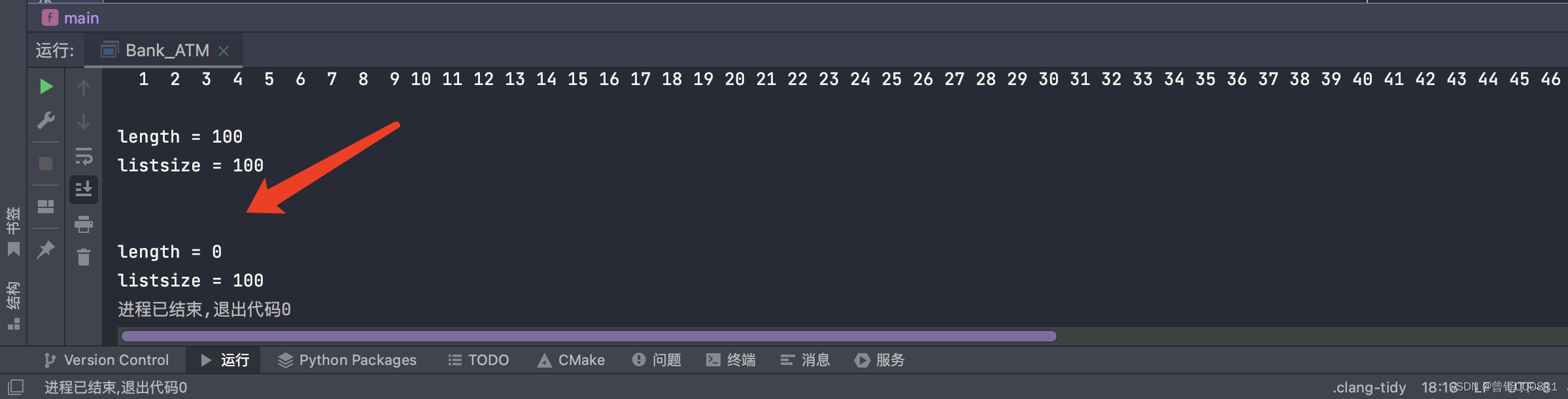
Test the destruction function (Destroy):
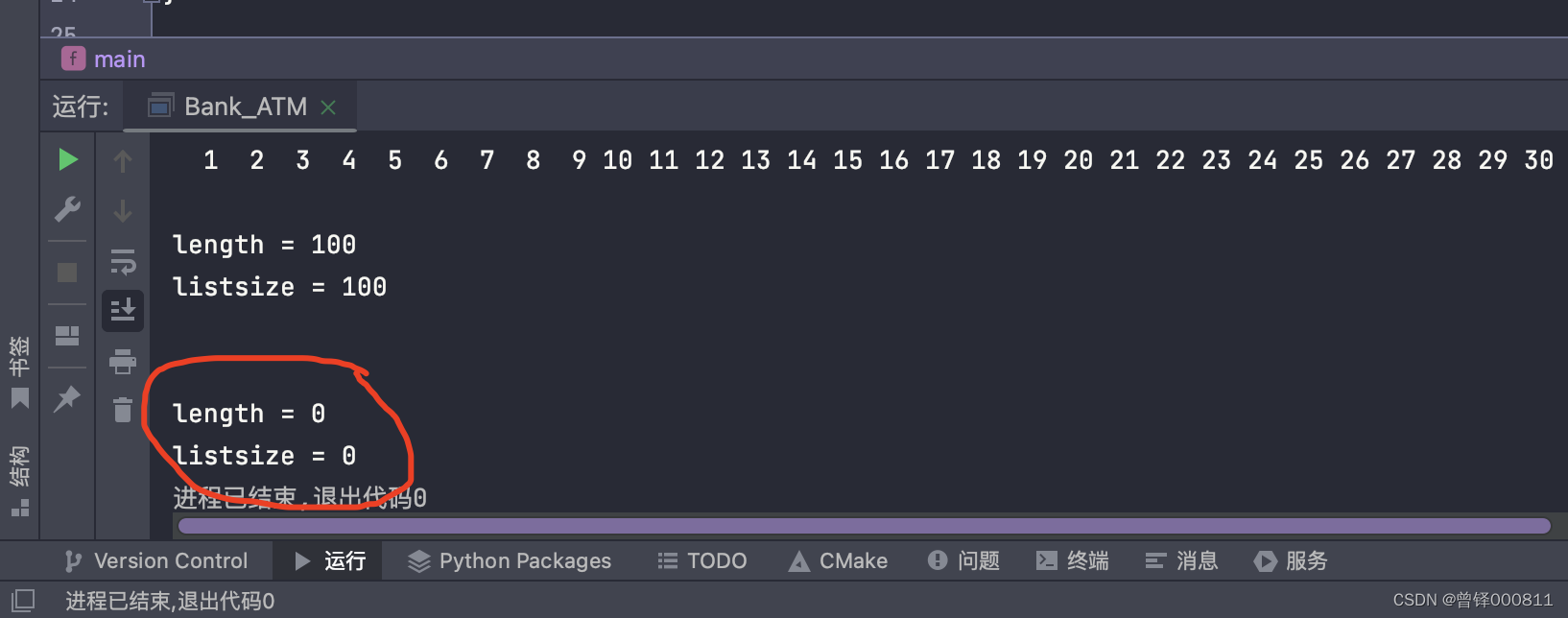
Destroy(&head);
Show(&head);
printf("\nlength = %d",head.length);
printf("\nlistsize = %d",head.listsize);operation result:
Summarize:
The advantage of the sequential table is that it can be accessed directly, and its deletion and insertion operations are mainly concentrated at the end. However, having advantages means that there are corresponding disadvantages. Insertion and deletion operations at the head and middle of the sequence table require a large number of operations, which is followed by high space-time overhead and frequent expansion operations. The cost is also relatively high.
So far, the implementation of the sequence table has been basically completed. This article is used to summarize what the teacher said in class. If there are other functions, you can add it. The sequence table is the first data structure I learned, and it synthesizes the C The knowledge in the language, such as: dynamic memory management, structure, pointer, and the code to write the sequence table are also equivalent to a review of these knowledge. I will follow up in Yan Weimin - "Data Structure (C Language Edition)" Other functions of the linear table Will be added at a later date. I will upload the complete code of the sequence table to resources.
References:
Yan Weimin - "Data Structure (C Language Edition)"